

前言
由于之前存在过对两者的区别考虑,所以把他们放在一起来说,更加容易区别和理解
对于有关线性表的概念这里就不展示了,这里主要是介绍线性表里面的这两个结构的知识点
一.顺序表
1.顺序表介绍


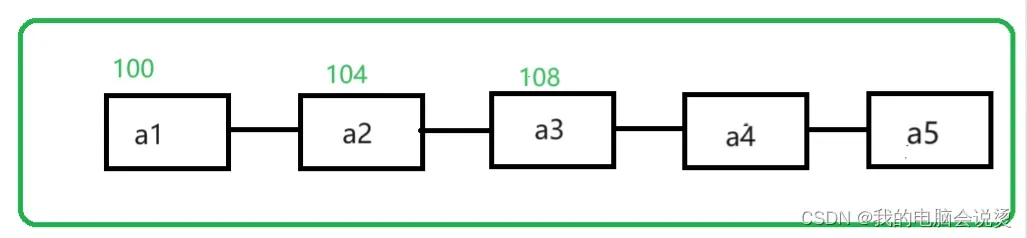
顺序表的存储结构和逻辑结构都是相邻的, 这里如果我们把a1的地址设置成100,假设每个元素占4个存储空间,那么a2就是104,a3就是108,依次往下 ,所以只要确定起始位置,后面的位置都能找到,这也就代表了可以随机存取,这句话请记住,和后面链表的区别有关。

顺序表的底层结构就是数组,其实你把它当作数组来看也不是不行,同时顺序表采用的是顺序存储结构,对与数组的操作一般有增删查改,和之前的通讯录差不多,大家可以参考一下之前的通讯录 动态顺序表的实现,其实也有静态版本,但是静态版本有缺陷
typedef int SLDataType;
#define N 7
typedef struct SeqList
{
SLDataType a[N];//数组长度
int size;//当前有效数据个数
}SL;可以很明显的看出,N是固定的,所以大小不能随便改变,但是如果用动态的方法去用malloc开辟一片空间,那么这个空间用realloc去增容,那这块空间就是可以随时变化的
typedef int SLDataType;
typedef struct SeqList
{
SLDataType *a;
int size;//有效数据
int capacity;//容量,如果不够,就用realloc去增容
}SL;动态分配的空间是在堆上开辟的,静态分配是在栈上开辟的,两者的开辟空间不一样,所以动态开辟需要自己主动去释放空间,而且需要一个指针去指向这个空间,因为你需要知道它的地址才能对它进行一个操作,而静态的因为是数组,数组名就代表了它的地址
2. 顺序表的实现
1.初始化表
2.插入元素
3.删除元素
4.查找元素
5.修改元素
初始化
void SLInit(SL *psl) {
psl->a = (SLDatatype*)malloc(sizeof(SLDatatype) * 4);//先开辟这么多大小
if (psl == NULL) {
perror("malloc fail");
return;
}
psl->sz = 0;
psl->capacity =4;//分别把结构体里的元素初始化
}静态版本的初始化就是遍历整个顺序表的元数,把他们全设置为0。
这里的空间要记得用free释放,不然会有内存泄露
容量不够的时候,就增容,这个函数一般反正插入数据的函数里面
void SLCheckBack(SL* psl) {
if (psl->sz == psl->capacity) {
