




📢 人社部:2022年第二季度全国招聘大于求职『最缺工』的100个职业排行
http://www.mohrss.gov.cn/SYrlzyhshbzb/dongtaixinwen/buneiyaowen/rsxw/202207/t20220722_478921.html
7月份发布了2022年Q2人力资源市场供求关系较为紧张的招聘、求职岗位信息,形成了这份『最缺工』的100个职业排行。本期数据来源于全国102个定点监测城市公共就业服务机构填报的人力资源市场招聘、求职数据。
从排行可以看出,制造业缺工状况持续,电子信息产业缺工情况较为突出,更多新职业被收集进入排行榜。其中,集成电路工程技术人员、工业机器人系统操作员、半导体芯片制造工、 人工智能工程技术人员、电子仪器与电子测量工程技术人员等职业进入排行,说明存在用工缺口。


工具&框架
🚧 『rs-code-visualizer』伪代码生成大幅可视化图
https://github.com/sloganking/codevis
codevis 将一个文件夹中的所有源代码 / UTF-8 编码的文件,渲染成一个大图像,并且它会进行语法高亮显示。大家可以把这些图像视作缩略图,它帮助你了解代码文件的形状和大小,但不显示文件内的确切字符。

🚧 『Visual Taste Approximator (VTA)』自画像工具,绘制像又不完全像的自己
https://github.com/SelfishGene/visual_taste_approximator
Visual Taste Approximator(VTA)是一个非常简单的工具,它可以帮助任何人创建一个自己的照片形象,一个可以近似他们自己但又包含独特视觉品味的人物形象。它可以通过标记一些图像,然后训练一个机器学习模型来模仿完成这个任务。
这个工具被开发并广泛用于创建合成脸部高质量数据集(Synthetic Faces High Quality (SFHQ))。对应的示例还展示了它是如何被用作为stable diffusion模型(文本提示到图像生成)构建大量图像语料库的。

