

stable diffusion webui 安装与入门
- 原理简介
- 一、源码仓库
- 二、模型库地址
- 三、在 Windows 上自动安装步骤
-
- 安装Python
- 安装git
- 下载源代码
- 编辑 webui-user.bat
- 四、如何打开
- 五、依据文字生成图片
- 六、API在哪里?
- 七、用python调用API接口示例
- 八、如何制作生成精美的图片
-
- 1、下载模型
- 2、参考(抄袭)别人的提示词
- 九、如何使用模型
-
- 1. LoRA 是什么?
- 2. LoRA 目录
原理简介
Stable diffusion是一种用于图像处理的算法,主要用于处理图像中的噪声问题。该算法的源代码和实现可以根据不同的编程语言和库进行实现,以下是对Python中使用的源代码进行分析:
1.导入库和模块
import numpy as np
import cv2
该算法主要使用了NumPy和OpenCV库,前者是Python中用于数值计算的基础库,后者是用于计算机视觉的著名库。在代码中,我们还需要使用NumPy中的一些数组操作和OpenCV中的图像操作。
2.定义函数
def stable_diffusion_filter(img, k=0.1, t=50, sigma=10):
filtered_img = img.astype(np.float32)
for i in range(t):
dx = cv2.Sobel(filtered_img, cv2.CV_32F, 1, 0, ksize=3)
dy = cv2.Sobel(filtered_img, cv2.CV_32F, 0, 1, ksize=3)
dxx = cv2.Sobel(dx, cv2.CV_32F, 1, 0, ksize=3)
dyy = cv2.Sobel(dy, cv2.CV_32F, 0, 1, ksize=3)
dxy = cv2.Sobel(dx, cv2.CV_32F, 0, 1, ksize=3)
dxy2 = cv2.Sobel(dy, cv2.CV_32F, 1, 0, ksize=3)
num = dxx * dyy - dxy * dxy2
den = dxx + dyy + sigma
filtered_img += k * num / den
return filtered_img
该函数是对图像进行稳定扩散滤波的主体部分。该函数使用了图像的梯度信息进行计算,并根据梯度的变化对图像进行滤波。在这个函数中,我们需要指定一些参数,如滤波器系数k、迭代次数t以及平滑参数sigma。
