

一、前言
对于时间拐点问题,其实就是找changepoint的问题,业务场景比如机器的缩扩容,业务的升级回滚等,都会让一些指标发生这样的现象, 如下图。(这种场景比较理想,现实情况要复杂得多)
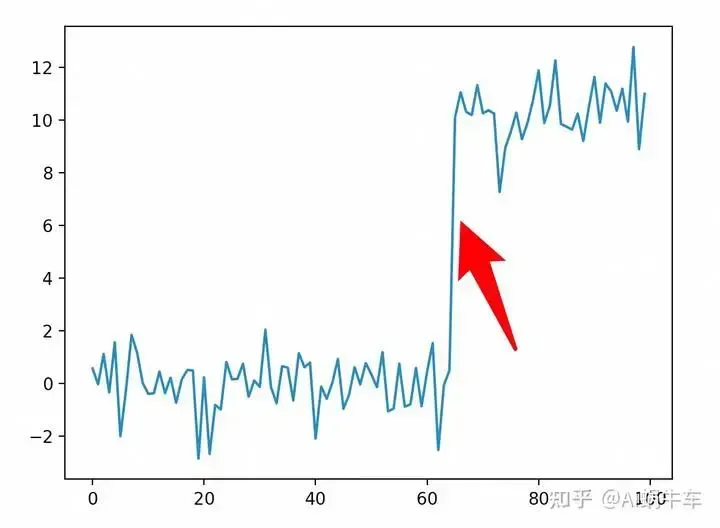

为了检测这个区域,需要使用changepoint detector:ruptures
二、ruptures
ruptures 是专门用于检测时间序列数据中的结构性变化,这种变化也常被称为断点(breakpoints)或变点(changepoints)。
库提供了多种算法来检测时间序列中的突变或者异常模式变化。这些算法能够识别出时间序列数据中的突变,这些突变可能表明了一些潜在的事件或状态变化。
项目地址:https://github.com/deepcharles/ruptures 官方文档在这里 http://ctruong.perso.math.cnrs.fr/ruptures
2.1 安装
pip install ruptures2.2 使用
其中有很多算法供选择,这里选择Dynp(dynamic programming.)
其他算法使用可以参考:https://forecastegy.com/posts/change-point-detection-time-series-python/#detecting-change-points-with-binary-segmentation
import matplotlib.pyplot as plt
import ruptures as rpt
import numpy as np
mean = 0
std_dev = 1
length_of_series = 100
values = np.random.normal(mean, std_dev, length_of_series)
values[-35:] = values[-35:] + 10
# 找拐点
algo = rpt.Dynp(model="l2", min_size=3, jump=3).fit(values)
# 检测断点,指定最大断点数
result = algo.predict(n_bkps=1)
result = result[:-1]
# 显示结果
plt.plot(values)
for bkp in result:
plt.axvline(x=bkp, color='r', linestyle='--')
plt.show()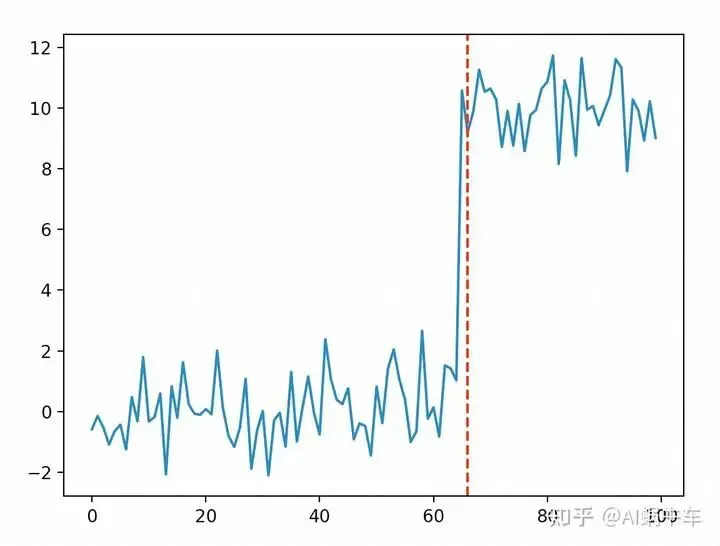

