

写在前面:时代在进步,技术在进步,赶紧跑来玩玩
文章目录
- 简介
- 配置要求
- 安装部署
- 下载模型
- 启动ui
- 插件安装教程
- 分区提示词插件
- Adetailer插件
- 提示词的分步采样
- 采样器选择
-
- 采样器的收敛性
- UniPC采样器
- 高分辨率修复 (Hires. fix)
- 图生图
- ControlNet
-
- 介绍
- 控制类型
-
- 线稿类型
- 结构类型
- 参考类型
- 重绘类型
- 总结
简介
Stable Diffusion是一种人工智能(AI)模型,可以根据训练数据创建图像。
Stable Diffusion使用的是一种称为潜在扩散模型(LDM)的东西。
Stable Diffusion用于根据文本提示生成图像,并使用修复和外部绘制的过程改变现有的图像。
参考资料1:
https://www.lifewire.com/what-is-stable-diffusion-7485593
参考资料2:
https://en.wikipedia.org/wiki/Stable_Diffusion
参考资料3:
https://stablediffusionweb.com/
不想写的太长,更详细的介绍请查看参考资料
配置要求
显存 > 6G
内存 > 16G
安装部署
参考资料:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
可以看这个视频:
https://www.bilibili.com/video/BV1gj411R7eQ/
先创建一个环境
conda create --name light python=3.9
然后git clone安装WebUI项目或者下载压缩包,下载慢的话可以使用代理:https://mirror.ghproxy.com/
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
或者国内用代理下载更快
git clone https://mirror.ghproxy.com//https://github.com/AUTOMATIC1111/stable-diffusion-webui
等待WebUI项目下载完成

回到conda环境,
首先,我们需要先安装torch,因为torch默认是装最新的版本不支持我们的CUDA11.7
可以到这个网站https://pytorch.org/get-started/previous-versions/,CTRL+F搜索CUDA 11/12找自己版本对应的pytorch安装pytorch
以我的CUDA 11.7为例子,pip进行安装:
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装python lighting,==后填上自己的版本号,因为我上面pytorch装的2.0.1,所以我pytorch-lightning也装2.0.1
pip install pytorch-lightning==2.0.1 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
提前安装opencv库,这些都是踩了无数坑后才知道的…
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python
安装scipy
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scipy
清华源没有tb_nightly,切换阿里云
pip install tb_nightly -i https://mirrors.aliyun.com/pypi/simple
下载完后进入项目主目录,安装requirements_versions.txt
pip install -r requirements_versions.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
这可能会将花费比较长时间…
下载模型
去https://www.liblib.art/下一个自己喜欢的,注意的是需要下载checkpoint类型模型
全部类型,选择checkpoint
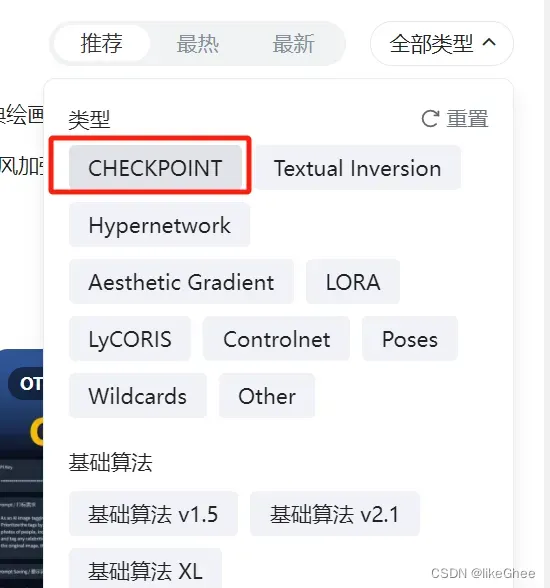

我下载的是lu简笔画风卡通模型_v2.safetensors,大家可以找自己喜欢的,然后把这个文件复制到项目主目录下的models/Stable-diffusion文件夹里

注意这里可能会出现中文乱码的问题,是linux操作系统的问题…很坑
因此,我在服务器上用mv重新命名了一下这个文件名成中文的:
mv lu.safetensors lu简笔画风卡通模型_v2.safetensors

下面是模型推荐:
https://huggingface.co/gsdf/Counterfeit-V2.5
配合EasyNegative使用,上面的萝姬就是用这个模型,很好看,tag写起来也简单。
https://huggingface.co/andite/anything-v4.0
祖师爷,出图质量稳定,插图风格很不错。
https://huggingface.co/datasets/gsdf/EasyNegative
用这个负面tag就可以写很简单了。
https://huggingface.co/TASUKU2023/Chilloutmix
真人模型,不过我没怎么用过,还是喜欢二次元的图,不过之后可能研究配合Lora玩赛博COS。
来源: https://www.bilibili.com/read/cv21987039/
启动ui
启动UI还要远程安装一些文件,
因为我们连不上github,因此我们需要修改一下配置文件,如果你们能连上github就跳过这步:
需要修改的下载github路径配置文件在:
stable-diffusion-webui/modules/launch_utils.py
我们去编辑一下launch_utils.py,推荐先在本地编辑在传会服务器
或者大佬直接用vim
vim modules/launch_utils.py
搜索prepare_environment
在https://github.com开头的网址前面都加上代理网址
https://mirror.ghproxy.com,推荐使用ctrl+r替换
"https://github.com 替换成"https://mirror.ghproxy.com/https://github.com
'https://github.com 替换成'https://mirror.ghproxy.com/https://github.com
注意:这个文件可能会随项目后续更新,所以可能不一定是一样的,各位只能自行判断了。


我们可以看看webui.sh,根据提示,我们应该去webui-user.sh修改一下自己的配置
#!/usr/bin/env bash
#################################################
# Please do not make any changes to this file, #
# change the variables in webui-user.sh instead #
#################################################
修改我自己的webui-user.sh,各位看者自行把握了,毕竟这是我的个人设置了…
重点是:修改python3 executable路径,改成刚刚安装的conda环境light
# python3 executable
python_cmd="/home/$(whoami)/anaconda3/envs/light/bin/python3"
添加执行权限
chmod +x webui.sh
在项目主目录用webui.sh启动
如果你的服务器不能开放端口,那么使用--listen
./webui.sh --listen --no-half --device-id 2
如果可以的话,使用--share
./webui.sh --share --no-half --device-id 2
--no-half表示不用半精度,防止出现黑图像
--device-id表示使用指定的GPU
等待安装下载,喝杯咖啡…
这里就会使用到之前配置的github链接进行下载文件

然后等待模型加载
出现一个报错:
OSError: Can’t load tokenizer for ‘openai/clip-vit-large-patch14’. If you were trying to load it from ‘https://huggingface.co/models’, make sure you don’t have a local directory with the same name. Otherwise, make sure ‘openai/clip-vit-large-patch14’ is the correct path to a directory containing all relevant files for a CLIPTokenizer tokenizer.
解决方案见这篇:
https://blog.csdn.net/SuperB666/article/details/132826492
具体做法是先在这个镜像网站下载所有文件:
https://hf-mirror.com/openai/clip-vit-large-patch14/tree/main
又可以泡杯茶了…
同和解决方案的博客做法一样,创建stable-diffusion-webui/.cache/huggingface/transformers目录,把文件都丢上去
注意:.cache是创建隐藏目录
在两个文件各两处搜索:openai/clip-vit-large-patch14
改成stable-diffusion-webui/.cache/huggingface/transformers的绝对路径,
请自行参考解决方案博客。

这是那两个文件位置:
stable-diffusion-webui/repositories/generative-models/sgm/modules/encoders/modules.py
stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/modules/encoders/modules.py
重新启动webui.sh
出现Model loaded in 21.8s (load weights from disk: 1.3s, create model: 0.6s, apply weights to model: 19.5s, calculate empty prompt: 0.2s).表明启动成功!
然后本地做个隧道
本机设置:
win+r开启cmd,
使用以下命令将本地端口与服务器端相映射:
ssh -L [本地端口]:localhost:[远程端口] [远程用户名]@[远程IP] -p [ssh连接端口]
例如:
ssh -L 7860:localhost:7860 root@172.31.224.191 -p 22
自行更改ip和用户名后,输入密码连接即可
本地访问127.0.0.1:7860

