介绍
通过微调,您可以通过提供以下内容从通过 API 提供的模型中获得更多收益:
- 比提示设计更高质量的结果
- 能够训练比提示所能容纳的更多示例
- 由于提示时间较短,可以节省代币
- 更低的延迟请求
GPT-3 已经对来自开放互联网的大量文本进行了预训练。当给出一个只有几个例子的提示时,它通常可以直观地判断你正在尝试执行什么任务并生成一个合理的完成。这通常被称为“少镜头学习”。
微调通过训练比提示所能容纳的更多的示例来改进少数镜头学习,让您在大量任务上获得更好的结果。对模型进行微调后,无需再在提示中提供示例。这样可以节省成本并实现更低的延迟请求。
概括地说,微调涉及以下步骤:
- 准备和上传训练数据
- 训练新的微调模型
- 使用微调模型
请访问我们的定价页面,详细了解如何对微调的模型训练和使用计费。
哪些模型可以微调?
微调目前仅适用于以下基本型号:ada、babbage、curie、davinci,最新的gpt-3.5-turbo-0301是不支持微调的。
安装
我们建议使用我们的 OpenAI 命令行界面 (CLI)。要安装它,请运行
pip install --upgrade openai(以下说明适用于版本 0.9.4 及更高版本。此外,OpenAI CLI 需要 python 3。
通过在 shell 初始化脚本(例如 .bashrc、zshrc 等)中添加以下行或在微调命令之前的命令行中运行它来设置环境变量:OPENAI_API_KEY
#Linux命令
export OPENAI_API_KEY=<OPENAI_API_KEY>
#windows命令
set OPENAI_API_KEY=<OPENAI_API_KEY>未设置好环境变量会报错提示:

准备训练数据
训练数据是你教 GPT-3 你想说什么的方式。
