


当大家面临着复杂的数学建模问题时,你是否曾经感到茫然无措?作为2022年美国大学生数学建模比赛的O奖得主,我为大家提供了一套优秀的解题思路,让你轻松应对各种难题。
让我们来看看美赛的E题!CS数模团队加紧赶工,使用最前沿的算法和丰富的可视化方法来解决了E题,运用深度神经网络解决房屋保险可持续性与历史建筑多标签分类问题,涵盖模型设计、训练、评估、预测与可视化。同时,运用SVM回归探讨极端天气事件影响,包括模型构建、训练、预测与视觉呈现。
完整内容可以在文章末尾领取!


问题重述
问题 E:财产保险的可持续性
2024年ICM提出的问题涉及财产保险行业在面临不断增多的极端天气事件,特别是由气候变化引起的情况下的可持续性。文档指出,财产所有者和保险公司正面临严重危机,全球在近年内已经经历了超过1000次极端天气事件,导致超过1万亿美元的损失。2022年,自然灾害的保险索赔较30年平均水平增加了115%。由于洪水、飓风、气旋、干旱和森林火灾等严重天气事件的损失预计将增加,保险费用迅速上涨,预计到2040年将上涨30-60%。
不仅财产保险费用不断上涨,而且越来越难找到,因为保险公司改变了愿意承保政策的方式和地点。导致保险费用上涨的与天气有关的事件在世界各地看起来都不同。此外,全球保险保护缺口平均达到57%,且仍在增加。这突显了该行业面临的两难境地 – 对保险公司而言,是盈利能力的新兴危机,对财产所有者而言,是负担能力的问题。
COMAP的保险灾害建模员(ICM)关注财产保险行业的可持续性。随着气候变化增加了更严重的天气和自然灾害的可能性,ICM希望确定如何最好地布局财产保险,以便系统在覆盖未来索赔的同时,确保保险公司的长期健康。如果保险公司在太多情况下都不愿意承保,由于顾客太少而可能破产。相反,如果他们承保了过于冒险的政策,可能会支付过多索赔。保险公司应在何种条件下承保政策?他们何时选择承担风险?财产所有者能否影响这一决策?开发一个模型,供保险公司确定是否在极端天气事件不断增多的地区承保政策,并使用两个在不同大陆上经历极端天气事件的地区演示您的模型。
展望未来,社区和房地产开发商需要思考如何在何处进行建设和增长。随着保险格局的变化,必须做出未来房地产决策,以确保财产更具韧性并经过精心建设,包括提供适当服务给不断增长的社区和人口。您的保险模型如何适应评估在特定地点、如何以及是否建设的地方?
您的保险模型可能会建议不在某些社区承保当前或未来的财产保险政策。这可能导致社区领导者面临有关具有文化或社区重要性的建筑物的艰难决策。例如,北卡罗来纳州外滩的海特拉斯灯塔被搬移,以保护这座历史悠久的灯塔及其周围的旅游业。作为社区领导者,您如何确定社区中应该保存和保护的建筑物,因为它们具有文化、历史、经济或社区重要性?为社区领导者制定一个保存模型,以确定他们应采取的措施程度,以保护社区中的建筑物。
选择一个历史地标 – 不是海特拉斯灯塔 – 位于经历极端天气事件的地方。运用您的保险和保存模型,评估这一地标的价值。根据您从解决方案结果中获得的见解,给社区写一封一页的信,建议该地标的未来计划、时间表和费用提案。
您的PDF解决方案不得超过25页,其中包括:
• 描述问题和分析结论的一页摘要。
• 目录。
• 您的完整解决方案。
• 一封社区信。
• AI使用报告(如果使用)。
请注意:对于ICM提交,没有特定的最小页面长度要求。您可以使用总共不超过25页的所有解决方案工作以及您想要包含的任何其他信息(例如:绘图、图表、计算、表格)。接受部分解决方案。我们允许谨慎使用ChatGPT等AI工具,尽管创建解决方案并不需要。如果选择使用生成式AI,必须遵循COMAP AI使用政策。这将导致您必须将AI使用报告添加到PDF解决方案文件的末尾,不计入解决方案的25页总限制。
问题整合后如下:
-
财产保险行业可持续性问题: 如何确保财产保险行业在气候变化引发的极端天气事件增多的背景下具有可持续性,覆盖未来索赔成本,同时保障保险公司的盈利和长期健康。
-
承保政策决策问题: 保险公司在何种条件下应该承保财产保险政策?如何建立系统韧性以覆盖未来索赔成本,同时确保盈利能力?