尝试生成一张图片,这个模型看了下显存卡2占用大概是8G左右,
注意:卡0需要有300M的空间预留,不然会OOM
插件安装教程
详细可见参考资料:https://www.bilibili.com/video/BV1Qw411N7uM(推荐观看)
注意:
受限于SD的安全策略 开启监听后默认不允许安装插件
解决办法是在webui-user.sh 的export COMMANDLINE_ARGS 参数中增以下参数
–enable-insecure-extension-access
参考资料:https://zhuanlan.zhihu.com/p/640499741
# Commandline arguments for webui.py, for example: export COMMANDLINE_ARGS="--medvram --opt-split-attention"
export COMMANDLINE_ARGS="--listen --enable-insecure-extension-access"
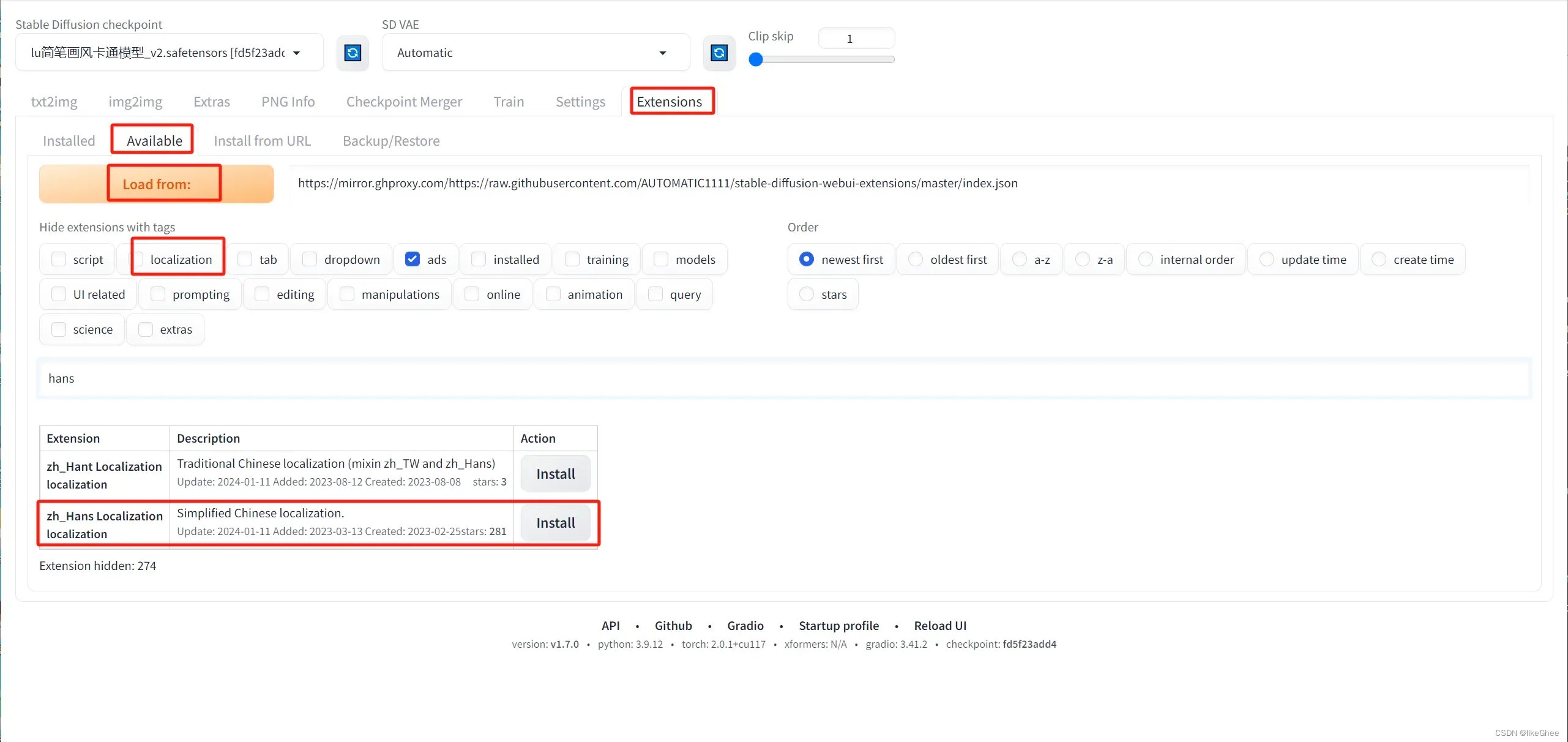
点击extensions-》available
url换成镜像:https://mirror.ghproxy.com/https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui-extensions/master/index.json
点击load from,去掉location,搜索hans,找到zh_Hans Localization
对需要的插件点击install即可,这里我们安装中文汉化

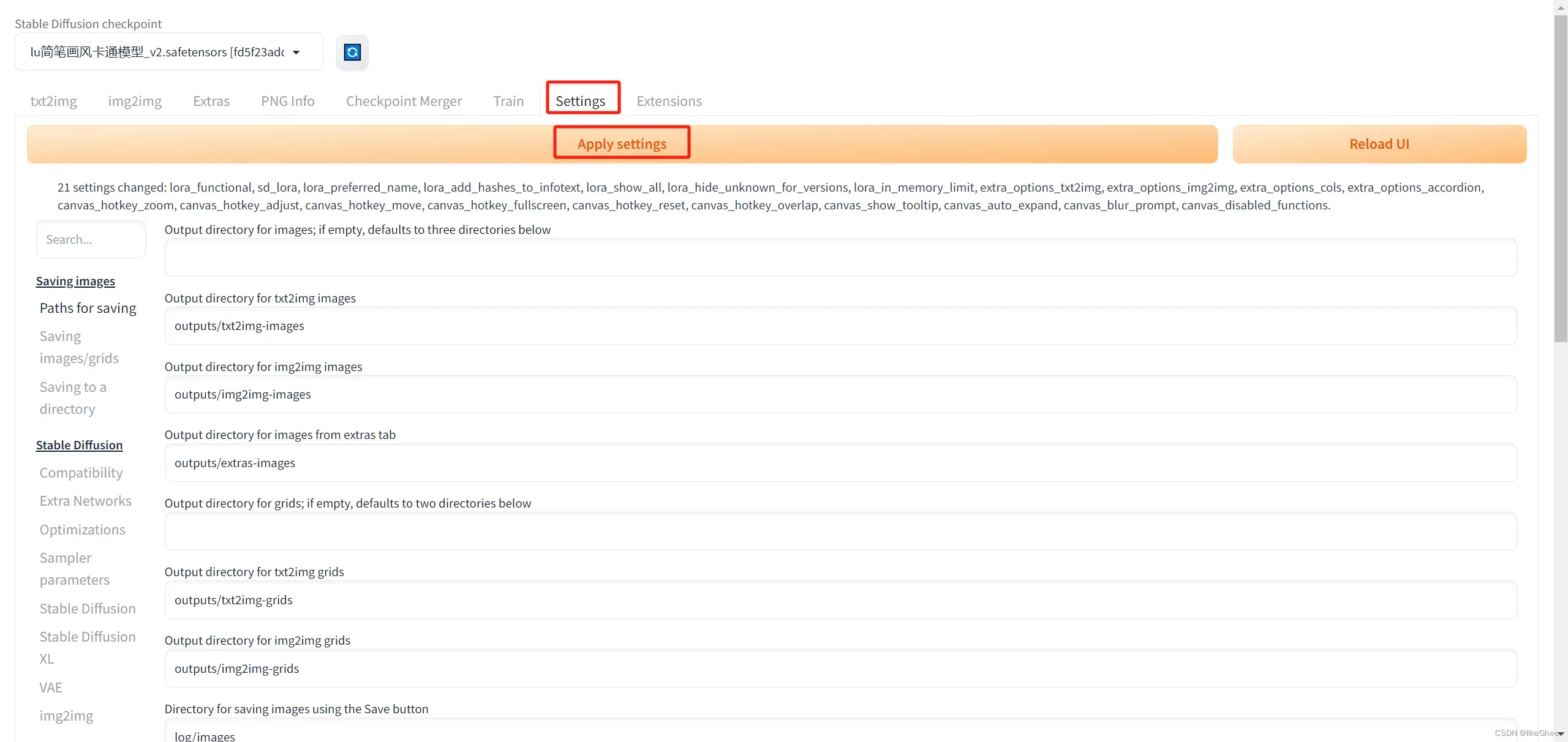
安装好后,去到setting,点击apply setting,最后点击reload UI
再去到setting,找到user interface,到localization选择zh-hans插件,在apply后再重启一边UI

第二种方式使用从url下载,同样的也是安装好后apply setting再reload UI即可
https://github.com/canisminor1990/sd-webui-lobe-theme.git
这里只为了演示,大家仍就可以从安装列表搜索的方式安装
注意:如果因为网络问题安装不了,可以使用代理哦~
https://mirror.ghproxy.com/https://github.com/canisminor1990/sd-webui-lobe-theme.git

