

Midjourney API 申请及使用
在人工智能绘图领域,想必大家听说过 Midjourney 的大名吧!
Midjourney 以其出色的绘图能力在业界独树一帜。无需过多复杂的操作,只要简单输入绘图指令,这个神奇的工具就能在瞬间为我们呈现出对应的图像。无论是任何物体还是任何风格,都能在Midjourney的绘画魔法下得以轻松呈现。如今,Midjourney 早已在各个行业和领域广泛应用,其影响力愈发显著。
然而,在国内想要使用 Midjourney 却面临着相当大的挑战。首先,Midjourney 目前驻扎在 Discord 平台中,这意味着要使用 Midjourney,必须通过特殊的充值途径获得访问权限。如果没有订阅,几乎无法使用 Midjourney,因此单是使用这一工具就成了一个巨大的难题。此外,有人或许会疑问:Midjourney 是否提供对外API服务?然而事实是,Midjourney 并未向外界提供任何API服务,而且从目前情况看来,这一情况似乎也不会改变。
那么,是否有方法能够与 Midjourney 对接,并将其融入到自己的产品中呢?
答案是肯定的。接下来,我将为大家介绍知数云平台所提供的 Midjourney API,通过使用该 API,我们能够实现与 Midjourney 官方完全一致的效果和操作,下文会详细介绍。
简介
知数云平台是什么呢?简单来说,它是一个提供多样数字化 API 的服务平台,其官网链接是:知数云官网
你可能会疑惑,既然 Midjourney 官方并未向外提供 API,那么知数云平台的API是如何诞生的呢?简言之,知数云的 Midjourney 与 Discord 内的 Midjourney Bot 进行了接口对接,同时模拟了底层通信协议,从而能够在 Discord 平台上实现与 Midjourney 官方完全相同的操作。这涵盖了文字生成图片、图像转换、图像融合、图文生成等多个功能。此外,该 API 在后台维护了大量 Midjourney 账号,通过负载均衡控制实现了高度的并发处理,比官方 Midjourney 单一账号的并发能力要更高。
总体来看,无论是在 Discord 上使用 Midjourney 提供的哪一项功能,这个 API 都能完全还原官方操作的效果和效能。
稳定性如何呢?根据我个人几个月的观察和使用经验,可以毫不夸张地说,目前业界很难找到比知数云 Midjourney API 更稳定且并发处理能力更高的选择,而且还能保持 Midjourney 这一价格水平。这样的选择寥寥无几。
下面我们就来了解下这个 API 的申请和使用方法吧。
申请流程
下文内容大多数来源于知数云 Midjourney API 官方介绍文档,文档链接:https://data.zhishuyun.com/documents/0fd3dd40-a16a-4246-8313-748b8e75c29e,最新内容以官方文档为准。
要使用 Midjourney Imagine API,首先可以到
知数云官网Midjourney Imagine AP 页面点击「获取」按钮:


如果你尚未登录,会自动跳转到登录页面。扫码关注公众号即可自动登录,无需额外注册步骤。
登录完了之后会跳回原页面 Midjourney Imagine API ,此时会提示「您尚未申请该服务,需要申请」。
申请时会校验实名认证情况,请按照网站提示完成实名认证。实名认证会校验姓名、手机号、身份证号,需要三者一致才可以通过认证。认证完了之后可以返回页面,刷新一下页面确保信息更新,然后重新申请即可通过申请。
基本使用
接下来就可以在界面上填写对应的内容,如图所示:
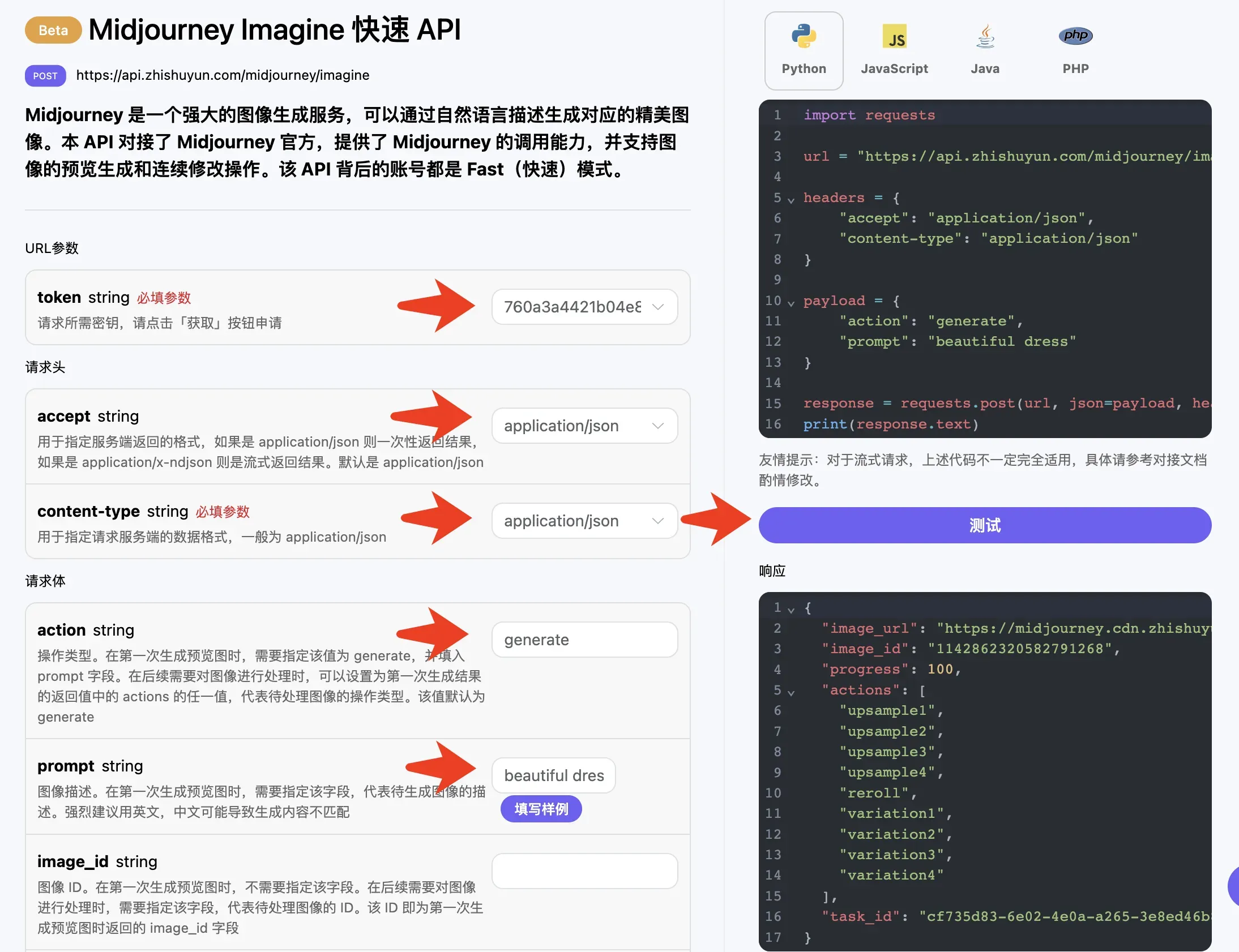

在第一次使用该接口时,我们至少需要填写两个参数,一个是 action,另一个是 prompt。其中 action 参数代表了生成图的操作类型,由于第一次调用该 API 我们没有生成过任何内容,所以我们需要先输入文字来生成一副预览图,所以这时候 action 应该填写为 generate。另外一个参数 prompt 就是我们想生成的图片描述内容了,强烈建议用英文描述,画的图会更准确效果更好,这里我们填写了 beautiful dress,代表要画一条好看的裙子。
依次填写好图中所示参数,然后点击「测试」按钮即可测试接口。「测试」按钮下方会显示 API 返回的结果。同时您可以注意到右侧有对应的调用代码生成,您可以复制代码到您的 IDE 里面进行对接和开发。
调用之后,我们发现返回结果如下:
{
"image_url": "https://midjourney.cdn.zhishuyun.com/attachments/1124768570157564029/1142862320582791268/nglover_beautiful_dress_id4899456_02d66331-b4d5-46bd-b5ea-efa6d9447528.png",
"image_id": "1142862320582791268",
"progress": 100,
"actions": [
"upsample1",
"upsample2",
"upsample3",
"upsample4",
"reroll",
"variation1",
"variation2",
"variation3",
"variation4"
],
"task_id": "cf735d83-6e02-4e0a-a265-3e8ed46b8070"
}
返回结果一共有如下字段:
task_id,生成此图像任务的 ID,用于唯一标识此次图像生成任务。
image_id,图片的唯一标识,在下次需要对图片进行变换操作时需要传此参数。
image_url,图片的 URL,直接打开即可查看生成的效果,如图所示:


可以看到,这里生成了一张 2×2 的预览图。
actions,可以对生成的图片进行的进一步操作列表。这里一共列了 9 个,其中 upsample 代表放大,variation 代表变换,reroll 代表重新生成。所以 upsample1 代表的就是对左上角第一张图片进行放大操作,variation3 就是代表根据左下角第三张图片进行变换操作。
到现在为止,第一次 API 调用就完成了。
提示:如果您觉得上述生图速度较慢,想进一步提升用户体验,可以考虑采用流式传输的模式或者使用极速 API,具体可参考文档下方内容。
图像放大与变换
下面我们尝试针对当前生成的照片进行进一步的操作,比如我们觉得右上角第二张的图片还不错,但我们想进行一些变换微调,那么就可以进一步将 action 填写为 variation2,同时将 image_id 传递即可,prompt 可以留空:
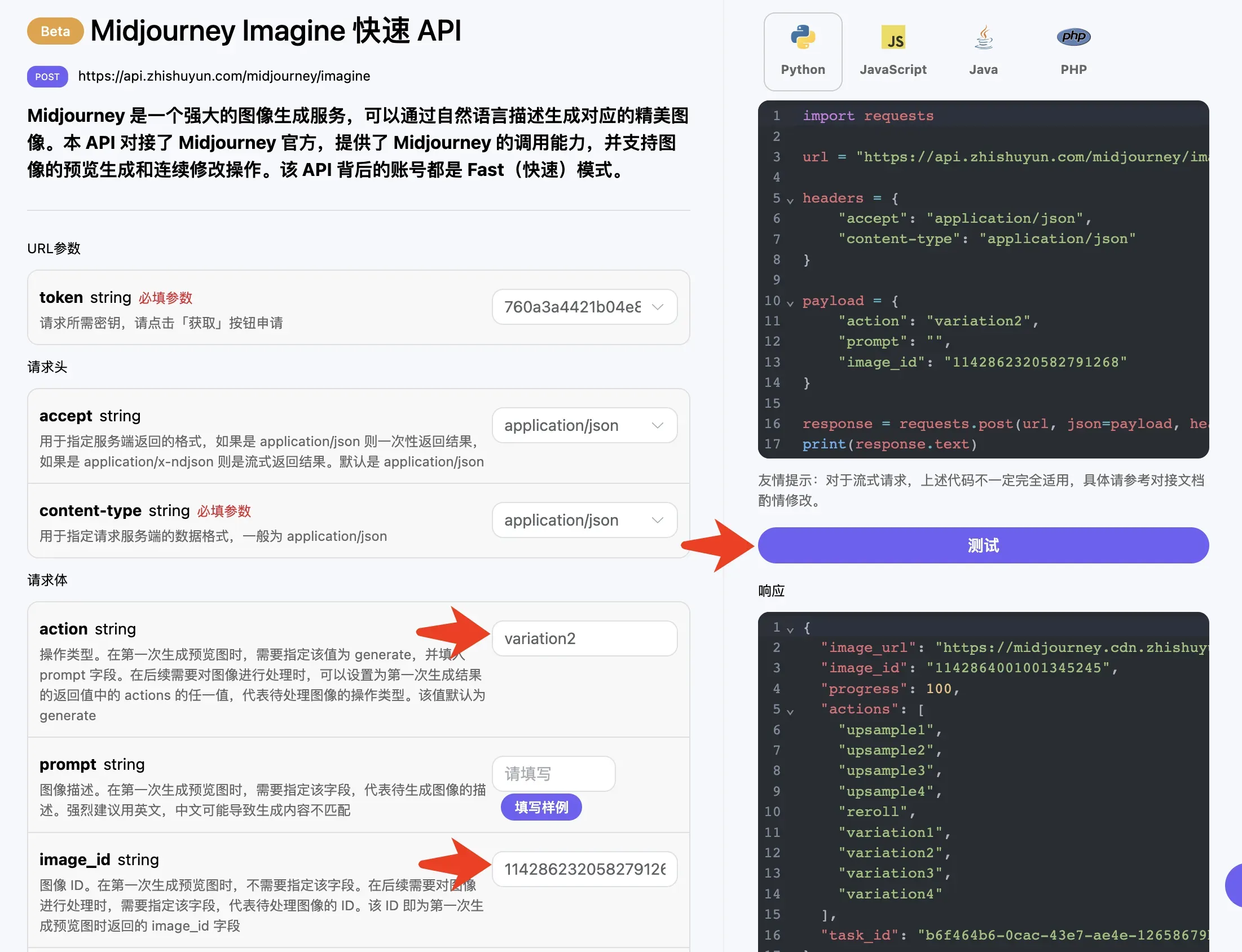

