

第1关:线性回归模型应用
实现代码:
# -*- coding: utf-8 -*-
”’
油气藏的储量密度Y与生油门限以下平均地温梯度X1、
生油门限以下总有机碳百分比X2、生油岩体积与沉积岩体积百分比X3、砂泥岩厚度百分比X4、
有机转化率X5有关,数据文件为“1.xlsx”,字段如下:
样本ID X1 X2 X3 X4 X5 Y
(注:数据取自教材《Matlab数据分析方法》)
任务如下:
(1)利用线性回归分析命令,求出Y与5个因素之间的线性回归关系式系数向量c_x和常数项c_b
(2)求出线性回归关系的判定系数Slr
(3)今有一个样本X1=4,X2=1.5,X3=10,X4=17,X5=9,试预测该样本的Y值。
”’
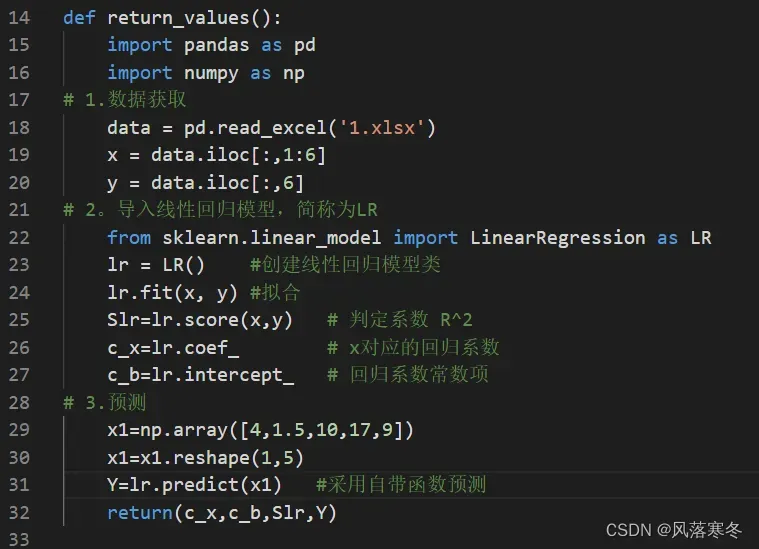
def return_values():
import pandas as pd
import numpy as np
# 1.数据获取
data = pd.read_excel(‘1.xlsx’)
x = data.iloc[:,1:6]
y = data.iloc[:,6]
# 2。导入线性回归模型,简称为LR
from sklearn.linear_model import LinearRegression as LR
lr = LR() #创建线性回归模型类
lr.fit(x, y) #拟合
Slr=lr.score(x,y) # 判定系数 R^2
c_x=lr.coef_ # x对应的回归系数
c_b=lr.intercept_ # 回归系数常数项
# 3.预测
x1=np.array([4,1.5,10,17,9])
x1=x1.reshape(1,5)
Y=lr.predict(x1) #采用自带函数预测
return(c_x,c_b,Slr,Y)

第2关:分类模型及应用
实现代码:
# -*- coding: utf-8 -*-
”’
企业到金融商业机构贷款,金融商业机构需要对企业进行评估。评估结果为0和1两种形式,
0表示企业两年后破产,将拒绝贷款;而1表示企业2年后具备还款能力,可以贷款。
表”2.xlsx”,字段如下:企业编号、X1、X2、X3、Y,
(数据取自《Matlab在数学建模中的应用(第2版)》,卓金武,37页)
已知前20家企业的三项评价指标值和评估结果,试建立逻辑回归模型对剩余5家企业进行评估。
返回模型准确率rv和模型评估结果R
”’
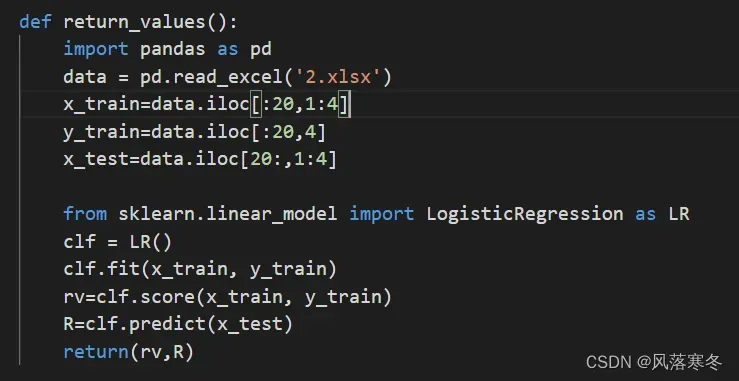
def return_values():
import pandas as pd
data = pd.read_excel(‘2.xlsx’)
x_train=data.iloc[:20,1:4]
y_train=data.iloc[:20,4]
x_test=data.iloc[20:,1:4]
from sklearn.linear_model import LogisticRegression as LR
clf = LR()
clf.fit(x_train, y_train)
rv=clf.score(x_train, y_train)
R=clf.predict(x_test)
return(rv,R)