SLDatatype *tmp = (SLDatatype*)realloc(psl->a, sizeof(SLDatatype) * psl->capacity*2);//如果容量不够了,那么就增容
if (tmp == NULL) {
perror("realloc fail");//扩容失败,把错误信息打印出来
return;
}
psl->a = tmp;
psl->capacity *= 2;
}
}插入元素
插入元素有头插和尾插,还有中间插入,其实很简单,就把它当作数组来做就行了,因为用malloc开辟的空间是连续的,那么放进去的元素也是连续的,还有一点就是这里要判断是否要扩容。还有就是头插和中间插入的时候要移动数据
时间复杂度O(N)
void SLPushBack(SL* psl, SLDatatype x) {
SLCheckBack(psl);//判断
psl->a[psl->sz++] = x;
} //尾插
void SLPushFron(SL* psl, SLDatatype x) {
SLCheckBack(psl);
for (int i = psl->sz - 1; i >= 0; i--) {//这里需要移动数据,把他们都往后移一位
psl->a[i+1]=psl->a[i];
}
psl->a[0] = x;
psl->sz++;
}//头插
void SLInsert(SL* psl, int pos, SLDatatype x){//中间插入
assert(pos >= 0 && pos <= psl->sz);这里插入的位置不能出错,不然会越界,所以用assert断言
SLCheckBack(psl);
for (int i = psl->sz - 1; i >= psl->sz - pos; i--) {
psl->a[i + 1] = psl->a[i];
}
psl ->a[pos-1] = x;
psl->sz++;
}
删除元素
删除元素和插入有些类似,删除头和中间的需要把数据往前面移动,删除最后的则不需要
时间复杂度位 O(N)
void SLPopBack(SL* psl) {
assert(psl->sz >= 0);
psl->sz--;
}//尾删
void SLPopFron(SL* psl) {
assert(psl->sz >= 0);
for (int i = 1; i <= psl->sz - 1; i++) {
psl->a[i - 1] = psl->a[i];
}
psl->sz--;
}//头删
void SLErase(SL* psl, int pos) {//中间删除
assert(pos >= 0 && pos < psl->sz);
