

今天我们来重点研究与实测一个开源的
Text2SQL优化框架 – Vanna

1. Vanna 简介【Text-to-SQL 工具】
Vanna 是一个基于 MIT 许可的开源 Python RAG(检索增强生成)框架,用于 SQL 生成和相关功能。它允许用户在数据上训练一个 RAG “模型”,然后提问问题,这将生成在数据库上运行的 SQL 查询语句,并将查询结果通过表格和图表的方式展示给用户。
简单的说,Vanna是一个开源的、基于Python的、用于SQL自动生成与相关功能的RAG(检索增强生成)框架。
基本特点:
- 官网:https://vanna.ai/
- 开放源代码:https://github.com/vanna-ai/vanna
- 基于Python语言。可通过PyPi包vanna在自己项目中直接使用
- RAG框架。RAG最典型的应用是 私有知识库问答,通过Prompt注入私有知识以提高LLM回答的准确性。但RAG本身是一种Prompt增强方案,完全可以用于其他LLM应用场景。
2. Vanna工作原理
借助LLM实现一个最简单的、基于Text2SQL的数据库对话机器人本身原理是比较简单的:
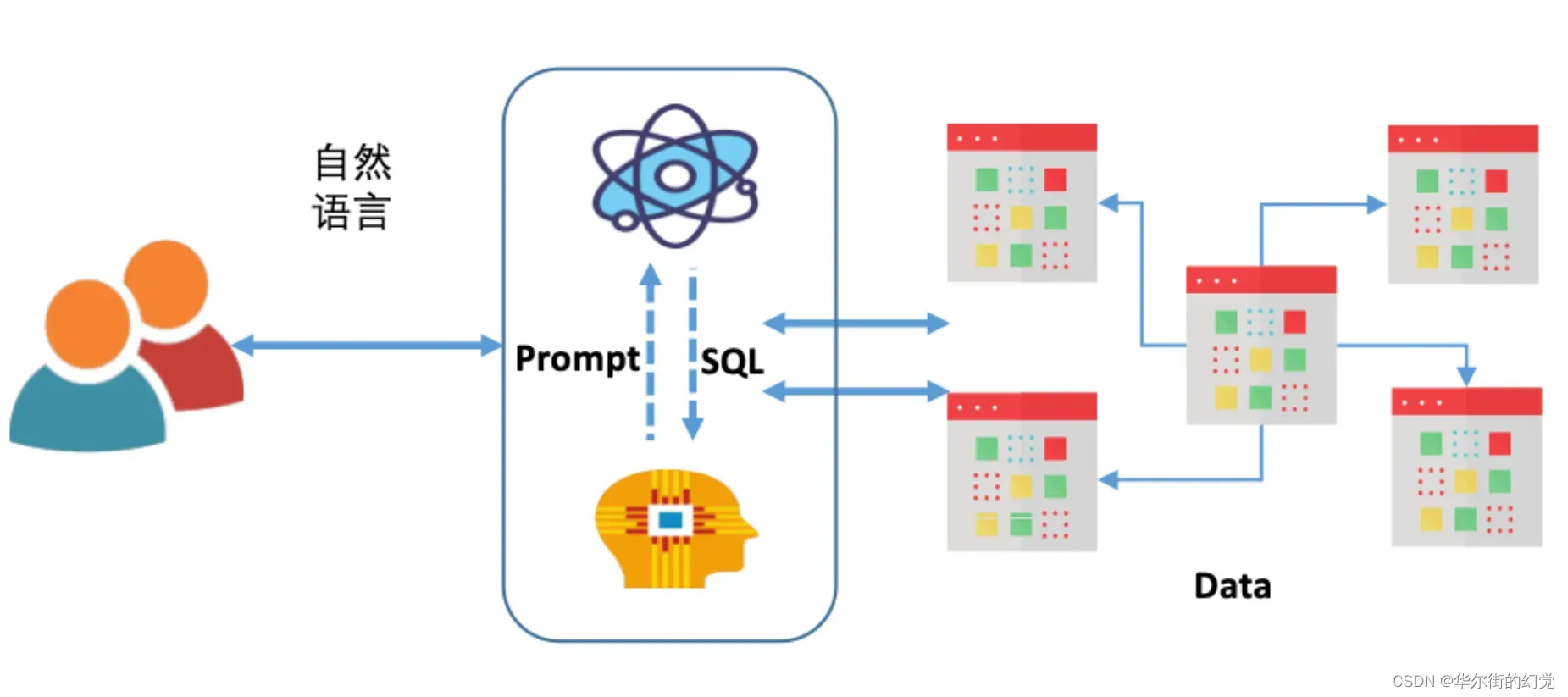
Vanna则是借助了相对简单也更易理解的RAG方法,通过检索增强来构建Prompt,以提高SQL生成的准确率:
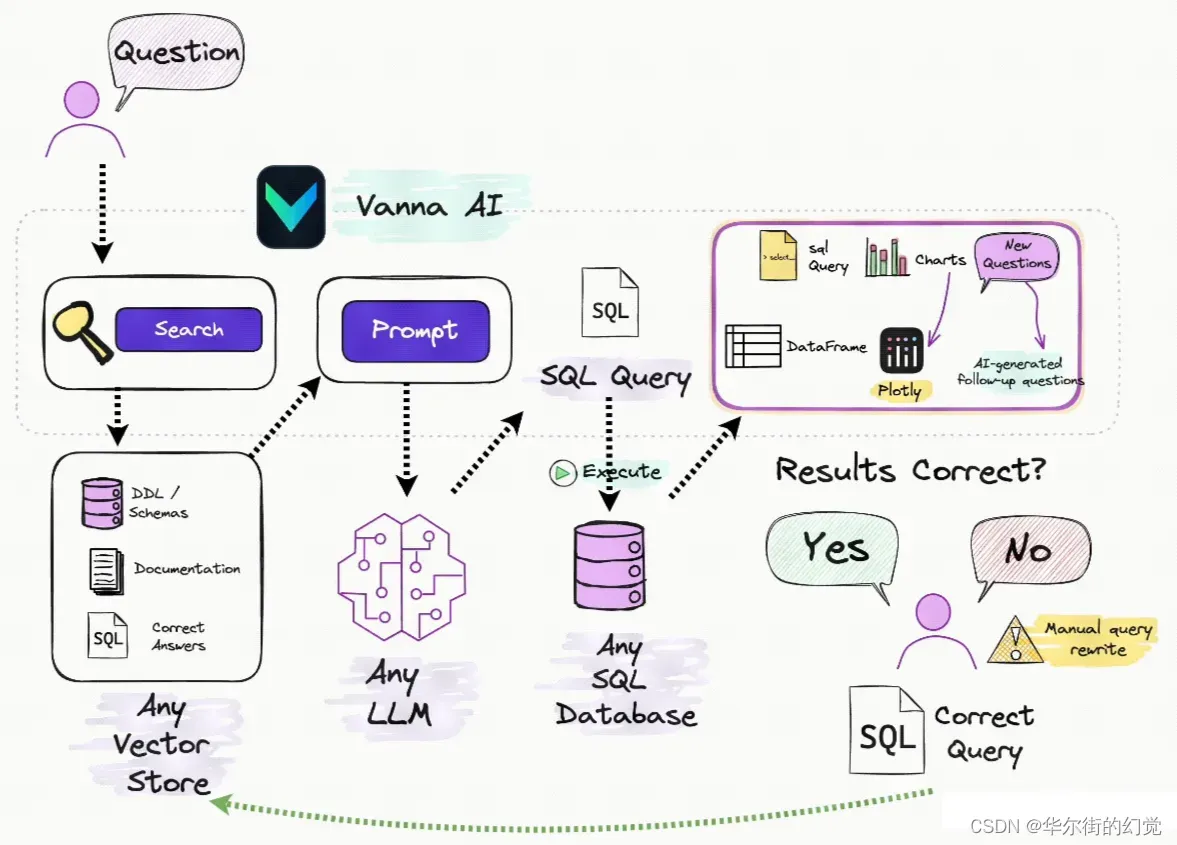
从这张图可以了解到,Vanna的关键原理为:


借助数据库的DDL语句、元数据(数据库内关于自身数据的描述信息)、相关文档说明、参考样例SQL等
训练一个RAG的“模型”(embedding+向量库);
并在收到用户自然语言描述的问题时,从RAG模型中通过语义检索出相关的内容,进而组装进入Prompt,然后交给LLM生成SQL。
3. 使用步骤
第一步:在你的数据上训练一个RAG“模型”
把DDL/Schemas描述、文档、参考SQL等交给Vanna训练一个用于RAG检索的“模型”(向量库)。

本文尝试了1、3、4的方法,记住这几种方法,下面会用到。

第二步:提出“问题”,获得回答
RAG模型训练完成后,可以用自然语言直接提问。Vanna会利用RAG与LLM生成SQL,并自动运行后返回结果。
4. vanna的扩展与定制化
