

Mysql删除表重复数据
表里存在唯一主键
根据多个字段删除重复数据,只保留一条数据
DELETE
FROM
table_name
WHERE
(字段1, 字段2) IN (
SELECT
t.字段1,
t.字段2
FROM
(
SELECT
字段1,
字段2
FROM
table_name
GROUP BY
字段1,
字段2
HAVING
count(1) > 1
) t
)
AND id NOT IN (
SELECT
dt.id
FROM
(
SELECT
min(id) AS id
FROM
table_name
GROUP BY
字段1,
字段2
HAVING
count(1) > 1
) dt
)没有主键时删除重复数据
1、创建新表
①创建一个新表与目标表结构字段保持一致
create table new_table_temp②将过滤查询的统计的数据写入到新表
insert into new_table_temp③将旧表table_name 删除
delete from table_name ④将创建的新表名称修改为旧表名称
2、添加字段
①表结构添加一个自增且唯一字段
②按照存在唯一主键进行删除重复数据
③删除添加的自增字段
Mysql删除表中重复数据并保留一条
最近有个需求,给角色添加菜单权限,这是一个role_menu 表。
里面存放的是角色id和菜单id,是批量给一种类型角色添加,但有可能角色人为添加过,因为数据量还是比较大的,如果先查询这个有没有添加过再添加会很耗时,而统一不管有没有添加过一并添加则很快,这就需要后续给重复数据给删除掉,于是有了今天的分享。
我这里只做一个列子,工作代码安全底线大家谨记哈。
准备一张表 用的是mysql8 大家自行更改
/*
Navicat Premium Data Transfer
Source Server : localmysql
Source Server Type : MySQL
Source Server Version : 80030
Source Host : localhost:3306
Source Schema : nie_db
Target Server Type : MySQL
Target Server Version : 80030
File Encoding : 65001
Date: 17/08/2022 10:49:41
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for message
-- ----------------------------
DROP TABLE IF EXISTS `message`;
CREATE TABLE `message` (
`id` bigint(0) NOT NULL,
`message_title` varchar(50) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL,
`message_context` varchar(200) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL,
`send_peo` bigint(0) NULL DEFAULT NULL,
`receive_peo` bigint(0) NULL DEFAULT NULL,
`scope` int(0) NULL DEFAULT 0,
`del_flag` tinyint(0) NULL DEFAULT 0,
`create_time` datetime(0) NULL DEFAULT NULL,
`creator` tinyint(0) NULL DEFAULT NULL,
`update_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of message
-- ----------------------------
