

数学建模入门篇(0基础必看,全是自己的经验)
【竞赛|数学建模】Part 1:什么是数学建模和各模块介绍
0基础小白,如何入门数学建模?
数学建模入门篇(0基础必看,全是自己的经验)
什么是数学建模
重申了一下题目,但是还是很有必要,简要概述:解决实际问题时构建数学模型的过程。
很优秀的一个版本来自刘宏志老师《数据、模型与决策》书中解释:数学模型是利用系统化的符号和数学表达式对间题的一种抽象描述。数学建模可看作是把问题定义转换为数学模型的过程。 和问题定义相对应,数学模型包括几个主要组成部分:决策变量、环境变量、目标函数和约束条件。决策变量表示决策者可以控制的因素,即可控输入,是需要通过模型求解来确定的模型中的未知变量。环境变量表示决策者不可控的外界因素,即非可控输入,需要在收集数据阶段确定其具体数值,并在模型中以常量表示。目标函数是指描述问题目标的数学方程,而约束条件则是指描述问题中制约和限制因素的数学表达式(等式或不等式)。(这个主要是规划的一种定义) 数学建模是一项富有创造性的工作。对任何问题,“没有唯一正确的模型”。数学模型是对现实问题的一种抽象描述,必然会忽略一些因素。而这些被忽略的看似无关或不重要的因素,可能会引起重大的变化,例如人们熟知的“蝴蝶效应”。著名的统计学家乔治·博克斯曾说过:“All models are wrong.Some are useful.”(所有的模型都是错误的,但有一些是有用的。)对同一问题,可以从不同角度对其构建出多个不同的模型。 对于复杂问题的建模,很难一步到位,通常需要采取一种逐步演化的方式来进行。从简单的模型开始(忽略一些难以处理的因素),然后通过逐步添加更多相关因素,让模型演化,使其与实际问题更加接近。基于模型分析得出的结论或建议的价值,与模型对实际情况的描述符合程度有很大的关系。通常,模型越接近实际,分析得出的结果的价值也越大。
一份简短又全面的数学建模技能图谱:常用模型&算法总结