从上述的vanna原理介绍可以知道,其相关的三个主要基础设施为:
- Database,即需要进行查询的关系型数据库
- VectorDB,即需要存放RAG“模型”的向量库
- LLM,即需要使用的大语言模型,用来执行
Text2SQL任务
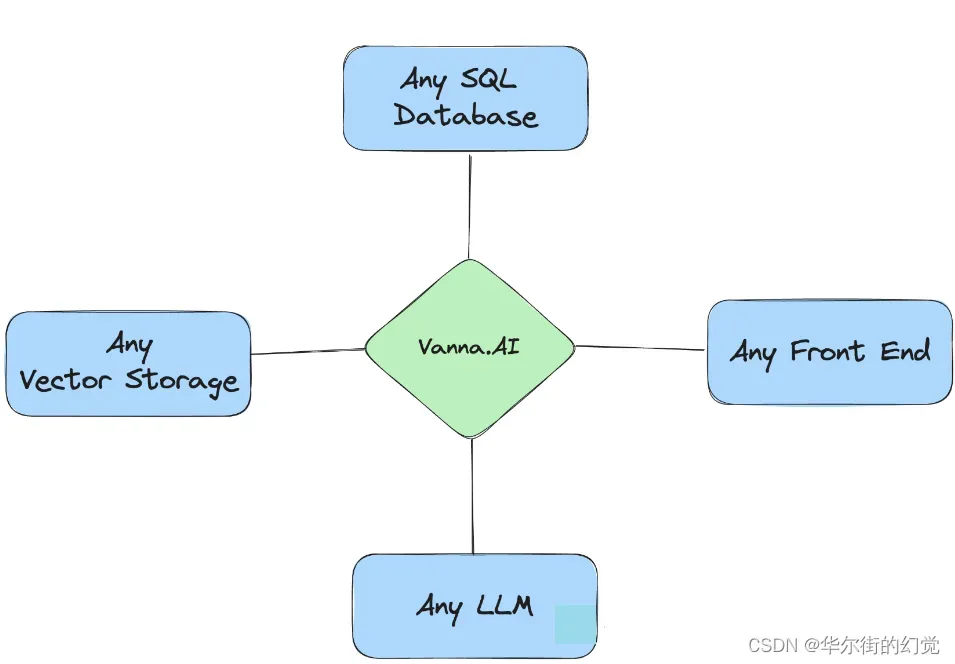
Vanna的设计具备了很好的扩展性与个性化能力,能够支持任意数据库、向量数据库与大模型。

4.1 自定义LLM与向量库
默认情况下,Vanna支持使用其在线LLM服务(对接OpenAI)与向量库,可以无需对这两个进行任何设置,即可使用。因此使用Vanna最简单的原型只需要五行代码:
import vanna
from vanna.remote import VannaDefault
vn = VannaDefault(model='model_name', api_key='api_key')
vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
vn.ask("What are the top 10 albums by sales?")
