
生成模型
文章目录
- 生成模型
- 1. 概述
- 2. 生成模型典型结构-VAE&GAN
- 2.1 VAE
- 2.1.1 简介
- 2.1.2 模型处理流程
- 2.2 GAN
- 2.2.1 简介
- 2.2.2 生成对抗网络要点
- 2.2.3 生成对抗网络的训练准则
- 2.2.4 生成对抗网络模型处理流程
- 3.生成模型和判别模型在AIGC中的应用
- 3.1 生成模型在AIGC中的应用
- 3.1.1 图像生成
- 3.1.2 自然语言生成
- 3.2 判别模型在AIGC中的应用
- 3.2.1 图像分类
- 3.2.2 自然语言分类
- 4. 代码工程实践-GAN生成手写数字
1. 概述
深度学习是一种人工智能的技术,其最大的特点是能够对复杂的数据进行分析和处理。在深度学习中,生成模型和判别模型是两个重要的概念,它们可以帮助我们更好地理解深度学习的工作原理并实现不同的任务。
生成模型和判别模型的区别在于,生成模型是通过学习输入数据的联合分布来进行预测和生成新的数据,而判别模型则是通过学习输入数据与输出标签之间的关系来进行分类和识别。
具体来说,生成模型主要用于生成新的数据样本,例如图像、语音、文本等。其基本思想是通过学习输入数据的联合分布,然后从这个分布中采样来生成新的数据。其中最常用的生成模型包括自编码器、变分自编码器、生成对抗网络等。

自编码器是一种简单但有效的生成模型,其基本思想是将输入数据压缩到一个低维空间中,然后再将其还原回原始空间。变分自编码器是自编码器的一种升级版,它能够生成具有更丰富的随机性和多样性的数据。而生成对抗网络则是由生成器和判别器两个部分组成,其中生成器用于生成新的数据样本,而判别器则用于判断生成的数据是否真实。
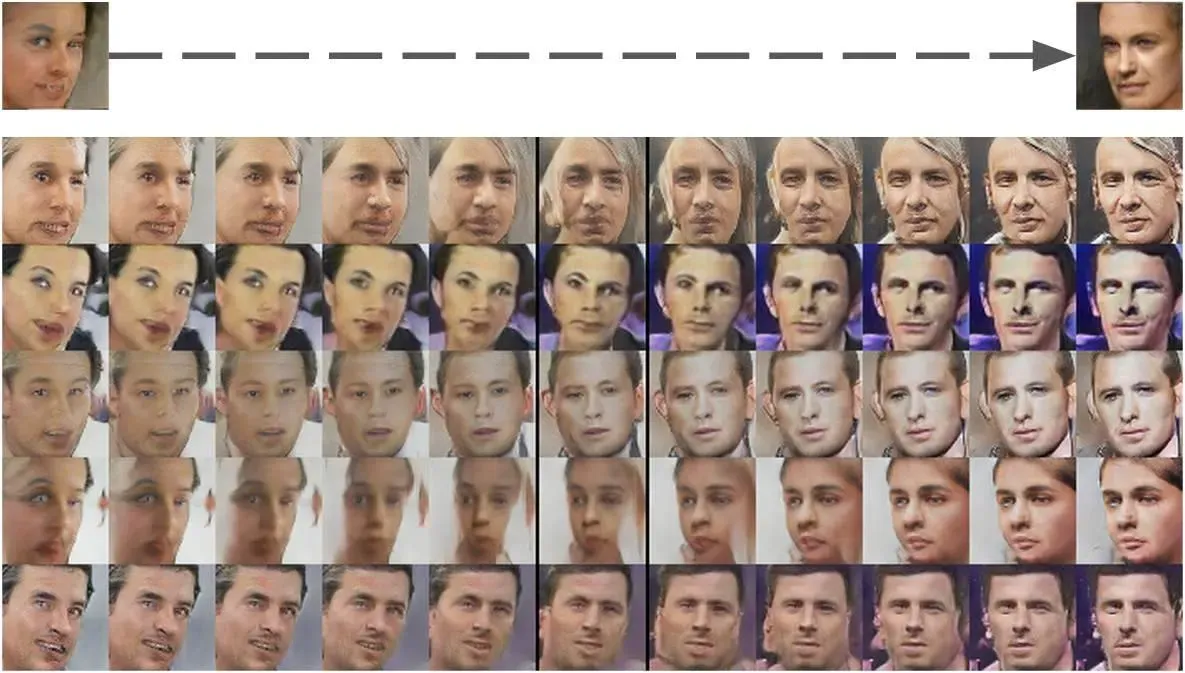
相比之下,判别模型主要用于分类和识别任务,例如图像分类、语音识别、自然语言处理等。其基本思想是通过学习输入数据与输出标签之间的关系来进行分类和识别。常见的判别模型包括支持向量机、随机森林、卷积神经网络等。
本专栏在本章之前所涉及的模型均为判别模型
卷积神经网络是一种非常成功的判别模型,它在图像和自然语言处理领域取得了很大的成功。其基本结构是由多个卷积层和池化层组成,在学习过程中能够提取出数据的空间和时间特征,从而实现对数据的分类和识别。
2. 生成模型典型结构-VAE&GAN
2.1 VAE
2.1.1 简介
VAE是一种生成模型,全称为Variational Autoencoder,中文名为变分自编码器。它是自编码器的一种改进版本,能够生成具有更丰富的随机性和多样性的数据。
VAE是通过学习输入数据的潜在分布来进行预测和生成新的数据。与传统的自编码器不同,VAE引入了隐变量(latent variables)的概念,将输入数据压缩到一个低维的潜在空间中,然后从该潜在空间中采样来生成新的数据。这一过程可以看作是一个从给定分布中随机取样的过程,因此生成的样本具有很强的随机性和多样性。
2.1.2 模型处理流程