这时候得到的结果如下:
{
"image_url": "https://midjourney.cdn.zhishuyun.com/attachments/1124768570157564029/1142864001001345245/handerson6243_beautiful_dress_id4899456_aab4a0bf-7d99-4b7f-818c-c4dc690300ea.png",
"image_id": "1142864001001345245",
"progress": 100,
"actions": [
"upsample1",
"upsample2",
"upsample3",
"upsample4",
"reroll",
"variation1",
"variation2",
"variation3",
"variation4"
],
"task_id": "b6f464b6-0cac-43e7-ae4e-12658679b7f3"
}
打开 image_url,新生成的图片如下所示:

可以看到,针对上一张右上角的图片,我们再次得到了四张类似的照片。
这时候我们可以挑选其中一张进行精细化地放大操作,比如选第四张,那就可以 action 传入 upsample4,通过 image_id 再次传入当前图像的 ID 即可。


注意:
upsample操作相比variation来说,Midjourney 的耗时会更短一些。
返回结果如下:
{
"image_url": "https://midjourney.cdn.zhishuyun.com/attachments/1124768570157564029/1142864651860840458/ruthgarcia3808_beautiful_dress_id4899456_096f6a64-7412-4cb5-8f50-4afbfc456d55.png",
"image_id": "1142864651860840458",
"progress": 100,
"actions": [
"high_variation",
"low_variation",
"zoom_out_2x",
"zoom_out_1_5x",
"pan_left",
"pan_right",
"pan_up",
"pan_down"
],
"task_id": "9f5c34e3-c8af-415c-9377-fb46cd47ad45"
}
其中 image_url 如图所示:


这样我们就成功得到了一张独立的连衣裙的照片。
同时注意到 actions 里面又包含了几个可进行的操作,介绍如下:
high_variation:对画面进行高变换(具体含义请参考 Midjourney 官方)。
low_variation:对画面进行低变换(具体含义请参考 Midjourney 官方)。
zoom_out_2x:对画面进行缩小两倍操作(周围区域填充)。
zoom_out_1_5x:对画面进行缩小 1.5 倍操作(周围区域填充)。
pan_left:对画面进行左移和填充操作。
pan_right:对画面进行右移和填充操作。
pan_top:对画面进行上移和填充操作。
pan_bottom:对画面进行下移和填充操作。
可以继续按照上述流程传入对应的变换指令进行连续生图操作,可以实现无限次连续操作,这里不再一一赘述。
图像改写(垫图)
该 API 也支持图像改写,俗称垫图,我们可以输入一张图片 URL 以及需要改写的描述文字,该 API 就可以返回改写后的图片。
注意:输入的图片 URL 需要是一张纯图片,不能是一个网页里面展示一张图片,否则无法进行图像改写。建议使用图床(如阿里云 OSS、腾讯云 COS、七牛云、又拍云等)来上传获取图片的 URL。
假设这里我们有一张图片,URL 是 https://zhishuyun-1256437459.cos.ap-beijing.myqcloud.com/20230504-222359.png,是一张小女孩写字的图片:


现在我们想把它转化为卡通风格,可以直接在 prompt 字段将 URL 和要调整的文字一并输入即可,二者用空格分隔,比如:
https://zhishuyun-1256437459.cos.ap-beijing.myqcloud.com/20230504-222359.png transfer to cartoon style
样例调用如下:


输出结果如下:
{
"task_id": "9297d5ab-4014-44d4-91c8-a6d8927a0756",
"image_id": "1103689414850387968",
"image_url": "https://midjourney.cdn.zhishuyun.com/attachments/1100813695770165341/1103689414850387968/Azyern_Zieca_ignore9297d5ab-4014-44d4-91c8-a6d8927a0756_ec5cda5c-8784-4707-be17-a168786e0c8a.png",
"actions": [
"upsample1",
"upsample2",
"upsample3",
"upsample4",
"variation1",
"variation2",
"variation3",
"variation4"
]
}
这时候,我们可以看到就得到了类似的卡通风格的图片了:

异步回调
由于 Midjourney 生成图片需要等待一段时间,所以本 API 也相应设计为了长等待模式。但在部分场景下,长等待可能会带来一些额外的资源开销,因此本 API 也提供了异步 Webhook 回调的方式,当图片生成成功或失败时,其结果都会通过 HTTP 请求的方式发送到指定的 Webhook 回调 URL。回调 URL 接收到结果之后可以进行进一步的处理。
下面演示具体的调用流程。
首先,Webhook 回调是一个可以接收 HTTP 请求的服务,开发者应该替换为自己搭建的 HTTP 服务器的 URL。此处为了方便演示,使用一个公开的 Webhook 样例网站 https://webhook.site/,打开该网站即可得到一个 Webhook URL,如图所示:


将此 URL 复制下来,就可以作为 Webhook 来使用,此处的样例为 https://webhook.site/c62713a6-0487-45bd-9ad2-08a91d7ed12d。
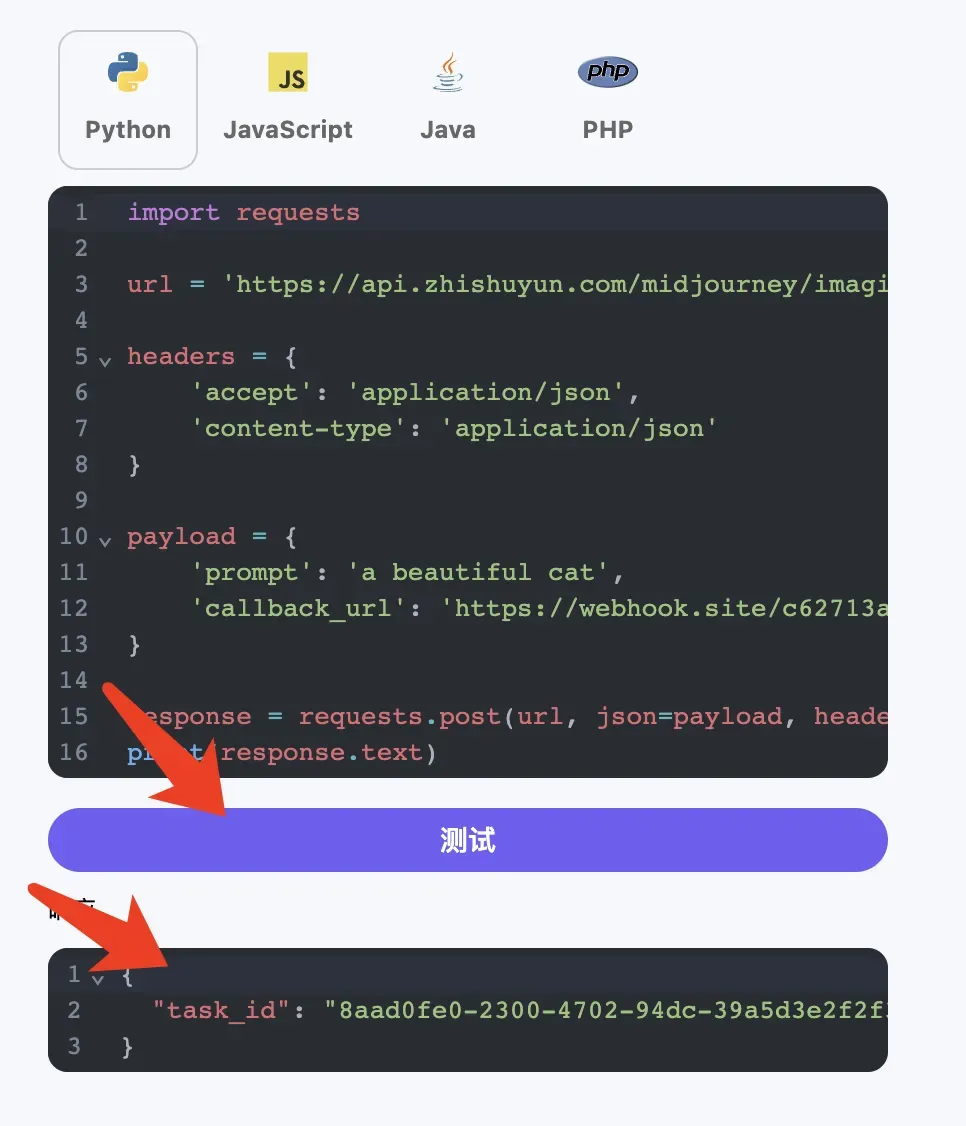
接下来,我们可以设置字段 callback_url 为上述 Webhook URL,同时填入 prompt,如图所示:


