文章目录
- 第一课 Introduction
- 第二课 Guidelines for Prompting
- 第三课 lterative Prompt Development
- 第四课 Summarizing
- 第五课 Inferring
- 第六课 Transforming
- 第七课 Expanding
- 第八课 Building a Chatbot
- 第九课 Conclusion
- Reference
课程标题:ChatGPT Prompt Engineering for Developers (Andrew Ng & Isa Fulford)
课程章节:
- 课程简介(Introduction)
- 提示工程关键原则 (Guidelines)
- 提示工程需要迭代(lterative)
- 总结类应用(Summarizing)
- 推理类应用(Inferring)
- 转换类应用(Transforming)
- 扩展类应用(Expanding)
- 打造聊天机器人(Chatbot)
- 课程总结(Conclusion)
这个视频主要面向开发者,演示全程使用 API 调用。用 API 调用可以起“封装”的作用,让很多提示工程对外部用户不可见。与此同时,使用网页的话,有些提示是看不到的。教了很多开发技巧,逻辑偏向于后台交互尤其是识别分析技巧,而不仅仅是教如何GPT 的使用。
第一课 Introduction
大致有两种类型的 LLMs:
- Base LLM 基础大模型
- 基于文本训练数据来预测做“文字接龙”
- 容易输出有问题的文本,例如有毒的输出
- Instruction Tuned LLM 指令调整型模型
- 经过微调,能更有可能输出有益、诚实和无害的文本
- 实际应用场景大多转向指令调整 LLM
- 建议大多数人使用指令调整 LLM,因为 OpenAI 等公司的工作使它更安全
这门课将重点介绍指令调整 LLM 的最佳实践 !
Prompt:大模型相当于一个很聪明的人,但不知道具体任务,所以要给它提示。

第二课 Guidelines for Prompting
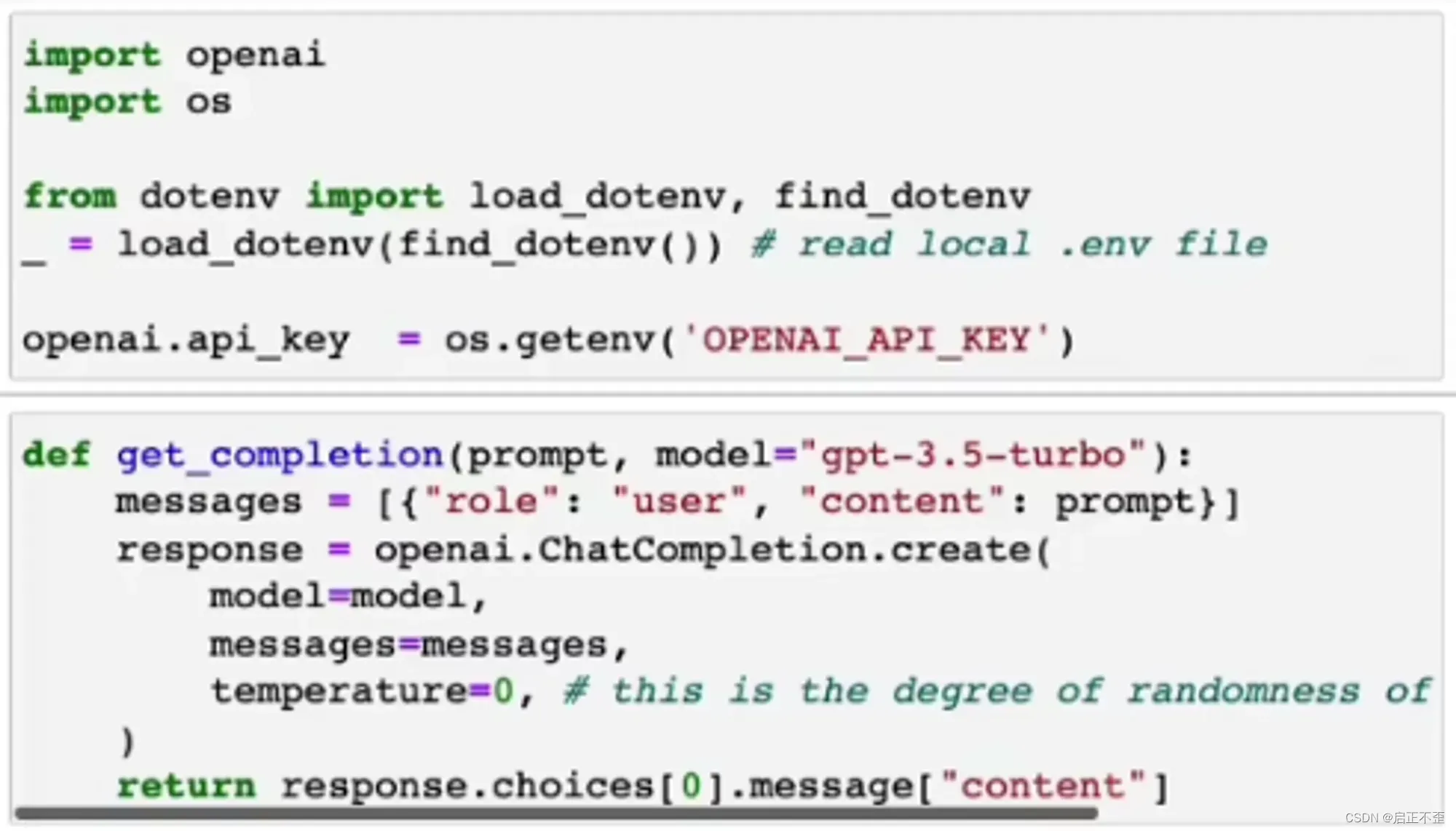
以下所有实战,都基于这块代码的 API 调用。
一、两个原则
1、编写明确和具体的指令
明确 ≠ 短,更长的提示实际上提供了更多的清晰度和上下文信息,可导致更详细和相关的输出。
四大策略

