

界面选项解读
这是在趋动云上部署的Stable Diffusion
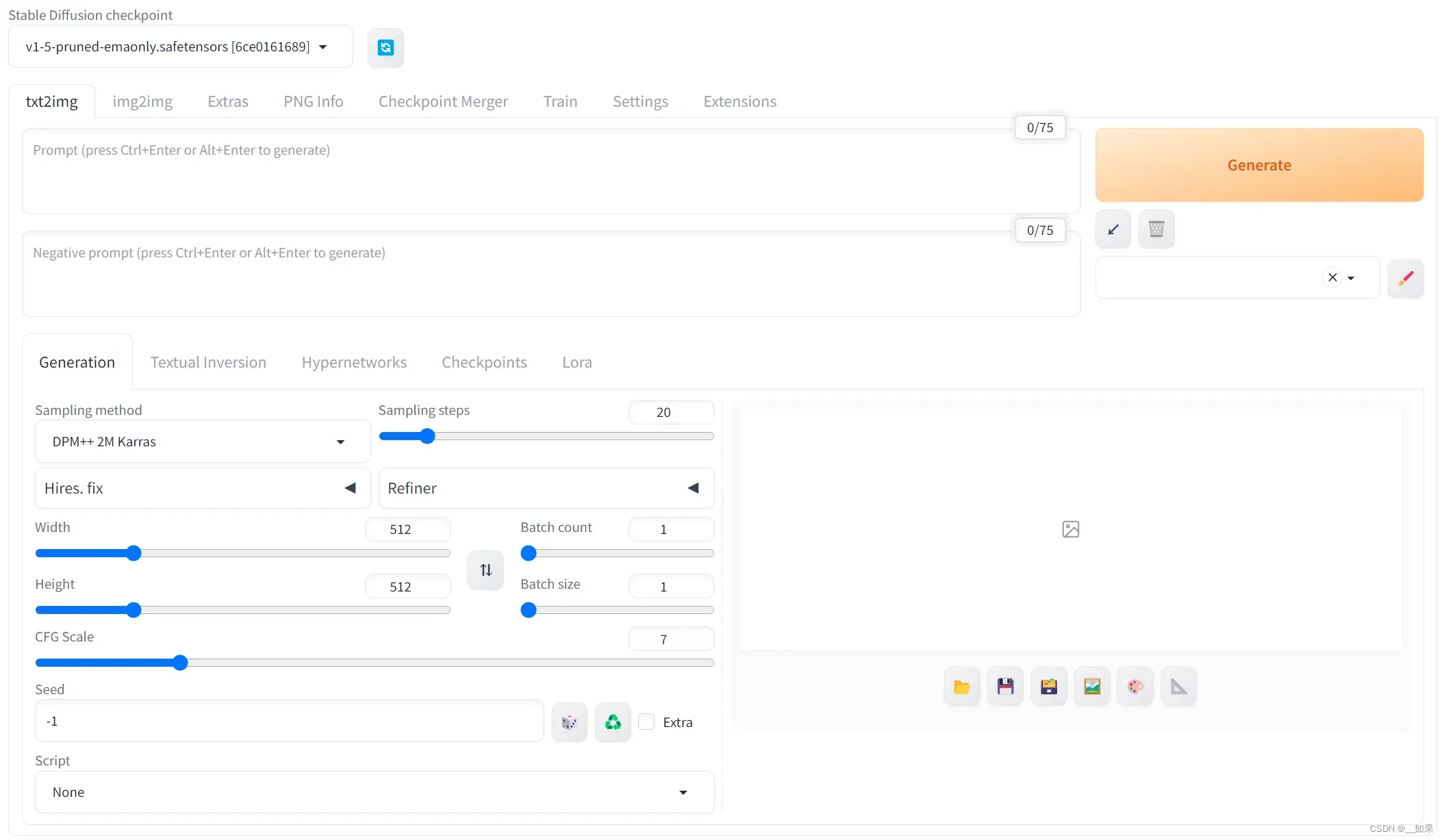

txt2img
prompt
(1)分割符号:使用逗号 , 用于分割词缀,且有一定权重排序功能,逗号前权重高,逗号后权重低
(2)建议的通用范式:建议用以下归类的三大部分来准备相关提示词:前缀(画质词+画风词+镜头效果+光照效果) + 主体(人物&对象+姿势+服装+道具) + 场景(环境+细节)
(3)更改提示词权重:使用小括号()增加模型对被括住提示词的注意 (提高权重)。用 (xxx: ) 语法形式来提升权重,其中 xxx 是你要强调的词 1.x 代表要提升的比例,如 1.5 就是提升 150% 的权重。权重取值范围 0.4-1.6,权重太小容易被忽视,太大容易拟合图像出错。例:(beautiful:1.3) 。叠加权重:通过叠加小括号方式提高权重,每加一层相当于提高1.1倍权重,例:((((beautiful eyes))))相当于(beautiful eyes: 1.1*1.1*1.1)
- (PromptA:权重):用于提高或降低该提示词的权重比例,注:数值大于1提高,小于1降低
- (PromptB):PromptB的权重为1.1=(PromptA:1.1)
- {PromptC}: PromptC的权重为1.05=(PromptB:1.05)
- [PromptD]: PromptD的权重减弱0.952=(PromptC:0.952)
- ((PromptE)=(PromptE:1.1*1.1)
- { {PromptF}}=(PromptF:1.05*1.05)
- [[PromptG]]=(PromptG:0.952*0.952)
(4)调取 LoRA & Hypernetworks 模型:使用尖括号 <> 调取LoRA或超网络模型。
按照下述形式输入:<lora:filename:multiplier> 或 <hypernet:filename:multiplier> 可调取相应模型,例:<lora:cuteGirlMix4_v10:0.5> 。
注:要先确保在【…\models\lora】或【…\models\hypernetworks】文件夹已保存好相关模型文件
(5)分布与交替渲染:使用方框号 [] 可应用较为复杂的分布与交替需求。
- [A:B:step] 代表执行A效果到多少进度,然后开始执行B。例:[blue:red:0.4],渲染蓝色到40%进度渲染红色。注:step > 1 时表示该组合在前多少步时做为 A 渲染,之后作为 B 渲染。step < 1 时表示迭代步数百分比。
- [A:0.5] 这样写的含义是从50%进度开始渲染A
- [A::step] 渲染到多少进度的时候去除A
- [A|B] A和B交替混合渲染
(6)反向提示词:反向提示词(Negative prompt),就是我们不想出现什么的描述。例:NSFW 不适合在工作时看的内容,包括限制级,还有低画质相关和一些容易变形身体部位的描述等。