INSERT INTO `message` VALUES (1, '测试消息', '消息内容', 23, 1231, 0, 0, '2022-08-17 10:39:51', 3, '2022-08-17 10:40:00');
INSERT INTO `message` VALUES (2, '测试消息', '消息内容', 23, 1231, 0, 0, '2022-08-17 10:39:51', 3, '2022-08-17 10:40:00');
INSERT INTO `message` VALUES (3, '测试消息', '消息内容', 23, 1231, 0, 0, '2022-08-17 10:39:51', 3, '2022-08-17 10:40:00');
INSERT INTO `message` VALUES (4, '测试消息', '消息内容', 23, 1231, 0, 0, '2022-08-17 10:39:51', 3, '2022-08-17 10:40:00');
SET FOREIGN_KEY_CHECKS = 1;创建表并添加四条相同的数据
接下来是我们这次的重头,我封装了一个存储过程,具体的逻辑都在注释里了,你也可以分析然后单独拿出来分批次执行sql
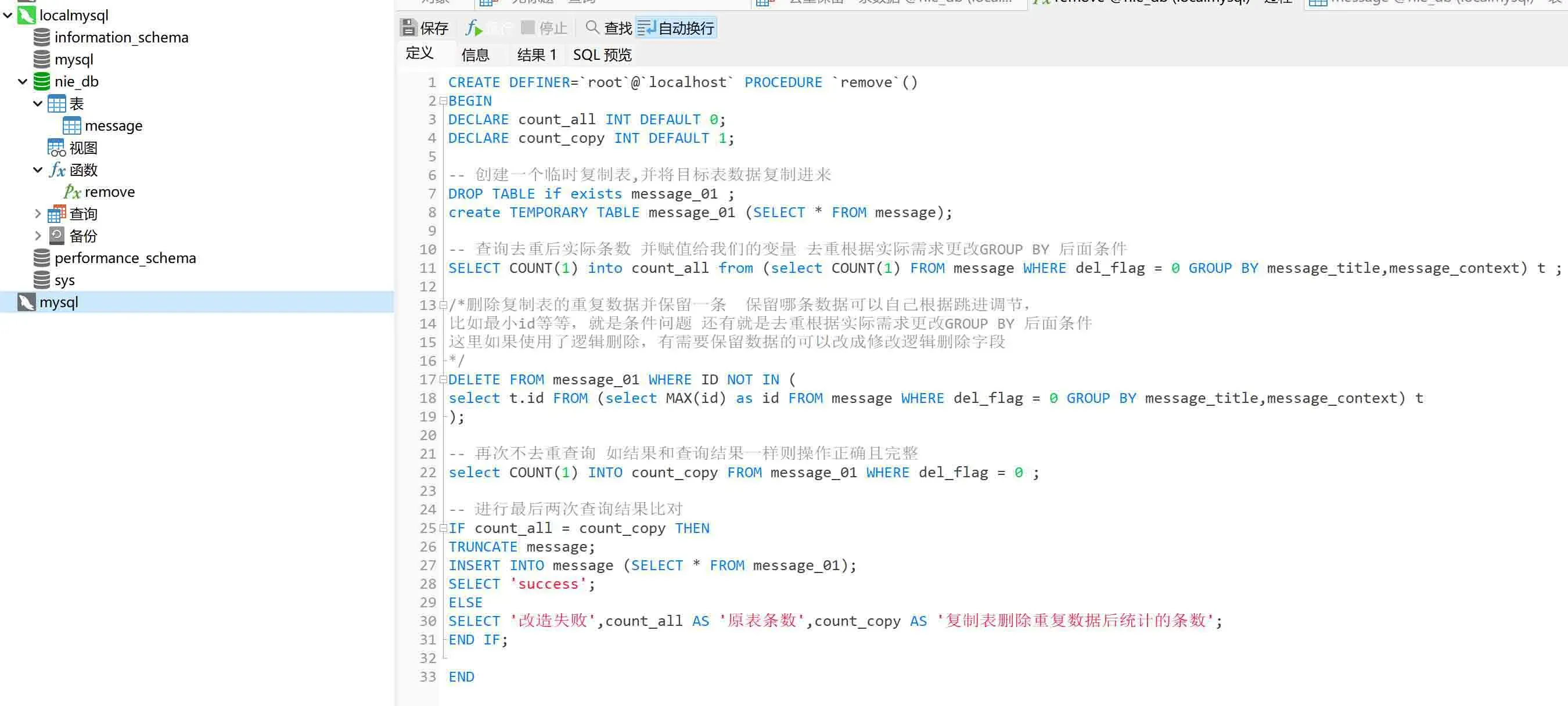

CREATE DEFINER=`root`@`localhost` PROCEDURE `remove`()
BEGIN
DECLARE count_all INT DEFAULT 0;
DECLARE count_copy INT DEFAULT 1;
-- 创建一个临时复制表,并将目标表数据复制进来
DROP TABLE if exists message_01 ;
create TEMPORARY TABLE message_01 (SELECT * FROM message);
-- 查询去重后实际条数 并赋值给我们的变量 去重根据实际需求更改GROUP BY 后面条件
SELECT COUNT(1) into count_all from (select COUNT(1) FROM message WHERE del_flag = 0 GROUP BY message_title,message_context) t ;
/*删除复制表的重复数据并保留一条 保留哪条数据可以自己根据条件调节,
比如最小id等等,就是条件问题 还有就是去重根据实际需求更改GROUP BY 后面条件
这里如果使用了逻辑删除,有需要保留数据的可以改成修改逻辑删除字段
*/
DELETE FROM message_01 WHERE ID NOT IN (
select t.id FROM (select MAX(id) as id FROM message WHERE del_flag = 0 GROUP BY message_title,message_context) t
);
-- 再次不去重查询 如结果和查询结果一样则操作正确且完整
select COUNT(1) INTO count_copy FROM message_01 WHERE del_flag = 0 ;
-- 进行最后两次查询结果比对
IF count_all = count_copy THEN
TRUNCATE message;
INSERT INTO message (SELECT * FROM message_01);
SELECT 'success';
ELSE
SELECT '改造失败',count_all AS '原表条数',count_copy AS '复制表删除重复数据后统计的条数';
END IF;
END另外创建存储过程,就是再函数那里右键 -》过程-》输入名字-》完成 ,你也可以百度下怎么创建的,我这里就不说太多啦。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持aitechtogether.com。