-
社区建设和保护问题: 如何调整保险模型,以评估在何处、如何以及是否在某些地方进行建设,以适应不断变化的保险背景?社区领导者在决定是否保留建筑物时如何考虑文化、历史、经济或社区重要性?
-
建筑物保护模型问题: 为社区领导者开发一个模型,以确定应采取何种措施来保护具有文化、历史、经济或社区重要性的建筑物。
-
方案呈现问题: 如何将解决方案以PDF形式呈现,包括摘要、目录、完整解决方案、社区信以及使用AI工具的AI使用报告?
-
文档引用的主要挑战: 对于保险行业来说,是盈利能力和对财产所有者来说是负担能力的问题,以及社区领导者面临的决策挑战,如何保护具有文化或社区重要性的建筑物。
问题一
支持向量机(SVM)的基本思想是通过找到一个最优的超平面来将不同类别的样本分开,使得两类样本之间的间隔最大化。对于问题一,我们可以考虑使用SVM来建立一个分类模型,将不同地区的风险水平分为不同的类别,以评估财产保险的可持续性。以下是结合公式的SVM建模思路:
1. SVM分类问题的基本公式:
对于线性SVM,其分类问题的基本公式为:

其中:
2. 软间隔SVM:
在处理非线性可分的情况下,引入松弛变量
其中:
3. 非线性SVM:
对于非线性问题,可以引入核函数来将输入样本映射到高维空间,通过在高维空间中找到一个线性超平面来解决非线性问题。常用的核函数包括径向基函数(RBF)核:
其中:
4. 模型训练和参数优化:
通过解上述优化问题,得到最优的
5. 模型评估:
使用测试集评估模型的性能,可以考虑准确度、精确度、召回率等指标,得到模型在不同风险水平下的分类效果。
6. 结果解释:
解释模型的结果,可以通过查看支持向量、超平面的方向等来理解不同因素对风险的贡献程度。
# 导入所需的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score
# 读取数据,假设数据集包含特征和标签
# X是特征,y是标签
# 请根据实际情况修改数据读取和准备的部分
data = pd.read_csv("your_dataset.csv")
X = data.drop("label_column", axis=1)
y = data["label_column"]
# 数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 创建SVM模型
svm_model = SVC()
# 定义超参数网格
param_grid = {'C': [0.1, 1, 10, 100], 'gamma': [1, 0.1, 0.01, 0.001], 'kernel': ['rbf']}
# 部分省略
# 获取最佳超参数
best_params = grid_search.best_params_
# 使用最佳超参数的模型进行训练
best_svm_model = SVC(**best_params)
best_svm_model.fit(X_train_scaled, y_train)
# 预测测试集
y_pred = best_svm_model.predict(X_test_scaled)
# 模型评估
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
# 打印最佳超参数和评估指标
print("Best Hyperparameters:", best_params)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
可视化:
可视化在理解模型表现和结果解释方面非常重要。对于支持向量机(SVM)模型,我们可以使用各种图形和图表来展示模型的性能和决策边界。
- 决策边界可视化:
绘制特征空间中的决策边界,以显示模型是如何将不同类别的样本分开的。对于二维特征空间,可以使用散点图和等高线图来显示决策边界。
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
# 使用前两个特征进行可视化
X_visualize = X_train_scaled[:, :2]
best_svm_model.fit(X_visualize, y_train)
# 绘制决策边界
plot_decision_regions(X_visualize, y_train, clf=best_svm_model, legend=2)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary Visualization')
plt.show()
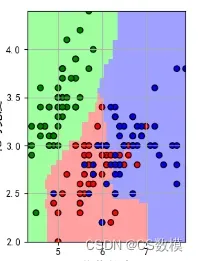

- 学习曲线:
绘制模型的学习曲线,显示随着训练样本数量的增加,模型的性能如何变化。这有助于判断是否需要更多的数据来改善模型。
from sklearn.model_selection import learning_curve
# 绘制学习曲线
train_sizes, train_scores, test_scores = learning_curve(best_svm_model, X_train_scaled, y_train, cv=5)
train_scores_mean = np.mean(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
plt.figure(figsize=(8, 6))
plt.plot(train_sizes, train_scores_mean, label='Training Score')