点击测试之后会立即得到一个 task_id 的响应,用于标识当前生成任务的 ID,如图所示:

稍等片刻,等图片生成结束,可以发发现 Webhook URL 收到了一个 HTTP 请求,如图所示:
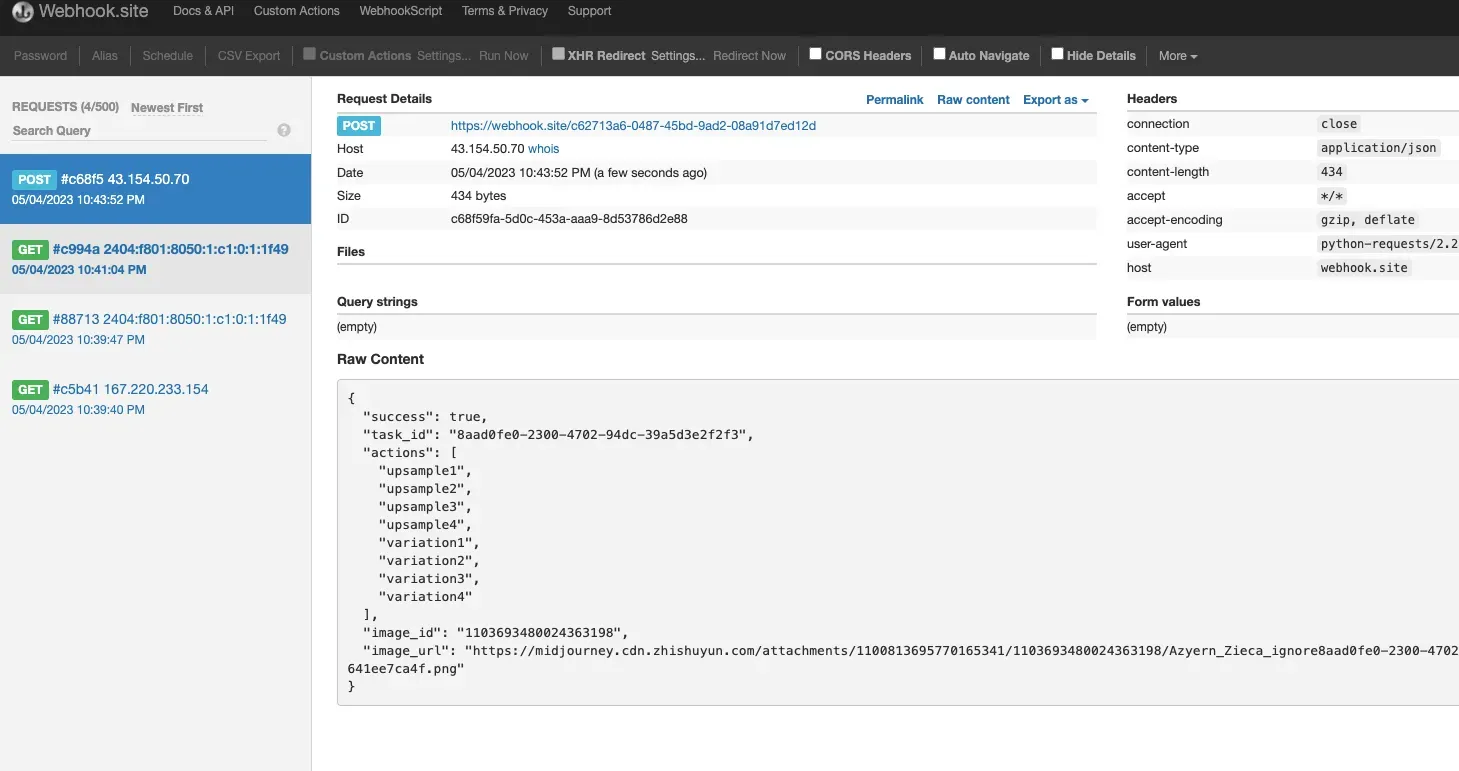