第3关:主成分分析、K-均值聚类应用
实现代码:
# -*- coding: utf-8 -*-
”’
我国各地区普通高等教育发展状况数据”3.xlsx”:首列为“地区”,其他列依次为:
x1-为每百万人口高等院校数
x2-为每十万人口高等院校毕业生数
x3-为每十万人口高等院校招生数
x4-为每十万人口高等院校在校生数
x5-为每十万人口高等院校教职工数
x6-为每十万人口高等院校专职教师数
x7-为高级职称占专职教师比例
x8-为平均每所高等院校的在校生数
x9-为国家财政预算内普通高教经费占国内生产总值比重
x10-为生均教育经费。
(注:数据取自教材《数学建模算法与应用(第2版)》司守奎)
任务如下:
1.对以上指标数据做主成分分析,并提取主成分(累计贡献率达到90%以上即可)。
2.基于提取的主成分,对以上30个地区做K-均值聚类分析(K=4)。
3.返回聚类结果,用一个序列Fs来表示,其中index为地区名称,值为类别标签
注意类别标签值按升序排列。
”’
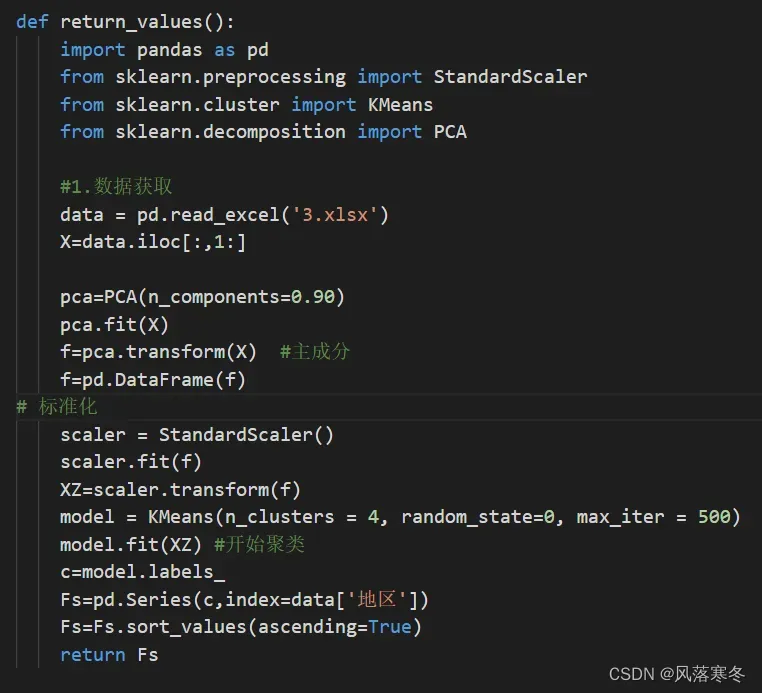
def return_values():
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
#1.数据获取
data = pd.read_excel(‘3.xlsx’)
X=data.iloc[:,1:]
pca=PCA(n_components=0.90)
pca.fit(X)
f=pca.transform(X) #主成分
f=pd.DataFrame(f)
# 标准化
scaler = StandardScaler()
scaler.fit(f)
XZ=scaler.transform(f)
model = KMeans(n_clusters = 4, random_state=0, max_iter = 500)
model.fit(XZ) #开始聚类
c=model.labels_
Fs=pd.Series(c,index=data[‘地区’])
Fs=Fs.sort_values(ascending=True)
return Fs