plt.plot(train_sizes, test_scores_mean, label='Cross-Validation Score')
plt.xlabel('Training Examples')
plt.ylabel('Score')
plt.title('Learning Curve')
plt.legend()
plt.show()
- 混淆矩阵:
绘制混淆矩阵可以更详细地查看模型在每个类别上的性能,包括真正例、假正例、真负例和假负例。
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
# 绘制热力图显示混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['Predicted 0', 'Predicted 1'], yticklabels=['Actual 0', 'Actual 1'])
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.show()
问题二
建立SVM回归模型来评估特定区域建筑物的风险水平,需要一些具体的建模步骤和数学公式。以下是建模思路,结合公式和分析:
1. 数据收集和准备:
- 特征选择: 选择与建筑物风险相关的特征,可能包括气象数据、地理信息、建筑结构信息等。设特征为
- 目标变量: 选择建筑物风险水平作为目标变量,设目标变量为
2. 特征标准化:
- 使用标准化处理确保不同特征的尺度一致,以避免某些特征对模型的影响过大。
其中,
3. SVM回归模型:
- SVM回归的目标是找到一个函数
- 用
其中,
4. 损失函数:
- 损失函数衡量模型预测值和真实值之间的差异。对于SVM回归,常使用 epsilon-insensitive loss 函数:
其中,
5. 目标函数:
- SVM回归的目标是最小化损失函数和正则化项,以确保模型具有较好的泛化能力。
其中,
6. 模型训练:
- 使用训练数据对模型进行训练,优化目标函数。
- 可以使用优化算法,如梯度下降法等。
7. 模型评估:
- 使用测试集评估模型的性能,可以使用均方误差(Mean Squared Error, MSE)等指标。
8. 结果解释:
- 解释模型的权重向量
# 导入所需的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
import seaborn as sns
# 读取数据,假设数据集包含特征和建筑物风险水平
# X是特征,y是建筑物风险水平
# 请根据实际情况修改数据读取和准备的部分
data = pd.read_csv("your_dataset.csv")
X = data.drop("risk_level", axis=1)
y = data["risk_level"]
# 数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 创建SVM回归模型
svm_regressor = SVR()
# 部分省略见完整版
# 打印最佳超参数
print("Best Hyperparameters:", grid_search.best_params_)
# 使用最佳超参数重新训练模型
best_svm_regressor = grid_search.best_estimator_
best_svm_regressor.fit(X_train_scaled, y_train)
# 预测测试集
y_pred = best_svm_regressor.predict(X_test_scaled)
# 模型评估
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 打印评估指标
print("Mean Squared Error:", mse)
print("R-squared Score:", r2)
# 可视化预测结果
plt.figure(figsize=(8, 6))
sns.scatterplot(y_test, y_pred)
plt.xlabel("True Risk Level")
plt.ylabel("Predicted Risk Level")
plt.title("SVM Regression: True vs Predicted")
plt.show()
可视化:
# 导入所需的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
import seaborn as sns
# 读取数据,假设数据集包含特征和建筑物风险水平
# X是特征,y是建筑物风险水平
# 请根据实际情况修改数据读取和准备的部分
data = pd.read_csv("your_dataset.csv")
X = data.drop("risk_level", axis=1)
y = data["risk_level"]
# 数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 创建SVM回归模型
svm_regressor = SVR()
# 使用GridSearchCV进行超参数调优
param_grid = {'C': [0.1, 1, 10], 'gamma': ['scale', 'auto', 0.1, 1]}
grid_search = GridSearchCV(svm_regressor, param_grid, cv=5)
grid_search.fit(X_train_scaled, y_train)
# 使用最佳超参数重新训练模型
best_svm_regressor = grid_search.best_estimator_