其结果就是当前任务的结果,内容如下:
{
"success": true,
"task_id": "8aad0fe0-2300-4702-94dc-39a5d3e2f2f3",
"actions": [
"upsample1",
"upsample2",
"upsample3",
"upsample4",
"variation1",
"variation2",
"variation3",
"variation4"
],
"image_id": "1103693480024363198",
"image_url": "https://midjourney.cdn.zhishuyun.com/attachments/1100813695770165341/1103693480024363198/Azyern_Zieca_ignore8aad0fe0-2300-4702-94dc-39a5d3e2f2f3_a_beaut_b3d5720a-b917-4a2d-b6e7-ae641ee7ca4f.png"
}
其中 success 字段标识了该任务是否执行成功,如果执行成功,还会有同样的 actions, image_id, image_url 字段,和上文介绍的返回结果是一样的,另外还有 task_id 用于标识任务,以实现 Webhook 结果和最初 API 请求的关联。
如果图片生成失败,Webhook URL 则会收到类似如下内容:
{
"success": false,
"task_id": "7ba0feaf-d20b-4c22-a35a-31ec30fc7715",
"code": "bad_request",
"detail": "Unrecognized argument(s): `-c`, `x`"
}
这里的 success 字段会是 false,同时还会有 code 和 detail 字段描述了任务错误的详情信息,Webhook 服务器根据对应的结果进行处理即可。
流式输出
Midjourney 官方在生成图片的时候是有进度的,在最开始是一张模糊的照片,然后经过几次迭代之后,图片逐渐变得清晰,最后得到完整的图片。
所以,一张图片的生成过程大约可以分为「发送命令」->「开始生图(多次迭代逐渐清晰)」->「生图完毕」的阶段。
在没开启流式输出的情况下,本 API 从发起请求到返回结果,实际上是从上述「发送命令」->「生图完毕」的全过程,中间生图的过程也全被包含在里面,由于 Midjourney 本身生成图片速度较慢,整个过程大约需要等待一分钟或更久。
所以为了更好的用户体验,本 API 支持流式输出,即当「开始生图」的时候就开始返回结果,每当绘制进度有变化,就会流式将结果输出,直至生图结束。
如果想流式返回响应,可以更改请求头里面的 accept 参数,修改为 application/x-ndjson,不过调用代码需要有对应的更改才能支持流式响应。
Python 样例代码:
import requests
url = 'https://api.zhishuyun.com/midjourney/imagine?token={token}'
headers = {
'content-type': 'application/json',
'accept': 'application/x-ndjson'
}
body = {
"prompt": "a beautiful cat",
"action": "generate"
}
r = requests.post(url, headers=headers, json=body, stream=True)
for line in r.iter_lines():
print(line.decode())
运行结果:
{"image_id":"1112780200447578272","image_url":"https://midjourney.cdn.zhishuyun.com/attachments/1111955518269948007/1112780200447578272/grid_0.webp","actions":[],"progress":0}
{"image_id":"1112780227496640635","image_url":"https://midjourney.cdn.zhishuyun.com/attachments/1111955518269948007/1112780227496640635/grid_0.webp","actions":[],"progress":15}
{"image_id":"1112780238934523994","image_url":"https://midjourney.cdn.zhishuyun.com/attachments/1111955518269948007/1112780238934523994/grid_0.webp","actions":[],"progress":31}
{"image_id":"1112780254398918716","image_url":"https://midjourney.cdn.zhishuyun.com/attachments/1111955518269948007/1112780254398918716/grid_0.webp","actions":[],"progress":46}
{"image_id":"1112780265933262858","image_url":"https://midjourney.cdn.zhishuyun.com/attachments/1111955518269948007/1112780265933262858/grid_0.webp","actions":[],"progress":62}
{"image_id":"1112780280965648394","image_url":"https://midjourney.cdn.zhishuyun.com/attachments/1111955518269948007/1112780280965648394/grid_0.webp","actions":[],"progress":78}
{"image_id":"1112780292621598860","image_url":"https://midjourney.cdn.zhishuyun.com/attachments/1111955518269948007/1112780292621598860/grid_0.webp","actions":[],"progress":93}
{"image_id":"1112780319758766080","image_url":"https://midjourney.cdn.zhishuyun.com/attachments/1111955518269948007/1112780319758766080/dawn97_ignore81c5c24e-ea94-4ae2-aee4-252a98a347ed_a_beautiful_c_e20c3bc8-8827-4c99-9cf5-7d56c2e9d47f.png","actions":["upsample1","upsample2","upsample3","upsample4","variation1","variation2","variation3","variation4"],"progress":100}
