

前言
我们已经安装好了SD,这篇文章不介绍难以理解的原理,说使用。以后再介绍原理。
我的想法是,先学会画,然后明白原理,再去提高技术。
我失败过,知道三天打鱼两天晒网的痛苦,和很多人一样试了安装 github 版本,生成了几张图,发现效果不太理想,就放着了。后来也是花了几千元学了很多 SD 的课程,才逐渐上道。
界面基本功能
安装好了 SD ,我们就可以再下面的网页上绘图了:
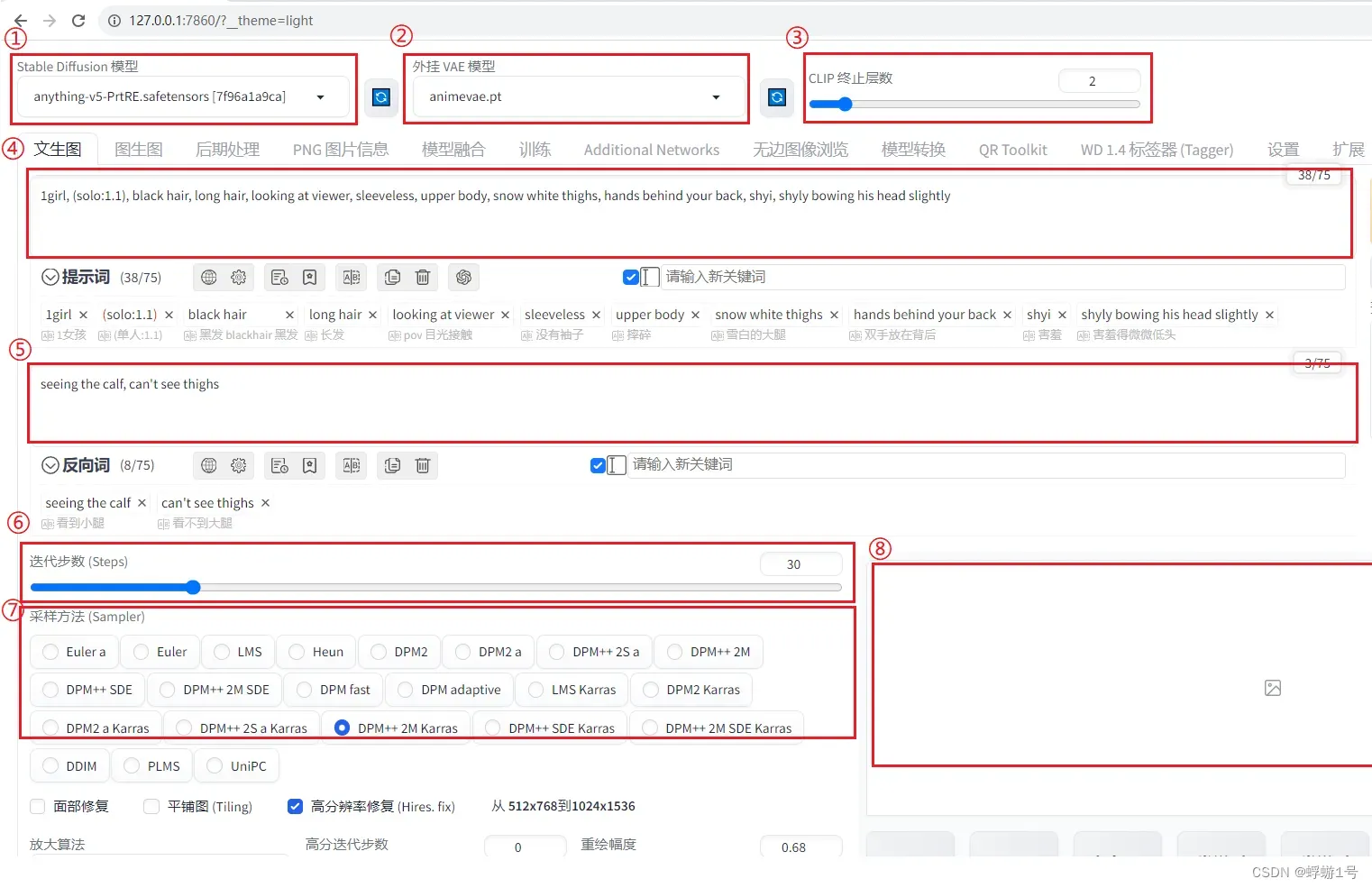

①:大模型:绘图的主要模型,大小一般都在几个G。
②:VAE模型:可以理解为让图片更明亮一些。(不重要,现在的大模型一般都自带了VAE)
③:CLIP终止层数:值越大,出的结果和你预想的差别越大。这个值我们一般固定用1-4,默认用2就行。
④:文生图:常用的生成图片方式,根据提示词来生成图片。框中就是我们写的提示词,只能用英文。
正向提示词:告诉 SD 需要生成什么样的图片,比如,一个桃子。
⑤:反向提示词:告诉 SD 图片中不需要什么元素,比如,狗。意思是不要狗。
⑥:迭代步数:一般地,数值越高,画得越好,时间越长。30是比较合适的数值。
⑦:采样方法:Euler a 方法是扩散类型的,结果很难控制。我们一般采用 DPM++ 2S a Karras 等几个,结果不会发生大的变化,而是不断丰富细节,容易控制。
⑧:生成的图片。
选好基本参数,大模型,迭代步数30,采样方法DPM++ 2S a Karras,再加上自己写的提示词,就可以画出一幅比较完整的画了。
尝试过后,你可能发现,图片似乎还不够理想,没有完全按照你的想法来,比如脸部不正常。下次我们会继续介绍如何完善图片的方法。
小结
一次不要学太多内容。基本功能的介绍已经完成,以后再介绍进阶内容。
版权声明:本文为博主作者:蜉蝣1号原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/JiuShu110/article/details/132266946