注意:使用Vanna.AI的在线LLM与向量库服务,需要首先到 https://vanna.ai/ 去申请账号,具体请参考下一部分实测。
如果需要使用自己本地的LLM或者向量库,比如使用自己的OpenAI账号与ChromaDB向量库,则可以扩展出自己的Vanna对象,并传入个性化配置即可。
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})
这里的OpenAI_Chat和ChromaDB_VectorStore是Vanna已经内置支持的LLM和VectorDB。
如果你需要支持 没有内置支持的LLM和vectorDB,
则需要首先 扩展出自己的LLM类与VectorDB类,
实现必要的方法(具体可参考官方文档),
然后再 扩展出自己的Vanna对象:


4.2 自定义关系型数据库
Vanna默认支持Postgres,SQL Server,Duck DB,SQLite等关系型数据库,可直接对这一类数据库进行自动访问,实现数据对话机器人。
但如果需要连接自己企业的其他数据库,比如企业内部的Mysql或者Oracle,自需要定义一个个性化的run_sql方法,并返回一个Pandas Dataframe即可。具体可参考下方的实测代码。
5. 实测:数据库对话机器人
这里我们使用Vanna快速构建一个与数据库对话的AI智能体,直观的感受Vanna的工作过程与效果。
【0 – 选择基础环境】
- LLM(大模型)
选择Vanna.AI在线提供的OpenAI服务,真实环境中建议使用自己的LLM。 - VectorDB(向量数据库)
选择Vanna.AI在线提供的VectorDB服务,真实环境中可根据条件灵活选择。 - RDBMS(关系型数据库)
我们选择本地测试环境中的一个MySQL数据库,其中存放了一些测试的社区用户信息数据customer:
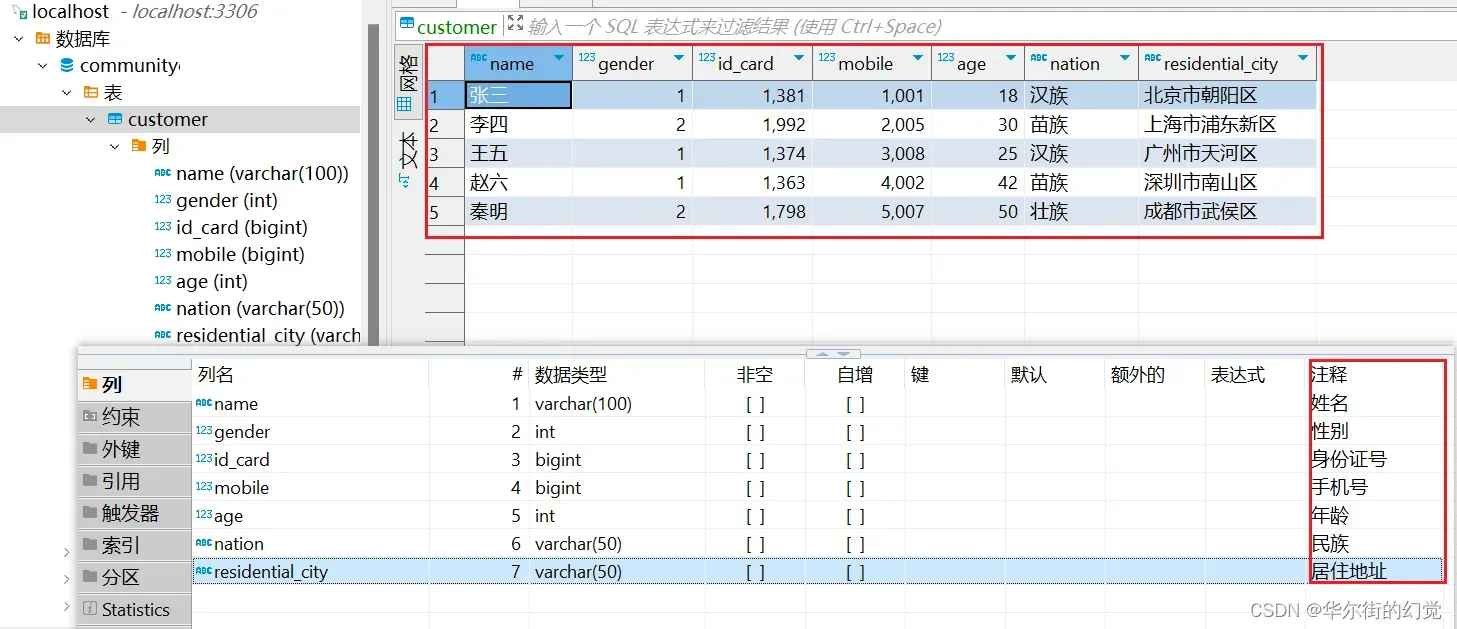

我用DBeaver工具来管理MySQL数据库,创建数据可以用SQL语句CREATE 或 导入csv
导入csv可以参考【数据库】DBeaver链接MariaDB建表,导入csv数据这篇博客
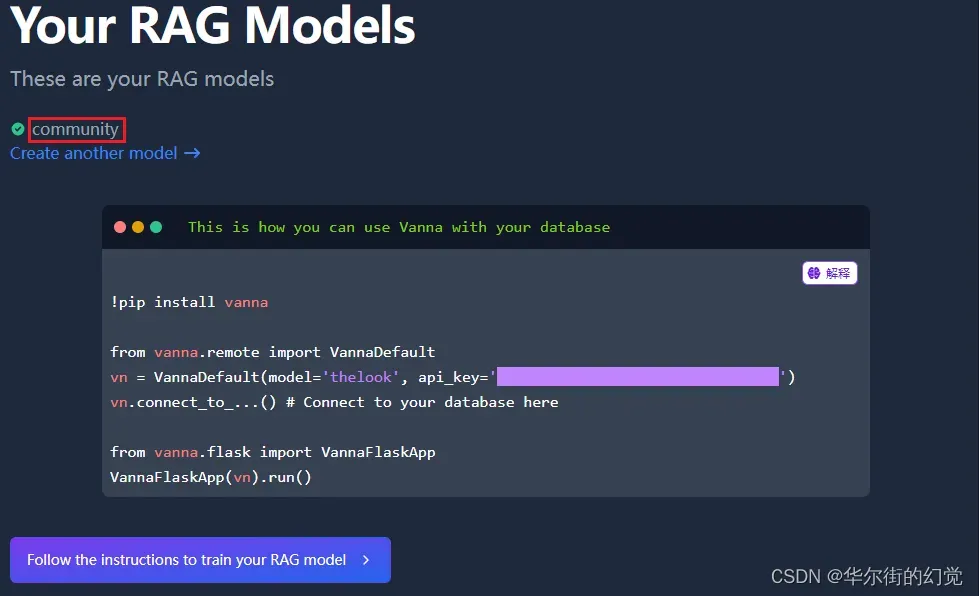
【1 – 申请Vanna账号】
由于我们使用了Vanna.AI的在线LLM与vectorDB服务。因此首先在Vanna.AI申请一个账号,并获得API-key(红框中部分 / 代码中隐藏部分):

设置一个Model name,用于在线的RAG model:
我的设置为:community


【2 – 构建Vanna对象】
pip install vanna
使用pip安装vanna库后,首先使用如下代码创建默认的Vanna对象:
import vanna
from vanna.remote import VannaDefault
api_key = '上面获得的API-key'
vanna_model_name = '上面设置的model-name( 我的是community )'
vn = VannaDefault(model=vanna_model_name, api_key=api_key)
由于我们需要使用自己的本地Mysql数据库,需要定义一个run_sql方法
设置好MySQL数据库的user 、password、host 和 database
(这个database名称是DBeaver工具customer上方的数据库名称Community,RAG model的名称是网页上设置的 community,首字母是小写的,各位别抄错啦!按自己的配置来哈!)