最后我们尝试增加两个功能参数在UI,在setting找到user interface,

添加sd_vae和clip_stop_at_last_layers,重启UI
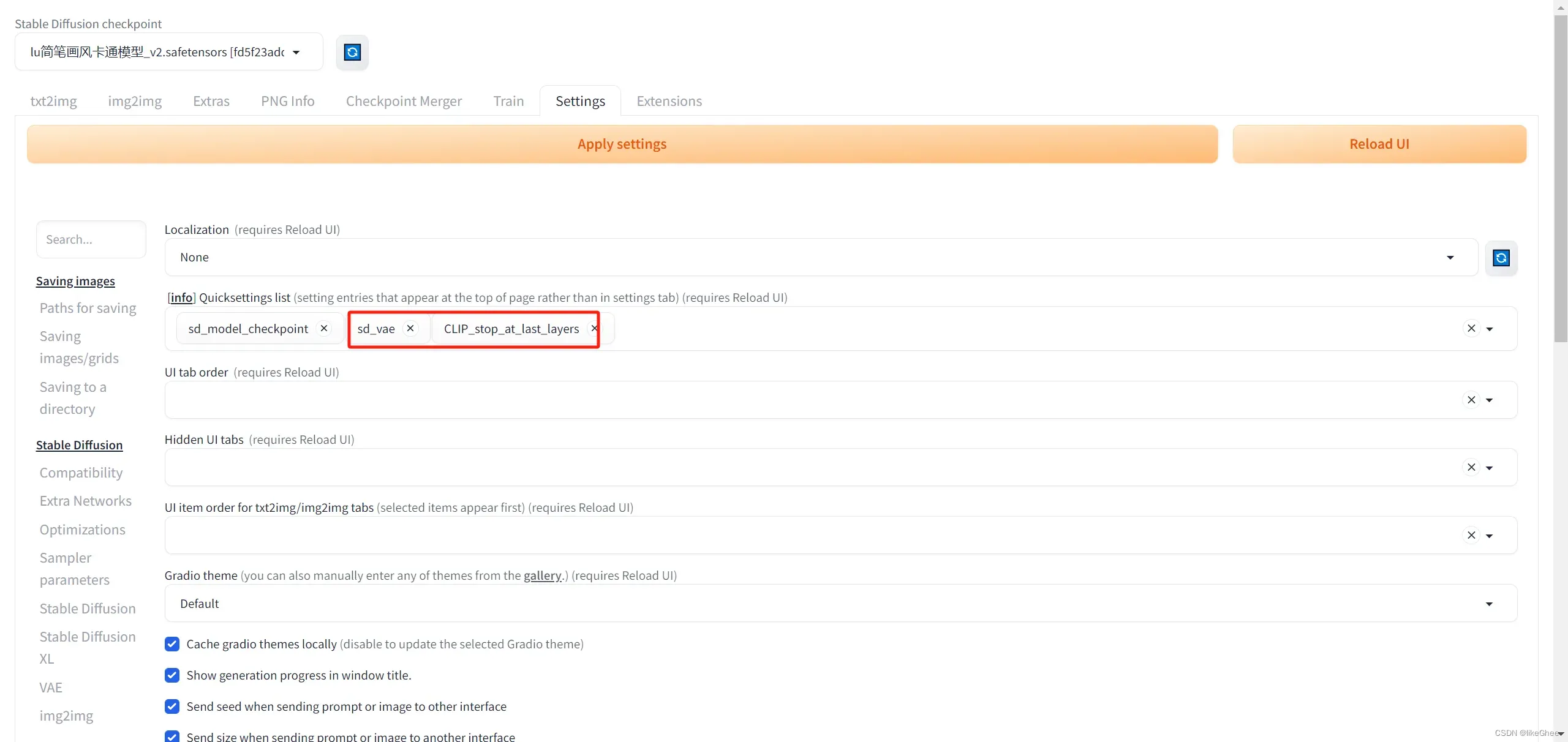
最后设置成功:
分区提示词插件
参考资料:https://www.bilibili.com/video/BV1Fa4y1S7bS/
安装regional prompter
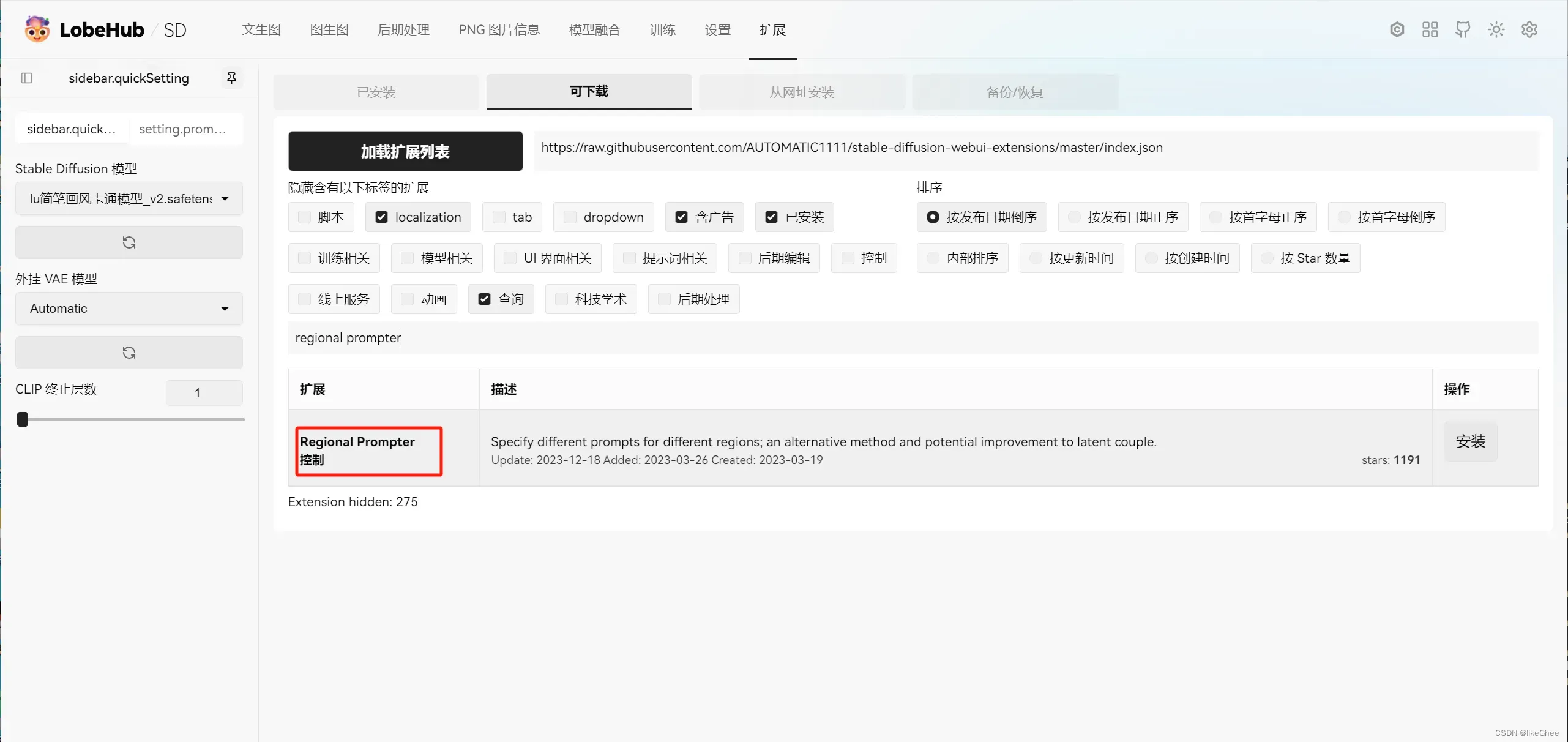
如果网络不好出现:
fatal: unable to access ‘https://github.com/hako-mikan/sd-webui-regional-prompter.git/’: GnuTLS recv error (-110): The TLS connection was non-properly terminated.
那么可以用URL镜像下载:
https://mirror.ghproxy.com/https://github.com/hako-mikan/sd-webui-regional-prompter.git
重启UI,出现regional prompter表示安装成功

打开regional prompter,勾选启用
我发现效果不是很好…我决定换个checkpoint,我下了_GhostInShell_大佬的模型试试,同时查看一下regional prompter更多的教程
参考资料:https://zhuanlan.zhihu.com/p/632947775
关键点:
勾选使用常见提示词,提示词的开头加上公共提示词:
公共提示词
BREAK
区域 0 的提示词
BREAK
区域 1 的提示词
上面我们就有三个提示词:(1)公共提示词;(2) 区域 0 的提示词;(3)区域 1 的提示词。公共提示词会被添加到每个区域的提示词开头。
这是我的例子:
two girl
BREAK
a girl with green hair,red eyes
BREAK
a girl with black hair,green eyes
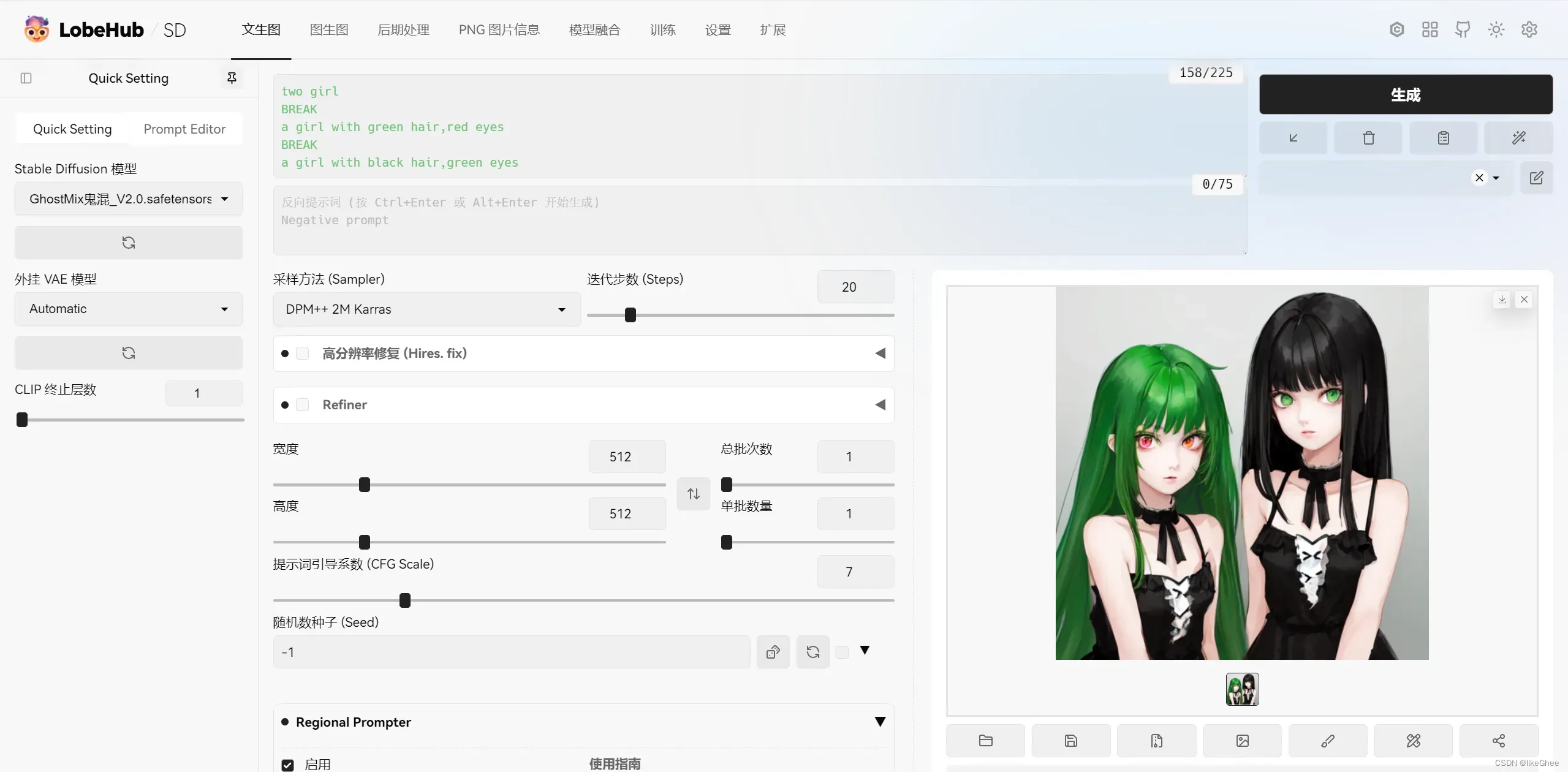