🚧 『tsai』基于Pytorch & fastai的深度学习时序处理库
https://github.com/timeseriesAI/tsai
https://timeseriesai.github.io/tsai/
tsai 是一个由 timeseriesAI 构建,建立在 Pytorch 和 fastai 之上的开源深度学习包,专注于最先进的时间序列任务的技术,如分类、回归、预测、归因等,更多高级功能正在积极开发中。

🚧 『Stable Diffusion WebUI Docker』基于Docker带Web界面方便部署的Stable Diffusion
https://github.com/AbdBarho/stable-diffusion-webui-docker
Stable Diffusion WebUI Docker 提供了多个漂亮的用户界面,让你在电脑上稳定运行 Stable Diffusion 模,基于提示创作非常多的 AI 艺术绘画。
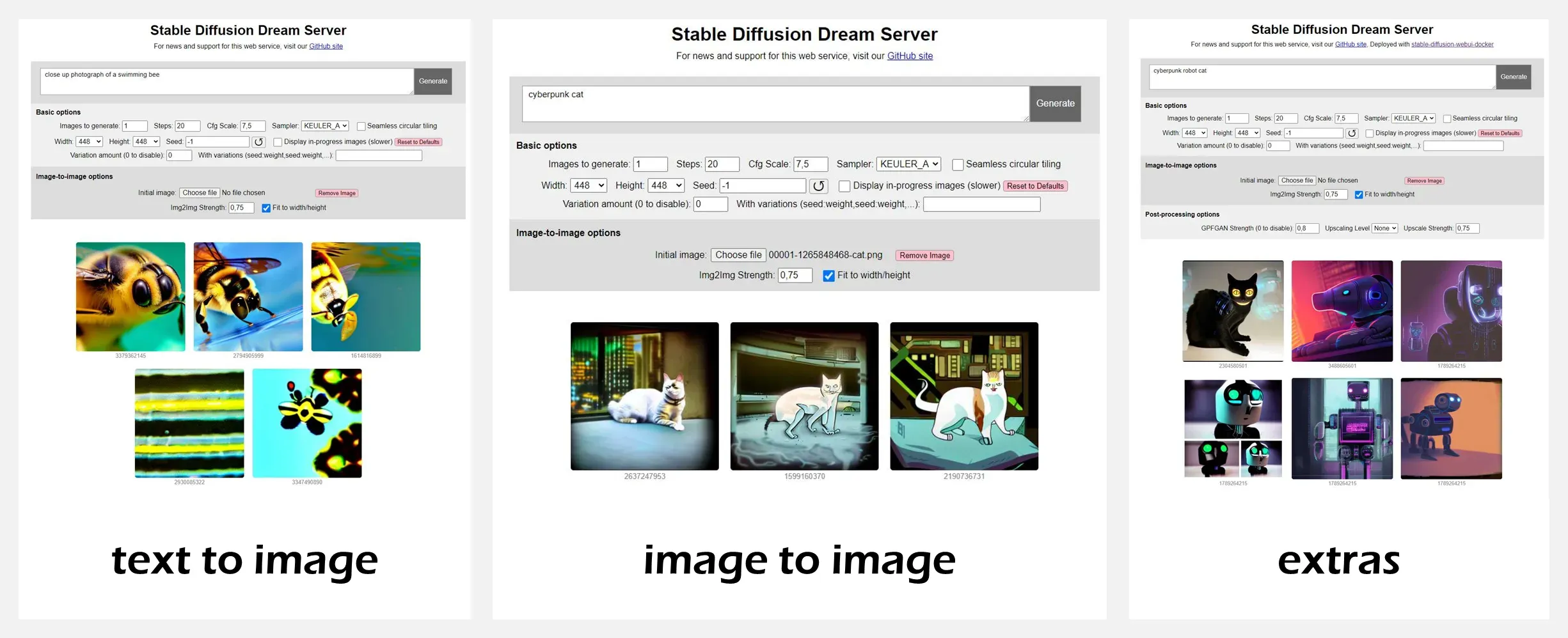

🚧 『Scholar』构建在Nx基础上的机器学习工具
https://github.com/elixir-nx/scholar
Scholar是一个构建在Nx基础上的机器学习工具。
博文&分享
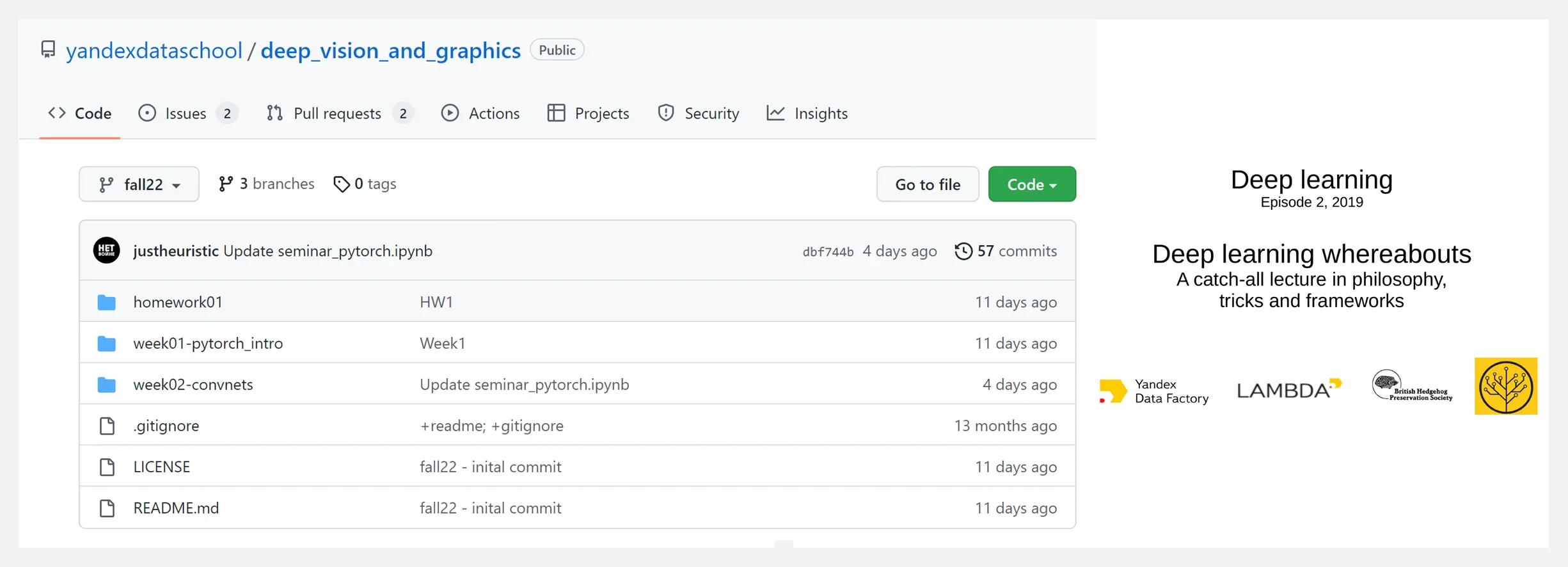
👍 『Deep Vision and Graphics』深度视觉与图形·课程资料
https://github.com/yandexdataschool/deep_vision_and_graphics
这是一门由 YSDA 和 Skoltech 共同开发的2022年度深度学习课程,聚焦计算机视觉和图形。其中,YSDA 全称 Yandex School of Data Analysis,是一个数据技能学习平台。
课程资料在 GitHub 子文件夹中,各内容主题为:
- 简介、神经网络基础知识回顾、优化、反向传播、生物网络
- 图像、线性过滤、卷积网络、batchnorms、增强
- ConvNet网络架构、3D稀疏卷积、视频卷积网络、迁移学习