for (int i = pos + 1; i <= psl->sz - 1; i++) {
psl->a[i - 1] = psl->a[i];
}
psl->sz--;
}
查找元素
遍历整个表中的元素,直到找到要找的元素为止,找到返回坐标,没有找到返回-1;除了实现方法查找也分为按位查找和按值查找,按位查找就是已经知道了数组下表去寻找,按值查找就是看是否有这个值,然后返回这个下标
按位查找的时间复杂度是 O(1), 按值查找的时间复杂度是 O(N) ;这两者还是要区分开的
int SLFind(SL* psl, SLDatatype pos)
{
for (int i = 0; i < psl->sz; i++)
{
if (psl->data == pos)
return i;
}
return -1;
}修改元素
这里的修改很简单,因为前面已经有了查找元素的函数,这里直接套过来就行了
void SLModify(SL* psl, int pos, SLDatatype x)
{
int k=SLFind(psl, pos);
psl->data[k] = x;//直接修改就行
}二.链表
1.链表介绍
链表的存储结构不要求连续,所以不具备顺序表的一些缺陷,但是链表也有自己的缺陷,就是不能随机存取,它是一种链式存储结构,之所以这样说,是因为它如果要存取一个元素,需要进行遍历到需要的位置,再进行操作。
链表分为,单链表,双链表,循环链表,循环双链表,其中由有带头和不带头的这样看起来链表其实有点复杂,其实链表咱们再偷点懒,把它们分为单链表和循环双链表,这样就简单很多了,因为循环双链表已经包括了前面两个。链表是由很多个结点组成,具体多少看你需求,每个结点都由一个数据域和指针组成,指针的作用就是把每个结点连起来



很多人会这么理解,就是不用指针,这里就会有一个结构体嵌套的问题,如果嵌套了,那么这个结构体的大小就无法计算, 所以这里要用指针去链接,假设每个结点的大小是一个字节,如图所示
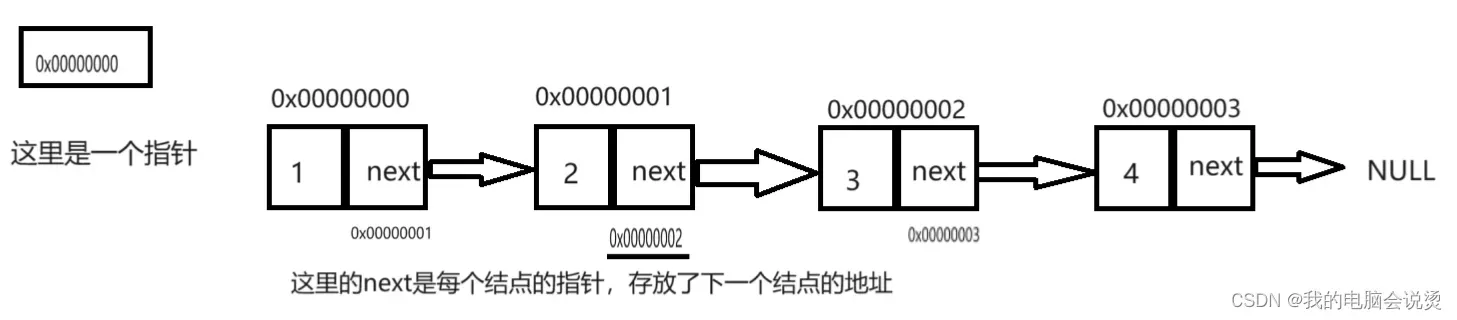

这就是基本的单链表结构,这里是不带头的,从图中可以看出,其实链表其实并没有箭头,只不过是为了更好的显示,他们的next指针保存了下一个结点的地址,所以可以通过指针去寻找他们,记住指针是用来存放地址的变量,把这里理解了就不会有什么问题。
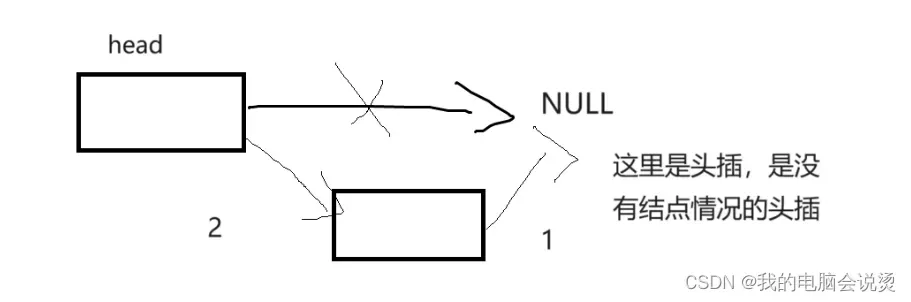
如果是带头的,也称之为哨兵位,也就是没有前面的头指针,有一个不存放数据的头结点
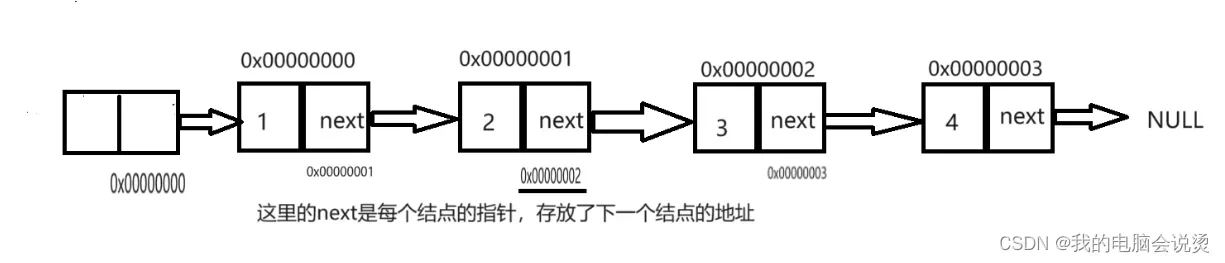

有了哨兵位可以减少在链表头插的时候判断是不是空的情况,这样使头插,尾删的操作变简单了
下面我们进行单链表的实现,让你去体会这句话
2.单链表的实现