regional prompter的设置

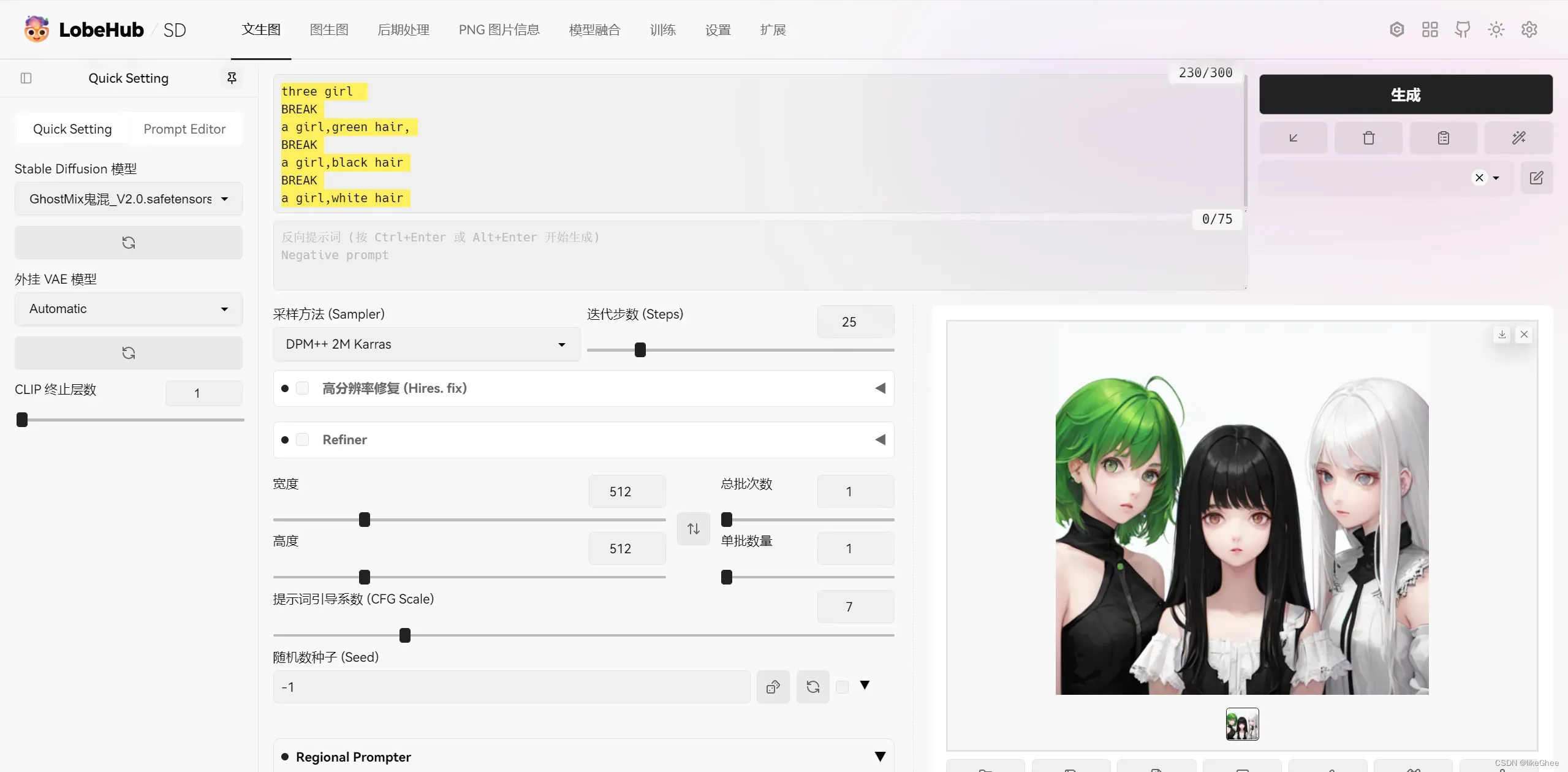
这时候我想画三个人…
那么可以改分割比率为1,1,1

three girl
BREAK
a girl,green hair,
BREAK
a girl,black hair
BREAK
a girl,white hair
总结:
在安装和使用regional prompter时遇到了一些问题。
网络问题可以尝试使用URL镜像下载。
效果不佳的问题,可以尝试更多的模型。
可以查看更多regional prompter的教程,也许有一些技巧可以提高效果,
比如在提示词的开头加上公共提示词以及区域的提示词。
Adetailer插件
Adetailer是人脸重绘修复插件,会自动检测人类生成蒙版进行重绘
官网:https://github.com/Bing-su/adetailer
输入https://github.com/Bing-su/adetailer.git进行安装
也可以通过直接从“扩展”选项卡安装它

选择启用

感觉效果一般…
提示词的分步采样
语法:
[物体1:物体2:介入时机]
决定主框架的物体放在前面,而汲取主特征的物体放在后面,介入时机是0到1之间的小数,表示从百分之多少开始介入
先抽卡-》确定种子-》设置介入参数
一般从0.3开始尝试,提前介入0.2会太早
物体2可以采用1.5倍强调
推荐流程:抽卡-》固定种子-》设置参数[物体1:(物体2:1.x):0.3] -》设置参数[物体1:(物体2:1.x):0.x]
采样器选择
参考资料:https://www.bilibili.com/video/BV1FN411i7sB/ (Stable diffusion采样器全解析,30种采样算法教程,推荐观看)

图片来源:https://www.bilibili.com/opus/838501405743382562

采样器的收敛性
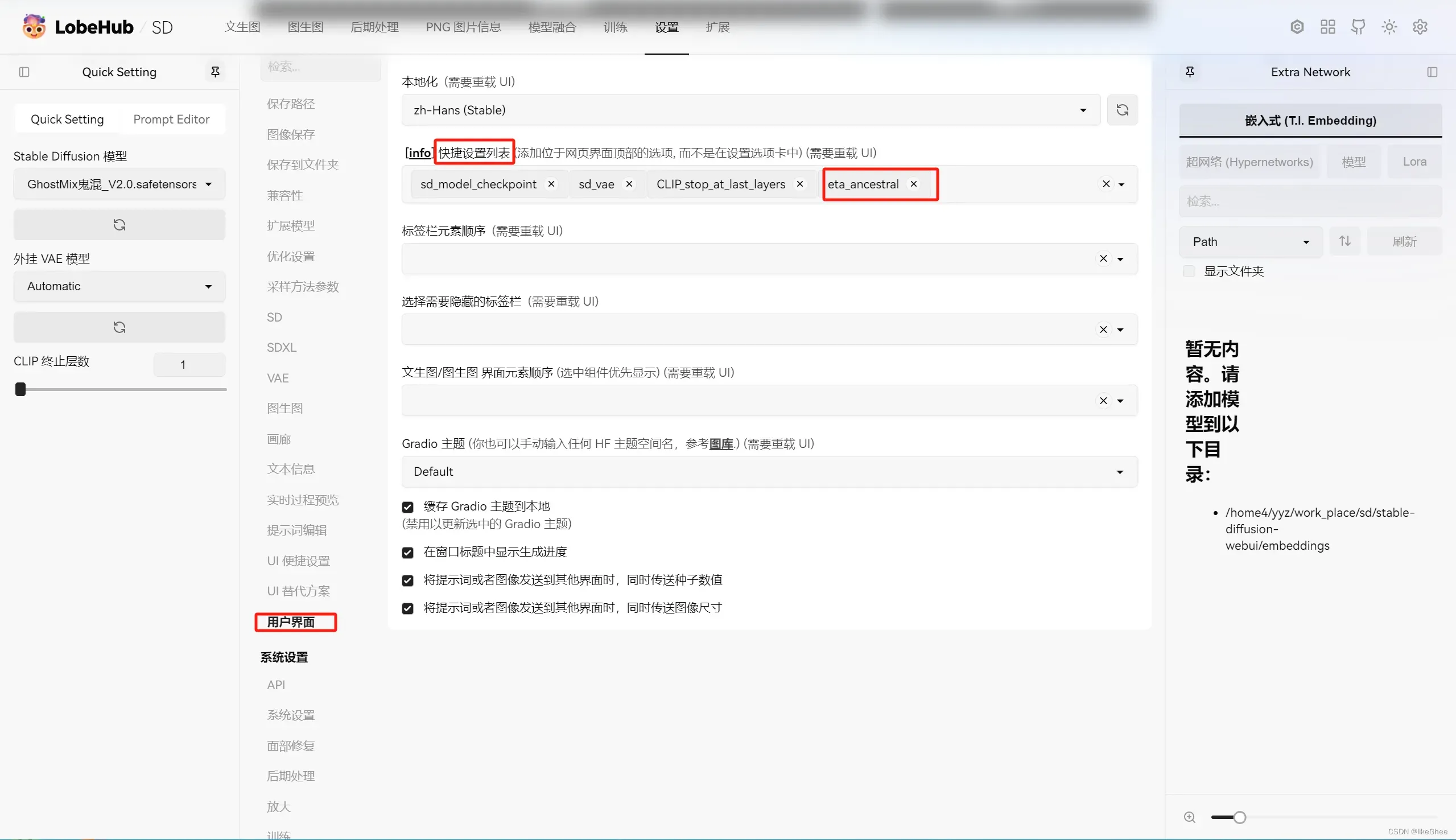
如SDE不收敛采样器,收敛性并非一成不变,ETA参数即噪声倍率值,控制添加噪声的强度,进而控制发散程度,甚至可以完全关闭,在设置中找到采样方法Eta系数:


可以将这个参数添加到快捷键:
选择2M SDE Karras采样器做实验


使用脚本,画XYZ plot
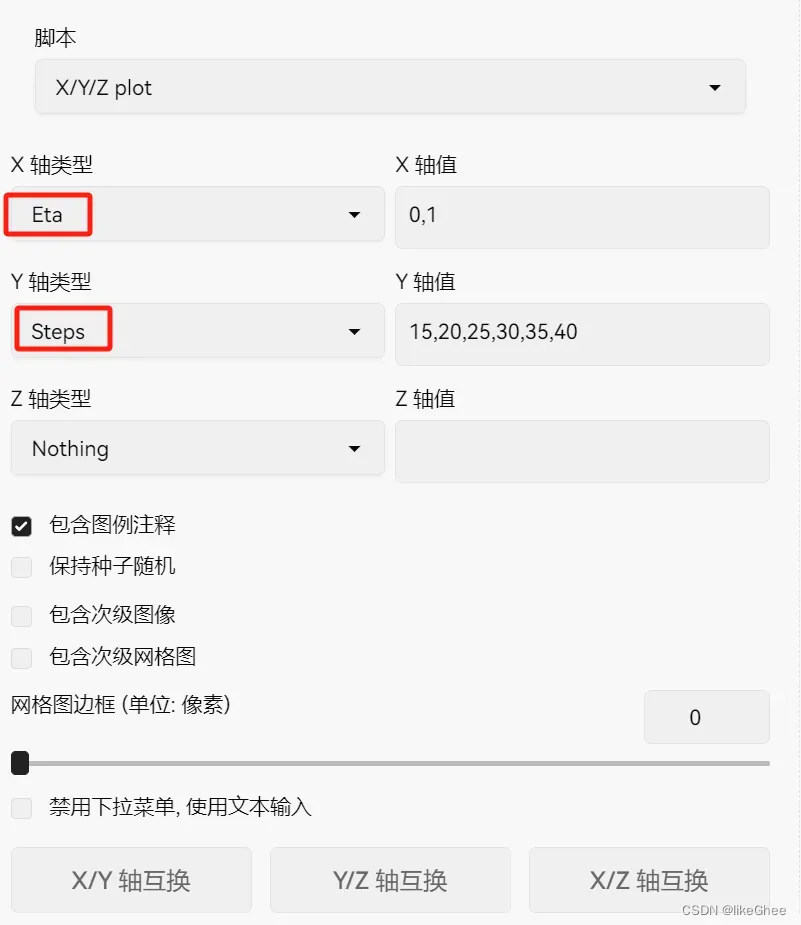
ETA为1时不收敛,ETA为0有收敛趋势



UniPC采样器
优势:最新采样器,低步数快速出图
参数有:
UniPC variant
UniPC skip type
UniPC order
UniPC lower order final
将这4个参数添加到快捷菜单中:
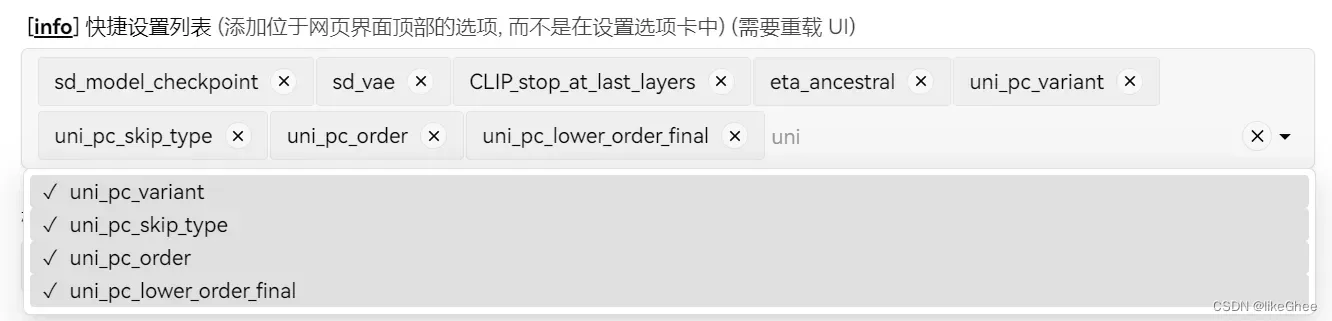
首先是变体,有三个,当步骤 < 10 时,建议使用 bh1 进行无条件采样,否则使用 bh2。
什么是无条件采样,那就无任何提示词
solver_type (str, default bh2) — Solver type for UniPC. It is recommended to use bh1 for unconditional sampling when steps < 10, and bh2 otherwise.
参考资料:https://huggingface.co/docs/diffusers/main/en/api/schedulers/unipc
我们使用uniPC时候,应该使用bh2,cfg值适当降低至3~4



第二参数,UniPC skip type:
>51*512选 time_uniform
<512*512选logSNR
两者都不行,请尝试time_quadratic
选择time_uniform即可,因为大部分场景不会涉及小于512的情况


第三个参数,UniPC order
这个值我们需要微调
生成器会先生成高阶特征,再生成低阶特征
高阶特征:图像中具有较高层次结构的特征,如场景,体型,信号处理中的低频部分,可以理解成高斯模糊后图片的大光影结构
低阶特征:图像中具有较低层次结构的特征,如边缘,纹理,信号处理中的高频部分
低阶步数就是生成低阶特征的步数,一般不会设置太大,1~3之间就行
官网建议:solver_order (int, default 2) — The UniPC order which can be any positive integer. The effective order of accuracy is solver_order + 1 due to the UniC. It is recommended to use solver_order=2 for guided sampling, and solver_order=3 for unconditional sampling.
solver_order (int, 默认值 2) — UniPC 顺序,可以是任何正整数。由于 UniC 的原因,有效精度顺序为 solver_order + 1。建议使用 solver_order=2 进行引导采样,使用 solver_order=3 进行无条件采样。
记住默认为有条件为2就好
其实可以按照画面需求进行设置,如果觉得画面太过平滑,可以设置成3,4…但是过高手部会出现奇怪细节
也就是步数越高,细节更多,越 不够唯美


第四个参数,UniPC lower order final保持勾选即可,不然会出现鬼图
高分辨率修复 (Hires. fix)
参考资料:https://medium.com/rendernet/using-hires-fix-to-upscale-your-stable-diffusion-images-8d8e2826593e
先生成低分辨率再超分
下面这几个比较常用:latent效果个人感觉不好


放大倍数,不要调太大会占不下显存
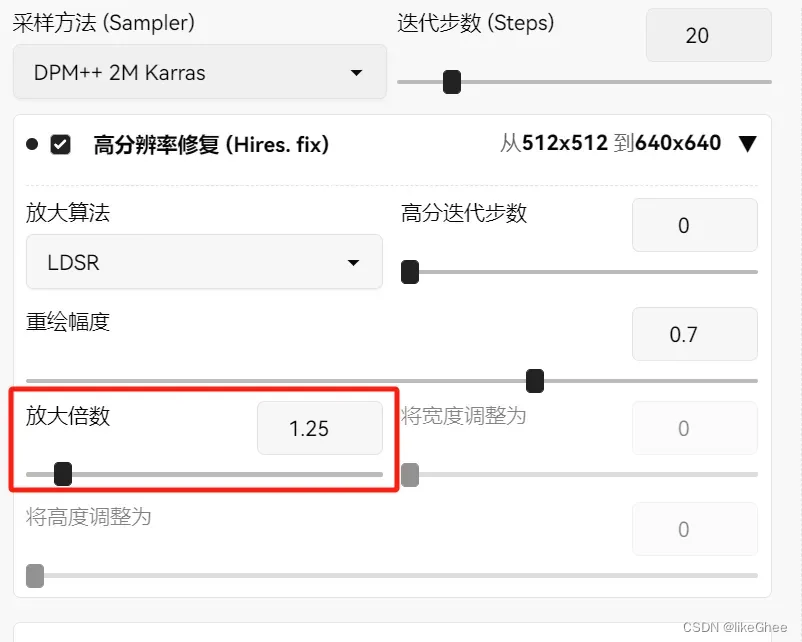

可以在 0–150 范围内设置 HiRes 步长
将其保持为 0 会使 HiRes 步骤 = 采样步骤
因此,如果您的采样步数为 20,而 HiRes 步数为 0,则总步数为 40。
选择正确的 HiRes 步数非常重要,因为将其设置得太低或太高都会使图像结果恶化。我们发现选择 10-15 个 一般效果较佳
但是,如果采样步数超过 50,那么最好将 HiRes 步数设置为采样步数的一半。
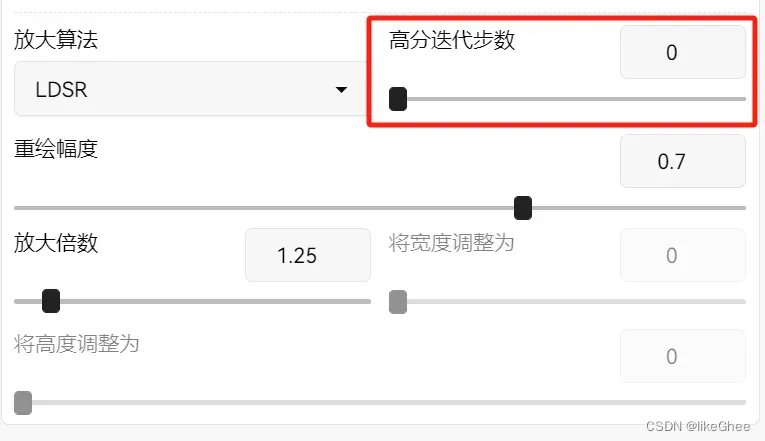

去噪,默认降噪强度为0.7。然而,在很多情况下,这往往过于强烈。
建议首先使用 0.3–0.5 之间的值,然后根据结果将其调高或调低
如果出现网络问题无法下载:Unable to load RealESRGAN model https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth
那么可以自行下载一下,根据提示丢到
stable-diffusion-webui/models/RealESRGAN/RealESRGAN_x4plus_anime_6B.pth
个人感觉比较占显存,放大2倍就要16G显存了。
图生图
图生图必装:Interrogate图像反推
下面是Interrogate模型:
https://github.com/AUTOMATIC1111/TorchDeepDanbooru/releases/download/v1/model-resnet_custom_v3.pt
放至stable-diffusion-webui/models/torch_deepdanbooru/
记得重启项目,上传图片,点击Interrogate(下图红色框框位置),自动填充prompt,然后点生成
当然可以自己调整一下参数


刚刚用的就是最基础的图生图,在原图上修改,如高清转化,图片放大等。下面介绍其他几个功能:
涂鸦模式,是在原图上进行简单的手绘,让AI完成润色
局部重绘,需要重绘的地方用画笔画出来,写好提示词
涂鸦重绘,类似局部重绘,会多考虑颜色
上传重绘蒙版,其实就是局部重绘
批处理,用的不多
参数调整:
重绘幅度,对原图的改造程度,大家可以0~1自己调整试试,取决于自己的需求

缩放图像

仅调整大小如果长宽比不一致会出现拉伸,那么可以选择裁剪后缩放,
缩放后填充空白,有点像重绘
潜空间放大,在潜空间进行,这时候要调高cfg


类似PS羽化效果,透明程度越高被影响越小

小幅修改使用原版
大幅修改,但又不想产生割裂,使用填充
更多的自由发挥空间,使用潜空间噪声或者空白潜空间,注意的是这里需要搭配较高cfg



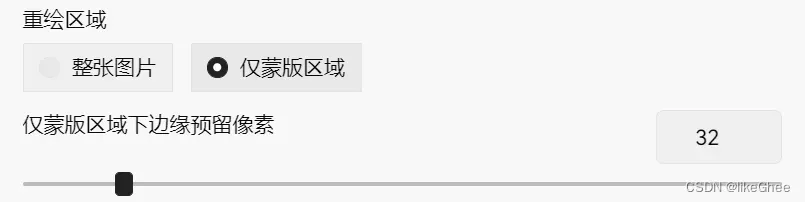
重绘区域,仅蒙版区域下面的预留边缘像素才会生效

ControlNet
介绍
ControlNet是一种网络结构,通过添加额外控制条件,来控制出图效果。
参考资料:
https://github.com/Mikubill/sd-webui-controlnet(官网,适合高玩直接上手)
https://openai.wiki/controlnet-install.html(推荐新手照着做)
https://openai.wiki/controlnet-models-download.html (模型下载,当然我下面也提供百度盘)
首先安装ControlNet插件,然后下载模型:
打开“扩展”选项卡。
在选项卡中打开“从 URL 安装”选项卡。
输入https://github.com/Mikubill/sd-webui-controlnet.git
(下不动的话使用代理,https://mirror.ghproxy.com/https://github.com/Mikubill/sd-webui-controlnet.git)
安装后等消息:已安装到 stable-diffusion-webui\extensions\sd-webui-controlnet。
切换到设置,应用并重新启动 UI
完全重新启动 webui,退出启动的应用,重新用webui.sh启动
重启提示:ControlNet init warning: Unable to install insightface automatically. Please try run pip install insightface manually.
手动安装pip install insightface即可,注意切换环境
目前ControlNet 1.1的所有14个模型都处于beta测试阶段。
从 ControlNet 1.1 下载模型:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
您需要下载以“.pth”结尾的模型文件。
将模型放入stable-diffusion-webui\extensions\sd-webui-controlnet\models中。只需要下载“pth”文件。


