一、首先要保证自己的环境已经配置完整,可以跑通自带图片的检测
二、准备自己的数据集,(使用labelimg)
1.在yolov5-5.0创建一个新的文件夹,比如map_gongxunsai,在此文件夹下创建
labels (存放labelimg生成的标注文件)
images (存放图片)
ImageSets (在此文件夹再创建一个Main文件夹)
文件夹
最新的labelimg已经可以直接标注产生yolov5可用的.txt文件,不需要再使用voc转txt的脚本了。
选择这个就可以生成.txt文件了。
2.可以使用下面的代码进行训练集、验证集、测试集的划分,由于之前使用的仍然是voc转txt的方法,所以有些变量名没有更改,但是对应的文件夹已更改
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#txt文件的地址,根据自己的数据进行修改
parser.add_argument('--xml_path', default='labels', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行代码后,在Main文件夹下生成下面四个txt文档:

3.创建label.py文件,将数据集路径导入txt文件中,代码内容如下:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = [
"H",
"A",
"B",
"C",
] # 改成自己的类别,注意这里存放的顺序和当初标注的各个类别顺序一致
abs_path = os.getcwd()
print(abs_path)
for image_set in sets:
image_ids = open('//home//jcfh//Desktop//yolov5-5.0//map_gongxunsai//ImageSets//Main//%s.txt' % (image_set)).read().strip().split()
list_file = open('//home//jcfh//Desktop//yolov5-5.0//map_gongxunsai//%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '//images//%s.jpg\n' % (image_id))
list_file.close()
运行代码会生成三个txt文件:
txt里面是图片的路径
4.配置文件
1)数据集的配置
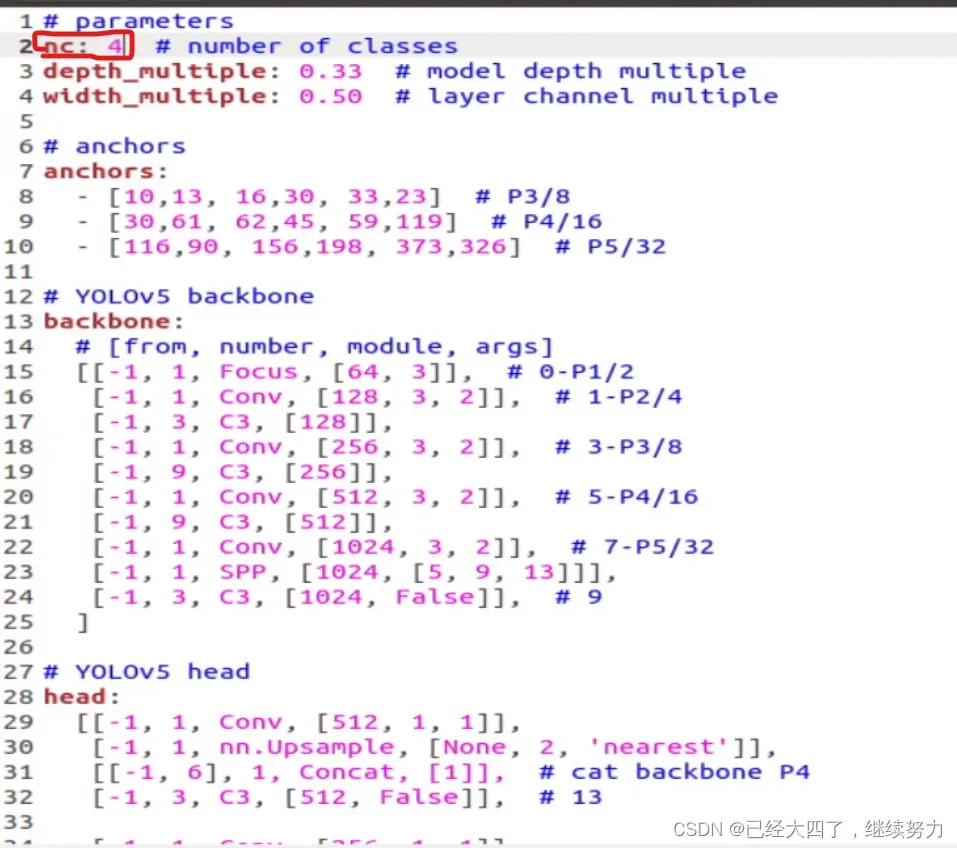
在yolov5目录下的data文件夹下新建一个map.yaml文件(可以自定义命名),用来存放训练集和验证集的划分文件(train.txt和val.txt),这两个文件是通过运行label.py代码生成的,然后是目标的类别数目和具体类别列表,map.yaml内容如下:

nc是你的模型里物体有多少个类别,names是每个类别的名称。注意‘:’后面一定有个空格!