1.单链表的创建与销毁
2.单链表的增加元素
3.单链表的删除元素
4.单链表的修改元素
5.单链表的查找元素
下面给出单链表所以实现函数,以便有一个清晰的认识,这里说明一下为什么要双指针,因为我们在头插和头删的时候我们需要去改变头指针的指向,改变指针的指向我们需要指针的指针,细品
#pragma once
#include<iostream>
#include<cstdlib>
#include<assert.h>
using namespace std;
typedef int SLTDataType;
typedef struct SListNode {
SLTDataType data;
struct SListNode* next;
}SLTNode;
//创建一个结点
SLTNode* BuyLTNode(SLTDataType* x);
//打印
void SLTPrint(SLTNode* phead);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//尾删
void SLTPopBack(SLTNode* phead);
//头删
void SLTPopFront(SLTNode** pphed);
//查找
SLTNode* SLTFind(SListNode* phead, SLTDataType x);
//在pos之前插入
void SLInsert(SLTNode** pphead, SLTDataType x);
//在pos之后插入
void SLInsetAfter(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//在pos之前删除
void SLErase(SLTNode* phead);1.单链表的创建销毁
创建就是创建一个结点,销毁是把创建的所有结点都销毁
SLTNode* BuyLTNode(SLTDataType x) {//创建一个结点
SLTNode* newnode =(SLTNode*) malloc(sizeof(SLTNode));
if (newnode == NULL) {
perror("malloc");
return NULL;
}
newnode->data = x;//创建出来初始化
newnode->next = NULL;//如果不初始化,会导致野指针的问题出现
return newnode;
}
//销毁
void SLDesTory(SLTNode** pphead)
{
SLTNode* next = *pphead;
while (next)
{
SLTNode* tail = next->next;
free(next);
next = tail;