本文总结了数学建模中常用的方法和模型,包括数学、统计和机器学习算法。常用的建模方法有主成分分析、因子分析法、层次分析法等。求解方法包括线性规划、整数规划、动态规划、图论算法等。另外,为了处理数据,还需要掌握数据变换、数据拟合、参数估计、插值等数据处理技术。此外,文章还列出了一些常见的模型和工具,包括神经网络、差分方程、偏微分方程、深度学习框架等,并给出了相应的教程和资源。文章将帮助读者建立起数学建模的知识框架和技能体系,以便更好地应对数学建模中的各种问题和挑战。
为什么需要掌握数据变换、数据拟合、参数估计、插值等数据处理?
需要掌握数据变换、数据拟合、参数估计、插值等数据处理的原因如下:
-
数据变换:数据在实际应用中可能存在非线性或非正态分布等问题,通过数据变换可以将数据转化为满足线性或正态分布的形式,以便更好地应用于统计分析和建模。
-
数据拟合:数据拟合是通过建立数学模型来拟合实际观测数据,从而预测未来可能的趋势或进行其他分析。通过数据拟合可以揭示数据背后存在的规律和关系。
-
参数估计:在建立数学模型时,需要确定模型中的参数值。参数估计是通过统计方法,利用观测数据来估计出最优的参数值。正确的参数估计可以提高模型的准确性和可靠性。
-
插值:插值是通过已知的离散数据点来估计未知数据点的值。通过插值可以填补数据中的缺失值,使得数据在空间或时间上的分布更加连续和均匀。
这些数据处理技术在科学研究、工程建模、金融分析、医学诊断等领域都有广泛应用。掌握这些技术可以有效地处理和分析数据,深入理解数据背后的规律和关系,为决策提供可靠的依据。
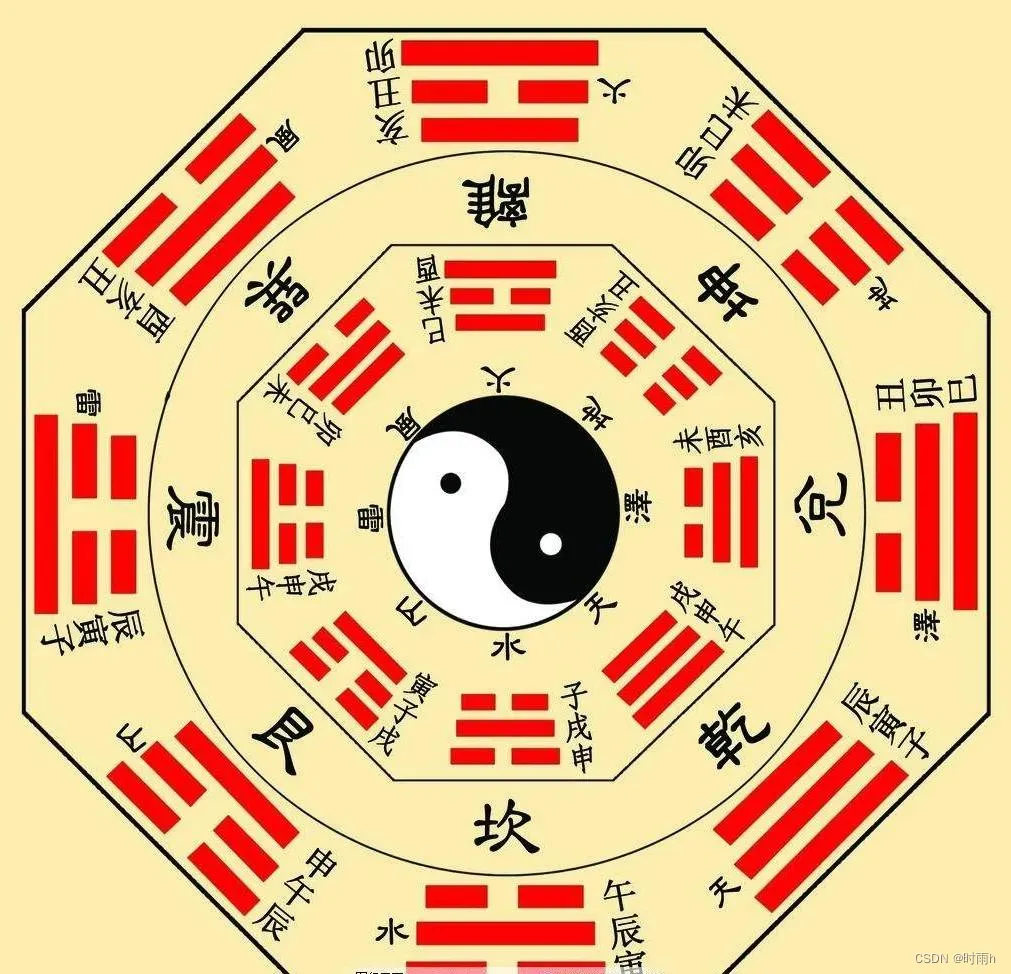
【伏羲八卦图】(Python&Matlab实现)


%% 太极八卦图
%%~~~~~~~欢迎关注公众号:电力系统与算法之美~~~~%%
clc;clear;close all;
t=0:.1:pi;
T=0:.1:2*pi;
c=@(t)cos(t);s=@(t)sin(t);
x=c(t);y=s(t);
X=c(t);Y=s(-t);
x1=.1*c(T)-.5;y1=.1*s(T);
x2=x1+1;%y2=y1;
x3=.5*c(t)-.5;y3=.5*s(t);
x4=x3+1;%y4=-y3;
hold on
f=@(x,y,c)fill([x,flip(x3,2),flip(x4,2)],...