- 密集预测:语义分割、超分辨率/图像合成、感知损失
- 非卷积架构:transformer、混合器、FFT 卷积
- 可视化和理解深层架构、对抗性示例
- 对象检测、实例/全景分割、2D/3D人体姿态估计
- 表示学习:人脸识别、验证任务、自我监督学习、图像字幕
- 生成对抗网络
- 潜在模型(GLO、AEs、VQ-VAE、生成变压器)
- 流动模型、扩散模型、生成变压器, CLIP, DALL-E
- 形状和运动估计:空间变换器、光流、立体、单深度、点云生成
- 新视图合成:多平面图像、神经辐射场、NVS 的基于网格和基于点的表示、神经渲染器
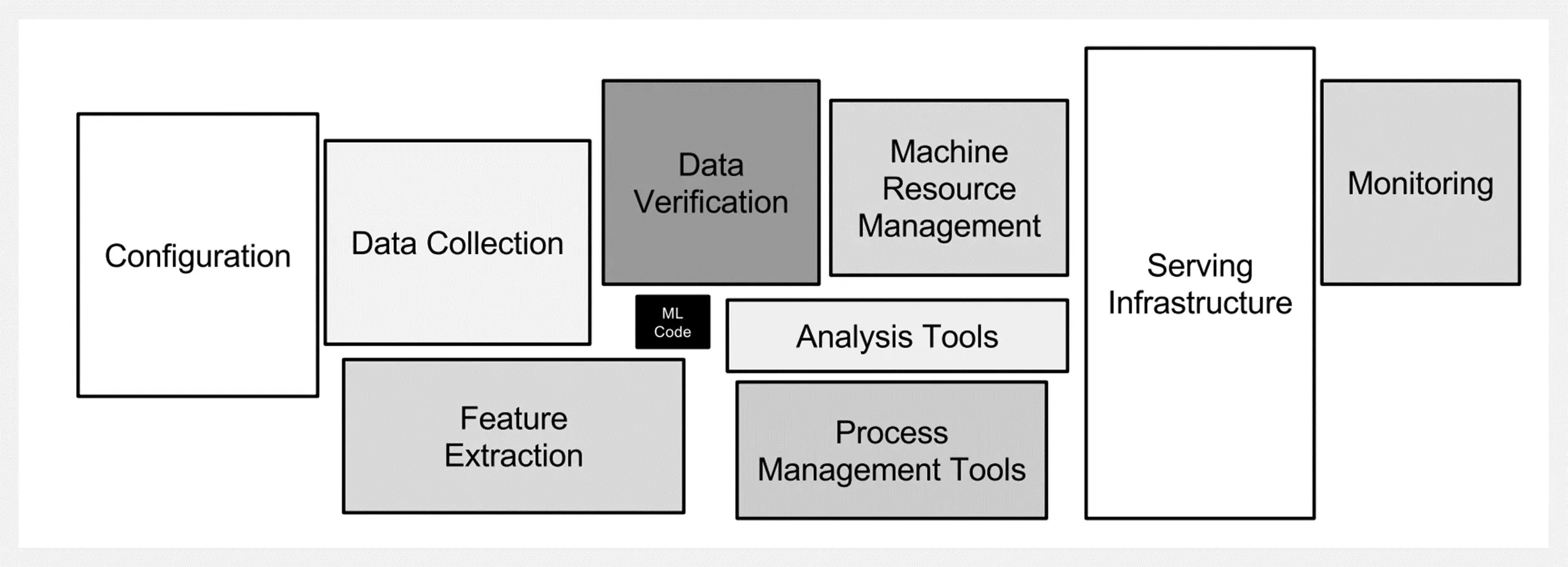
👍 『Machine Learning Systems versus Machine Learning Models』机器学习系统与机器学习模型
https://towardsdatascience.com/machine-learning-systems-versus-machine-learning-models-3955d038ea1f
一个正常运行的 AI 产品,除机器学习模型外,还有大量的其他部分,所有这些统称为机器学习系统。但时我们往往过于关注我们的模型,而忽略了其他部分。我们不应孤立地思考机器学习模型,而是将其视为动态机器学习系统的一部分。
作者将重视机器学习模型而忽略了系统生态的行为,命名为『Model-centric bias(以模型为中心的偏见)』,并阐述了这种偏见带来的负面影响。
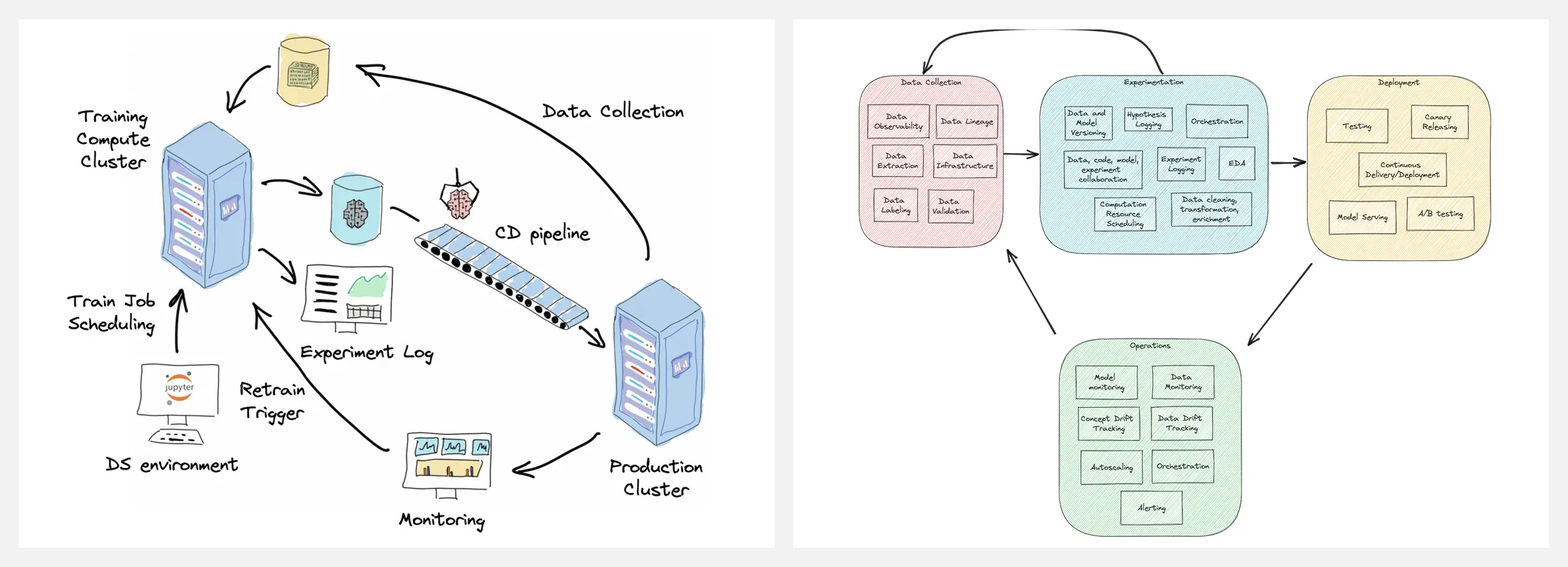
Machine Learning System(机器学习系统)
A Generic Value Stream Map of Machine Learning System(机器学习系统的通用价值流图)
Complexity map of Machine Learning Systems(机器学习系统的复杂图)
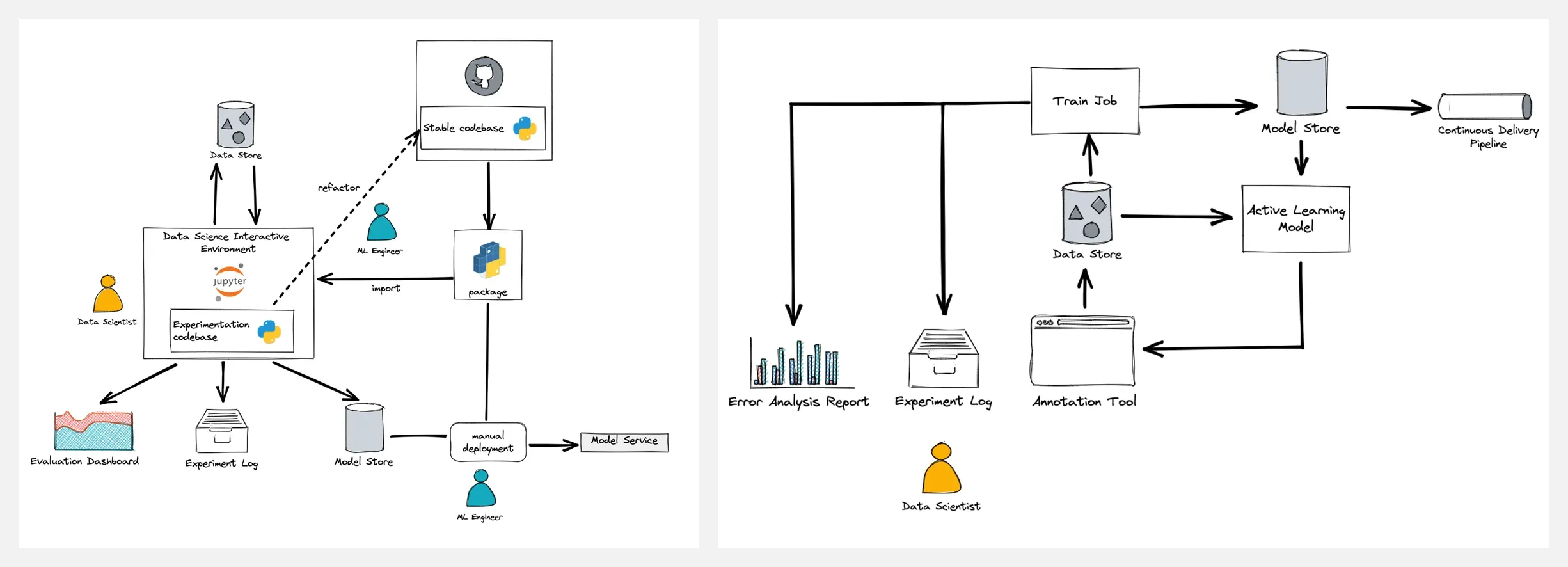