}
*pphead = NULL;
}
2.单链表的插入元素,头插,指定位置插
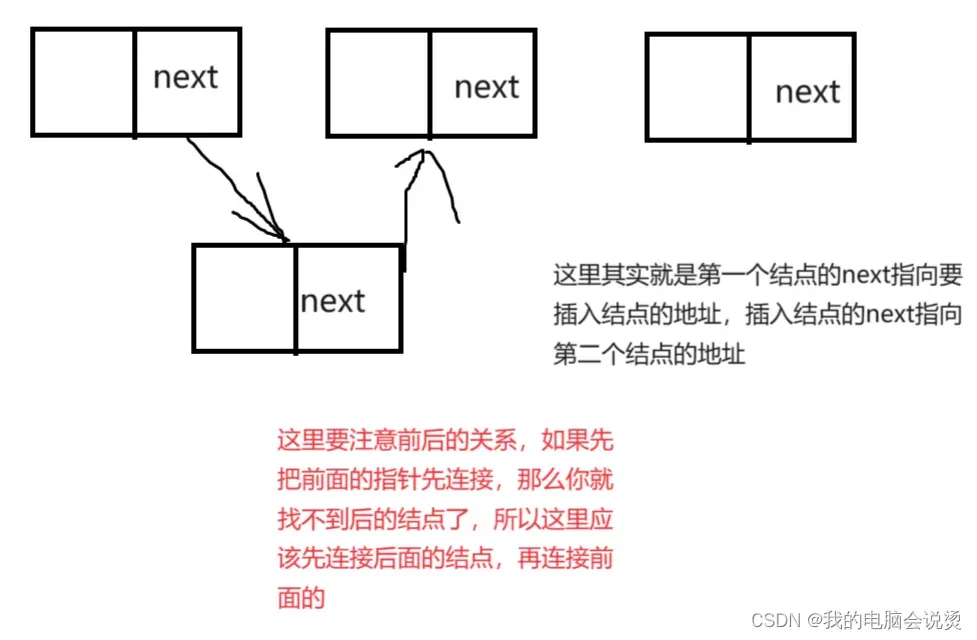




但是这里的如果有两个指针 ,一个指向当前位置,一个指向下一个位置,那么就可以不管顺序,因为你都可以找得到
void SLTPushFornt(SLTNode** pphead, SListDatatype x) {
assert(pphead);
SLTNode*newnode= BuyNode(x);//创建一个结点
newnode->next = *pphead;
*pphead = newnode;
}//头插
SLTNode* SLTFind(SListNode* phead,SLTDataType x) {
SLTNode* tail = phead;
while (tail) {
if (tail->data == x) {
return tail;
}
tail = tail->next;
}
return NULL;
}//查找函数,与下面的插入联系起来
void SLTInset(SLTNode** pphead,SListDatatype m,SListDatatype x) {
assert(pphead);
SLTNode*pos=SLTFind(*pphead, m);//需要寻找你要插入的位置,所以有一个Find函数
assert(pos);
if (*pphead==pos) {
SLTPushFornt(pphead, x);
}//这里分清没有结点的情况和有结点的情况,如果不判断那么会导致有野指针情况
else {
SLTNode* tail = *pphead;
while (tail->next != pos) {
tail = tail->next;
}
SLTNode* newnode = BuyNode(x);
tail->next = newnode;
newnode->next = pos;
}
}指定位置插3.单链表删除元素,头删,尾删
和插入元素有点像,这里删除就是如果链表为空那么就不能再删了,所以我们用assert断言去操作,插入是如果链表为空要特殊判断一下,细品,这里的尾删也有不同
void SLTPopFornt(SLTNode** pphead) {
assert(pphead);
assert(*pphead);//为空不能删
SLTNode* tail = *pphead;
*pphead = tail->next;//指向下一个,可以自己画图理解
free(tail);
}//头删
void SLTPopBack(SLTNode** pphead) {
assert(pphead);
assert(*pphead);