假设我们有如下网络,输入是一组元素均为1的向量,输出的目标是一张猫脸图像,经过多次迭代训练,理想状态下,只要输入为元素全1的向量就能得到这张猫脸图像。这种思想实现的原理实际上根据经验,就是将图片参数保存起来,通过网络的拟合映射,将输入映射为了保存的图像参数。
=
这样做的意义在于将高维空间的猫脸图像信息降维映射为了低维空间的向量,尝试使用更多的图片。这次我们用one-hot向量而不是全1向量。如果用代表猫,用
代表狗。虽然这也没什么问题,但是我们最多只能储存4张图片。于是,我们可以增加向量的长度和网络的参数,那么我们可以获得更多的图片。例如,将这个向量定义为四维,采用one-hot的表达方式表达四张不同的脸,那么这个网络就可以表达四个脸。输入不同的数据,他就会输出不同的脸来。
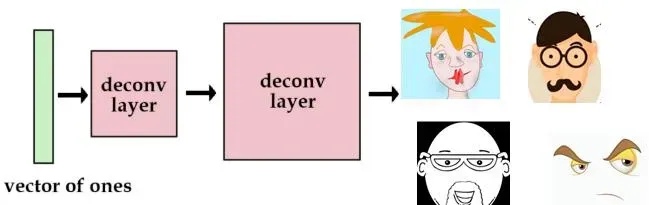
这样的输入向量的缺点就是向量稀疏,一种有效的优化思路就是使用实数向量而不是非0即1的向量。可认为这种实数值向量是原图片的一种编码,这也就引出了编码/解码的概念。
eg:
代表猫,
代表狗。
这个已知的初始向量可以作为我们的潜在变量。
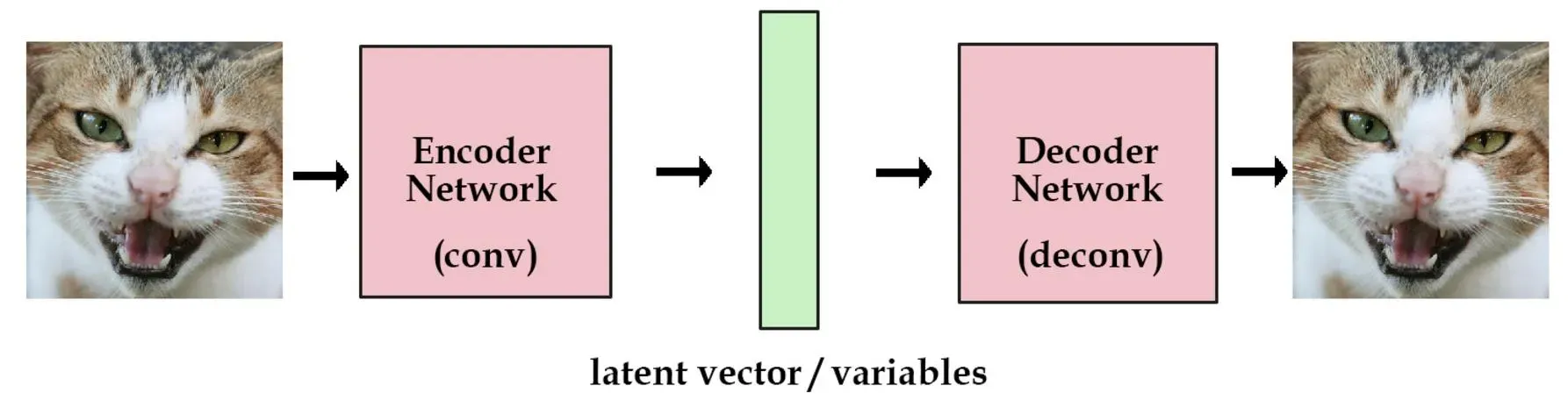
在auto encoder模型中,一个编码器能帮用户把图片编码成向量。然后解码器能够把这些向量恢复成图片。
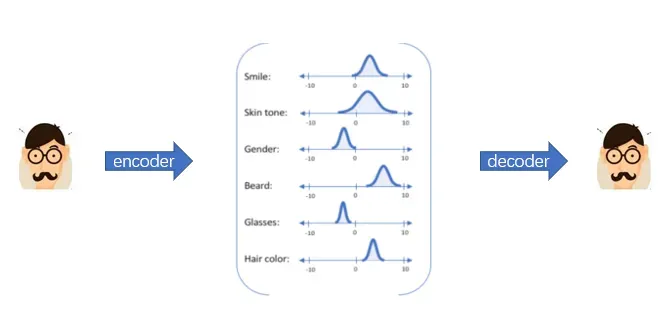
在下面这个图中,我们通过六个因素来描述最终的人脸形状,而这些因素不同的值则代表了不同的特性。

在上述建模中,输入和输出的约束是严格限定的,为了达到生成模型的效果(产生未知的输出),那么,可以设定一个先验分布(潜在变量z的抽样分布)和一个后验分布(输入数据x的抽样分布),先验分布通常选择为标准正态分布(N(0,1)),而后验分布则根据输入的数据x来生成,通常选择为高斯分布。然后,我们需要最小化重构误差和KL散度两个损失函数,以实现训练目标。
重构误差表示生成的样本与原始样本之间的误差,其计算方法类似于传统自编码器。而KL散度则用于度量先验分布和后验分布之间的差异,以确保生成的样本具有一定的随机性和多样性。
2.2 GAN
2.2.1 简介
GAN是一种生成模型,全称为Generative Adversarial Networks,中文名为生成对抗网络。它由生成器和判别器两个部分组成,能够生成逼真的图像、音频、文本等数据。
在GAN中,生成器用于生成逼真的数据样本,而判别器则用于判断输入的数据是真实的还是伪造的。生成器和判别器通过相互对抗的方式进行训练。具体来说,生成器生成假样本,判别器将真假样本进行分类,生成器会调整参数尝试生成更逼真的样本,判别器也随之进行更新以提高判断度,最终使得生成器可以生成逼真的样本。
2.2.2 生成对抗网络要点
- 对抗网络有一个生成器(Generator),还有一个判别器 (Discriminator)
- 生成器从随机噪声中生成图片,由于这些图片都是生成器臆想出来的,所以我们称之为 Fake Image;