请勿右键单击 HuggingFace 网站中的文件名进行下载。一些用户右键单击这些 HuggingFace HTML 网站,并将这些 HTML 页面保存为 PTH/YAML 文件。他们没有下载正确的文件。请点击 HuggingFace 中的小下载箭头“↓”图标进行下载。
我提供了百度盘可以用百度盘下载,失效了记得踹我一脚
Sd15模型:
链接:https://pan.baidu.com/s/1f8Ya8mnD379yIb0uZCG75w?pwd=2jem
提取码:2jem
sdxl模型:
链接:https://pan.baidu.com/s/1z_TtoQ_EdQbL8YiumCns7Q?pwd=nip8
提取码:nip8
本地存放地址:[你安装sd的位置]/stable-diffusion-webui/extensions/sd-webui-controlnet/models
注意玩的模型目前主流的是SD1.5和SDXL,当然你可以选择你需要的模型进行下载,反正我是一股脑全扔上去了
像我现在用的鬼混模型就是SD1.5,但还是把SDXL装了(其实可以不装)
下面是SD1.5的ControlNet模型介绍,关于模型的描述为官方描述【机器翻译】,可供参考。
ControlNet/models/control_sd15_canny.pth
ControlNet+SD1.5 模型,用于使用精明边缘检测来控制 SD。
ControlNet/models/control_sd15_depth.pth
ControlNet+SD1.5模型使用Midas深度估计来控制SD。
ControlNet/models/control_sd15_hed.pth
ControlNet+SD1.5 型号使用 HED 边缘检测(软边缘)控制 SD。
ControlNet/models/control_sd15_mlsd.pth
ControlNet+SD1.5模型使用M-LSD线检测来控制SD(也可以与传统的Hough变换一起使用)。
ControlNet/models/control_sd15_normal.pth
ControlNet+SD1.5 模型使用法线贴图控制 SD。最好使用该 Gradio 应用程序生成的法线贴图。只要方向正确,其他法线贴图也可以工作(左边看红色,右边看蓝色,上看绿色,下看紫色)。
ControlNet/models/control_sd15_openpose.pth
ControlNet+SD1.5 模型,使用 OpenPose 姿势检测控制 SD。直接操纵姿势骨架也应该有效。
ControlNet/models/control_sd15_scribble.pth
ControlNet+SD1.5模型使用人类涂鸦控制SD。该模型使用边界边缘进行训练,具有非常强大的数据增强功能,以模拟类似于人类绘制的边界线。
ControlNet/models/control_sd15_seg.pth
ControlNet+SD1.5模型使用语义分割来控制SD。协议是ADE20k。
ControlNet/annotator/ckpts/body_pose_model.pth
第三方模型:Openpose的姿势检测模型。
ControlNet/annotator/ckpts/hand_pose_model.pth
第三方模型:Openpose的手部检测模型。
ControlNet/annotator/ckpts/dpt_hybrid-midas-501f0c75.pt
第三方模型:迈达斯深度估计模型。
ControlNet/annotator/ckpts/mlsd_large_512_fp32.pth
第三方模型:M-LSD检测模型。
ControlNet/annotator/ckpts/mlsd_tiny_512_fp32.pth
第三方模型:M-LSD的另一个较小的检测模型(我们不使用这个)。
ControlNet/annotator/ckpts/network-bsds500.pth
第三方模型:霍尔效应器件边界检测。
ControlNet/annotator/ckpts/upernet_global_small.pth
第三方模型:Uniformer 语义分割。
泡杯咖啡吧…少女下载中…
下载模型
将模型放入正确的文件夹后,您可能需要刷新才能看到模型。刷新按钮位于“模型”下拉列表的右侧。
我选择直接重启应用…
出现Warning问题:
Warning: ControlNet failed to sync submodules. Please try run `git submodule init` and `git submodule update` manually.
解决方案参考:https://github.com/Mikubill/sd-webui-controlnet/pull/2428
反正是warning,就不管了
下面是安装好了模型,下面从控制类型开始介绍吧
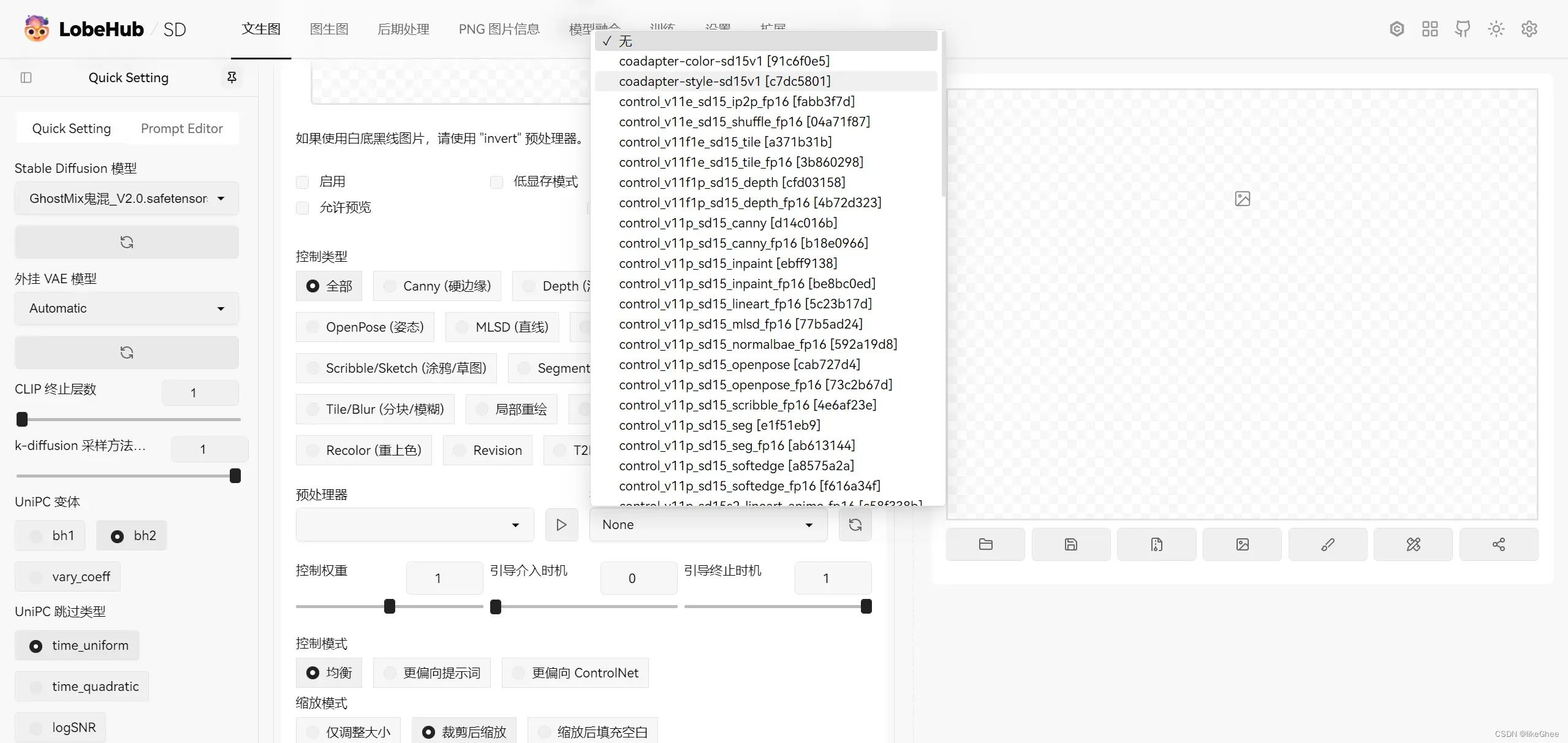
控制类型
控制类型用于固定画面的基本结构
注意:在使用的时候可能会下载额外的模型,大家自行下载放至指定的位置即可,比如:Downloading: “https://huggingface.co/lllyasviel/Annotators/resolve/main/res101.pth” to /home4/likeghee/work_place/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads/leres/res101.pth。那么就下载这个pth放到stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads/leres下面即可
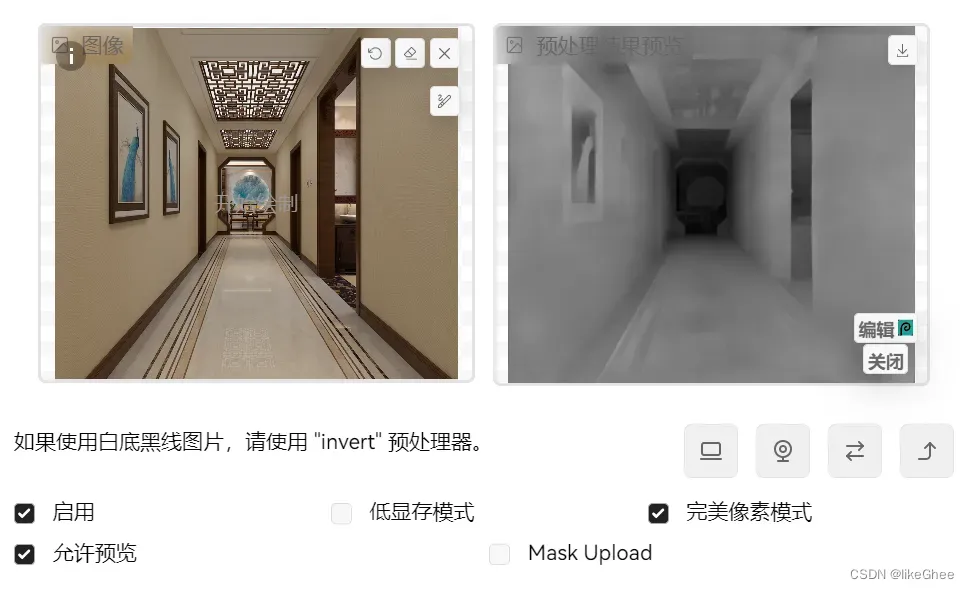
我们启controlnet,打开允许预览,勾选完美像素模式,不要勾选低显存模式,是用你的CPU来跑的
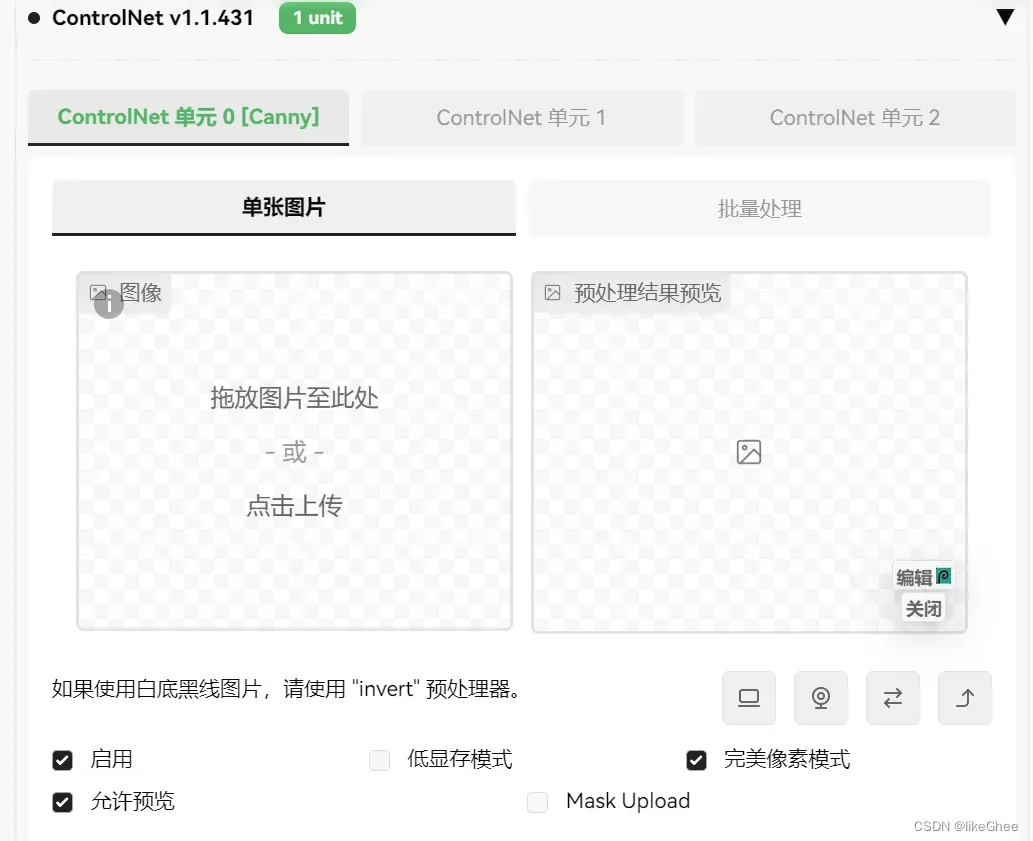

