

🎀个人主页: https://zhangxiaoshu.blog.csdn.net
📢欢迎大家:关注🔍+点赞👍+评论📝+收藏⭐️,如有错误敬请指正!
💕未来很长,值得我们全力奔赴更美好的生活!
前言
合成纹理图像和SAR(Synthetic Aperture Radar,合成孔径雷达)图像的分割任务在遥感图像处理和计算机视觉领域中具有重要的应用价值。例如对于环境监测、资源管理、灾害应对、国防安全等方面。本文主要介绍基于SLIC超像素和BDSCAN算法的合成纹理图像及SAR图像的分割小实例。
文章目录
- 前言
- 介绍
-
- 1. 合成纹理图像
- 2. 分割任务
- 一、SLIC超像素和BDSCAN算法
-
- 1. 基于SLIC超像素算法的线性谱聚类算法
- 2. 密度聚类算法 (BDSCAN)
- 二、SLIC超像素和BDSCAN算法实验
-
- 1. 基于SLIC超像素算法的线性谱聚类算法实验
- 2. 密度聚类算法 (BDSCAN)实验
介绍
1. 合成纹理图像
-
合成纹理图像通常是通过人工合成或利用纹理合成算法生成的图像。它们具有多样的纹理特征,用于模拟真实场景中的各种地物表面,如土地覆盖、植被类型等。合成纹理图像在图像分割任务中可以用作训练数据,用于模型的训练和验证。
SAR图像: -
合成孔径雷达(SAR)是一种主动遥感技术,利用雷达系统发射脉冲信号,接收反射回来的信号,并利用回波数据生成图像。SAR图像通常具有独特的特征,例如对地物形态、材质和湿度等的敏感性,因此在土地利用、资源管理、环境监测等领域具有广泛的应用。SAR图像分割任务的目的是将图像中的不同地物区域进行有效地分割和识别。
2. 分割任务
图像分割任务旨在将图像中的像素划分为不同的类别或区域,使得每个区域具有相似的特征或语义含义。在合成纹理图像和SAR图像的分割任务中,目标是将图像中的不同地物或地物类型进行分割,以实现对地物的识别和定量分析。
-
合成纹理图像分割任务:旨在将合成纹理图像中的不同地物区域(如建筑、水体、植被等)进行分割,从而实现对地物的识别和分类。
-
SAR图像分割任务:旨在将SAR图像中的不同地物区域(如建筑、道路、植被等)进行分割,以实现对地物的识别和监测。
这些分割任务的结果可以为地理信息系统(GIS)、环境监测、城市规划等应用提供重要的数据支持,有助于对地表覆盖类型、土地利用情况、环境变化等进行定量分析和监测。因此,合成纹理图像和SAR图像的分割任务在地学、地理信息科学、遥感技术和环境科学等领域具有广泛的应用前景。
一、SLIC超像素和BDSCAN算法
1. 基于SLIC超像素算法的线性谱聚类算法
SLIC超像素算法(Simple Linear Iterative Clustering)与线性谱聚类(Linear Spectral Clustering)相结合,可以实现对图像数据进行高效的聚类。基于SLIC超像素算法的线性谱聚类算法的一般步骤如下:
- SLIC超像素分割:使用SLIC算法对输入的图像进行超像素分割。SLIC算法是一种快速而有效的超像素分割算法,它将图像分割成紧密相连的区域,每个区域称为一个超像素。超像素的生成过程是基于图像的空间和颜色信息进行的,因此能够在保持图像结构的同时减少计算量。
- 构建图像的相似度图:基于SLIC超像素的结果,构建图像的相似度图(或称为邻接图)。在相似度图中,每个超像素作为一个节点,根据它们之间的相似度来连接边。
- 计算拉普拉斯矩阵:使用相似度图计算拉普拉斯矩阵。常见的方法包括计算拉普拉斯矩阵的拉普拉斯算子(Laplacian operator)或归一化拉普拉斯矩阵(Normalized Laplacian)。
- 求解特征值分解:对拉普拉斯矩阵进行特征值分解,得到对应的特征向量和特征值。通常只保留最小的K个特征值对应的特征向量,这些特征向量构成了数据的低维表示。
- K均值聚类或谱聚类:将得到的低维特征向量作为输入,使用K均值聚类或谱聚类对数据进行聚类。K均值聚类是一种常见的聚类算法,通过迭代地更新簇中心来实现聚类。谱聚类则是一种基于图论的聚类方法,通过对数据的特征向量进行谱分解来实现聚类。
- 可选的后处理:对聚类结果进行后处理,如将超像素分配给与其最相似的聚类结果,以获得更细粒度的聚类结果。
2. 密度聚类算法 (BDSCAN)
密度聚类算法中的一种经典方法是DBSCAN(Density-Based Spatial Clustering of Applications with Noise),它是一种基于密度的聚类算法,能够有效地识别具有足够高密度的区域,并将它们扩展为簇。DBSCAN算法的基本原理和步骤如下:
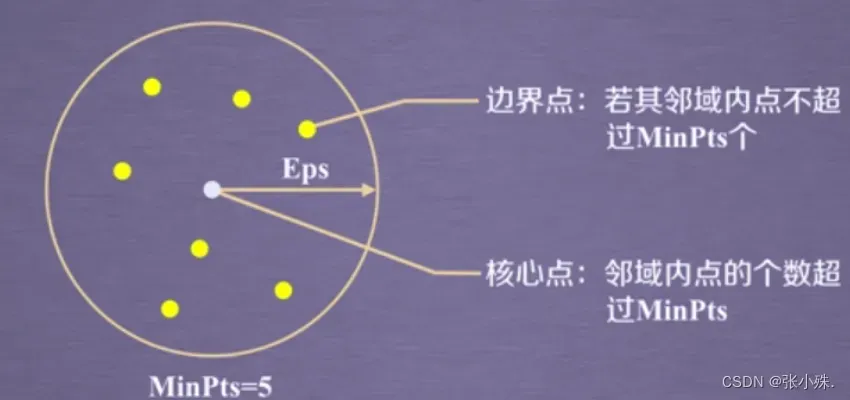

