

一、前言
单表存储上下级关系,使用mysql 内置函数循环递归查出来
二、相关语法函数介绍
@
@是用户变量,@@是系统变量。
:=
不只在set和update时时赋值的作用,在select也是赋值的作用。
group_concat()
将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
FIND_IN_SET()
查询字段(strlist)中包含(str)的结果,返回结果为null或记录
三、具体实现
创建表
查询父级为 2 的下级 无限级查询
SELECT
@ids AS _ids,
( SELECT @ids := GROUP_CONCAT( descendant ) FROM relation WHERE FIND_IN_SET( ancestor, @ids ) ) AS cids,
@l := @l + 1 AS LEVEL
FROM
relation,
( SELECT @ids := 2, @l := 0 ) b
WHERE
@ids IS NOT NULL 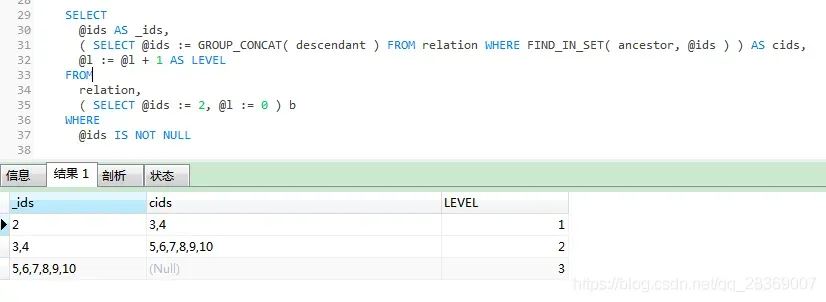

列表化
SELECT
descendant.LEVEL,
DATA.*
FROM
(
SELECT
@ids AS _ids,
( SELECT @ids := GROUP_CONCAT( descendant ) FROM relation WHERE FIND_IN_SET( ancestor, @ids ) ) AS cids,
@l := @l + 1 AS LEVEL
FROM
relation,
( SELECT @ids := 2, @l := 0 ) b
WHERE
@ids IS NOT NULL
) descendant,
sys_dept_relation DATA
WHERE
FIND_IN_SET( DATA.descendant, descendant._ids )
ORDER BY
LEVEL,
DATA.descendant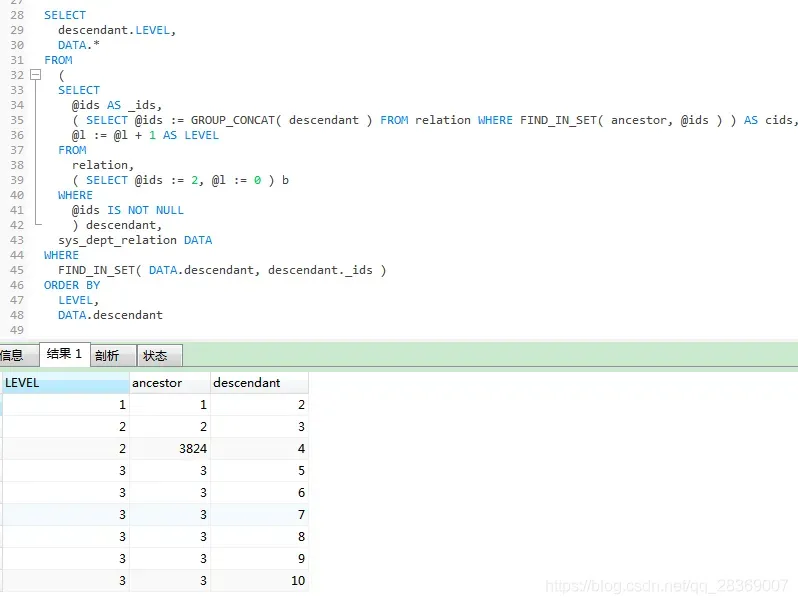