注:在C站可下载一个叫 Easynegative 的文件,它的作用是把一些常用的反向提示词整合在一起了,让我们只需输入简单的关键词就能得到较好效果。把它放到 xxx/enbeddings 文件夹,需要触发时在 negative prompt 中输入 easynegative 即可生效。
(7)一些注意说明:
- AI 会按照 prompt 提示词输入的先后顺序和所分配权重来执行去噪工作;
- AI 也会依照概率来选择性执行,如提示词之间有冲突,AI 会根据权重确定的概率来随机选择执行哪个提示词。
- 越靠前的 Tag 权重越大;比如景色Tag在前,人物就会小,相反的人物会变大或半身。
- 生成图片的大小会影响 Prompt 的效果,图片越大需要的 Prompt 越多,不然 Prompt 会相互污染。
- Prompt 支持使用 emoji,且表现力较好,可通过添加 emoji 图来达到效果。如 形容喜欢表情, 可修手。
- 连接符号,使用 +, and, |, _ 都可连接描述词,但各自细节效果有所不同。
文章链接:【Stable Diffusion】Prompt 篇 – 知乎 (zhihu.com)
采样器
先放结论:
- 如果只是想得到一些较为简单的结果,选用欧拉(Eular)或者Heun,并可适当减少Heun的步骤数以减少时间
- 对于侧重于速度、融合、新颖且质量不错的结果,建议选择:
- DPM++ 2M Karras, Step Range:20-30
- UniPc, Step Range: 20-30
3. 期望得到高质量的图像,且不关心图像是否收敛:
- DPM ++ SDE Karras, Step Range:8-12
- DDIM, Step Range:10-15
4. 如果期望得到稳定、可重现的图像,避免采用任何祖先采样器
Sampling steps
增加采样步数,会缩小每一步的降噪幅度,有助于减少采样的截断误差
每一步迭代都是基于前一步的图像进行细化,理论上步数越多,图像越精细。但是,过多的步数会导致资源消耗增加和生成速度变慢,而且在达到一定步数后,图像质量的提升会逐渐减少
Sampling method
经典ODE求解器
- Euler采样器:欧拉采样方法。
- Heun采样器:欧拉的一个更准确但是较慢的版本。
- LMS采样器:线性多步法,与欧拉采样器速度相仿,但是更准确。
祖先采样器
名称中带有a标识的采样器表示这一类采样器是祖先采样器。这一类采样器在每个采样步骤中都会向图像添加噪声,采样结果具有一定的随机性。
- Euler a
- DPM2 a
- DPM++ 2S a
- DPM++ 2S a Karras
由于这一类采样器的特性,图像不会收敛。因此为了保证重现性,例如在通过多帧组合构建动画时,应当尽量避免采用具有随机性的采样器。需要注意的是,部分采样器的名字中虽然没有明确标识属于祖先采样器,但也属于随机采样器。如果希望生成的图像具有细微的变化,推荐使用variation seed进行调整。
Karras