2)选择一个你需要的模型
在yolov5-5.0目录下的model文件夹下是模型的配置文件,这边提供s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大),假设采用yolov5s.yaml,只用修改一个参数,把nc改成自己的类别数;
自定义数据集就算是创建完毕了,接下来就是训练模型了。
三.模型训练
1.在weights文件夹里面有四个预训练模型:
s是最轻量化的,我们假设使用该模型。
2.训练
我们需要修改train.py程序里面的几个参数:
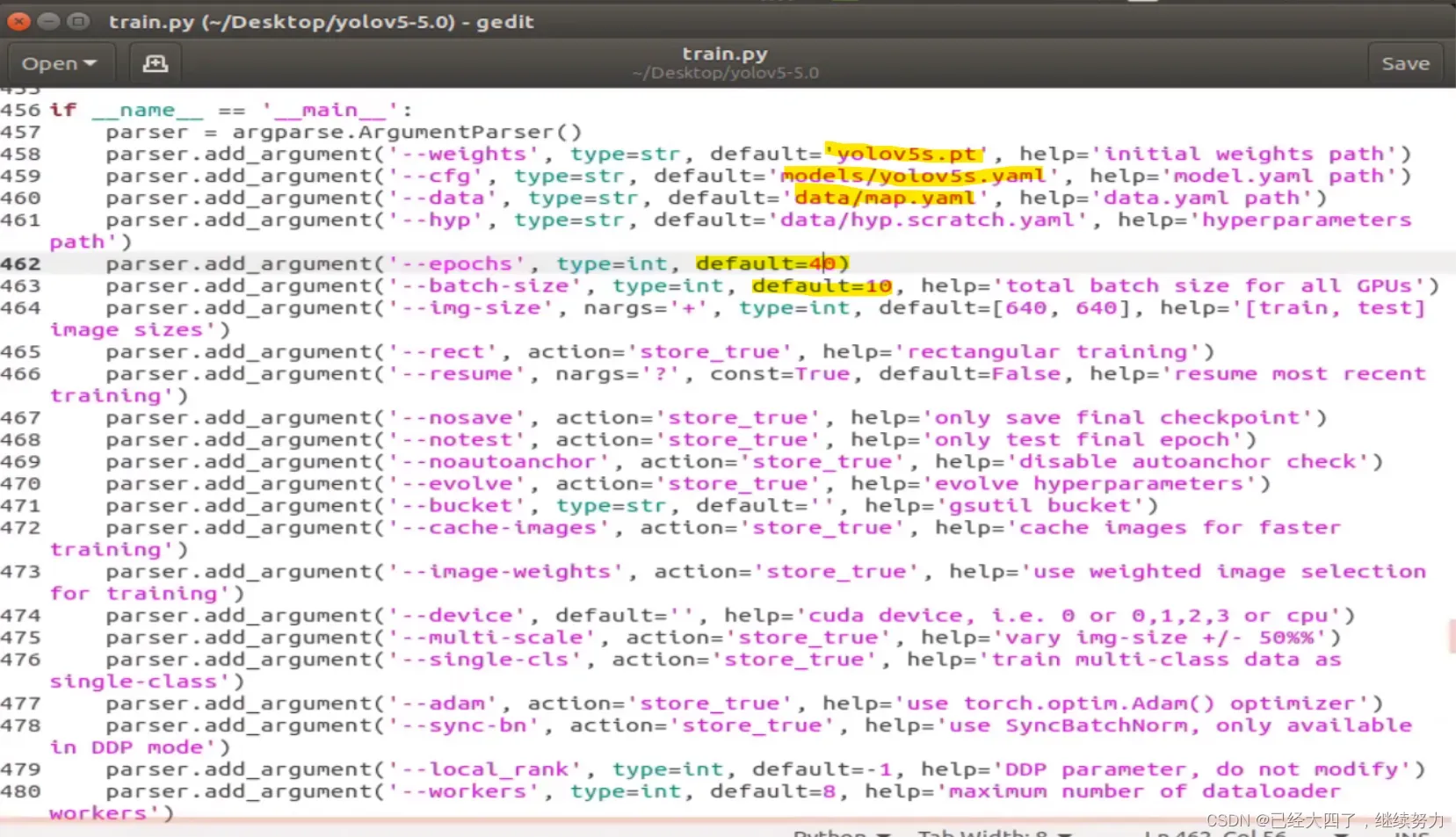
python3 train.py
训练好的模型会被保存在yolov5-5.0目录下的runs/exp0/weights/last.pt和best.pt,详细训练数据保存在runs/exp0/results.txt文件中。