import pandas as pd
import mysql.connector
def run_sql(sql: str) -> pd.DataFrame:
cnx = mysql.connector.connect(user='root',password='111000',host='localhost',database='Community')
cursor = cnx.cursor()
cursor.execute(sql)
result = cursor.fetchall()
columns = cursor.column_names
df = pd.DataFrame(result, columns=columns)
return df
将自定义的方法设置到上面创建的Vanna对象:
vn.run_sql = run_sql
vn.run_sql_is_set = True
【3 – 训练RAG Model】
这里我们先采用Vanna提供的一种更简单的方式:通过数据库的元数据信息构建训练计划(plan),然后交给Vanna生成RAG model:
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS where table_schema = 'chatdata'")
plan = vn.get_training_plan_generic(df_information_schema)
vn.train(plan=plan)
我构建计划(plan)的方式失败!
故通过 DDL语句 和 SQL问答对 的方式来构建。
表和列名的注释很重要!
表和列名的注释很重要!
表和列名的注释很重要!
有助于vn识别语义,有的列名英文不是那么明确,可能会导致vn生成SQL出错。
比如身份证号的英文可以是id_number,我这里是
id_card
比如性别的英文可以是sex,我这里是gender。
当时我的表还没添加注释,所以多加了CREATE TABLE的操作,如果各位同学在创建表时,已添加了注释,下面这句CREATE TABLE就可以省略了。
需要注意的是,下面的训练代码只需要执行一次即可。
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS customer (
name INT PRIMARY KEY COMMENT '姓名',
gender INT COMMENT '性别(男性=1/女性=2)',
id_card VARCHAR(100) COMMENT '身份证',
mobile VARCHAR(100) COMMENT '手机',
nation VARCHAR(10) COMMENT '民族',
residential_city VARCHAR(100) COMMENT '居住城市',
) COMMENT='customer' CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
""")
vn.train(question='年龄最大的是哪个?',sql='SELECT name FROM customer ORDER BY age DESC LIMIT 1')
