

概要
我们经常在SQL Server中使用group by语句配合聚合函数,对已有的数据进行分组统计。本文主要介绍一种分组的逆向操作,通过一个递归公式,实现ungroup操作。
代码和实现
我们看一个例子,输入数据如下,我们有一张产品表,该表显示了产品的数量。
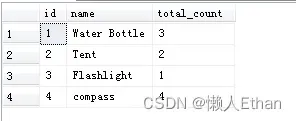

要求实现Ungroup操作,最后输出数据如下:
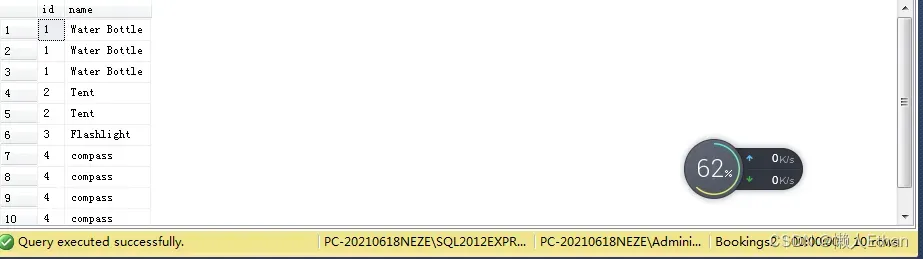

代码和实现
基本思路
要想实现ungroup,显然需要表格的自连接。自连接的次数取决于total_count的数量。
代码
自连接操作过程中涉及大量的子查询,为了便于代码后期维护,我们采用CTE。每次子查询,total_count自动减一,total_count小于0时,直接过滤掉,该数据不再参与查询。
第1轮查询
获取全部total_count 大于0的数据,即全表数据。
with cte1 as (
select * from products where total_count > 0
),输出结果:


第2轮查询
第2轮子查询,以第1轮的输出作为输入,进行表格自连接,total_count减1,过滤掉total_count小于0的产品。
with cte1 as (
select * from products where total_count > 0
),
cte2 as (
select * from (
select cte1.id, cte1.name, (cte1.total_count -1) as total_count from cte1
join products p1
on cte1.id = p1.id) t
where t.total_count > 0
)
select * from cte2输出结果是:
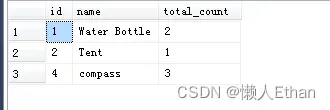

和第1轮相比较,输出结果中没了Flashlight了,因为它的total_count减1后为0,被过滤了。
第3轮查询
第3轮子查询,以第2轮的输出作为输入,进行表格自连接,total_count减1,过滤掉total_count小于0的产品。
with cte1 as (
select * from products where total_count > 0
),
cte2 as (
select * from (
select cte1.id, cte1.name, (cte1.total_count -1) as total_count from cte1
join products p1
on cte1.id = p1.id) t
where t.total_count > 0
),
cte3 as (
select * from (
select cte2.id, cte2.name, (cte2.total_count -1) as total_count from cte2
join products p1
on cte2.id = p1.id) t
where t.total_count > 0
)
select * from cte3输出结果如下:
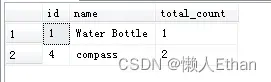

第4轮查询
第4轮子查询,以第3轮的输出作为输入,进行表格自连接,total_count减1,过滤掉total_count小于0的产品。
with cte1 as (
select * from products where total_count > 0
),
cte2 as (
select * from (
select cte1.id, cte1.name, (cte1.total_count -1) as total_count from cte1
join products p1
on cte1.id = p1.id) t
where t.total_count > 0
),
cte3 as (
select * from (
select cte2.id, cte2.name, (cte2.total_count -1) as total_count from cte2
join products p1
on cte2.id = p1.id) t
where t.total_count > 0
),
cte4 as (
select * from (
select cte3.id, cte3.name, (cte3.total_count -1) as total_count from cte3
join products p1
on cte3.id = p1.id) t
where t.total_count > 0
)
select * from cte4输出结果:
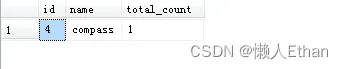

下一次迭代,compass的total_count也将等于0,被过滤掉,查询结果不会再有新的记录,所以查询结束。我们将cte1,cte2,cte3 和 cte4 合并,合并结果即是所求。
代码改进
显然上述代码过于冗长,如果产品数量很多,那子查询的代码也将大幅度增加。
事实上,从第2轮到第4轮的子查询,代码是非常相近的,对于这种情况,无论任何开发语言,我们都可以采用递归的方式进行优化处理。对于此类为题,递归公式如下:
with CTE as (
initial query -- 初始查询
union all -- 查询结果合并
recursive query -- 递归部分,即在查询中直接引用CTE
Recursive terminatation condition -- 递归终止条件
)初始查询,就是我们的第1轮迭代。递归部分,就是我们所谓的相似代码部分。
对于递归终止条件,默认是如果没有新的记录参加递归,则递归终止。本例是按照业务逻辑,设置的终止条件,即total_count需要大于0,这样也可以做到过滤到最后,不会再有新的记录参与到递归中。
按照上述供述,得到的查询代码如下:
with cte as (
select * from products where total_count > 0
union all
select * from (
select cte.id, cte.name, (cte.total_count -1) as total_count from cte
join products p1
on cte.id = p1.id) t
where t.total_count > 0
)
select id, name from cte
order by id, name当我们使用CTE时候,发现每次查询的代码类似,就可以考虑采用上述递归公式对代码进行优化。找到初始查询结果,在相似的代码中找到递归部分以及递归终止条件。
附录
建表和数据初始化代码
if OBJECT_ID('products', 'U') is not null
drop table products
create table products
(
id int primary key identity(1,1),
name nvarchar(50) not null,
total_count int not null
)
insert into products (name, total_count) values
('Water Bottle', 3),
('Tent', 2),
('Flashlight', 1),
('compass',4)到此这篇关于SQLServer实现Ungroup操作的示例代码的文章就介绍到这了,更多相关SQLServer Ungroup操作内容请搜索aitechtogether.com以前的文章或继续浏览下面的相关文章希望大家以后多多支持aitechtogether.com!