带有Karras字样的采样器,最大的特色是使用了Karras论文中建议的噪音计划表。主要的表现在于噪点步长在接近尾声时会更小,有助于图像的质量提升。
DDIM与PLMS(已过时,不再使用)
DDIM(去噪扩散隐式模型)和PLMS(伪线性多步方法)是伴随Stable Diffusion v1提出的采样方法,DDIM也是最早被用于扩散模型的采样器。PLMS是DDIM的一种更快的替代方案。当前这两种采样方法都不再广泛使用。
DPM与DPM++
DPM(扩散概率模型求解器)这一系列的采样器于2022年发布,代表了具有类似体系结构的求解器系列。
由于DPM会自适应调整步长,不能保证在约定的采样步骤内完成任务,整体速度可能会比较慢。对Tag的利用率较高,在使用时建议适当放大采样的步骤数以获得较好的效果。
DPM++是对DPM的改进,DPM2采用二阶方法,其结果更准确,但是相应的也会更慢一些。
UniPC
UniPC(统一预测校正器),一种可以在5-10个步骤中实现高质量图像生成的方法。
K-diffusion
用于指代Katherine Crowson’s k-diffusion项目中实现的Karras 2022论文中提及的的相关采样器。当前常用的采样器中,除了DDIM、PLMS与UniPC之外的采样器均来自于k-diffusion
DPM++ Family
DPM++ SDE与DPM++ SDE Karras的收敛能力较差,图像的波动情况较为显著。
DPM++ 2M与DPM++ 2M Karras表现较好,当步数足够大时,Karras方法收敛的更快。
文章链接:Stable Diffusion-采样器篇 – 知乎 (zhihu.com)
Hires.fix
提供了一个方便的选项,可以部分地以较低分辨率呈现图像,然后将其放大,最后在高分辨率下添加细节。换句话说,这相当于在txt2img中生成图像,通过自己选择的方法将其放大,然后在img2img中对现在已经放大的图像进行第二次处理,以进一步完善放大效果并创建最终结果。
Width&Height
图像的宽度和高度直接决定了其尺寸和分辨率。更大的图像能够包含更多细节和信息,但同时也要求更高的处理能力和更长的生成时间
Batch count&Batch size
这两个参数控制生成图像的数量和频率。通过调整它们,可以批量生成多个图像,提高效率。适当的批次数和数量设置可以帮助你更快地获取所需的图像,特别是在寻找那“完美一张”时
CFG Scale
CFG Scale参数控制提示词与生成图像之间的相关性。更高的数值意味着模型会更加专注于提示词的内容,生成更加符合描述的图像。这个参数对于调整生成图像的创意程度和精确度非常有用
Seed
种子值控制了图像生成的随机性。通过固定种子值,可以重现特定的图像结果,这对于复现喜欢的图像或进行微调非常有用
版权声明:本文为博主作者:__如果原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_73202283/article/details/135147408