可能直接给个问答对即可。引导vn去customer表中查询。
不行的话这两句vn.train都加上。
【4 – 测试:与数据库对话】
以上的准备工作完成后,就可以与你的关系型数据库对话了:
vn.ask('统计不同民族数量?')
控制台可以看到输出的结果,包含了SQL和执行结果:
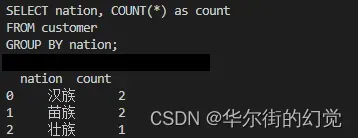
并且会弹出一个网页,显示执行的结果

【5 – 前端Web APP测试】
Vanna提供了一个内置的基于Flask框架的Web APP,可以直接运行后,通过更直观的界面与你的数据库对话,并且具有图表可视化的效果,还内置了简单的RAG Model数据的管理功能。通过这种方式启动web App:


from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
通过默认的端口访问http://localhost:8084,即可与你的数据库对话,界面如下:
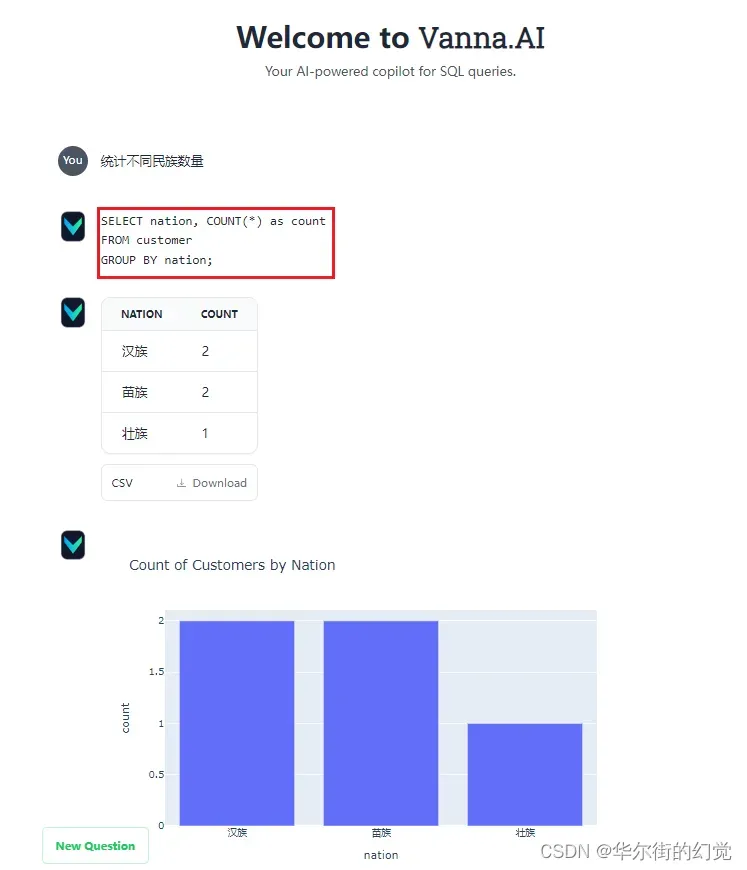
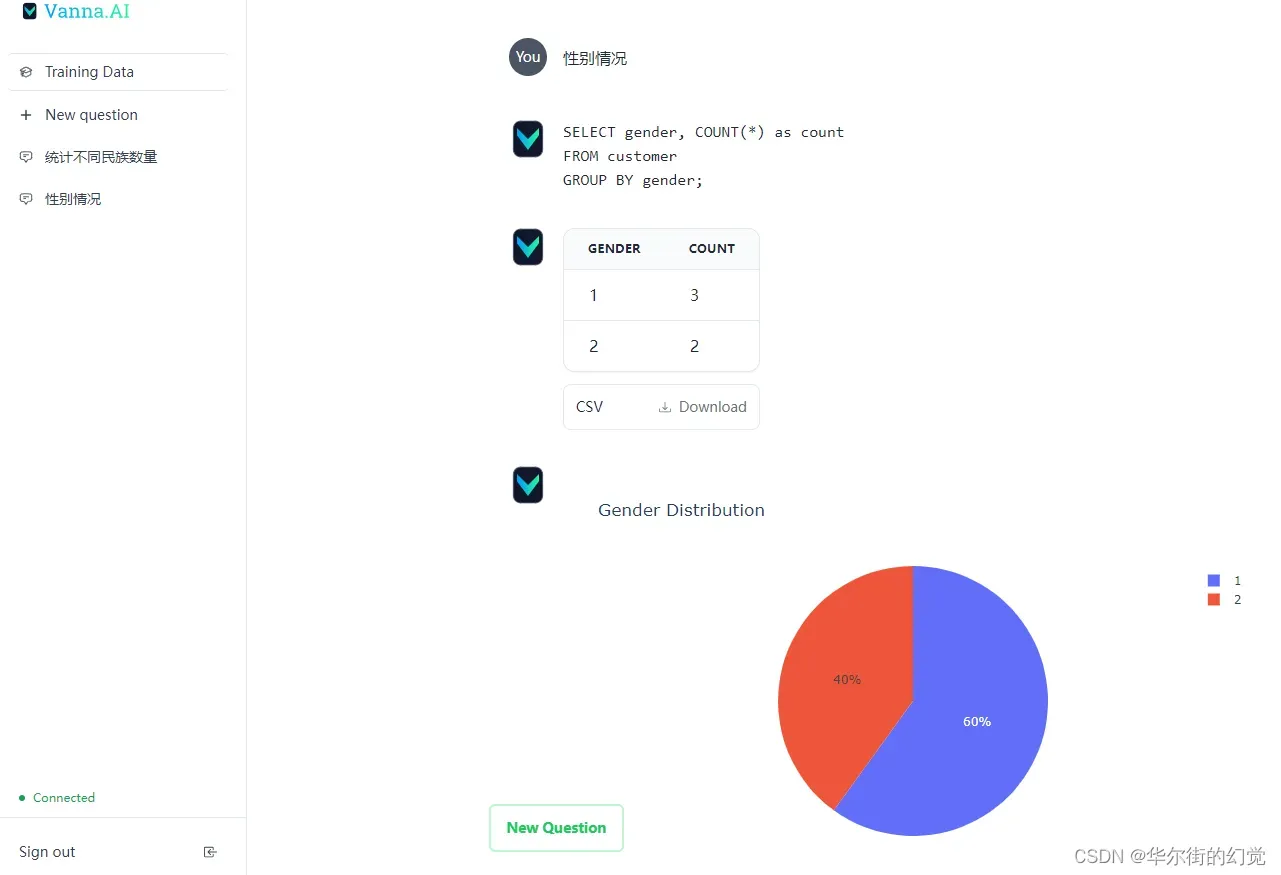
以上,我们深入了解了Vanna这样一个基于Python与RAG的Text2SQL交互式数据分析框架。借助这样的框架,我们无需太多关心Prompt的构建、组装与优化,就可以快速实现一个基于Text2SQL方案的交互式数据库对话机器人,且具备更高的正确率。


此外,Vanna也提供了一些有用的关联功能:
- RAG model数据的查询与管理API
- 基于Plotly的结果可视化API
- 前端Web APP的简单参考实现
在实际测试中,我们也发现Vanna仍然存在一些问题,
- 大部分问题和我们交给Vanna训练RAG model的信息不足
倾向于一次性生成,不便基于上一句SQL进行调优[增、删、改]
根据Vanna.ai官方的未来愿景规划,Vanna旨在成为未来创建AI数据分析师的首选工具。并在准确性(Text2SQL的最大挑战)、交互能力(能够实现交互协作,比如要人类做进一步澄清、解释答案、甚至提出后续问题),与自主性(主动访问必要的系统和数据甚至触发工作流程等)三个方面更加接近人类数据分析师,我们希望Vanna未来能够展示更强大的能力。
6. 训练技巧
利用好 SQL问答对
-
没添加SQL问答对之前
问:居住在重庆市的人有哪些?
答:SQL语句不够准确SELECT name FROM customer WHERE residential_city = '重庆';
-
添加SQL问答对之后
问:居住在重庆市的人有哪些?
答:SQL语句可以模糊匹配,可以得到准确的查询结果SELECT name FROM customer WHERE residential_city LIKE '%重庆%';


代码自取
import vanna
from vanna.remote import VannaDefault
from vanna.flask import VannaFlaskApp
import pandas as pd
import mysql.connector