An example of a Machine Learning System for an early-stage PoC project(用于早期 PoC 项目的机器学习系统示例)
An example of a Machine Learning System utilizing the Active Learning approach(利用主动学习方法的机器学习系统示例)
数据&资源
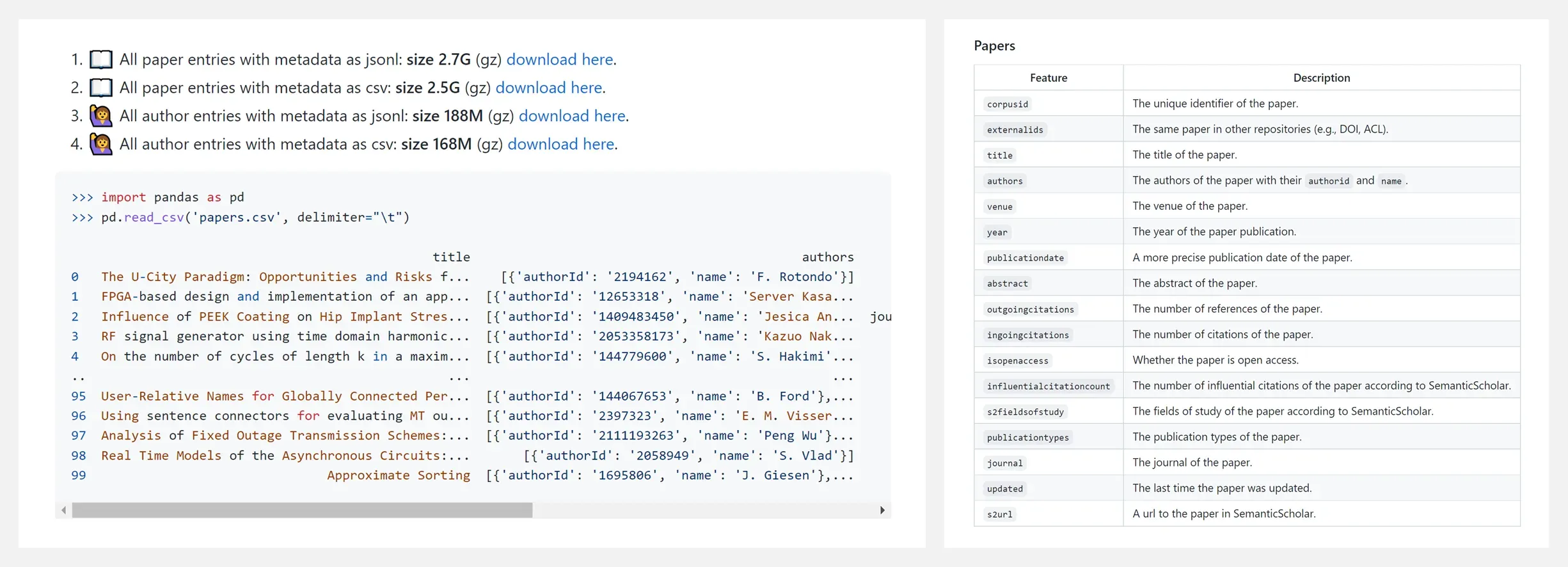
🔥 『The DBLP Discovery Dataset (D3)』DBLP 计算机科学学术文献与作者数据集
https://github.com/jpwahle/d3-dataset
Repo 为使用 cs-insights-crawler 爬取的 DBLP 论文元数据(> 590万篇文章,> 380万作者)。此语料库每月更新,并提供完整 DBLP 集合的综合存储库。导出路径如下:
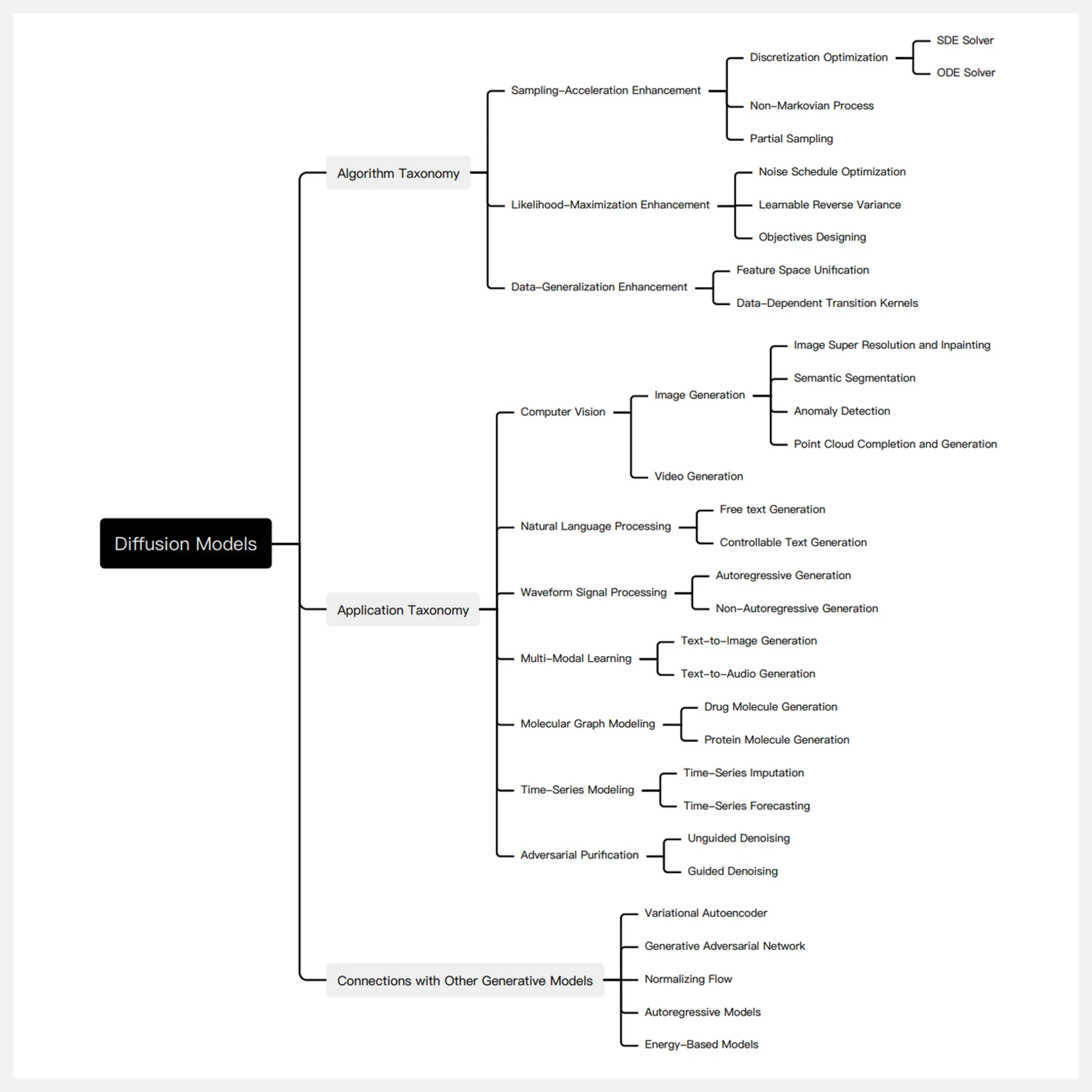
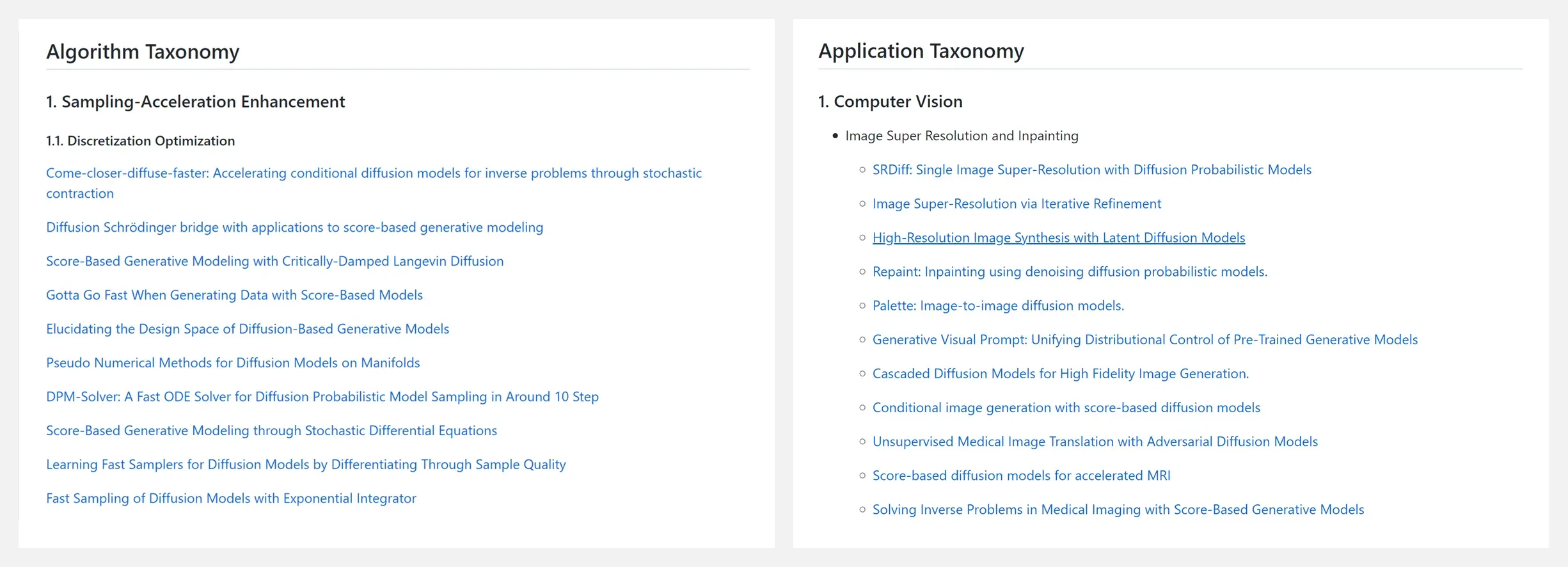
🔥 『Diffusion Models』扩散模型相关文献资源列表
https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy
Repo 是用于收集和分类有关扩散模型的论文,包含以下主题:
Algorithm Taxonomy / 算法分类
- Sampling-Acceleration Enhancement / 采样加速增强
- Likelihood-Maximization Enhancement / 似然最大化增强
- Data-Generalization Enhancement / 数据泛化增强
Application Taxonomy / 应用分类
Connections with Other Generative Models / 与其他生成模型的连接

研究&论文