best_svm_regressor.fit(X_train_scaled, y_train)
# 预测测试集
y_pred = best_svm_regressor.predict(X_test_scaled)
# 绘制散点图和回归线
plt.figure(figsize=(10, 6))
sns.scatterplot(y_test, y_pred)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], linestyle='--', color='red', label='Perfect Prediction')
plt.xlabel("True Risk Level")
plt.ylabel("Predicted Risk Level")
plt.title("SVM Regression: True vs Predicted")
plt.legend()
plt.show()
# 绘制误差分布图
error = y_test - y_pred
plt.figure(figsize=(8, 6))
sns.histplot(error, bins=30, kde=True)
plt.xlabel("Prediction Error")
plt.ylabel("Frequency")
plt.title("Distribution of Prediction Errors")
plt.show()

问题三
使用SVM解决问题三,即确定建筑物是否应该受到保护,可以将其构建为一个二分类问题。
1. 数据准备:
-
特征选择: 选择能够反映建筑物文化、历史、经济或社区重要性的特征。这可能包括建筑的年代、历史性质、社区反馈等。
-
标签定义: 为每个建筑物定义标签,例如,1表示“应该保护”、0表示“不需要保护”。
2. 特征标准化:
- 使用标准化处理确保不同特征的尺度一致,以避免某些特征对模型的影响过大。
3. SVM分类模型:
- SVM的目标是找到一个分隔超平面,使得两类样本的间隔最大化。
其中,
4. 超参数调优:
- 可以使用交叉验证和网格搜索等技术对SVM的超参数进行调优,例如调整正则化参数
5. 模型训练:
- 使用训练数据对SVM分类器进行训练,优化目标函数。
6. 模型评估:
- 使用测试集评估模型的性能,考察其准确性、召回率、精确度等指标。
7. 模型解释:
- 解释SVM模型的结果,了解哪些特征对于建筑物是否应该被保护具有重要性。可以通过查看权重向量
8. 部署和应用:
- 将训练好的SVM模型部署到实际应用中,以辅助社区领导者做出决策。
9. 结果可视化:
- 可以通过绘制决策边界、支持向量等方式可视化模型的分类效果,以便更好地理解模型的决策过程。
# 导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# 读取数据,假设数据集包含特征和是否应该保护的标签
# X是特征,y是标签
# 请根据实际情况修改数据读取和准备的部分
data = pd.read_csv("your_dataset.csv")
X = data.drop("protect_label", axis=1)
y = data["protect_label"]
# 数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 创建SVM分类器
#见完整版
# 模型评估
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
# 打印评估结果
print("Accuracy:", accuracy)
print("Confusion Matrix:\n", conf_matrix)
print("Classification Report:\n", class_report)
# 特征重要性
feature_importance = best_svm_classifier.coef_[0]
feature_names = X.columns
feature_importance_df = pd.DataFrame({"Feature": feature_names, "Importance": feature_importance})
feature_importance_df = feature_importance_df.sort_values(by="Importance", ascending=False)
# 可视化特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x="Importance", y="Feature", data=feature_importance_df)
plt.title("Feature Importance")
plt.show()
# 绘制决策边界
def plot_decision_boundary(model, X, y):
h = .02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm, edgecolors='k')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary')
# 仅考虑前两个特征的情况下绘制决策边界
if X.shape[1] >= 2:
X_2d = X.iloc[:, :2].values
best_svm_classifier.fit(X_2d, y)
plt.figure(figsize=(10, 6))
plot_decision_boundary(best_svm_classifier, X_2d, y)