查询ID为 8 的上级 无限级查询
SELECT
@id AS _id,
( SELECT @id := ancestor FROM relation WHERE descendant = @id ) AS _pid,
@l := @l + 1 AS LEVEL
FROM
relation,
( SELECT @id := 8, @l := 0 ) b
WHERE
@id > 0 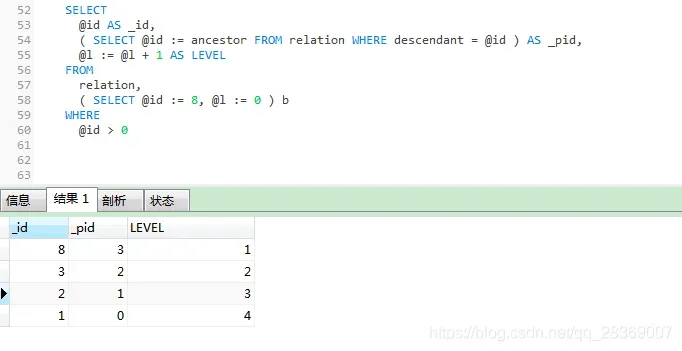

四、效率问题
我目前测试表有8千多数据量
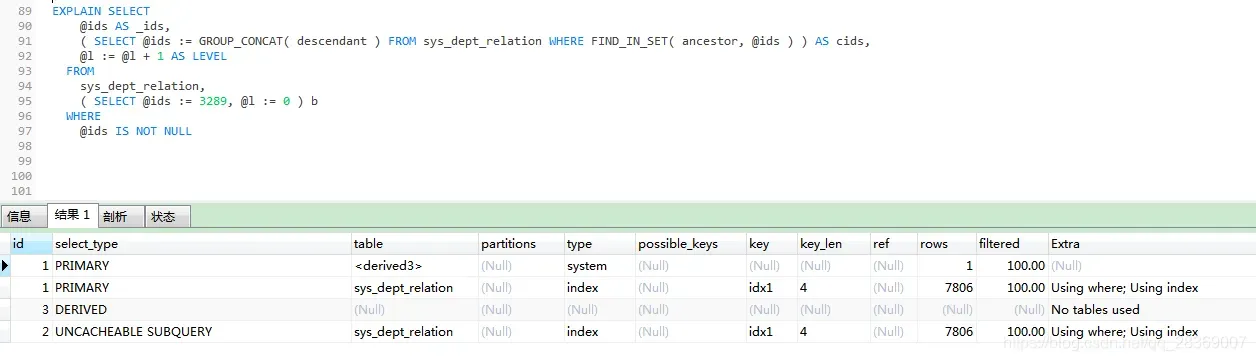

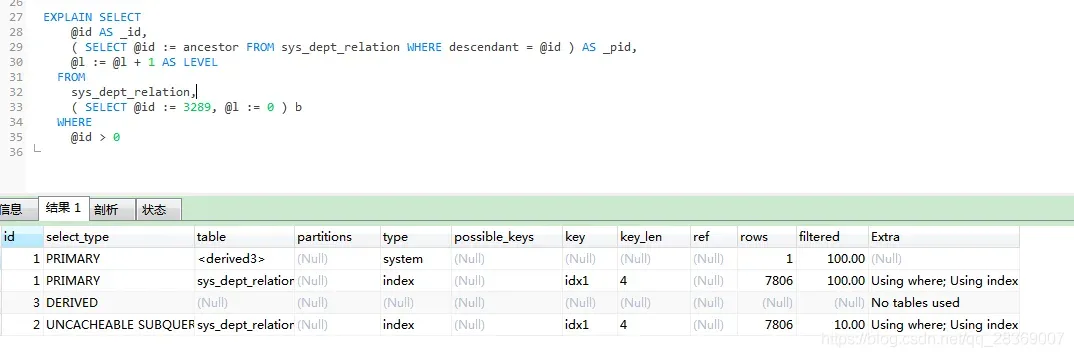

EXPLAN 相关参数
Select_type:
PRIMARY:查询中最外层的SELECT(如两表做UNION或者存在子查询的外层的表操作为PRIMARY,内层的操作为UNION)DERIVED:被驱动的SELECT子查询(子查询位于FROM子句)UNCACHEABLE SUBQUERY:一个子查询的结果不能被缓存,必须重新评估外链接的第一行
Type:
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。index: Full Index Scan,index与ALL区别为index类型只遍历索引树System:system是const类型的特例,当查询的表只有一行的情况下,使用system
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持aitechtogether.com。