参数:
-
model:用于计算cost的function,根据这个来找changepoint
-
custom_cost: 自定义cost function
-
min_size:最小的分段长度。
-
jump:在进行断点搜索时的采样步长。
2.3 源码简单解析
predict源码:
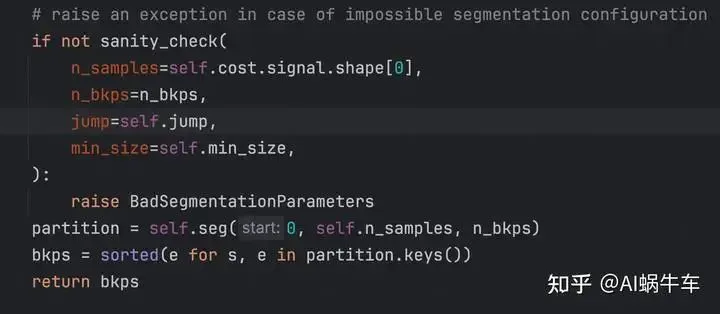

实则还是self.seg是核心函数,结果通过长度的index进行排序 输出的结果格式为长度的index,看上面给出的results就明白了。
@lru_cache(maxsize=None)
def seg(self, start, end, n_bkps):
"""Recurrence to find the optimal partition of signal[start:end].
This method is to be memoized and then used.
Args:
start (int): start of the segment (inclusive)
end (int): end of the segment (exclusive)
n_bkps (int): number of breakpoints
Returns:
dict: {(start, end): cost value, ...}
"""
jump, min_size = self.jump, self.min_size
if n_bkps == 0:
cost = self.cost.error(start, end)
return {(start, end): cost}
elif n_bkps > 0:
# Let's fill the list of admissible last breakpoints
multiple_of_jump = (k for k in range(start, end) if k % jump == 0)
admissible_bkps = list()
for bkp in multiple_of_jump:
n_samples = bkp - start
# first check if left subproblem is possible
if sanity_check(
n_samples=n_samples,
n_bkps=n_bkps - 1,
jump=jump,
min_size=min_size,
):
# second check if the right subproblem has enough points
if end - bkp >= min_size:
admissible_bkps.append(bkp)
assert (
len(admissible_bkps) > 0
), "No admissible last breakpoints found.\
start, end: ({},{}), n_bkps: {}.".format(
start, end, n_bkps
)
# Compute the subproblems
sub_problems = list()
for bkp in admissible_bkps:
left_partition = self.seg(start, bkp, n_bkps - 1)
right_partition = self.seg(bkp, end, 0)
tmp_partition = dict(left_partition)
tmp_partition[(bkp, end)] = right_partition[(bkp, end)]
sub_problems.append(tmp_partition)
# Find the optimal partition
return min(sub_problems, key=lambda d: sum(d.values()))稍微看下 这个源码,大致就懂这个算法的含义了。
-
通过jump大小得到可能的候选边界
-
通过min_size的大小比较,得到每段的前后边界组合
-
进行递归
-
如果没有分块,则计算此时的时间序列段的cost value
-
得到所有分块的cost值,找到此时cost的最小值
这个其实比较暴力了,相当于目标函数cost fuction最小化。不暴力的有贝叶斯的方法:Bayesian Online Changepoint Detection
2.4 一些问题
-
这个必须要预先设置要检测多少个拐点
-
比如要大于min_size
这两个问题对于实际应用,基本不会知道检测的长度预先有多少个拐点,其次大于min_size这个要求如果是流式场景肯定会有一定的延迟。
所以对于流式场景这个只能检测过去几个点的拐点状态,无法实时检测出来。
并且针对第一个问题,不知道有多少个,那我们也可以通过卡阈值的方式来自动化的选出排名前部的边界
# 找拐点
algo = rpt.Dynp(model="l2", min_size=3, jump=3).fit(values)
# 这块n可以很多,但是要满足分割的条件, 直接采用 seg
partition = algo.seg(0, algo.n_samples, n_bkps=10)
# 输出的肯定有最后一个边界要去掉
filter_partition = {}
for key, value in partition.items():
if key[1] == algo.n_samples:
continue
filter_partition[key] = value
partition = filter_partition
sort_partition = sorted(partition.items(), key=lambda x: x[1], reverse=True)后续怎么操作就看需求了,可以按照cost大小进行排序,也可以直接根据数量取前面的等等
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步


发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书
版权声明:本文为博主作者:AI蜗牛车原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_33431368/article/details/136003279