完美像素模式,1.1版本的新功能,作用是自动计算分辨率


线稿类型
那么一般的线稿类型有: Canny,软边缘,涂鸦,线稿,直线
选择Canny,点击下面的执行按钮,我们就可以在预处理结果预览看到结果
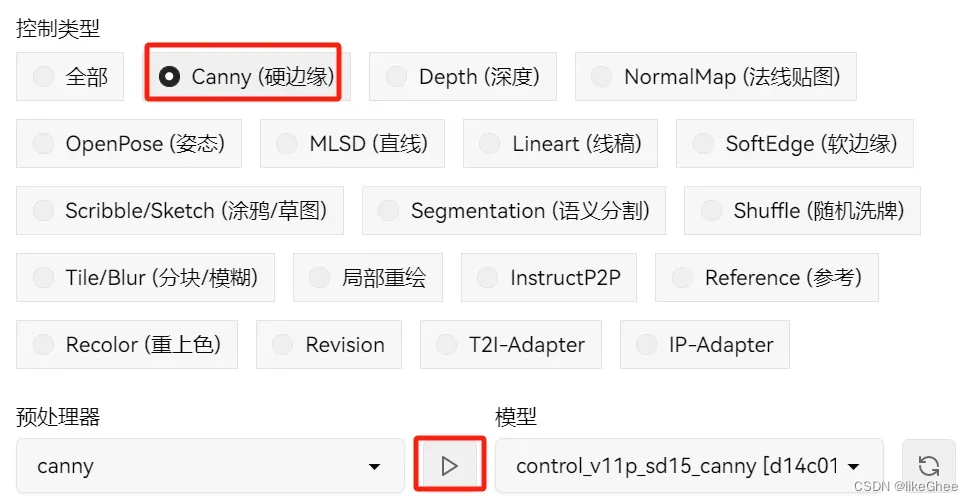
写上提示词,生成图片,你会发现生成的图片就固定了画面的基本结构
Canny是边缘检测算法,根据灰度梯度判断图片边缘,那么自然就有梯度阈值进行过滤,越低保留的线条越多。
实际使用还是靠感觉了


软边缘有四种提取算法,软边缘一般有过渡效果,没有那么锐利,具体作用不详
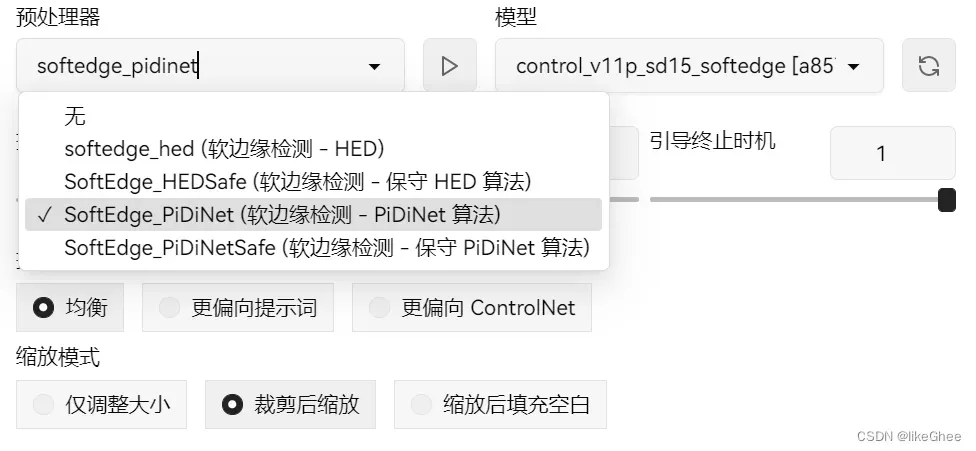
涂鸦,提取线稿比较粗糙,不常用
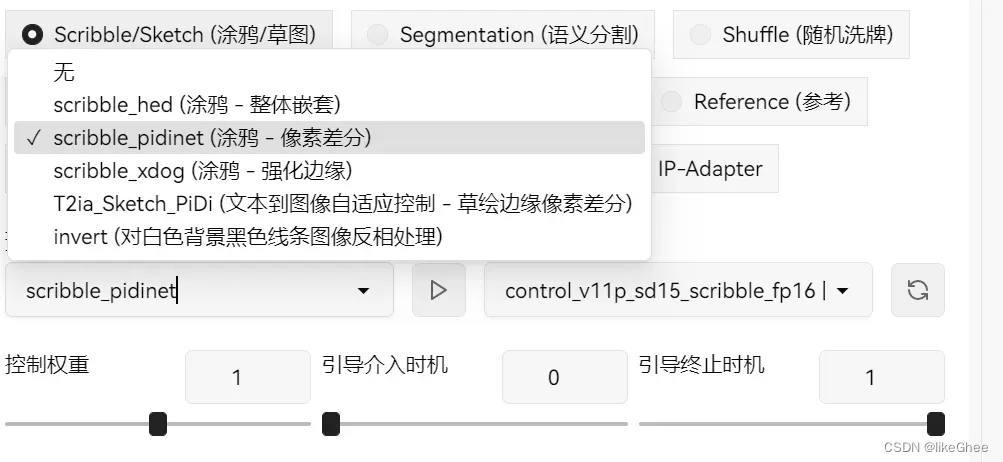