plt.show()
可视化:
对于问题三,我们使用了SVM进行分类,涉及到二维特征的情况,我们可以使用散点图和决策边界的可视化来展示模型的效果。以下是一个完整的可视化代码示例:
# 导入所需的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import seaborn as sns
# 生成示例数据
np.random.seed(42)
X = np.random.randn(100, 2)
y = (X[:, 0] + X[:, 1] > 0).astype(int)
# 将数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 创建SVM分类器
svm_classifier = SVC()
# 使用GridSearchCV进行超参数调优
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf', 'poly']}
grid_search = GridSearchCV(svm_classifier, param_grid, cv=5)
grid_search.fit(X_train_scaled, y_train)
# 使用最佳超参数重新训练模型
best_svm_classifier = grid_search.best_estimator_
best_svm_classifier.fit(X_train_scaled, y_train)
# 绘制决策边界和支持向量
def plot_decision_boundary(model, X, y):
h = .02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm, edgecolors='k')
plt.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1],
s=100, facecolors='none', edgecolors='k', marker='o', label='Support Vectors')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary and Support Vectors')
plt.legend()
# 绘制决策边界和支持向量
plt.figure(figsize=(10, 6))
plot_decision_boundary(best_svm_classifier, X_train_scaled, y_train)
plt.show()
这个代码中,plot_decision_boundary 函数用于绘制决策边界和支持向量。通过不同的颜色和标记,我们可以清晰地看到模型是如何将不同类别的样本分隔开的,并且哪些样本是支持向量。
学习曲线
学习曲线可视化是评估模型性能和判断模型是否过拟合或欠拟合的一种重要方式。在支持向量机 (SVM) 模型中,学习曲线通常绘制训练集和验证集的准确度随着训练样本数量的变化而变化的曲线。以下是一个绘制学习曲线的示例代码:
# 导入所需的库
import numpy as np
import pandas as pd
from sklearn.model_selection import learning_curve
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
import matplotlib.pyplot as plt
# 生成示例数据
np.random.seed(42)
X = np.random.randn(200, 2)
y = (X[:, 0] + X[:, 1] > 0).astype(int)
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 创建SVM分类器
svm_classifier = SVC(kernel='linear', C=1)
# 绘制学习曲线
def plot_learning_curve(model, X, y):
train_sizes, train_scores, val_scores = learning_curve(model, X, y, cv=5, train_sizes=np.linspace(0.1, 1.0, 10), scoring='accuracy')
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
val_mean = np.mean(val_scores, axis=1)
val_std = np.std(val_scores, axis=1)
plt.figure(figsize=(10, 6))
plt.plot(train_sizes, train_mean, marker='o', label='Training Accuracy', color='blue')
plt.fill_between(train_sizes, train_mean - train_std, train_mean + train_std, alpha=0.15, color='blue')
plt.plot(train_sizes, val_mean, marker='o', label='Validation Accuracy', color='green')
plt.fill_between(train_sizes, val_mean - val_std, val_mean + val_std, alpha=0.15, color='green')