- 定义邻域参数:
- 定义两个参数:邻域半径(ε)和最小点数(MinPts)。
- ε决定了一个点的邻域范围,MinPts是一个点的邻域中最小的数据点数目。
- 标记核心点和边界点:
- 对于数据集中的每个点,计算其ε邻域中的数据点数目。
- 如果某个点的ε邻域内的点数目不少于MinPts,则将其标记为核心点。
- 如果某个点不是核心点,但是它位于某个核心点的ε邻域内,则将其标记为边界点。
- 构建簇:
- 从任意一个未被访问的核心点开始,通过邻域连接,将其密度可达的所有点都分配到同一个簇中。
- 通过密度可达的传递性,不断扩展簇的大小,直到无法再找到新的密度可达点为止。
- 标记噪声点:
- 对于所有不属于任何簇的点,将其标记为噪声点。
二、SLIC超像素和BDSCAN算法实验
1. 基于SLIC超像素算法的线性谱聚类算法实验
算法代码如下所示:
import cv2
import matplotlib.pyplot as plt
# 11.31 LSC 超像素区域分割
# 注意:本例程需要 opencv-contrib-python 包的支持
img = cv2.imread('D:/VSCode/Task_python/lab/homework/Mosaic1_new.tif')
#img = cv2.imread('D:/VSCode/Task_python/lab/homework/river_2.bmp')
imgHSV = cv2.cvtColor(img, cv2.COLOR_BGR2HSV_FULL) # BGR-HSV 转换
# SLIC 算法
slic = cv2.ximgproc.createSuperpixelSLIC(img, region_size=2, ruler=10.0) # 初始化 SLIC
slic.iterate(10) # 迭代次数,越大效果越好
mask_slic = slic.getLabelContourMask() # 获取 Mask,超像素边缘 Mask==1
img_slic = cv2.bitwise_and(img, img, mask=cv2.bitwise_not(mask_slic)) # 在原图上绘制超像素边界
# LSC 算法 (Linear Spectral Clustering)
lsc = cv2.ximgproc.createSuperpixelLSC(img)
lsc.iterate(10)
mask_lsc = lsc.getLabelContourMask()
label_lsc = lsc.getLabels()
number_lsc = lsc.getNumberOfSuperpixels()
mask_inv_lsc = cv2.bitwise_not(mask_lsc)
img_lsc = cv2.bitwise_and(img, img, mask=mask_inv_lsc)
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
plt.figure(figsize=(9, 7))
plt.subplot(221), plt.axis('off'), plt.title("原始图像")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # 显示 img(RGB)
plt.subplot(222), plt.axis('off'), plt.title("线性谱聚类mask")
plt.imshow(mask_lsc, 'gray')
plt.subplot(223), plt.axis('off'), plt.title("SLIC超像素图像")
plt.imshow(cv2.cvtColor(img_slic, cv2.COLOR_BGR2RGB))
plt.subplot(224), plt.axis('off'), plt.title("线性谱聚类图像")
plt.imshow(cv2.cvtColor(img_lsc, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.savefig('D:/VSCode/Task_python/lab/homework/SLIC_LSC_1.jpg')
plt.show()
结果如下图所示:




2. 密度聚类算法 (BDSCAN)实验
算法代码如下所示:
function IDX=DBSCAN_kmeans(GRAY,K,epsilon)
[m1,m2]=size(GRAY);
X=reshape(GRAY,m1*m2,1);
X=double(X);
b=kmeans(X,K);
MinPts=zeros(K,1);
for i =1:K
G=X;
G((b(:)~=i))=[];
G=unique(G);
G(G(:)==0)=[];
y=zeros(numel(G),1);
for q=1:numel(G)
y(q)=numel(RegionQuery(G(q)));
end
MinPts(i)=sum(y)/numel(y);
end
C=0;
n=size(X,1);
IDX=zeros(n,1);
visited=false(n,1);
for i=1:n
if ~visited(i)
visited(X==X(i))=true;
l=b(i);
Neighbors=RegionQuery(X(i));
if numel(Neighbors)>=MinPts(l)
B=zeros(2*n,1);
B(1:numel(Neighbors),1)=Neighbors;
C=C+1;
ExpandCluster(i,C);
end
end
end
IDX=reshape(IDX,m1,m2);
function ExpandCluster(i,C)
IDX((X<=X(i)+epsilon)&(X>=X(i)-epsilon))=C;
visited(X==X(i))=true;
k = 1;
while true
k=k+1;
j = B(k);
if j==0
break;
end
if ~visited(j)
visited(j)=true;
Neighbors2=RegionQuery(X(j));
visited(X==X(j))=true;
l=b(j);
if numel(Neighbors2)>=MinPts(l)
IDX((X<=X(j)+2)&(X>=X(j)-2))=C;
t=sum(sum(B~=0));
B(t+1:t+numel(Neighbors2),1)=Neighbors2;
B1=unique(B);
B1(1)=[];
B=zeros(2*n,1);
B(1:numel(B1),1)=B1;
end
end
end
end
function Neighbors=RegionQuery(i)
D=abs(X-i);
Neighbors=find(D<=epsilon);
end
end
结果如下图所示:




文中图片大多来自论文和网络,如有侵权,联系删除,文中有不对的地方欢迎指正、补充。
版权声明:本文为博主作者:张小殊.原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_46009046/article/details/136990393