- 生成器生成的照片Fake Image和训练集里的Real Image都会传入判别器,判别器判断他们是 Real 还是 Fake。
2.2.3 生成对抗网络的训练准则
-
生成器生成的图片足够真实,可以骗过判别器;
-
判别器足够“精明”,可以很好的分别出真图还是生成图;
-
最后在训练中,生成器和判别器达到一种“对抗”中的平衡,结束训练。
-
分离出生成器,它便可以帮助我们“生成”想要的图片。
2.2.4 生成对抗网络模型处理流程
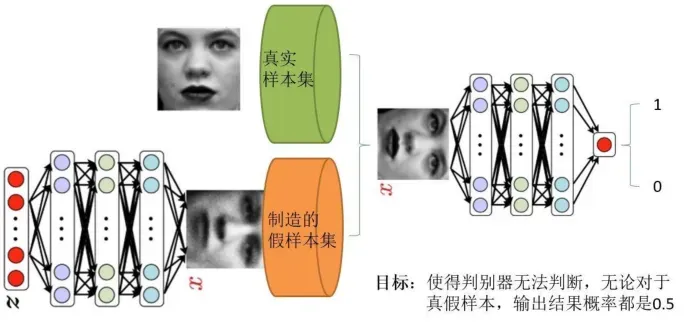
生成对抗网络的输入:
我们有的只是真实采集而来的人脸样本数据集,仅此而已,而且很关键的一点是我们连人
脸数据集的类标签都没有,也就是我们不知道那个人脸对应的是谁。
生成对抗网络的输出:
通过输入一个噪声,模拟得到一个人脸图像,这个图像可以非常逼真以至于以假乱真。
首先判别模型,就是图中右半部分的网络,直观来看就是一个简单的神经网络结构,输入就是一副图
像,输出就是一个概率值,用于判断真假使用(概率值大于0.5那就是真,小于0.5那就是假),真假也不过是人们定义的概率进行的阈值分类。
其次是生成模型,同样也可以看成是一个神经网络模型,输入是一组随机数Z,输出是一个图像,不再
是一个数值。从图中可以看到,会存在两个数据集,一个是真实数据集,另一个是假的数据集.
GAN的训练目标:
- 判别网络的目的:就是能判别出来输入的一张图它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0,达到了很好的判别的目的。
- 生成网络的目的:生成网络是造样本的,它的目的就是使得自己造样本的能力尽可能强,尽可能的使判别网络没法判断是真样本还是假样本。
GAN中的对抗来源于生成器和判别器,生成器和判别器前者训练自己生成”假图“使其越来越逼真,判别器训练自己鉴伪的能力,在内卷中,使得生成模型的效果越来越好。
GAN的训练-单独交替训练
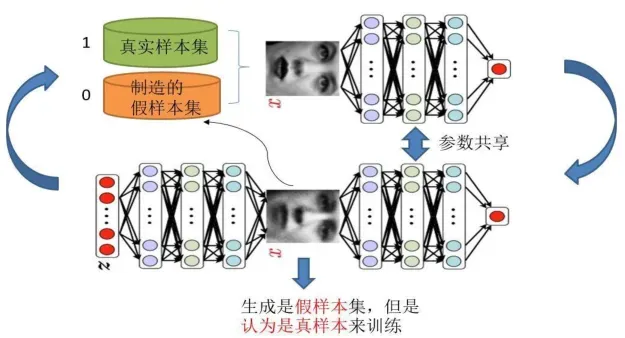
-
判别网络的训练
真样本集以及它们的label(都是1)、假样本集以及它们的label(都是0)
这样单就判别网络来说,此时问题就变成了一个再简单不过的有监督的二分类问题了,直接送
到神经网络模型中训练就可以了。 -
生成网络的训练
对于生成网络的训练其实是对生成-判别网络串接的训练。
对于样本,我们要把生成的假样本的标签都设置为1,也就是认为这些假样本在生成网络训练的时候是真样本。
那么为什么要这样呢?我们想想,是不是这样才能起到迷惑判别器的目的,也才能使得生成的假样本逐渐逼近为真样本。
现在对于生成网络的训练,我们有了样本集(只有假样本集,没有真样本集),有了对应的label(全为1)。注意,在训练这个串接的网络的时候,一个很重要的操作就是不要更新判别网络的参数,只是把误差一直传,传到生成网络后更新生成网络的参数。
在完成生成网络训练后,我们就可以根据目前新的生成网络再对先前的那些噪声Z生成新的假样本了。