您的数据必须是 JSONL 文档,其中每行都是对应于训练示例的提示完成对。您可以使用我们的 CLI 数据准备工具轻松地将数据转换为此文件格式。
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...设计用于微调的提示和完成与设计用于我们基本模型(Davinci、Curie、Babbage、Ada )的提示不同。特别是,虽然基础模型的提示通常由多个示例组成(“少数镜头学习”),但为了微调,每个训练示例通常由单个输入示例及其关联的输出组成,而无需给出详细说明或在同一提示中包含多个示例。
有关如何为各种任务准备训练数据的更详细指导,请参阅我们准备数据集最佳实践。
您拥有的培训示例越多越好。我们建议至少有几百个示例。通常,我们发现数据集大小每增加一倍,模型质量就会线性提高。
CLI 数据准备工具
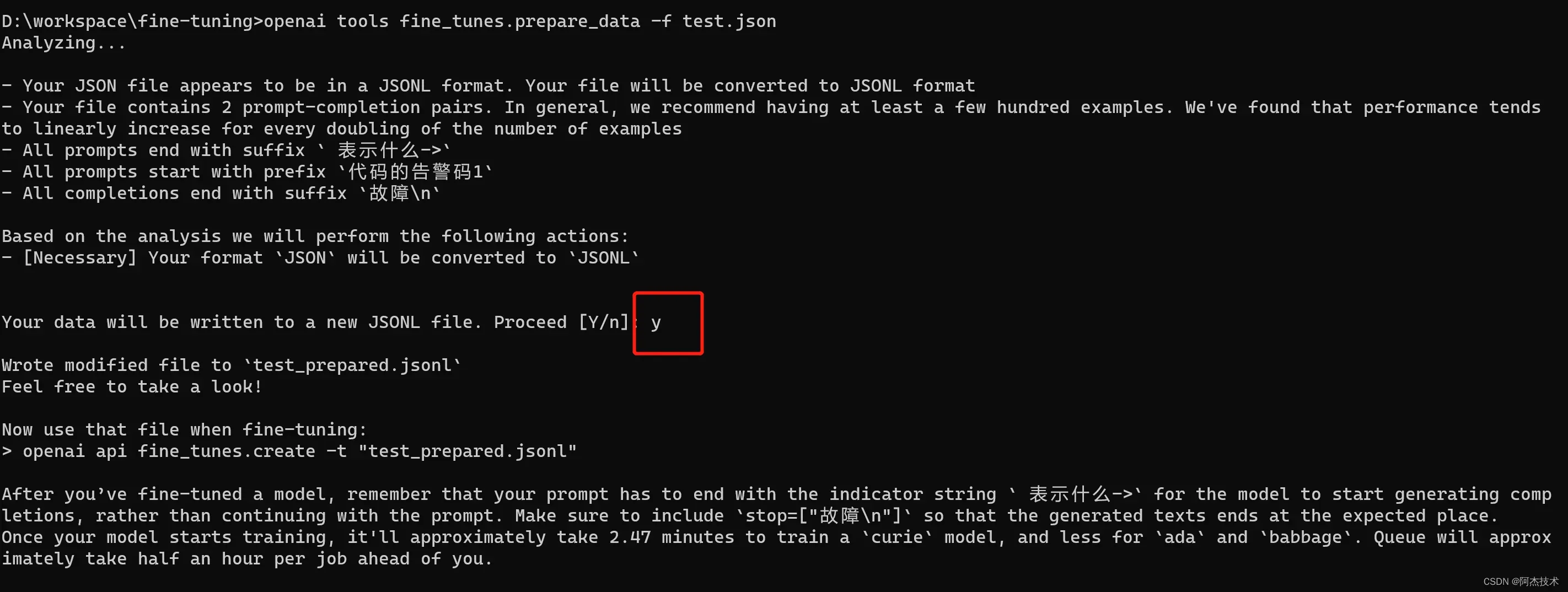
我们开发了一个工具来验证、提供建议和重新格式化您的数据:
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>此工具接受不同的格式,唯一要求它们包含提示和完成列/键。您可以传递 CSV、TSV、XLSX、JSON 或 JSONL 文件,它会在指导您完成建议的更改过程后,将输出保存到 JSONL 文件中,以便进行微调。
创建微调模型
以下假设你已按照上述说明准备了训练数据。
使用 OpenAI CLI 启动微调作业:
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL> 您从哪里开始的基本模型的名称(ada、babbage、居里或达芬奇)。您可以使用后缀参数自定义微调模型的名称。