在函数中,我们首先将输入的图像转换为浮点数数组,这样我们可以进行计算。然后,我们迭代t次,每次使用Sobel算子计算图像的x和y方向的梯度,并使用这些梯度计算x和y方向的二阶导数dxx和dyy,以及混合导数dxy和dxy2。使用这些导数,我们计算了一个num和den的值,并使用它们来更新过滤图像。最后,我们返回滤波后的图像。
3.调用函数
img = cv2.imread('input.jpg')
filtered_img = stable_diffusion_filter(img)
cv2.imwrite('output.jpg', filtered_img)
在调用该函数之前,我们需要首先读入输入图像。这可以通过OpenCV库中的imread函数实现。然后,我们调用stable_diffusion_filter函数对图像进行滤波,并将结果保存到一个变量中。最后,我们使用OpenCV中的imwrite函数将滤波后的图像保存到磁盘中。Stable diffusion是一种用于图像处理的算法,主要用于处理图像中的噪声问题。该算法的源代码和实现可以根据不同的编程语言和库进行实现,以下是对Python中使用的源代码进行分析:
1.导入库和模块
import numpy as np
import cv2
该算法主要使用了NumPy和OpenCV库,前者是Python中用于数值计算的基础库,后者是用于计算机视觉的著名库。在代码中,我们还需要使用NumPy中的一些数组操作和OpenCV中的图像操作。
2.定义函数
def stable_diffusion_filter(img, k=0.1, t=50, sigma=10):
filtered_img = img.astype(np.float32)
for i in range(t):
dx = cv2.Sobel(filtered_img, cv2.CV_32F, 1, 0, ksize=3)
dy = cv2.Sobel(filtered_img, cv2.CV_32F, 0, 1, ksize=3)
dxx = cv2.Sobel(dx, cv2.CV_32F, 1, 0, ksize=3)
dyy = cv2.Sobel(dy, cv2.CV_32F, 0, 1, ksize=3)
dxy = cv2.Sobel(dx, cv2.CV_32F, 0, 1, ksize=3)
dxy2 = cv2.Sobel(dy, cv2.CV_32F, 1, 0, ksize=3)
num = dxx * dyy - dxy * dxy2
den = dxx + dyy + sigma
filtered_img += k * num / den
return filtered_img