可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.09.12 『机器人控制』 GenLoco: Generalized Locomotion Controllers for Quadrupedal Robots
- CVPR 2022 『3D目标检测』 Surface Representation for Point Clouds
- CVPR 2022 『神经渲染』 Zero-Shot Text-Guided Object Generation with Dream Fields
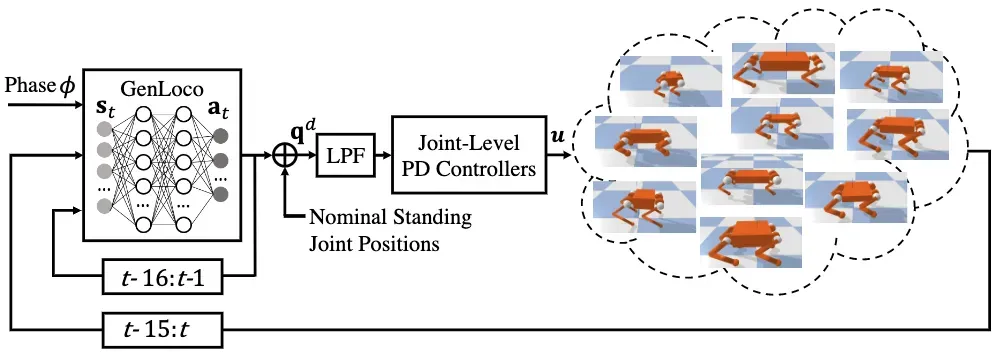
⚡ 论文:GenLoco: Generalized Locomotion Controllers for Quadrupedal Robots
论文时间:12 Sep 2022
领域任务:机器人控制
论文地址:https://arxiv.org/abs/2209.05309
代码实现:https://github.com/HybridRobotics/GenLoco
论文作者:Gilbert Feng, Hongbo Zhang, Zhongyu Li, Xue Bin Peng, Bhuvan Basireddy, Linzhu Yue, Zhitao Song, Lizhi Yang, Yunhui Liu, Koushil Sreenath, Sergey Levine
论文简介:In this work, we introduce a framework for training generalized locomotion (GenLoco) controllers for quadrupedal robots./在这项工作中,我们介绍了一个用于训练四足机器人通用运动(GenLoco)控制器的框架。