您从哪里开始的基本模型的名称(ada、babbage、居里或达芬奇)。您可以使用后缀参数自定义微调模型的名称。BASE_MODEL
运行上述命令会执行以下几项操作:
- 使用文件 API 上传文件(或使用已上传的文件)
- 创建微调作业
- 流式传输事件,直到作业完成(这通常需要几分钟,但如果队列中有许多作业或数据集很大,则可能需要数小时)
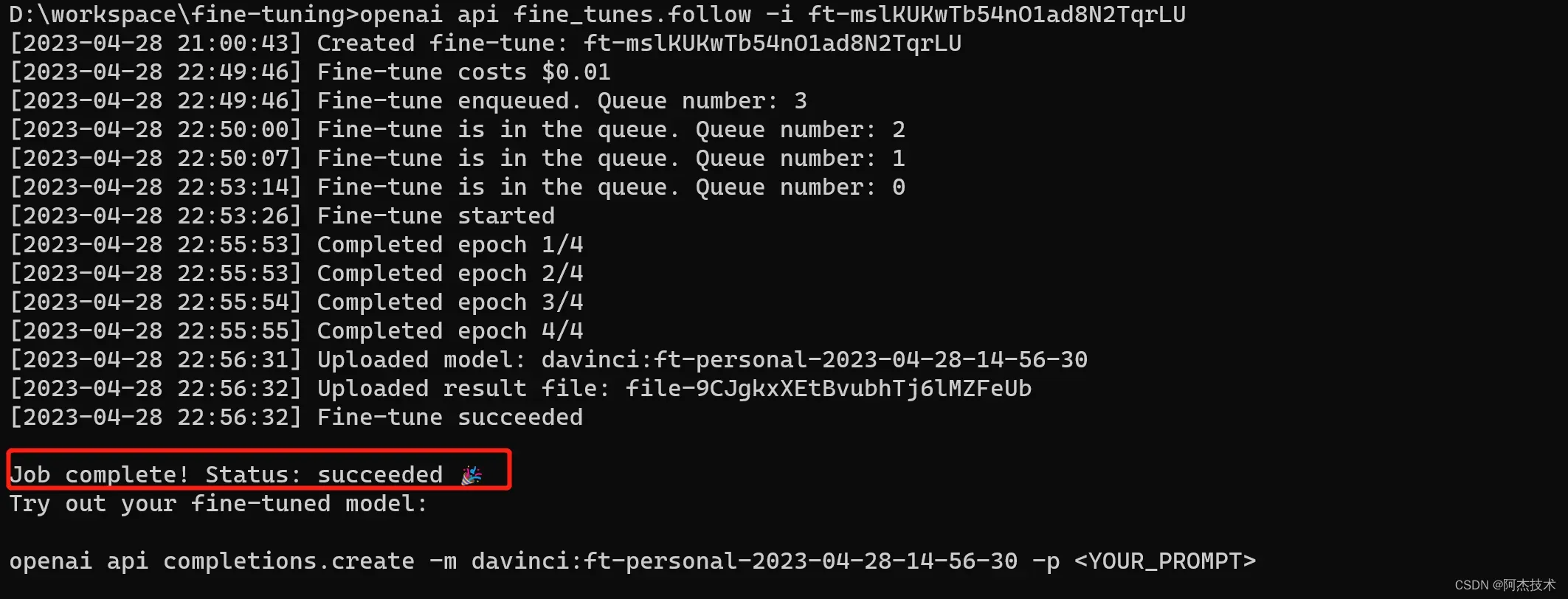
开始微调作业后,可能需要一些时间才能完成。你的作业可能排在我们系统上的其他作业后面,训练我们的模型可能需要几分钟或几小时,具体取决于模型和数据集大小。如果事件流因任何原因中断,运行以下命令来恢复模型执行:
openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>作业完成后,它应显示微调模型的名称。
除了创建微调作业之外,您还可以列出现有作业、检索作业状态或取消作业。
# 列表显示已创建的微调模型
openai api fine_tunes.list
#检索微调的状态。生成的对象包括
#作业状态(可以是挂起、正在运行、成功或失败之一)
#其他信息
openai api fine_tunes.get -i <YOUR_FINE_TUNE_JOB_ID>
# 取消任务
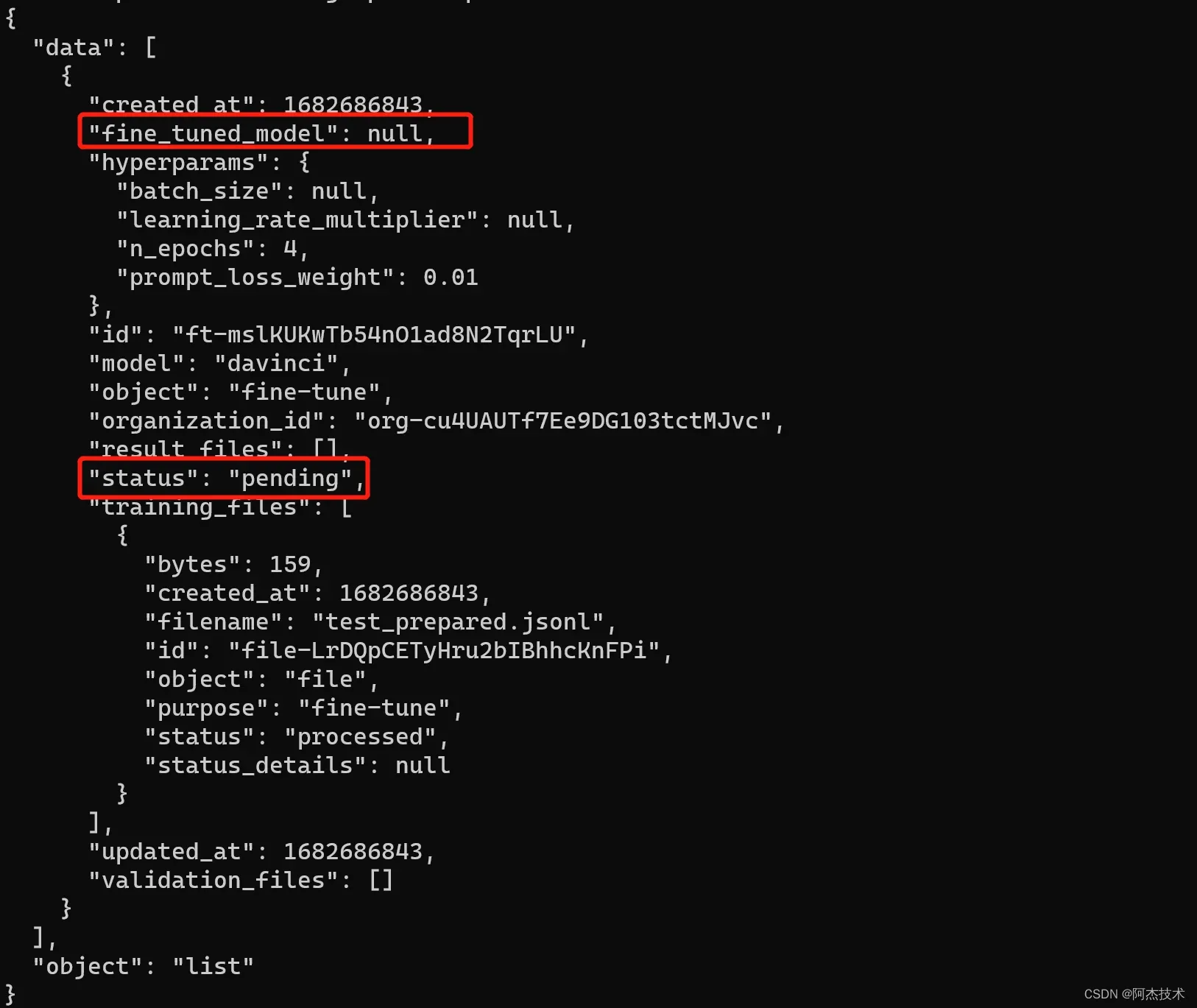
openai api fine_tunes.cancel -i <YOUR_FINE_TUNE_JOB_ID>正在运行创建模型,fine_tuned_model为空
使用微调模型
作业成功后,将使用模型名称fine_tuned_model填充该字段。您现在可以将此模型指定为我们的完成 API 的参数,并使用 Playground 向其发出请求。
作业首次完成后,模型可能需要几分钟才能准备好处理请求。如果对模型的完成请求超时,则可能是因为模型仍在加载中。如果发生这种情况,请在几分钟后重试。
您可以通过将模型名称作为完成请求的参数传递来开始发出请求:model
OpenAI CLI:
openai api completions.create -m <FINE_TUNED_MODEL> -p <YOUR_PROMPT>cURL:
curl https://api.openai.com/v1/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{"prompt": YOUR_PROMPT, "model": FINE_TUNED_MODEL}'Python:
import openai
openai.Completion.create(
model=FINE_TUNED_MODEL,
prompt=YOUR_PROMPT)Node.js:
const response = await openai.createCompletion({
model: FINE_TUNED_MODEL
prompt: YOUR_PROMPT,
});
删除微调的模型
若要删除微调的模型,必须在组织内指定“所有者”。
OpenAI CLI:
openai api models.delete -i <FINE_TUNED_MODEL>cURL:
curl -X "DELETE" https://api.openai.com/v1/models/<FINE_TUNED_MODEL> \
-H "Authorization: Bearer $OPENAI_API_KEY"Python:
import openai
openai.Model.delete(FINE_TUNED_MODEL)文章出处登录后可见!