并且训练后的假样本应该是更真了才对。所有这样我们又有了新的真假样本集,这样又可以重复上述过程了。我们把这个过程称作为单独交替训练。
3.生成模型和判别模型在AIGC中的应用
3.1 生成模型在AIGC中的应用
3.1.1 图像生成
在AIGC中,图像生成是一个重要的任务。通过图像生成技术,我们可以生成逼真的图像样本,从而用于数据增强、图像修复等应用。在这个任务中,常用的生成模型有GAN、VAE等。
以GAN为例,它由生成器和判别器两个部分组成。生成器用于生成逼真的图像样本,而判别器则用于判断生成的图像是否真实。在GAN训练过程中,生成器和判别器相互对抗,最终生成器可以生成逼真的图像样本。
3.1.2 自然语言生成
自然语言生成是另一个重要的任务,在AIGC中也得到广泛的应用。通过自然语言生成技术,我们可以生成符合语法规则和语义逻辑的文本,从而用于聊天机器人、翻译机器人等应用。在这个任务中,常用的生成模型有LSTM、Transformer等。
以Transformer为例,它是一种非常成功的自然语言生成模型。它能够学习到文本中的语法结构和语义信息,从而生成符合逻辑的文本。在AIGC中,Transformer被广泛应用于机器翻译、对话系统等领域。
3.2 判别模型在AIGC中的应用
3.2.1 图像分类
图像分类是深度学习领域中最为常见的任务之一,在AIGC中也得到了广泛的应用。通过图像分类技术,我们可以将输入的图像分为不同的类别,从而实现自动化的图像分类和标注。在这个任务中,常用的判别模型有卷积神经网络(CNN)等。
以CNN为例,它是一种非常成功的图像分类模型。它利用卷积层和池化层提取图像的特征,然后通过全连接层进行分类。在AIGC中,CNN被广泛应用于图像分类、目标检测等领域。
3.2.2 自然语言分类
自然语言分类是另一个重要的任务,在AIGC中也得到广泛的应用。通过自然语言分类技术,我们可以将输入的文本分为不同的类别,从而实现自动化的文本分类和标注。在这个任务中,常用的判别模型有卷积神经网络、循环神经网络(RNN)等。
以RNN为例,它是一种可以处理序列数据的判别模型。它能够学习到文本中的序列信息和上下文信息,从而实现自然语言分类和识别。在AIGC中,RNN被广泛应用于情感分析、文本分类等领域。
综上所述,生成模型和判别模型在AIGC中都得到了广泛的应用,涉及了图像、自然语言等多个领域。通过深入理解这些技术的原理和应用场景,我们可以更好地应用它们来解决实际问题。
4. 代码工程实践-GAN生成手写数字
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
import matplotlib.pyplot as plt
import sys
import numpy as np
class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# The generator takes noise as input and generates imgs
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The discriminator takes generated images as input and determines validity
validity = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
self.combined = Model(z, validity)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
model = Sequential()
model.add(Dense(256, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
model = Sequential()
model.add(Flatten(input_shape=self.img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, sample_interval=50):
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3)
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random batch of images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Generate a batch of new images
gen_imgs = self.generator.predict(noise)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Train the generator (to have the discriminator label samples as valid)
g_loss = self.combined.train_on_batch(noise, valid)
# Plot the progress
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# If at save interval => save generated image samples
if epoch % sample_interval == 0:
self.sample_images(epoch)
def sample_images(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("./images/mnist_%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=2000, batch_size=32, sample_interval=200)
文章出处登录后可见!