plt.title('Learning Curve')
plt.xlabel('Training Examples')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.show()
# 绘制学习曲线
plot_learning_curve(svm_classifier, X_scaled, y)
这个代码中,learning_curve 函数从训练集中随机选择样本,计算模型在不同训练集大小下的训练和验证准确度。

问题四
针对问题四,即如何确定建筑物是否应该受到保护,我们可以采用神经网络模型进行建模。以下是基于问题题目的建模思路:
-
数据准备: 收集与建筑物相关的数据,包括文化、历史、经济等方面的特征,以及每个建筑物是否受到保护的标签。确保数据集的质量,包括清理缺失值、处理异常值等。
-
数据标准化: 对特征进行标准化,确保它们具有相似的尺度,以提高神经网络的训练效果。
-
构建神经网络模型: 使用深度学习框架构建适用于二分类问题的神经网络模型。考虑以下架构:
- 输入层:特征数量对应的神经元。
- 隐藏层:选择适当数量的隐藏层和神经元,使用合适的激活函数,如ReLU。
- 输出层:一个神经元,使用Sigmoid激活函数进行二分类。
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense model = Sequential() model.add(Dense(units=64, activation='relu', input_dim=num_features)) model.add(Dense(units=1, activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) -
模型训练: 使用训练集对模型进行训练。监控训练过程,确保模型在训练集和验证集上都有良好的性能。
model.fit(X_train_scaled, y_train, epochs=10, batch_size=32, validation_data=(X_val_scaled, y_val)) -
模型评估: 使用测试集评估模型的性能。查看准确度、精确度、召回率等指标。
loss, accuracy = model.evaluate(X_test_scaled, y_test) print(f"Test Accuracy: {accuracy}") -
建议和解释: 利用训练好的模型对新的建筑物数据进行预测。通过阈值设定,将模型输出的概率解释为建筑物应该受到保护的置信度。根据模型的输出,给出建议,例如建议对置信度高的建筑物进行保护。
-
模型解释: 在建议中,考虑将模型的决策过程以可解释的方式呈现,以增加决策的透明度和可理解性。可以使用SHAP(SHapley Additive exPlanations)等方法进行模型解释。
可视化:
- 学习曲线: 学习曲线可视化模型在训练和验证集上的损失(loss)变化。这有助于判断模型是否过拟合或欠拟合。
# 绘制训练损失和验证损失
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
- 准确度曲线: 如果是分类问题,可以绘制模型在训练和验证集上的准确度。
# 绘制训练准确度和验证准确度
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
- 混淆矩阵: 对于分类问题,绘制混淆矩阵可以帮助了解模型在不同类别上的性能。
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 计算混淆矩阵
cm = confusion_matrix(y_test, predicted_labels)
# 可视化混淆矩阵
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues', xticklabels=['Not Protected', 'Protected'], yticklabels=['Not Protected', 'Protected'])
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.show()
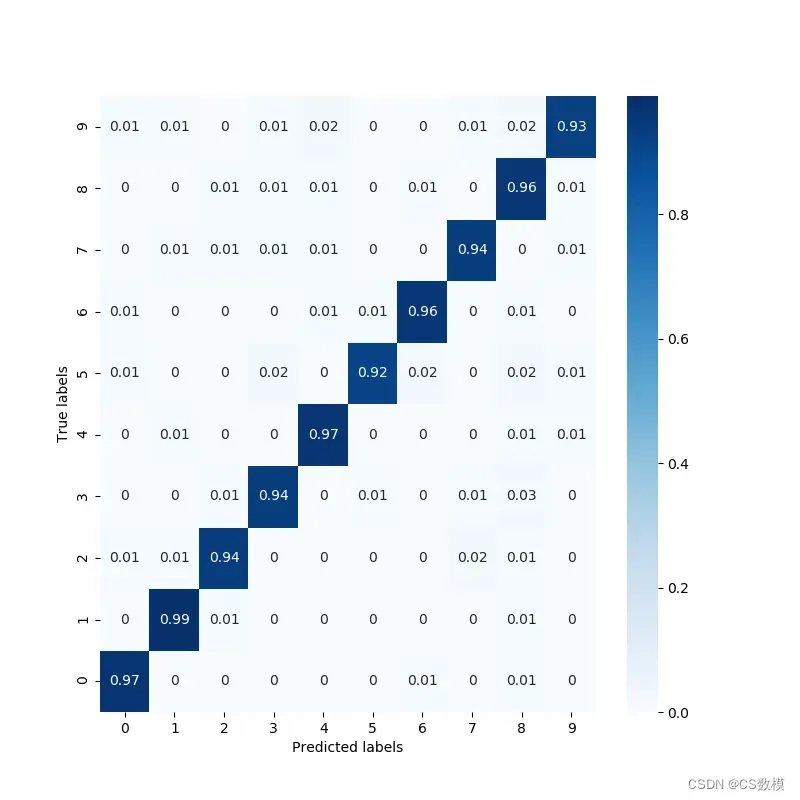

- ROC曲线和AUC: 对于二分类问题,绘制ROC曲线和计算AUC值可以帮助评估模型的性能。
from sklearn.metrics import roc_curve, auc
# 计算 ROC 曲线
fpr, tpr, _ = roc_curve(y_test, predictions)
roc_auc = auc(fpr, tpr)
# 可视化 ROC 曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = {:.2f})'.format(roc_auc))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()
问题五
问题五涉及对历史建筑的保护措施和未来发展的建议。为了解决这个问题,我们可以使用神经网络模型,但与问题四不同,这次我们需要进行多标签分类。每个历史建筑可能涉及多个方面的保护和考虑。以下是建模思路:
-
数据准备: 收集包含历史建筑的各种特征以及与其相关的多个标签的数据。标签可能包括文化保护、历史保护、经济考虑等。确保数据集的质量,包括清理缺失值、处理异常值等。
-