可以看到,启用流式输出之后,返回结果就是逐行的 JSON 了。在这里我们用 Python 里面的 iter_lines 方法自动获取了下一行的内容并打印出来。
如果要手动进行处理逐行 JSON 结果的话可以使用 \r\n 来进行分割。
例如在浏览器环境中,用 JavaScript 的 axios 库来实现手动处理,代码可改写如下:
axios({
url: 'https://api.zhishuyun.com/midjourney/imagine?token={token}',
data: {
prompt: 'a beautiful cat',
action: 'generate'
},
headers: {
'accept': 'application/x-ndjson',
'content-type': 'application/json'
},
responseType: 'stream',
method: 'POST',
onDownloadProgress: progressEvent => {
const response = progressEvent.target.response;
const lines = response.split('\r\n').filter(line => !!line)
const lastLine = lines[lines.length - 1]
console.log(lastLine)
}
}).then(({ data }) => Promise.resolve(data));
但注意在 Node.js 环境中,实现稍有不同,代码可写为如下:
const axios = require('axios');
const url = 'https://api.zhishuyun.com/midjourney/imagine?token={token}';
const headers = {
'Content-Type': 'application/json',
'Accept': 'application/x-ndjson'
};
const body = {
prompt: 'a beautiful cat',
action: 'generate'
};
axios.post(url, body, { headers: headers, responseType: 'stream' })
.then(response => {
console.log(response.status);
response.data.on('data', chunk => {
console.log(chunk.toString());
});
})
.catch(error => {
console.error(error);
});
Java 样例代码:
import okhttp3.*;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
public static void main(String[] args) {
String url = "https://api.zhishuyun.com/midjourney/imagine?token={token}";
OkHttpClient client = new OkHttpClient();
MediaType mediaType = MediaType.parse("application/json");
RequestBody body = RequestBody.create(mediaType, "{\"prompt\": \"a beautiful cat\"}");
Request request = new Request.Builder()
.url(url)
.post(body)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/x-ndjson")
.build();
client.newCall(request).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
e.printStackTrace();
}
@Override
public void onResponse(Call call, Response response) throws IOException {
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
try (BufferedReader br = new BufferedReader(
new InputStreamReader(response.body().byteStream(), "UTF-8"))) {
String responseLine;
while ((responseLine = br.readLine()) != null) {
System.out.println(responseLine);
}
}
}
});
}
}
运行结果都是类似的。
另外注意到,流式输出的结果多了一个字段叫做 progress,这个代表绘制进度,范围是 0-100,如果需要,您也可以在页面展示这个信息。
注意:当绘制未完全完成的时候,
actions字段是空,即无法对中间过程的图片做进一步的处理操作。绘制完毕之后,绘制过程中产生的image_url会被销毁。另外异步回调可以和流式输出一起使用。
好了,通过以上内容介绍,我们就了解了知数云 Midjourney API 的使用方法,有了这个 API,我们可以包装自己的产品,实现和官方 Midjourney 一模一样的对接。
套餐介绍
到了最后,大家可能好奇,这个价格套餐式怎样的情况呢?
知数云对上文介绍的 API 提供了三种套餐,分别是快速、慢速、极速模式,介绍如下:
- 快速:背后的 Midjourney 账号均是 Fast 模式,能够以快速模式出图,正常情况下绘制完整图片时间在 1 分钟左右,开启流式模式会更快。
- 慢速:背后的 Midjourney 账号均是 Relax 模式,生成速度无任何保证,快的话可能 1 分钟,慢的话可能甚至 10 分钟,适合对速度要求较低的用户。
- 极速:背后的 Midjourney 账号军事 Turbo 模式,生成速度比快速模式更快,正常情况下绘制完整图片时间在 30 秒左右,开启流式模式会更快。适合对速度要求极高的用户。
价格怎么样呢?由于价格可能会动态变化,大家可以直接参考知数云的官方网站了解:https://data.zhishuyun.com/services/d87e5e99-b797-4ade-9e73-b896896b0461。但总的来说,能够以这个价格做到知数云 Midjourney API 这样的稳定性和并发的,业界寥寥无几,欢迎选购和评测。
谢谢!
文章出处登录后可见!