

线性表的链式表示
- 导言
- 一、链式存储
- 二、单链表
-
- 1.1 单链表的定义
- 1.2 单链表节点的创建
- 1.3 单链表的头指针与头结点
-
- 1.3.1 头指针与头结点的区别
- 1.3.2 头结点的优点
- 1.4 单链表的初始化
-
- 1.4.1 不带头结点的初始化
- 1.4.2 带头结点的初始化
- 结语


导言
大家好,很高兴又和大家见面啦!!!
在前面的内容中我们介绍了线性表的第一种存储方式——顺序存储,相信大家经过前面的学习应该已经掌握了对顺序表的一些基本操作了。今天,我们将开始介绍线性表的第二种存储方式——链式存储。
一、链式存储
线性表中的数据元素在存储时,其逻辑顺序与物理位置都相邻的存储方式,我们称其为顺序存储,又称为顺序表;
当线性表中的数据元素在存储时,只满足逻辑上相邻,但是物理位置上可以不相邻时,我们称其为链式存储,又称为链表。如下图所示:
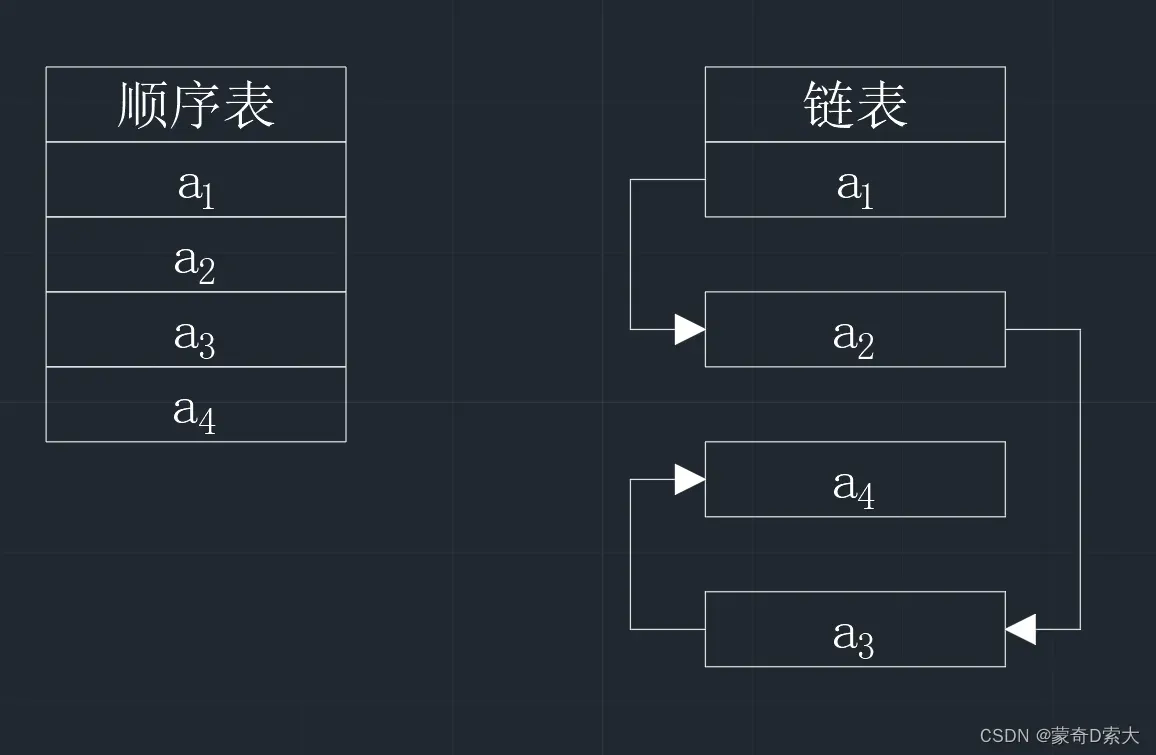
顺序存储的优点是可以做到顺序表中的数据元素可以进行随机存储,所以它又是一种随机存取的存储结构;但是它的缺点是需要再内存中申请一块连续的存储空间,而且在进行空间大小的修改时不方便,并且在插入和删除元素时需要进行元素的移动。

链式存储则优化了这个缺点,链表中的数据元素并不需要物理位置上相邻,所以在内存中不需要通过申请连续的空间进行存放,而且不需要在插入或删除元素时调整元素的物理位置;但是它的缺点是需要消耗额外的空间来单独存放指向其它元素的指针。
链表根据存放的指针数量不同又分为单链表与双链表,下面我们就来介绍一下单链表的基本概念与基础操作。
二、单链表
1.1 单链表的定义
线性表的链式存储又称为单链表。它是指通过一组任意的存储单元来存储线性表中的数据元素。为了建立数据元素之间的线性关系,对链表的每个结点,除存放元素自身的信息外,还需要存放一个指向其后继结点的指针。
1.2 单链表节点的创建
链表在内存中是通过一个个结点构成的,单链表的结点分为两部分:
- date——数据域,存放数据元素;
- next——指针域,存放其后继结点的地址;
结构如下图所示:


下面我们就来通过C语言来描述一下单链表的结点:
//单链表结点的C语言描述
typedef struct LNode//定义单链表的结点类型
{
ElemType data;//数据域
struct LNode* next;//指针域
}LNode,*LinkList;//将结点类型重命名为LNode,将单链表类型重命名为LinkList
//LNode——强调的是结点
//LinkList——强调的是链表
注:由于链表中的结点数据类型相同,所以结点的数据类型也就代表着链表的数据类型,在后续的基本操作中,我们为了更好的区分此时引用的是整个链表还是单个结点,这里我们将单链表的结点类型重命名为
LNode,将其指针类型重命名为LinkList,这样我们在后续的操作中就可以通过LNode与LinkList这两个名字来更好的区分结点与链表。
因为单链表的各个元素时离散的分布在内存中,所以单链表不能像顺序表一样做到随机存取,因此单链表是一个非随机存取的存储结构,即不能直接找到表中某个特定的节点。在查找某个特定的结点时,需要从表头开始遍历,依次查找。
1.3 单链表的头指针与头结点
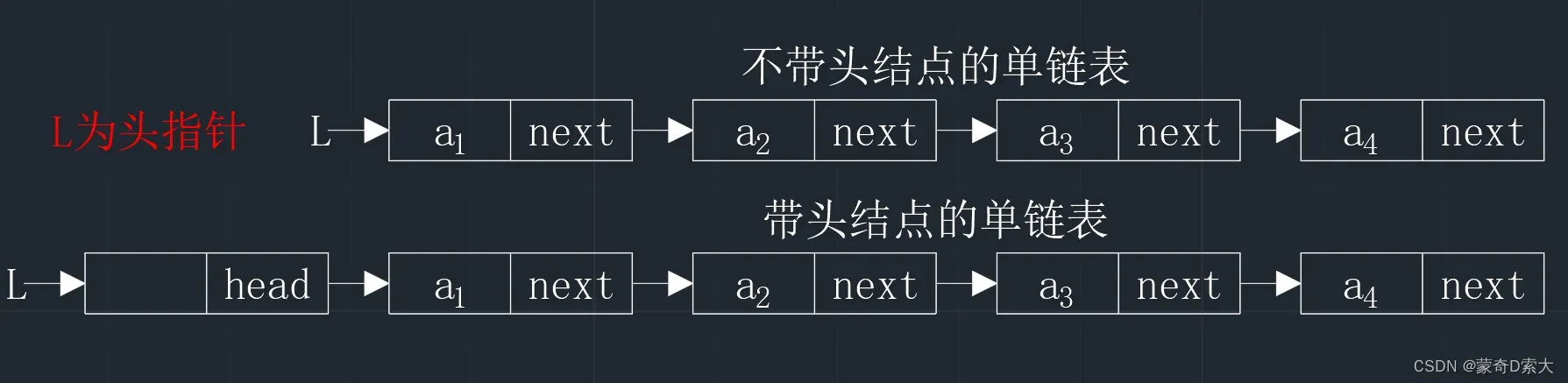
因为单链表都是由一个个结点组成,所以我们通常将指向单链表的指针称为头指针,头指针指向的是单链表中的第一个结点,当头指针为空指针NULL时,表示的是一个空表。
此外,为了操作上的方便,我们还可以在单链表的第一个结点之前附加一个不需要存储任何数据的结点,这个结点我们将它称为头结点。头结点的数据域可以存储表长等信息,也可以不存储任何信息,头结点的指针域指向的是链表中的第一个元素结点。如下图所示:

1.3.1 头指针与头结点的区别
- 性质不同
- 头指针是指向链表第一个结点的指针;
- 头结点是链表的第一个结点;
- 存储内容不同
- 不管链表带不带头结点,头指针存储的始终是链表第一个结点的地址;
- 带头结点的链表中,头结点的数据域可以存储表长等信息,也可以不存储,指针域存储的是下一个结点的地址,即链表中第一个元素的地址;
1.3.2 头结点的优点
引入头结点后,可以带来两个优点:
- 由于第一个数据节点的位置被存放在头结点的指针域中,因此在链表的第一个位置上的操作和在表的其它位置上的操作一致,无需进行特殊处理;
- 无论链表是否为空,其头指针都是指向头结点的非空指针,因此空表和非空表的处理也就得到了统一。
注:当链表为空表时,头指针指向的是头结点,而头结点的指针域为空指针。
接下来我们来看一下带头结点的单链表与不带头结点的单链表它们的初始化有什么区别。
1.4 单链表的初始化
1.4.1 不带头结点的初始化
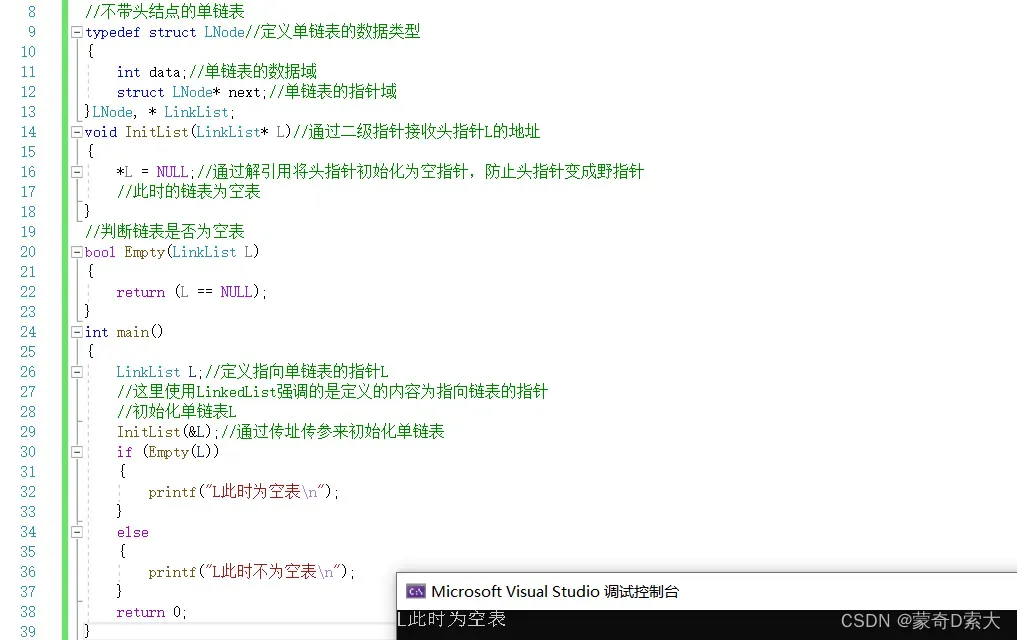
对于不带头结点的单链表来说,我们在进行初始化时,头指针指向的是NULL即空指针,如下所示:
//不带头结点的单链表
typedef struct LNode//定义单链表的数据类型
{
int data;//单链表的数据域
struct LNode* next;//单链表的指针域
}LNode, * LinkList;
void InitList(LinkList* L)//通过二级指针接收头指针L的地址
{
*L = NULL;//通过解引用将头指针初始化为空指针,防止头指针变成野指针
//此时的链表为空表
}
int main()
{
LinkList L;//定义指向单链表的指针L
//这里使用LinkedList强调的是定义的内容为指向链表的指针
//初始化单链表L
InitList(&L);//通过传址传参来初始化单链表
return 0;
}
当然,我们也可以在初始化完了之后对这个链表进行判断,看看它是否为空表,如下所示:
为了提高代码的健壮性,我们还可以在初始化之后给函数一个返回值,用来告知现在已经完成了初始化,如下所示:

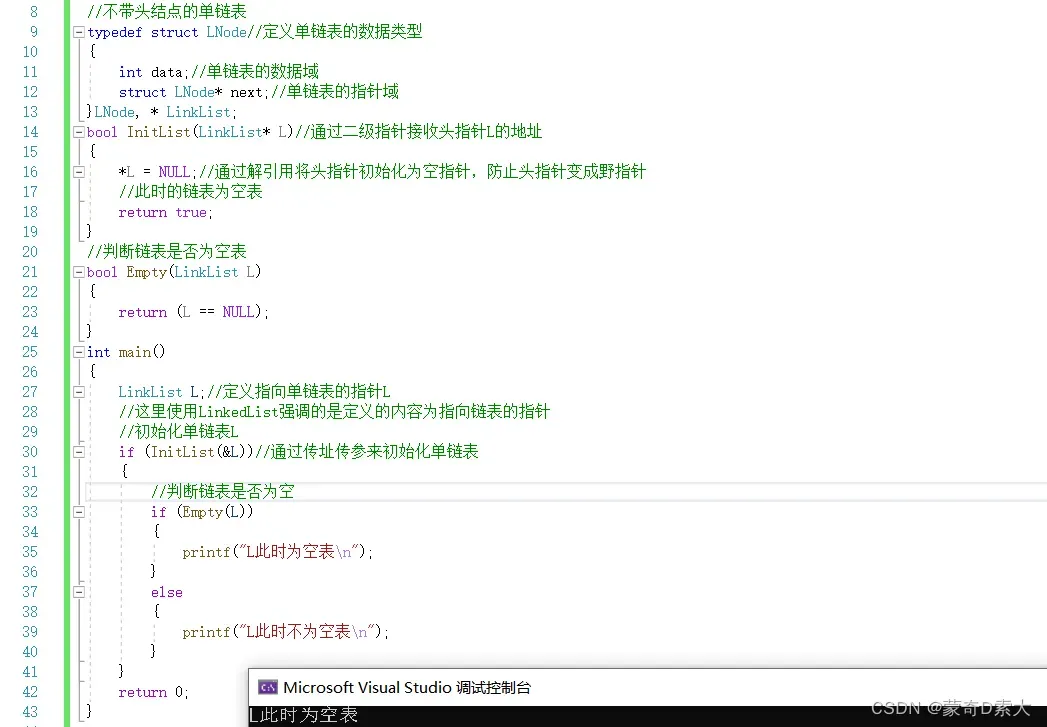
像这样修改后,我们就能更加清楚的知道此时是否成功进行了初始化。

1.4.2 带头结点的初始化
当我们需要创建一个带头结点的单链表时,我们就不能直接将头指针初始化为空指针,而是应该先让头指针指向头结点,再将头结点的指针域初始化为空指针。如下所示:
//带头结点的单链表
typedef struct LNode//定义单链表的数据类型
{
int data;//单链表的数据域
struct LNode* next;//单链表的指针域
}LNode, * LinkList;
bool InitList(LinkList* L)//通过二级指针接收头指针L的地址
{
//通过calloc向内存申请一块空间
*L = (LNode*)calloc(1, sizeof(LNode));
//这里不能直接通过L来接收申请的空间的起始地址,L此时是一个二级指针,我们需要先对其解引用
//这里使用LNode*来表示此时申请的是结点的空间
if (!(*L))//通过逻辑反操作,判断空间是否申请失败
//!的优先级高于*,此时我们需要先通过括号让*与二级指针结合,再对其进行逻辑反操作
return false;//当空间申请失败时,头指针为空指针,此时返回false
(*L)->next = NULL;//当空间申请成功时,将头结点的指针域初始化为空指针
//->的优先级高于*,此时我们需要通过括号先让*与二级指针L结合,再对其进行指向结构体成员
return true;
}
int main()
{
LinkList L;//定义指向单链表的指针L
//这里使用LinkedList强调的是定义的内容为指向链表的指针
//初始化单链表L
InitList(&L);//通过传址传参来初始化单链表
return 0;
}
现在我们就能很直观的感受到使用LinkList与LNode这两个名字的区别了:
LinkList强调的是整个链表;LNode强调的是单个结点;
注:这里一定要注意我们通过
LinkList定义的L是一个指针类型,我们在对L进行初始化时,需要通过传址传参,函数需要使用二级指针来接收,所以是LinkList*。
这时我们需要通过解引用才能对L进行初始化;
我们需要通过L来访问结构体成员时,也需要对其进行解引用。
我们如果相对带头结点的链表进行判空操作的话,就不是直接对头指针L进行判空操作,而是对头结点的指针域进行判空操作,如下所示:
//判断链表是否为空表
bool Empty(LinkList L)
{
return (L->next == NULL);
//这里同样可以通过逻辑反操作来进行判空
return (!L->next);
//根据操作符的优先级->的优先级高于!,所以不需要使用括号
}
int main()
{
LinkList L;//定义指向单链表的指针L
//这里使用LinkedList强调的是定义的内容为指向链表的指针
//初始化单链表L
if (InitList(&L))//通过传址传参来初始化单链表
{
//判断链表是否为空
if (Empty(L))
{
printf("L此时为空表\n");
}
else
{
printf("L此时不为空表\n");
}
}
return 0;
}
通过这两种链表初始化的对比,我们可以更直观的看到带头结点与不带头结点的区别。因此为了方便我们后面的操作,在后续的介绍中,我都会以带头结点的链表来进行介绍,同时也希望大家能够多使用带头结点的链表。
结语
今天的内容到这里就结束了,我们今天重点介绍了带头结点的单链表与不带头结点的单链表之间的区别。希望大家在阅读完这篇内容后,能够更好的理解这两种形式的单链表,在下一篇内容中,我会继续给大家介绍单链表的一些基本操作,大家记得关注哦!
最后,感谢大家的翻阅,咱们下一篇再见!!!
版权声明:本文为博主作者:蒙奇D索大原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/2301_79458548/article/details/135220889