第4关:多因变量神经网络回归应用
实现代码:
# -*- coding: utf-8 -*-
”’
公路运量主要包括公路客运量和公路货运量两个方面。
根据研究,某地区的公路运量主要与该地区的人数、机动车数量和公路面积有关,
表”4.xlsx”给出了某个地区20年的公路运量相关数据,字段如下:
年份、人数(万人)、机动车数量(万辆)、公路面积(万平方千米)、
公里客运量(万人)、公里货运量(万吨)
根据相关部门数据,该地区2010年和2011年的人数分别为73.39万和75.55万,
机动车数量分别为3.9635万辆和4.0975万辆,公路面积分别为0.9880万平方千米和1.0268万平方千米。
请利用BP神经网络预测该地区2010年和2011年的公路客运量和公路货运量,记为y1(2*2的数组)
”’
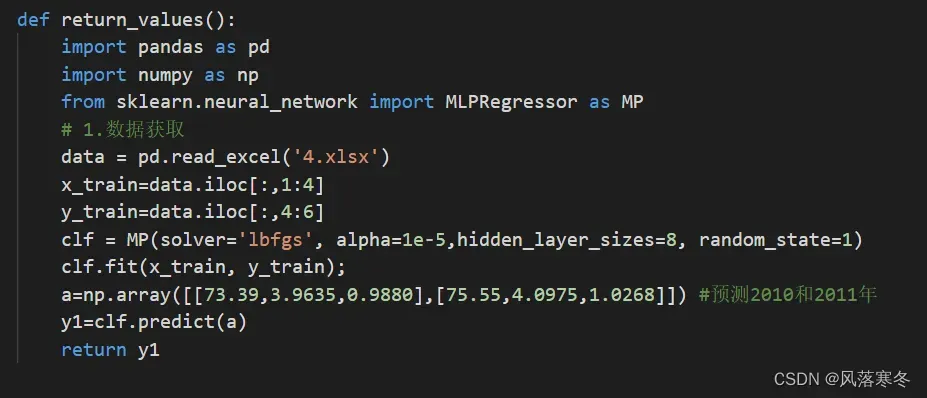
def return_values():
import pandas as pd
import numpy as np
from sklearn.neural_network import MLPRegressor as MP
# 1.数据获取
data = pd.read_excel(‘4.xlsx’)
x_train=data.iloc[:,1:4]
y_train=data.iloc[:,4:6]
clf = MP(solver=’lbfgs’, alpha=1e-5,hidden_layer_sizes=8, random_state=1)
clf.fit(x_train, y_train);
a=np.array([[73.39,3.9635,0.9880],[75.55,4.0975,1.0268]]) #预测2010和2011年
y1=clf.predict(a)
return y1

第5关:布尔数据集构建、关联规则挖掘应用
实现代码:
# -*- coding: utf-8 -*-
”’
假设有数据集”5.xlsx”,每行代表一个顾客在超市的购买记录,内容如下:
I1、西红柿、排骨、鸡蛋、毛巾、水果刀、苹果
I2、西红柿、茄子、水果刀、香蕉
I3、鸡蛋、袜子、毛巾、肥皂、苹果、水果刀
I4、西红柿、排骨、茄子、毛巾、水果刀
I5、西红柿、排骨、酸奶、苹果
I6、鸡蛋、茄子、酸奶、肥皂、苹果、香蕉
I7、排骨、鸡蛋、茄子、水果刀、苹果
I8、土豆、鸡蛋、袜子、香蕉、苹果、水果刀
I9、西红柿、排骨、鞋子、土豆、香蕉、苹果
(注意:表格的每行内容如上所述,无表头,列数不相同)
任务如下:
1.将数据集转换为布尔数据集
2.利用关联规则支持度和置信度定义挖掘出任意两个商品之间的关联规则。
3.要求支持度大于0.4,置信度大于0.7
4.返回结果用一个数据框R来表示,字段为:rule、support、confidence
其中规则为“商品名称–商品名称”命名
”’
def return_values():
##生成布尔值数据表Data
tiem=[‘西红柿’,’排骨’,’鸡蛋’,’毛巾’,’水果刀’,’苹果’,’茄子’,’香蕉’,’袜子’,’肥皂’,’酸奶’,’土豆’,’鞋子’]
import pandas as pd
import numpy as np
data=pd.read_excel(‘5.xlsx’,header=None)
data=data.iloc[:,1:]
D=dict()
for t in range(len(tiem)):
z=np.zeros((len(data)))
li=list()
for k in range(len(data.iloc[0,:])):
s=data.iloc[:,k]==tiem[t]
li.extend(list(s[s.values==True].index))
z[li]=1
D.setdefault(tiem[t],z)
Data=pd.DataFrame(D) #布尔值数据表
##(1)小问
#获取字段名称,并转化为列表
c=list(Data.columns)
c0=0.7#最小置信度
s0=0.4#最小支持度
list1=[]#预定义列表list1,用于存放规则
list2=[]#预定义列表list2,用于存放规则的支持度
list3=[]#预定义列表list3,用于存放规则的置信度
for k in range(len(c)):
for q in range(len(c)):
#对第c[k]个项目与第c[q]个项挖掘关联规则
#规则的前件为c[k]
#规则的后件为c[q]
#要求前件和后件不相等
if c[k]!=c[q]:
c1=Data[c[k]]
c2=Data[c[q]]
I1=c1.values==1
I2=c2.values==1
t12=np.zeros((len(c1)))
t1=np.zeros((len(c1)))
t12[I1&I2]=1
t1[I1]=1
sp=sum(t12)/len(c1)#支持度
co=sum(t12)/sum(t1)#置信度
#取置信度大于等于c0的关联规则
if co>=c0 and sp>=s0:
list1.append(c[k]+’–‘+c[q])
list2.append(sp)
list3.append(co)
#定义字典,用于存放关联规则及其置信度、支持度
R={‘rule’:list1,’support’:list2,’confidence’:list3}
#将字典转化为数据框
R=pd.DataFrame(R)
return R



文章出处登录后可见!