if ((*pphead)->next == NULL) {
free(*pphead);
*pphead = NULL;
}
else {
SLTNode* tail = *pphead;
while (tail->next->next) {//这里就是那个特殊的地方,你需要找到删除位置的前一个位置,然后对要删除的位置进行操作,如果不这样,直接删除的话,会导致前一个指针为野指针,因为你找不到前一个,也就不能把它的next设置为空
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}//尾删 查找和修改比较容易都是一起的,这里就不介绍了,下面介绍一下双向循环链表
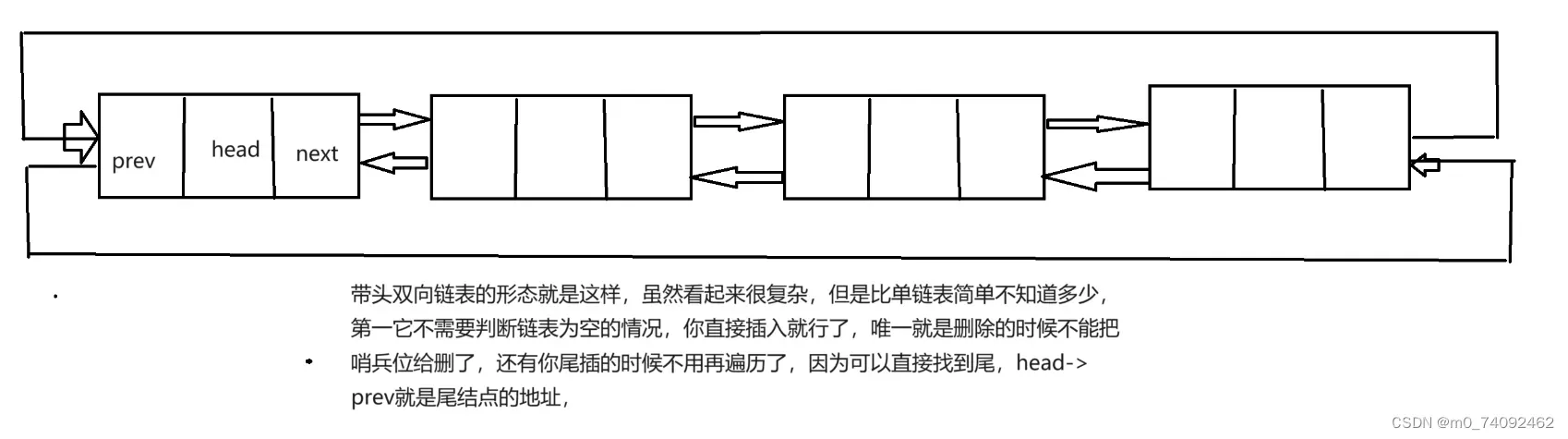

循环双向链表的优势比单链表的优势大很多,但是我们一般做题都用单链表,所以两者都要掌握
这里就不给双向链表的实现了,因为比较简单,唯一要注意的就是删除那里,可以自己去尝试操作一下
三.总结
顺序表
优点:
对于访问数据很方便,还有尾删,尾插很方便
缺点:
但是对于删除数据和增加数据(不包括尾插,尾删)所用的消耗比较大
单链表
优点:
插入和删除数据都比较快,不需要挪动数据
缺点:随机访问需要遍历时间复杂度为O(N),顺序表有一个二分查找时间复杂度为O(logN)
还有就是我们内存在读取数据的时候是读取cpu规定的字节大小的,比如一次读32字节,那么由于单链表的空间不连续,所以会读到很多垃圾信息,所以这里花的时间也有损耗
四.oj题
1.移除链表元素


这里的话我们的思路就是链表里面的删除操作,可以用尾删的方法,也可以逆向思维,把他们头插到新的链表里面,这里我们使用尾删的方法 ,也就是遍历遇到就删除
struct ListNode* removeElements(struct ListNode* head, int val) {
struct ListNode*prev=NULL,*tail=head;//这里使用tail去遍历,反正找不到头指针。这里的prev是找到删除的前面一个结点,防止出现野指针的情况,具体的在上面有探讨过
while(tail)
{
if(tail->val==val)//如果等于那么我们直接删除
{
if(prev){//这里还需要主要的就是如果第一个就是要删除的值,那么这里prev就是空,
//如果不判断直接进行,那么prev->next就会变成野指针
prev->next=tail->next;
free(tail);
tail=prev->next;
}
else{//如果是空,那么直接删
head=head->next;
free(tail);
tail=head;
}
}
else//不是目标值,进行迭代
{
prev=tail;