论文摘要:近年来,市场上可获得的、价格合理的四足机器人数量激增,其中许多平台被积极用于研究和工业。随着腿部机器人可用性的增加,对能够使这些机器人发挥有用技能的控制器的需求也在增加。然而,大多数基于学习的控制器开发框架都集中在训练机器人特定的控制器上,这个过程需要对每个新的机器人重复进行。在这项工作中,我们介绍了一个用于训练四足机器人的通用运动(GenLoco)控制器的框架。我们的框架合成了通用的运动控制器,可以部署在具有类似形态的各种四足机器人上。我们提出了一种简单而有效的形态随机化方法,该方法按程序生成了一组不同的模拟机器人用于训练。我们表明,通过在这一大组模拟机器人上训练控制器,我们的模型获得了更多的通用控制策略,可以直接转移到具有不同形态的新型模拟机器人和真实世界的机器人上,而这些机器人在训练过程中是没有观察到的。





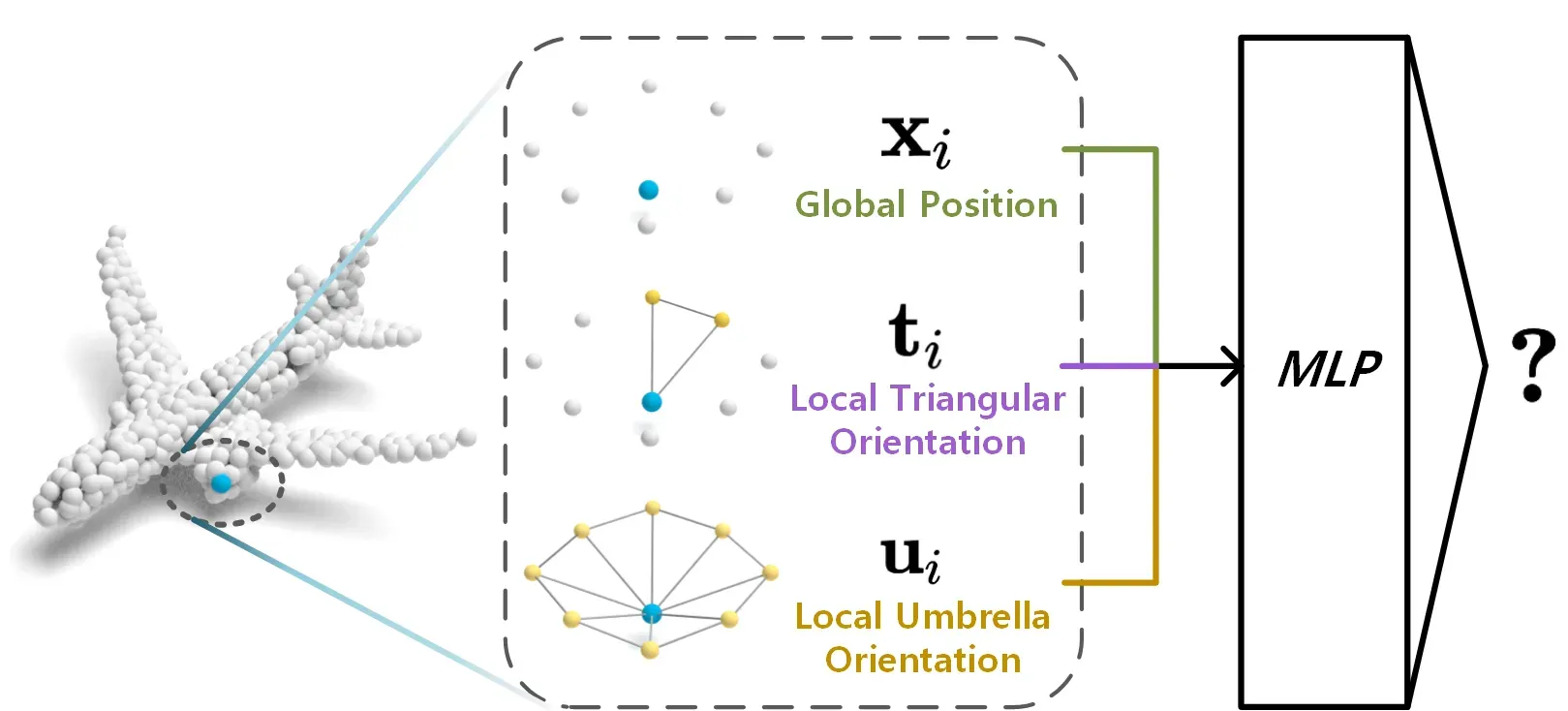
⚡ 论文:Surface Representation for Point Clouds
论文时间:CVPR 2022
领域任务:3D Object Detection, 3D Point Cloud Classification, 3D目标检测,3D点云分类
论文地址:https://arxiv.org/abs/2205.05740
代码实现:https://github.com/hancyran/RepSurf
论文作者:Haoxi Ran, Jun Liu, Chengjie Wang
论文简介:Based on a simple baseline of PointNet++ (SSG version), Umbrella RepSurf surpasses the previous state-of-the-art by a large margin for classification, segmentation and detection on various benchmarks in terms of performance and efficiency./基于PointNet++(SSG版本)的简单基线,Umbrella RepSurf在各种基准的分类、分割和检测方面的性能和效率都大大超过了之前的最先进水平。