数据标准化: 对特征进行标准化,确保它们具有相似的尺度。
-
多标签分类模型: 构建神经网络模型,适用于多标签分类问题。考虑以下架构:
- 输入层:特征数量对应的神经元。
- 隐藏层:选择适当数量的隐藏层和神经元,使用合适的激活函数,如ReLU。
- 输出层:多个神经元,每个代表一个标签,使用Sigmoid激活函数进行多标签分类。
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense num_labels = len(all_labels) # 替换成实际的标签数量 model = Sequential() model.add(Dense(units=64, activation='relu', input_dim=num_features)) model.add(Dense(units=num_labels, activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) -
模型训练: 使用训练集对模型进行训练。由于这是一个多标签分类问题,需要使用适当的损失函数和评价指标。
model.fit(X_train_scaled, y_train_labels, epochs=10, batch_size=32, validation_data=(X_val_scaled, y_val_labels)) -
模型评估: 使用测试集评估模型的性能。考虑每个标签的准确度、精确度、召回率等指标。
loss, accuracy = model.evaluate(X_test_scaled, y_test_labels) print(f"Test Accuracy: {accuracy}") -
模型预测和建议: 使用训练好的模型对新的历史建筑数据进行预测,得出每个标签的概率。根据概率和领域知识,提出对历史建筑的保护和发展建议。
-
模型解释: 对于每个历史建筑,通过模型输出的概率解释模型的决策过程,以增加决策的透明度和可理解性。
可视化:
在多标签分类问题中,可视化主要侧重于模型性能和预测结果的分析。
-
学习曲线: 可以绘制训练损失和验证损失的学习曲线,以监视模型的训练过程。
import matplotlib.pyplot as plt # 绘制训练损失和验证损失 plt.plot(history.history['loss'], label='Training Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show() -
准确度曲线: 如果是分类问题,可以绘制模型在训练和验证集上的准确度。
# 绘制训练准确度和验证准确度 plt.plot(history.history['accuracy'], label='Training Accuracy') plt.plot(history.history['val_accuracy'], label='Validation Accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show() -
混淆矩阵: 对于多标签分类问题,可以绘制每个标签的混淆矩阵,以了解模型在每个标签上的性能。
from sklearn.metrics import multilabel_confusion_matrix import seaborn as sns # 计算每个标签的混淆矩阵 cm_matrices = multilabel_confusion_matrix(y_test, predicted_labels) # 可视化混淆矩阵 for i, cm in enumerate(cm_matrices): plt.figure() sns.heatmap(cm, annot=True, fmt='g', cmap='Blues', xticklabels=['Negative', 'Positive'], yticklabels=['Negative', 'Positive']) plt.xlabel('Predicted Labels') plt.ylabel('True Labels') plt.title(f'Confusion Matrix for Label {i+1}') plt.show() -
ROC曲线和AUC: 对于每个标签,可以绘制ROC曲线和计算AUC值。
from sklearn.metrics import roc_curve, auc # 计算每个标签的 ROC 曲线和 AUC for i in range(num_labels): fpr, tpr, _ = roc_curve(y_test.iloc[:, i], predictions[:, i]) roc_auc = auc(fpr, tpr) # 可视化 ROC 曲线 plt.figure() plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = {:.2f})'.format(roc_auc)) plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title(f'Receiver Operating Characteristic (ROC) Curve for Label {i+1}') plt.legend(loc='lower right') plt.show()


版权声明:本文为博主作者:CS数模原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_25834913/article/details/135987227