api_key = '7acxxx68c'
vanna_model_name = 'community'
vn = VannaDefault(model=vanna_model_name, api_key=api_key)
def run_sql(sql: str) -> pd.DataFrame:
cnx = mysql.connector.connect(user='root',password='111000',host='localhost',database='Community')
cursor = cnx.cursor()
cursor.execute(sql)
result = cursor.fetchall()
columns = cursor.column_names
# print('columns:',columns)
df = pd.DataFrame(result, columns=columns)
return df
# 将函数设置到vn.run_sql中
vn.run_sql = run_sql
vn.run_sql_is_set = True
# vn.train(ddl="""
# CREATE TABLE IF NOT EXISTS customer (
# name INT PRIMARY KEY COMMENT '姓名',
# gender INT COMMENT '性别(男性=1/女性=2)',
# id_card VARCHAR(100) COMMENT '身份证',
# mobile VARCHAR(100) COMMENT '手机',
# nation VARCHAR(10) COMMENT '民族',
# residential_city VARCHAR(100) COMMENT '居住城市',
# ) COMMENT='customer' CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
# """)
vn.train(question='年龄最大的是哪个?',sql='SELECT name FROM customer ORDER BY age DESC LIMIT 1')
vn.train(question='居住在重庆的人有哪些?',sql="SELECT name FROM customer WHERE residential_city LIKE '%重庆%'")
first_conversation_sql = vn.ask('居住在重庆的人有哪些?')
print(type(first_conversation_sql))
app = VannaFlaskApp(vn)
app.run()
【参考链接】
手把手教你本地部署开源 Text-to-SQL 工具:Vanna
Vanna:10分钟快速构建基于大模型与RAG的SQL数据库对话机器人
版权声明:本文为博主作者:华尔街的幻觉原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/sinat_29950703/article/details/136658639