该函数是对图像进行稳定扩散滤波的主体部分。该函数使用了图像的梯度信息进行计算,并根据梯度的变化对图像进行滤波。在这个函数中,我们需要指定一些参数,如滤波器系数k、迭代次数t以及平滑参数sigma。
在函数中,我们首先将输入的图像转换为浮点数数组,这样我们可以进行计算。然后,我们迭代t次,每次使用Sobel算子计算图像的x和y方向的梯度,并使用这些梯度计算x和y方向的二阶导数dxx和dyy,以及混合导数dxy和dxy2。使用这些导数,我们计算了一个num和den的值,并使用它们来更新过滤图像。最后,我们返回滤波后的图像。
3.调用函数
img = cv2.imread('input.jpg')
filtered_img = stable_diffusion_filter(img)
cv2.imwrite('output.jpg', filtered_img)
在调用该函数之前,我们需要首先读入输入图像。这可以通过OpenCV库中的imread函数实现。然后,我们调用stable_diffusion_filter函数对图像进行滤波,并将结果保存到一个变量中。最后,我们使用OpenCV中的imwrite函数将滤波后的图像保存到磁盘中。
一、源码仓库
https://github.com/AUTOMATIC1111/stable-diffusion-webui
二、模型库地址
https://civitai.com/
三、在 Windows 上自动安装步骤
会linux基本上都懂得用github仓库,本指南主要面向小白,所以以windows为主。
安装Python
- 安装 Python 3.10.6 , 并检查 python 是否添加进全局变量.
安装git
安装 git.
下载源代码
运行 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git.
编辑 webui-user.bat
下载完之后,进入stable-diffusion-webui目录
@echo off
set PYTHON= { 这里填上你的python的真实地址 }\python.exe
set http_proxy= {这里填上你的vpn的地址}
set https_proxy= {这里填上你的vpn的地址}
set GIT=
set VENV_DIR=
REM 如果没有显卡就加上 --no-half --skip-torch-cuda-test,如果要开通API功能就加上 --api
set COMMANDLINE_ARGS= --no-half --skip-torch-cuda-test --api
git pull
call webui.bat
四、如何打开
- 双击运行 webui-user.bat
- 启动后就会开始执行python的本地服务器,并监听7860 端口,所以浏览器打开:
http://127.0.0.1:7860即可。
五、依据文字生成图片
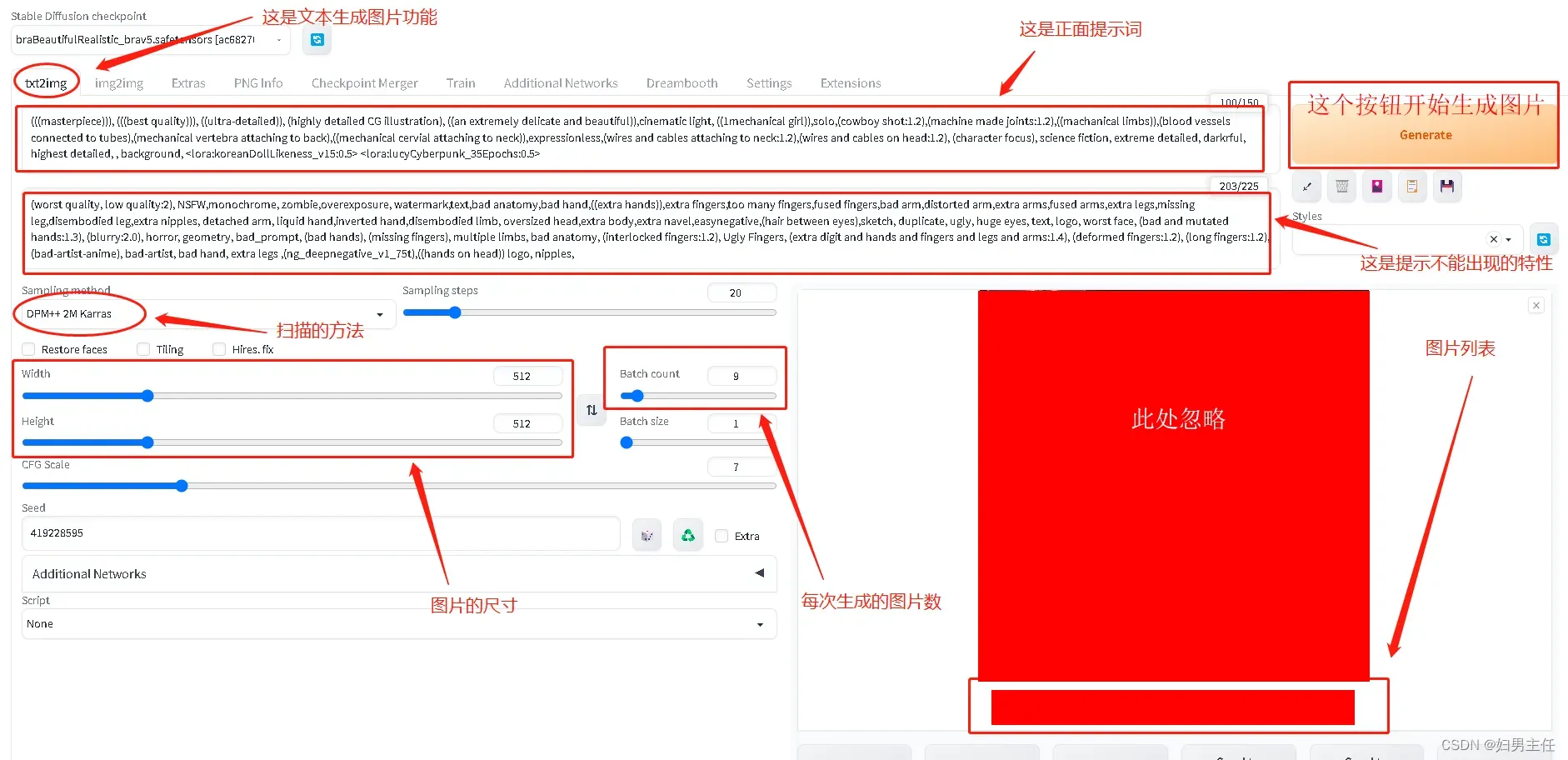

六、API在哪里?
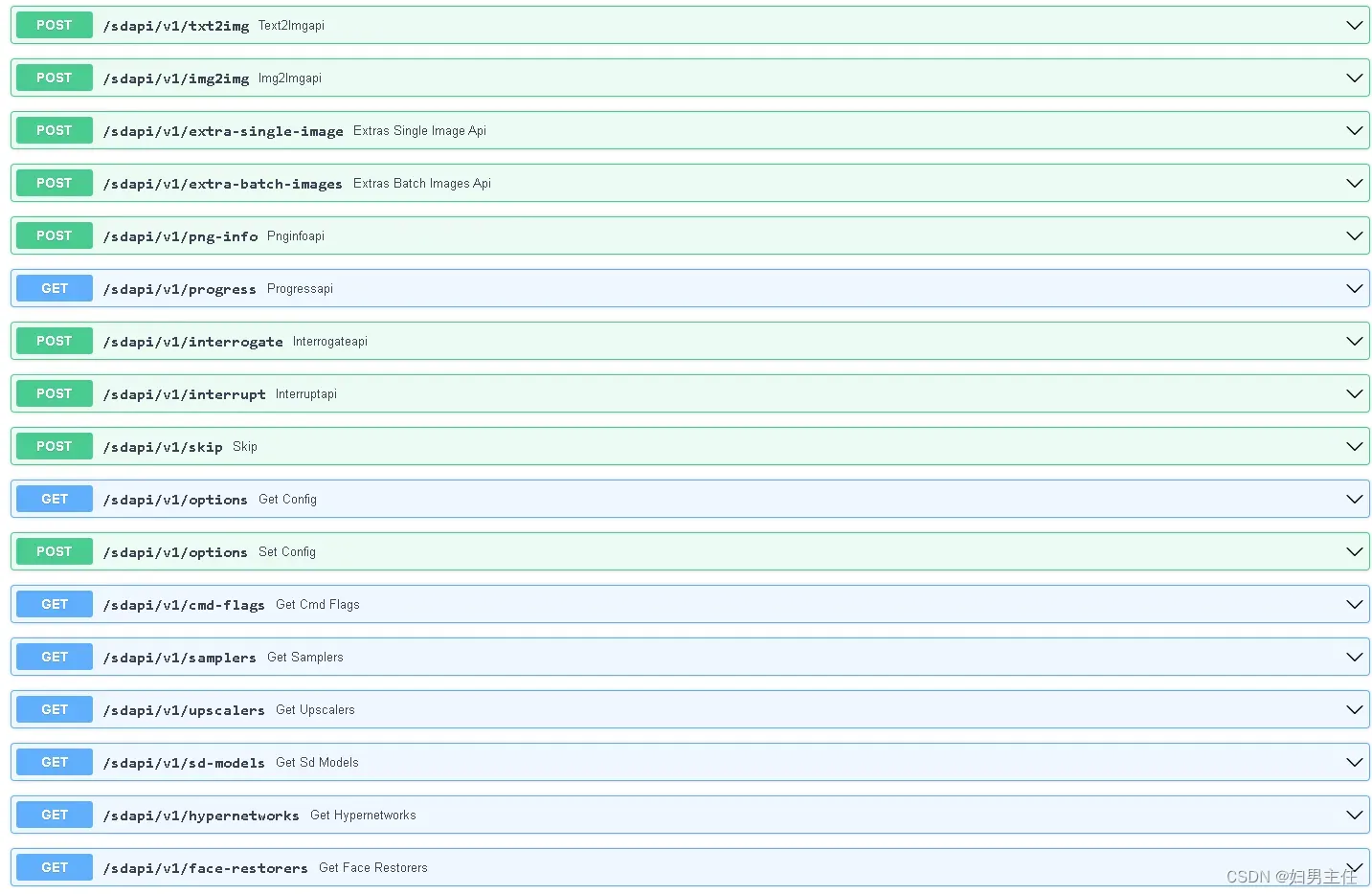
打开链接:http://127.0.0.1:7860/docs
这里面会有接口列表。
以 sdapi 开头的都是可使用的接口。

七、用python调用API接口示例
import requests
url = "http://127.0.0.1:7860"
payload = {
"prompt": "puppy dog",
"steps": 5
}
response = requests.post(url=f'{url}/sdapi/v1/txt2img', json=payload)
r = response.json()
print(r)
八、如何制作生成精美的图片
1、下载模型
因为模型是别人反复调试配备好的模板,生成的图片质量比较上乘
2、参考(抄袭)别人的提示词
除了模型,还要加上成熟的提示词,(要求英文的)这样才能进行精确的微调与操作
注意事项:生成的图片是比较随机的,所以可以一次性生成多张,方便挑选。
如果没有显卡的话,生成的速度会比较慢。建议加上显卡。
九、如何使用模型
为了让生成的图片更加好看,我们需要使用别人已经训练好的模型。
1. LoRA 是什么?
LoRA[^1],英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术。
比如,GPT-3有1750亿参数,为了让它能干特定领域的活儿,需要做微调,但是如果直接对GPT-3做微调,成本太高太麻烦了。
LoRA的做法是,冻结预训练好的模型权重参数,然后在每个Transformer(Transforme就是GPT的那个T)块里注入可训练的层,由于不需要对模型的权重参数重新计算梯度,所以,大大减少了需要训练的计算量。
LoRA的微调质量与全模型微调相当。要做个比喻的话,就好比是大模型的一个小模型,或者说是一个插件。
2. LoRA 目录
路径:stable-diffusion-webui\models\Lora
下载完的 LoRA 文件,直接拷贝到这个目录即可。
先试着生成图片,后续再一步步生成精致的图片.
[^1] https://zhuanlan.zhihu.com/p/610031713
版权声明:本文为博主作者:妇男主任原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_46596227/article/details/130651729