最好把runs文件夹的权限改成最大,以免权限不够无法运行程序:
sudo chmod 777 runs (每个人都有读和写以及执行的权限)
3.模型推理
在detect.py文件中指定测试图片和测试模型的路径,其他参数(img_size、置信度object confidence threshold、IOU threshold for NMS)可自行修改:
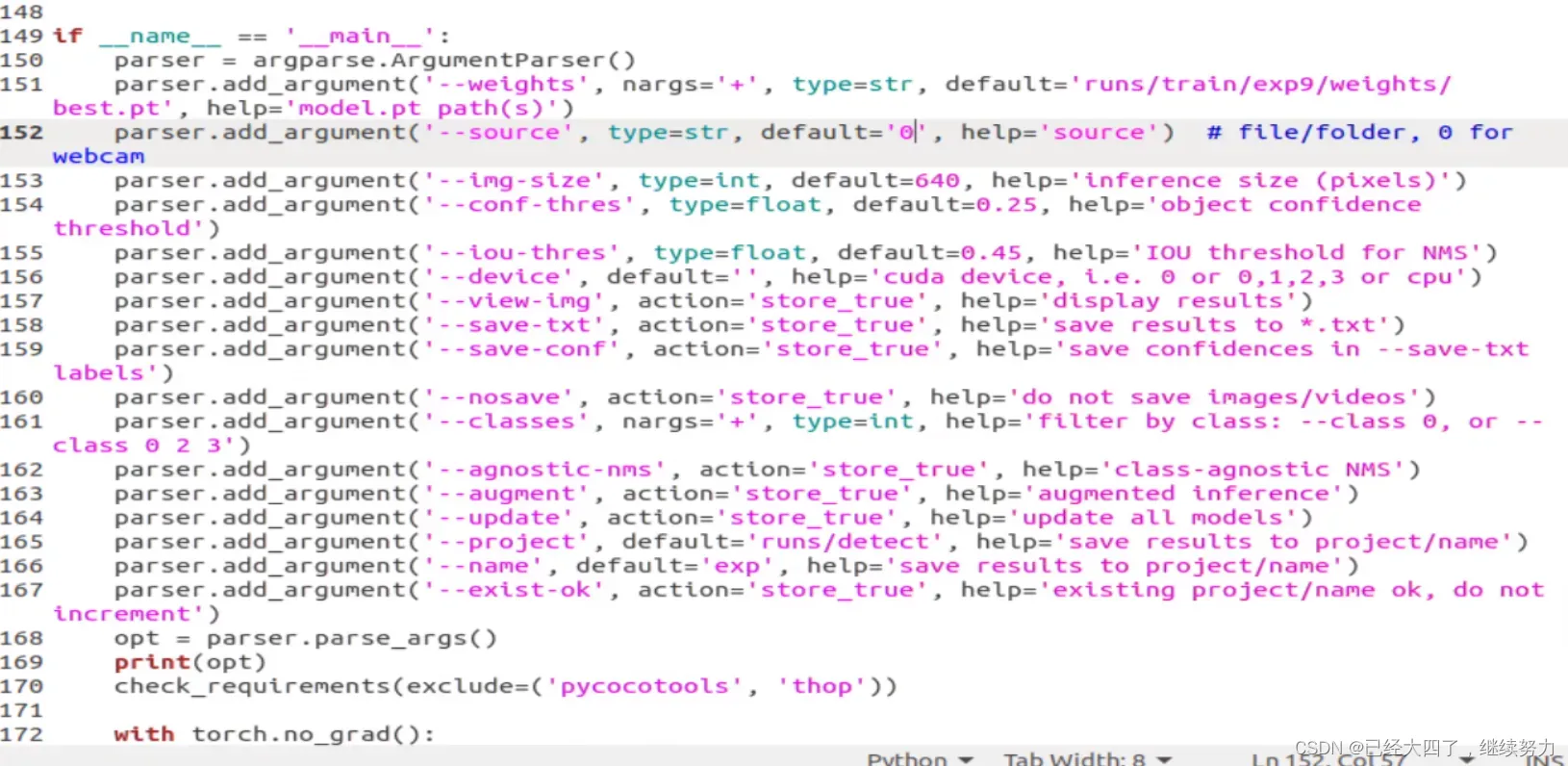
然后运行:
python3 detect.py
或者运行如下指令:
python3 detect.py --weights runs/exp1/weights/best.pt --source inference/images/
会在runs/detect/exp1文件下生成检测后的图片,如果source更改为0就是预测默认摄像头的实时数据
文章出处登录后可见!