

行索引、列索引、loc和iloc
import pandas as pd
import numpy as np
# 准备数据
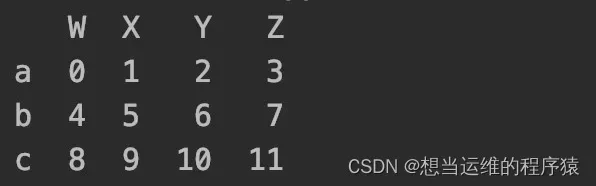
df = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))

-
行索引(index):对应最左边那一竖列
-
列索引(columns):对应最上面那一横行
-
.loc[]官方释义: Access a group of rows and columns by label(s) or a boolean array.(通过标签或布尔数组访问一组行和列) 官方链接
- loc使用索引来取值,基础用法 df.loc[[行索引],[列索引]]
-
.iloc[]官方释义: Purely integer-location based indexing for selection by position.(按位置进行索引选择) 官方链接
- iloc使用位置(从0开始)来取值,基础用法 df.iloc[[行位置],[列位置]]
一、根据列索引取某一列/多列(常用)
df['W'] # 取‘W’列,返回类型是Series
df[['W']] # 取‘W’列,返回类型是DataFrame
df[['W','Y']] # 取‘W’列和‘Y’列
df.loc[:,'W':'Y'] # 取‘W’列到‘Y’列
二、根据行索引取某一行/多行
df.loc['a'] # 取‘a’行,返回类型是Series
df.loc[['a']] # 取‘a’行,返回类型是DataFrame
df.loc[['a','c']] # 取‘a’行和‘c’行,也可以写成 df.loc[['a','c'],:]
df.loc['a':'c',:] # 取‘a’行到‘c’行
三、根据列位置取某一列/多列
df.iloc[:,1] # 取第2列(‘X’列),列号为1,返回类型是Series
df.iloc[:,0:2] # 取前2列(‘W’列和‘X’列),列号为0和1
df.iloc[:,0:-1] # 取最后一列之前的所有列
四、根据行位置取某一行/多行(常用)
df[:2] #取前2行,行号为0和1
df[1:2] #取第2行,行号为1
df.iloc[1] # 取第2行(‘b’行),行号为1,返回类型是Series,也可以写成df.iloc[1,:]
五、取某一行某一列(常用)
df.loc['b','W'] # 取‘b’行‘W’列的值
df.iloc[0]['W'] # 取第1行、‘W’列的值
六、取多行多列
df[:2][['W','Y']] # 取前2行的‘W’列和’Y‘列
df[:2].loc[:2,'W':'Y'] # 取前2行的‘W’列到’Y‘列
df.iloc[0][['W','Y']] # 取第1行的‘W’列和’Y‘列
df.iloc[0]['W':'Y'] # 取第1行的‘W’列到’Y‘列
df.loc[["a","c"],["W","Y"]] # 取‘a’行和‘c’行,‘W’列和‘Y’列
df.iloc[[0,2],[1,3]] # 取1、3行,2、4列
总结: 一般通过行位置来取行,通过列索引来取列,且行索引大多数情况下和行位置是相同的。
最常用的是以下几个
# 取某一列
df['W']
# 取某一行
df.iloc[0]
# 取多列
df.loc[:,'W':'Y'] # 取‘W’列到‘Y’列
df.iloc[:,0:-1] # 取最后一列之前的所有列
# 取对应行列的值
df.iloc[0]['W']
df.loc['a','W'] # 在行索引和行位置相同的情况下的写法就是,df.loc[0,'W']
文章出处登录后可见!
已经登录?立即刷新