论文摘要:大多数先前的工作通过坐标表示点云的形状。然而,这不足以直接描述局部的几何形状。在本文中,我们提出了RepSurf(代表面),这是一种新型的点云表示方法,明确地描述了非常局部的结构。我们探索了RepSurf的两个变体,即三角形RepSurf和伞形RepSurf,其灵感来自于计算机图形中的三角形网格和伞形曲率。我们在表面重建后通过预定义的几何先验来计算RepSurf的表示。由于RepSurf与不规则点的自由协作,它可以成为大多数点云模型的一个即插即用的模块。基于PointNet++(SSG版本)的简单基线,Umbrella RepSurf在各种基准上的分类、分割和检测方面的性能和效率都大大超过了之前的最先进水平。在增加了大约0.008M的参数数、0.04G的FLOPs和1.12ms的推理时间的情况下,我们的方法在ModelNet40上实现了94.7%(+0.5%),在ScanObjectNN上实现了84.6%(+1.8%)的分类,而在S3DIS 6倍上实现了74.3%(+0.8%)的mIoU,在ScanNet上实现了70.0%(+1.6%)mIoU的分割。在检测方面,以前最先进的检测器与我们的RepSurf在ScanNetV2上获得71.2%(+2.1%)mAP25,54.8%(+2.0%)mAP50,而在SUN RGB-D上获得64.9%(+1.9%)mAP25,47.7%(+2.5%)mAP50。我们的轻量级Triangular RepSurf在这些基准上也表现得很出色。代码可在https://github.com/hancyran/RepSurf获取。

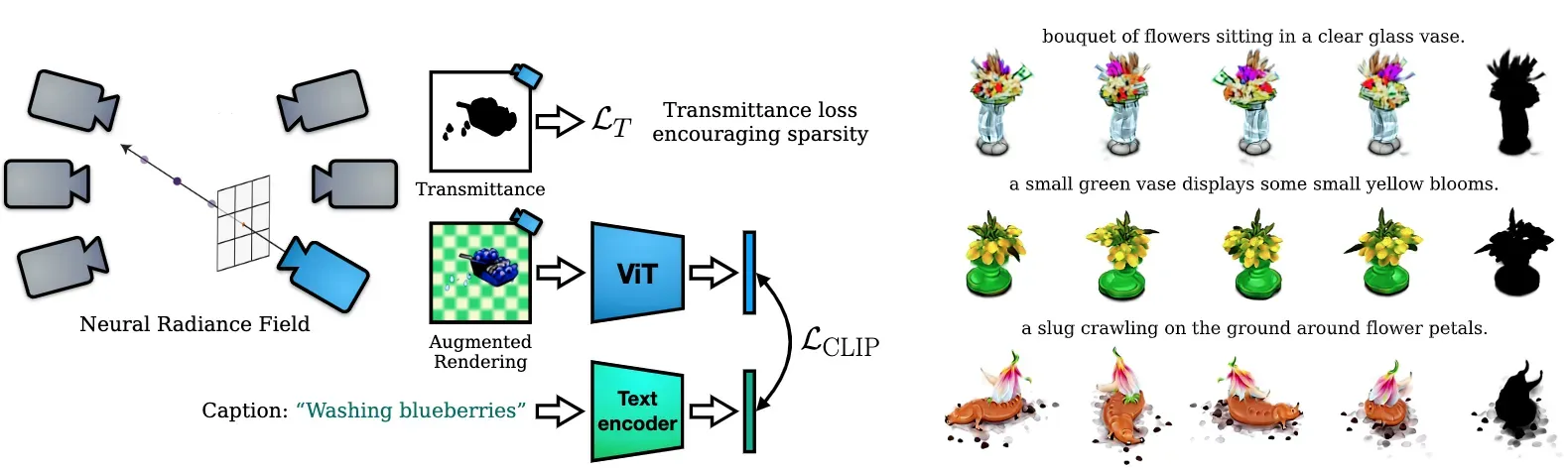
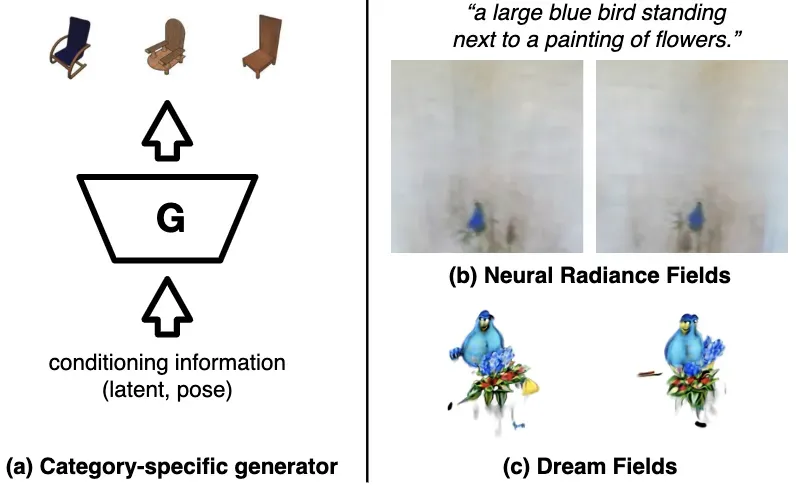
⚡ 论文:Zero-Shot Text-Guided Object Generation with Dream Fields
论文时间:CVPR 2022
领域任务:Neural Rendering,神经渲染
论文地址:https://arxiv.org/abs/2112.01455