[y,flip(y3,2),flip(-y3,2)],c);
f(X,Y,'k');
f(x,y,'w');
fill(x2,y1,'k',x1,y1,'w')
axis square off

#====导入相关库========
import turtle
import time
#====欢迎关注公众号:电力系统与算法之美======
#====更多惊喜,更多浪漫,更多算法等你=====
angle = 270
turtle.title('我与老子对话')
#=====太极图=======
def tai():
r = 200 # 设置半径
turtle.penup() # 拿起画笔
turtle.goto(0, 0) # 到画布中心
turtle.setheading(angle) # 设置当前朝向为angle角度
turtle.fd(r) # 前进r的距离
turtle.pendown() # 放下画笔
turtle.right(90) # 调整海龟角度
#======画阳鱼======
turtle.fillcolor("white") # 填充为白色
turtle.begin_fill() # 开始填充
turtle.circle(-r / 2, 180)
turtle.circle(r / 2, 180)
turtle.circle(r, 180)
turtle.end_fill() # 填充结束
#=====画阴鱼=========
turtle.fillcolor("black") # 填充为黑色
turtle.begin_fill()
turtle.circle(r, 180)
turtle.right(180)
turtle.circle(-r / 2, 180)
turtle.circle(r / 2, 180)
turtle.end_fill()
#=======画阴鱼眼==========
turtle.penup()
turtle.setheading(angle)
turtle.fd(-r / 2)
turtle.pendown()
turtle.dot(r / 4, "white") # dot()绘制具有特定大小和颜色的圆点
#=========画阳鱼眼=========
turtle.penup()
turtle.fd(-r)
turtle.pendown()
turtle.dot(r / 4, "black")
turtle.penup()
turtle.tracer(0) # 将刷新率置为0,即不刷新
for i in range(10000): # 这里设置了1w次,也可以是其他次数
tai()
turtle.update() # 更新绘图
time.sleep(0.01) # 休眠时间,这一句可以没有,但是如果没有的话,太极转的会很快
turtle.clear() # 清空画布
angle += 1
史上最完整的深度学习环境配置教程,亲自踩雷,看必会(包含问题解决)配置Anaconda+Pycharm+Pytorch+Jupyter
深度学习(Deep Learning)是机器学习的一个分支,它模仿人脑中神经网络的工作原理,通过构建和训练多层神经网络来进行模式识别和数据分析。
深度学习的核心思想是通过多层神经网络进行特征提取和抽象,从而实现对复杂数据的学习和理解。与传统机器学习方法相比,深度学习具有以下几个显著特点:
-
多层结构:深度学习模型通常由多个神经网络层组成,形成了深度的结构,可以自动地从原始数据中学习和提取特征。
-
端到端学习:深度学习模型能够接收原始数据作为输入,并直接输出结果,省去了手工设计和选择特征的过程。
-
数据驱动:深度学习强调从大量标注数据中学习,通过训练集上的反向传播算法优化网络参数,使得模型能够更好地拟合数据。
-
可扩展性:深度学习模型的规模和复杂度可以根据问题的需求进行灵活调整,适应不同规模的数据和任务。
深度学习在计算机视觉、自然语言处理、语音识别等领域取得了很大的突破,例如图像分类、物体检测、语义分析和机器翻译等任务。它已经成为人工智能领域最具有潜力和前景的技术之一,并在各种应用中取得了广泛的应用和推动。
深度学习与数学建模有密切的关系。数学建模是一种利用数学方法和技巧来描述现实问题、分析问题、预测问题、解决问题的过程。而深度学习则是通过构建和训练多层神经网络来进行模式识别和数据分析。
深度学习的核心是神经网络,而神经网络的运算和优化过程都涉及到数学的各个领域。下面是深度学习与数学建模中几个重要的关系:
-
线性代数:线性代数是深度学习中的基础,涉及向量、矩阵、线性变换等概念。神经网络中的输入、权重、输出等都可以用向量和矩阵表示,而神经网络的训练过程就是通过优化问题来更新权重,利用线性代数中的矩阵运算和求导来实现。