线稿,类似手绘的线稿,动漫类线稿比写实类线稿细节更少,按自己需求使用
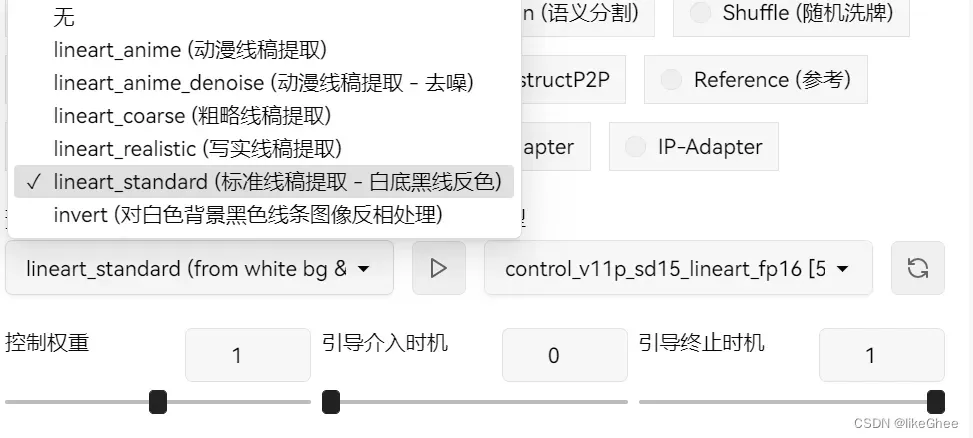

直线,只提取直线,弯曲线条忽略,不适合人像图,适合建筑之类的


结构类型
深度,提取图片的深度来控制出图效果,越黑表示离我们越远,越白的部分离我们越近,不同算法提取的深度细节同,可以根据自己的需求选择

法线图,空间中平面方向的信息图,与深度图类似,用于传输图像中的空间的一个组成,会有不同颜色,其实就是颜色表示平面所对的那个方向,算法选用bae即可


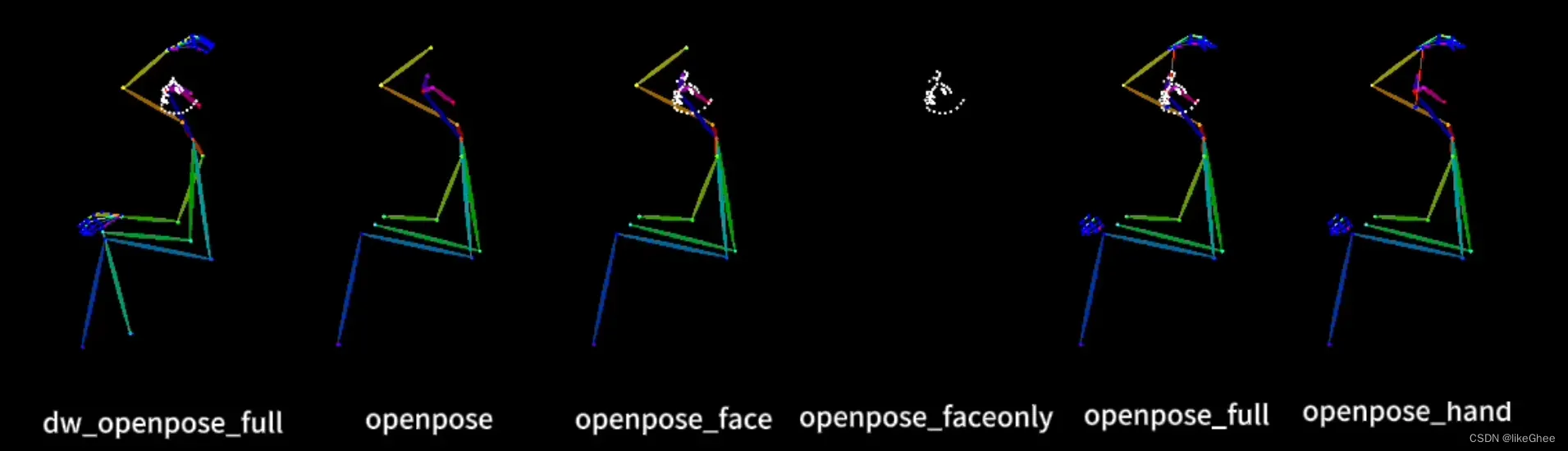
姿态,控制人物面部和肢体动作的控制器,目前来看面部特征识别效果还不是不太行,要用的话直接选DW_openpose_full这个算法即可,使用了双向卷积处理图像,效果更好也更快

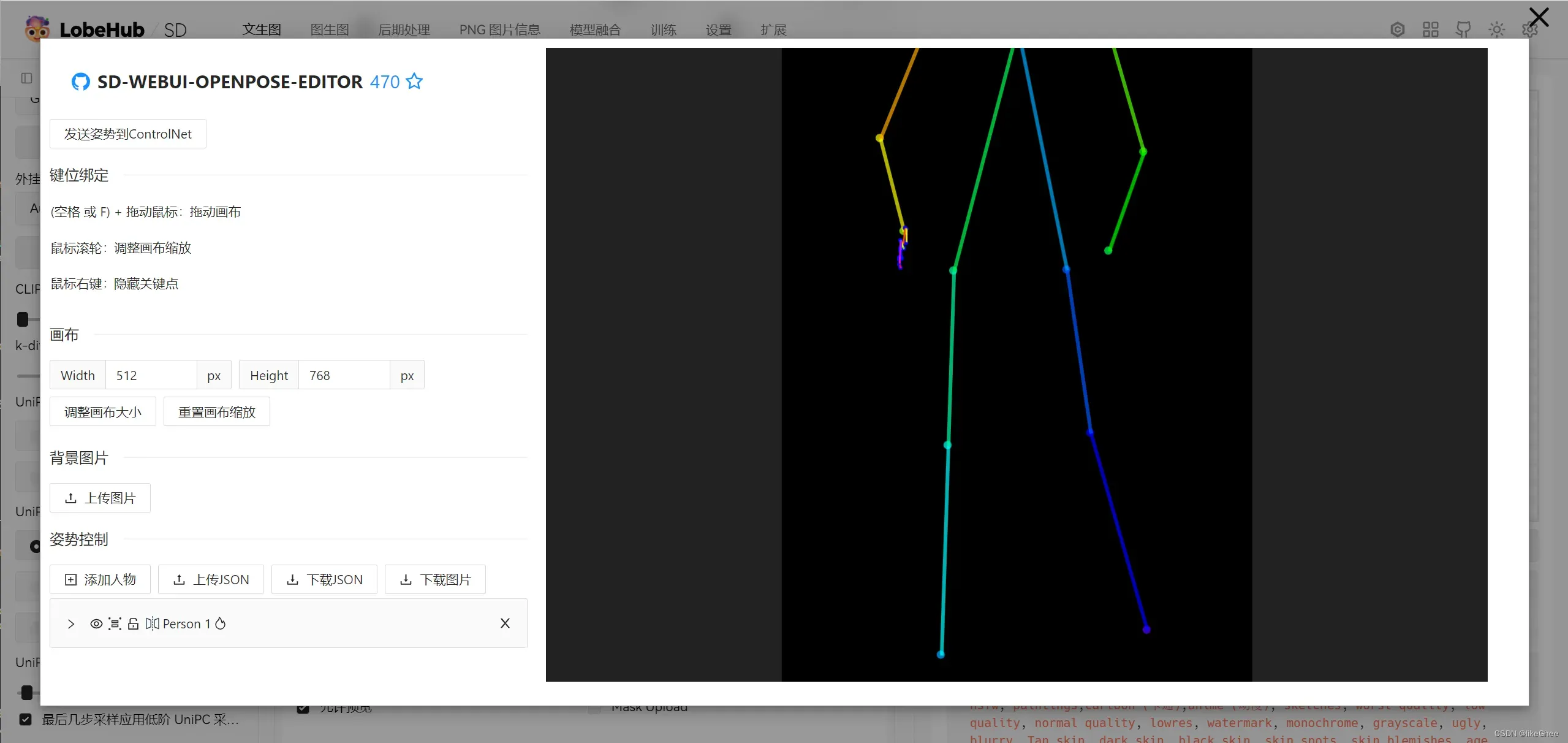
我们可以使用open pose editor来编辑骨骼,然后发送姿势回controlNet
语义分割,自动识别画面中的物体,并分割成不同的区域,然后用不同的颜色表示,一般情况下20K优于coco,这个数据集做CV的应该很熟悉了,COCO数据集数据种类不多,算法方面OneFormer更快更准确,直接用默认的即可。


参考类型
Reference控制器
用输入图片作为参考来控制AI出图的一种控制器,adain只会进行视觉分割迁移,only会迁移内容,adain+attn是二者的结合,可以理解为参考原始内容并且ai还会有一定程度的发挥

风格忠诚度参数可以调节,越大越忠于原图

个人觉得这个参考的控制还不太稳定


修订控制器
将上传图片作为条件作为输出,但是我们一般用咒语,这里提出了图片也能作为条件作为控制,建议直接使用作为补充

参数噪声增强,只有0和1选择有点类似ETA参数,可以理解成AI是否自我发挥



InstructP2P控制器
类似图生图,感觉作用不强
shuffle控制器
只是像素打乱,用于画风迁移,感觉作用不强
IP-Adapter控制器
类似修订,但是效果更好,推荐使用plus版本


重绘类型
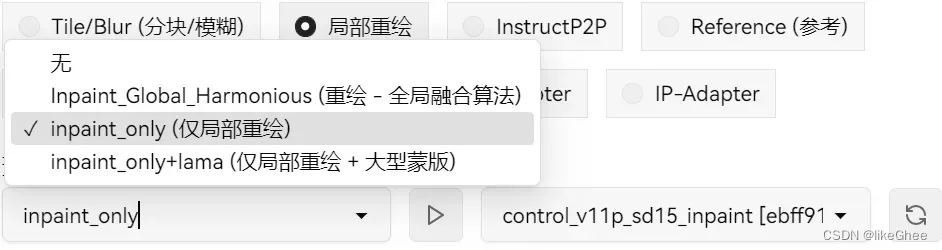
局部重绘
图生图也有局部重绘,但是会出现画面撕裂扭曲,ctrlnet就是为了解决这个问题
可以选择only预处理器,第一个和第二个是一样的,
+lama会产生一个比较干净的画面,会用lama模型先对图像进行预处理

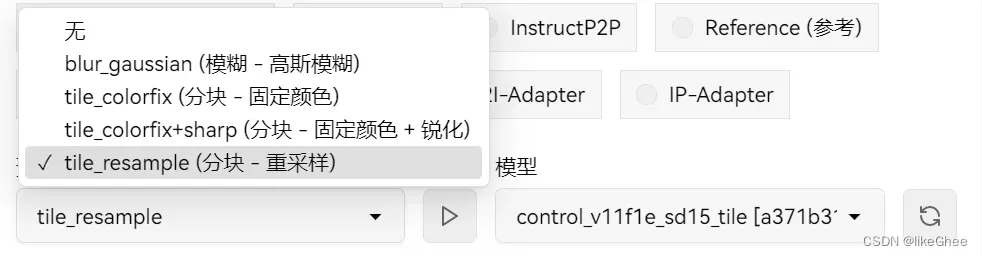
分块/模糊
分块就是先分割成若干块,并识别出每块信息,好处是分块处理减小硬件的压力。
如果提示词与某块中的对象匹配,就会不改变对象定义的情况下,生成新的细节,
如果提示词与某块中的对象不匹配,那就以对象为准,降低提示词的影响,
以此达到局部和全局的统一

重上色
给图片重上色彩风格,如老照片的上色
总结
介绍了这么多控制器,建议还是看看别人更多的成功案例,我这里并不深入,可能给不了太多的启发…
并且没有介绍组合单元用法,更多的功能就交给各位自行探索了…


版权声明:本文为博主作者:likeGhee原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_19841133/article/details/135547002