代码实现:https://github.com/google-research/google-research/tree/master/dreamfields , https://github.com/ashawkey/torch-ngp , https://github.com/autodeskailab/clip-forge , https://github.com/shengyu-meng/dreamfields-3D
论文作者:Ajay Jain, Ben Mildenhall, Jonathan T. Barron, Pieter Abbeel, Ben Poole
论文简介:Our method, Dream Fields, can generate the geometry and color of a wide range of objects without 3D supervision./我们的方法 “梦境 “可以在没有3D监督的情况下生成各种物体的几何形状和颜色。
论文摘要:我们将神经渲染与多模态图像和文本表示相结合,仅从自然语言描述中合成各种三维物体。我们的方法,即 “梦境”,可以在没有3D监督的情况下生成广泛的物体的几何和颜色。由于缺乏多样的、有说明的三维数据,先前的方法只能从少数几个类别中生成物体,如ShapeNet。相反,我们用图像-文本模型指导生成,这些模型是在网络上的大型标题图像数据集上预先训练过的。我们的方法优化了来自许多相机视角的神经辐射场,这样,根据预先训练的CLIP模型,渲染的图像在目标标题下得分很高。为了提高保真度和视觉质量,我们引入了简单的几何先验,包括疏散诱导的透射率正则化、场景界限和新的MLP架构。在实验中,”梦田 “从各种自然语言的标题中产生了现实的、多视图一致的物体几何和颜色。



我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。


{kind=link}
版权声明:本文为博主作者:ShowMeAI原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/ShowMeAI/article/details/127103927