-
概率论与统计学:深度学习中的许多模型和算法都建立在概率论和统计学的基础之上。例如,贝叶斯网络、混合模型等可以用于解决分类、聚类和生成模型等问题。深度学习中的一些常用算法,如随机梯度下降(SGD)和马尔科夫链蒙特卡罗(MCMC)等也与概率论和统计学密切相关。
-
微积分:微积分在深度学习中有广泛应用,例如求解损失函数的梯度、优化算法中的参数更新等。通过微积分的知识,可以对深度学习模型进行分析、理解和改进。
-
优化理论:深度学习模型的训练过程本质上是一个优化问题,需要通过调整模型的参数来最小化损失函数。优化理论提供了一系列的算法和技术,如梯度下降、共轭梯度、牛顿法等,用于解决这些优化问题。
总之,深度学习与数学建模密不可分。数学提供了严密的理论基础和方法,为深度学习的建模、训练和优化提供了重要的工具和指导。深度学习的发展也推动了数学建模的发展,促进了数学与实际问题的结合。
全国大学生数学建模竞赛(CUMCM)历年试题(查看超级方便)
吴恩达老师深度学习课程完整笔记
吴恩达(Andrew Ng)是一位著名的计算机科学家和人工智能专家。他在机器学习和深度学习领域有着丰富的研究和实践经验,被广泛认为是人工智能领域的顶级专家之一。
以下是吴恩达的一些主要成就和贡献:
-
Coursera:吴恩达是在线学习平台Coursera的联合创始人之一。他于2011年开设了一门名为《机器学习》的在线课程,为数百万人提供了机器学习和深度学习的入门教育。他的课程深入浅出,以清晰易懂的方式讲解复杂的概念和算法,深受学生和业界的欢迎。
-
Stanford大学:作为斯坦福大学的教授,吴恩达曾领导Stanford AI实验室,并在该实验室中进行了许多重要的研究工作。他的研究涉及机器学习、深度学习、自然语言处理和计算机视觉等领域,其中包括著名的研究项目如Google街景地图、无人驾驶汽车和智能助手等。
-
Google Brain:吴恩达曾在Google创办了Google Brain团队,该团队专注于研究深度学习和人工智能。他们的工作推动了深度学习技术在计算机视觉、语音识别和自然语言处理等领域的广泛应用。
-
deeplearning.ai:吴恩达也是deeplearning.ai的创始人,这是一个旨在为人工智能爱好者和专业人士提供深度学习教育和资源的在线平台。他通过deeplearning.ai推广了深度学习,并为学习者提供了实践项目、课程和认证等。
吴恩达不仅在学术界做出了重要贡献,还在人工智能产业的发展中扮演了关键角色。他的教育和普及工作使得更多人了解和应用深度学习,推动了人工智能技术的普及和发展。他的研究和影响力对整个人工智能领域产生了深远的影响。
吴恩达在人工智能领域的贡献和影响还包括以下方面:
-
深度学习研究:吴恩达致力于深度学习算法的研究和改进。他提出的一些算法和模型在学术界和工业界都取得了重要的突破。例如,他在2006年提出的稀疏自编码器(Sparse Autoencoder)为无监督学习提供了新的思路。他还与其他研究人员共同开发了广泛应用的深度学习模型,如深度信念网络(Deep Belief Networks)和卷积神经网络(Convolutional Neural Networks)。
-
应用于实际问题:吴恩达对将深度学习技术应用于实际问题有着丰富的经验。他曾参与多个实际项目,包括通过计算机视觉技术实现的无人驾驶汽车和Google街景地图。他的研究和实践经验使他能够理解实际问题,并提出有效的解决方案,推动了深度学习在实际应用中的发展。
-
开源贡献:吴恩达在人工智能领域的开源贡献也备受赞赏。他与团队开发了一些开源工具和框架,如深度学习框架Caffe和深度学习库Deeplearning4j等。这些工具的开源使得更多的研究人员和开发者能够方便地使用和应用深度学习技术。
-
人工智能倡导者:作为一个知名的人工智能专家,吴恩达一直致力于推广人工智能的发展和应用。他通过各种演讲、文章和社交媒体等渠道分享自己的见解和经验,鼓励更多的人关注和参与人工智能领域。他强调人工智能的潜力和影响,并提倡人工智能的道德和可持续发展。
总的来说,吴恩达在机器学习和深度学习领域的研究和教育工作为人工智能的发展和应用做出了重要贡献。他的领导力、创新思维和教学方法使得更多的人能够理解和掌握人工智能技术,推动了人工智能的普及和进步。他被广泛认为是人工智能领域的杰出领导者和启发者。
MATLAB新手简明使用教程专栏
时雨h个人数学建模公开收藏夹,持续更新看到的好文

版权声明:本文为博主作者:时雨h原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/shaozheng0503/article/details/131921124