tail=tail->next;
}
}
return head;
}有了上一个题目,感觉题目都是单链表的操作,其实不难,难的在于细节,这就需要边画图边操作
趁热打铁再来一个
2.反转链表
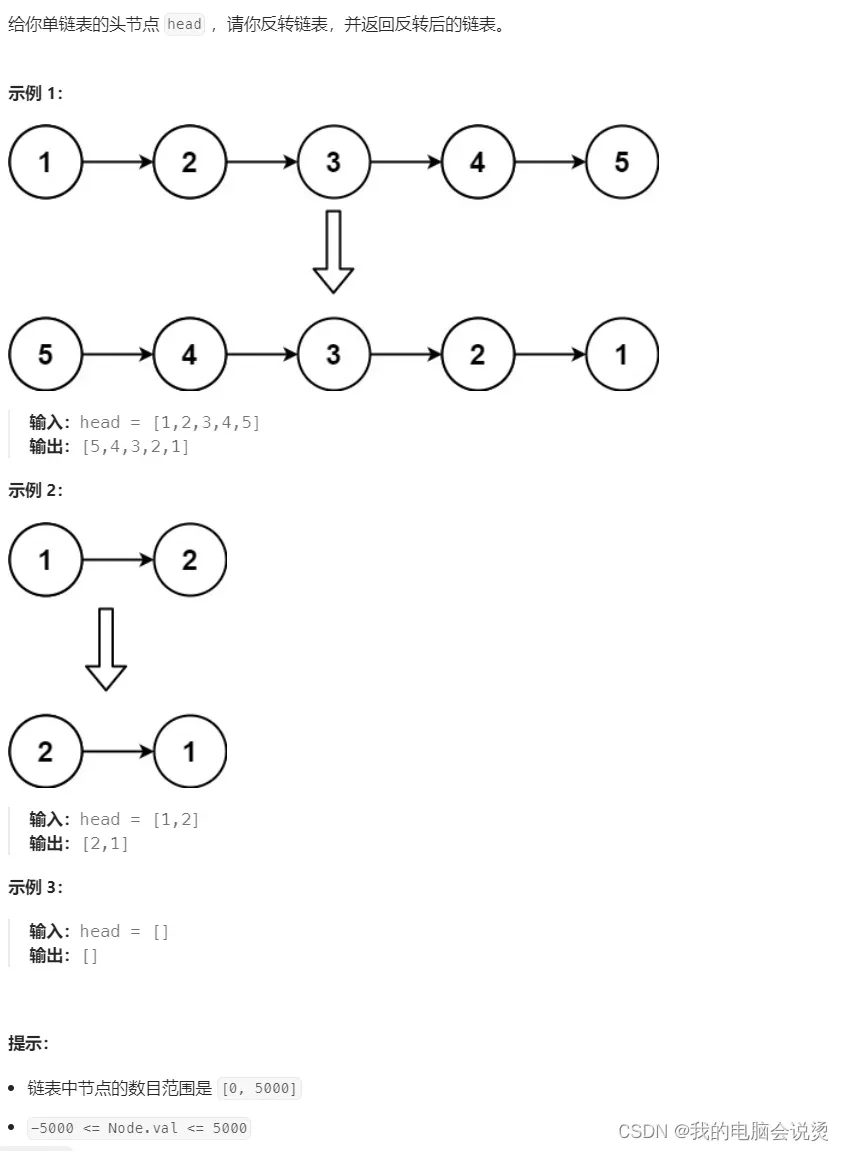

其实思路差不多,也可以采用头插的方法,也就是把最后一个元素依次头插,那么这样就复杂了,而且时间上开销也大,所以我们这里的思路是将指针全部逆置就行了
struct ListNode* reverseList(struct ListNode* head) {
if(head==NULL)//如果为空直接返回
return NULL;
struct ListNode*n1=NULL;//这里需要三个指针去指向不同的位置
struct ListNode*n2=head;
struct ListNode*n3=n2->next;//可以画图表示
while(n2)//当n2为空的时候就结束循环了,这里一直迭代,然后改变n2结点处的指针指向
{
n2->next=n1;
n1=n2;
n2=n3;
if(n3)
n3=n3->next;
}
return n1;
}如果第一题是我们的链表基础题,那么第二题有点偏理解和思维了,那我们继续
3. 返回倒数第 k 个节点


乍一看好像没什么思路,这里其实用一个快慢指针,快指针先走k步,然后再一起走,最后当快指针等于空的时候结束,这时候慢指针就指向了倒数第k个结点的位置,不理解的可以画图
int kthToLast(struct ListNode* head, int k){
struct ListNode*fast,*slow;
fast=slow=head;
while(k--){
if(fast==NULL)这里需要注意,如果k比原链表长度还大,那么就不存在倒数第几个,直接返回就行了
return NULL;
fast=fast->next;
}
while(fast){//快指针为空的时候退出循环
slow=slow->next;
fast=fast->next;
}
return slow->val;//返回慢指针指向的位置即可
}做完以后你对于链表的认识就有了比较好的理解了,但是还不够,下面给出几个题目练习
合并两个有序链表
链表分割
相交链表
以上就是顺序表和单链表的相关知识整理,可能单链表不是很全,但是把单链表理解,后面的链表也不在话下,如果认真看完,你会对链表有一个好的理解和认识,希望本篇文章可以给你们带来帮助
版权声明:本文为博主作者:我的电脑会说烫原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_74092462/article/details/136788271