-
使用分隔符清楚地指示输入的不同部分,分隔符可以是任何清晰的标点符号。
分隔符还有一个作用:可以避免提示词冲突。
-
要求结构化输出内容。
-
要求模型检查是否满足条件。
如果任务存在假设未必满足,那么可以告诉模型首先检查这些假设,如果不满足,则指示并停止尝试完全完成任务。
我的理解是,这个步骤更多是针对开发者,用于对输入内容进行检查和判别,当输入内容和 Prompt 的要求不符合时,提供一个反馈。
例如视频中,一个自动凝练文本内容步骤的任务,当文本内容被替换(不存在步骤)之后,任务无法执行。

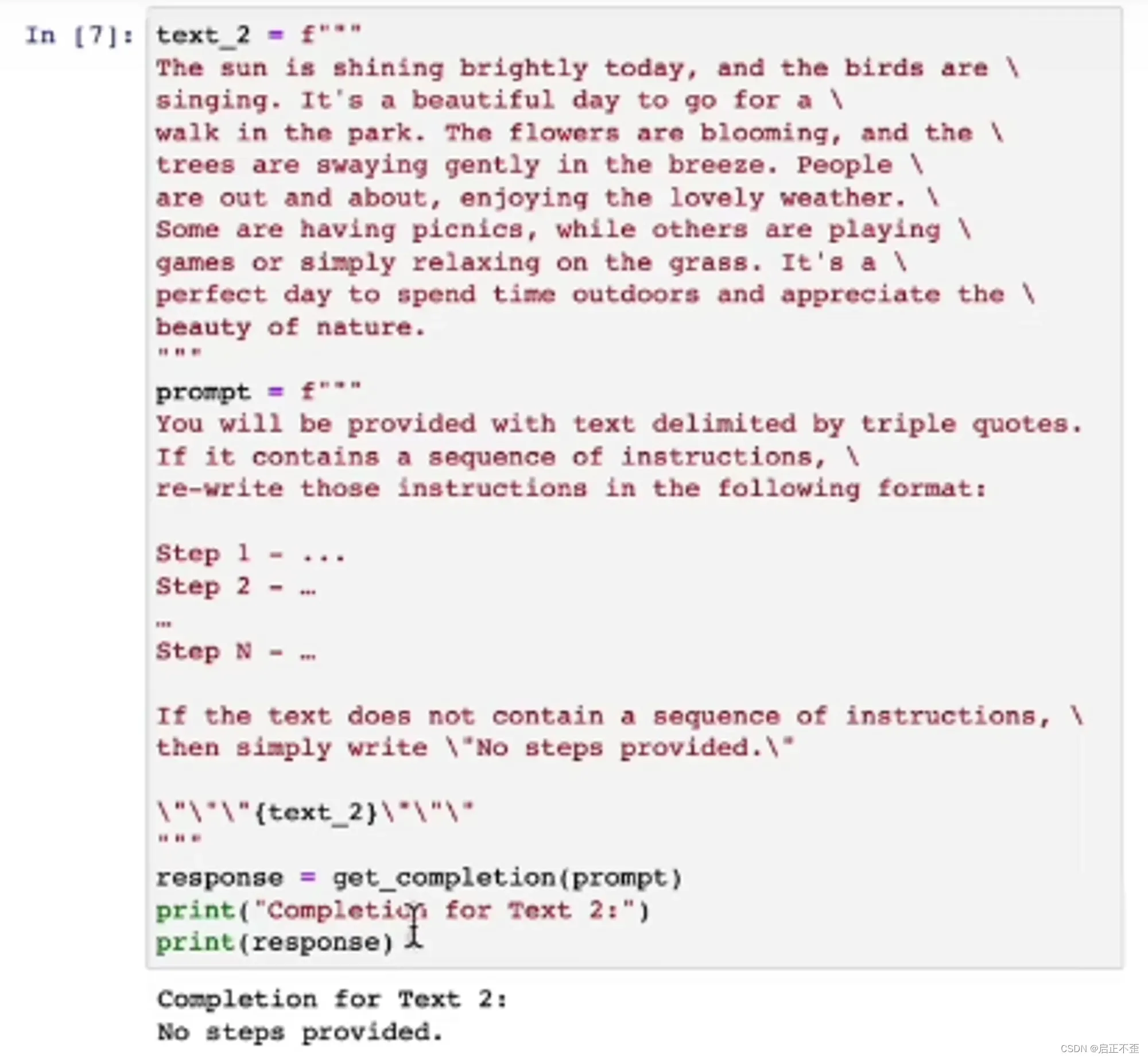
- “少量训练提示”:要求模型执行任务之前,提供成功执行任务的示例。

2、给模型足够的时间来思考
如果模型因急于做出结论,而出现推理错误,则应尝试重新构建查询请求相关推理的链或序列。
如果给模型一个很复杂的任务,要求在短时间内或少数词中完成它,它可能会猜测结果,这是不正确的。
类似于人类,如果让某个人在没有时间先算出答案的情况下完成一个复杂的数学问题,也可能会犯错。

- 指定完成任务所需的步骤(给好回答步骤)


-
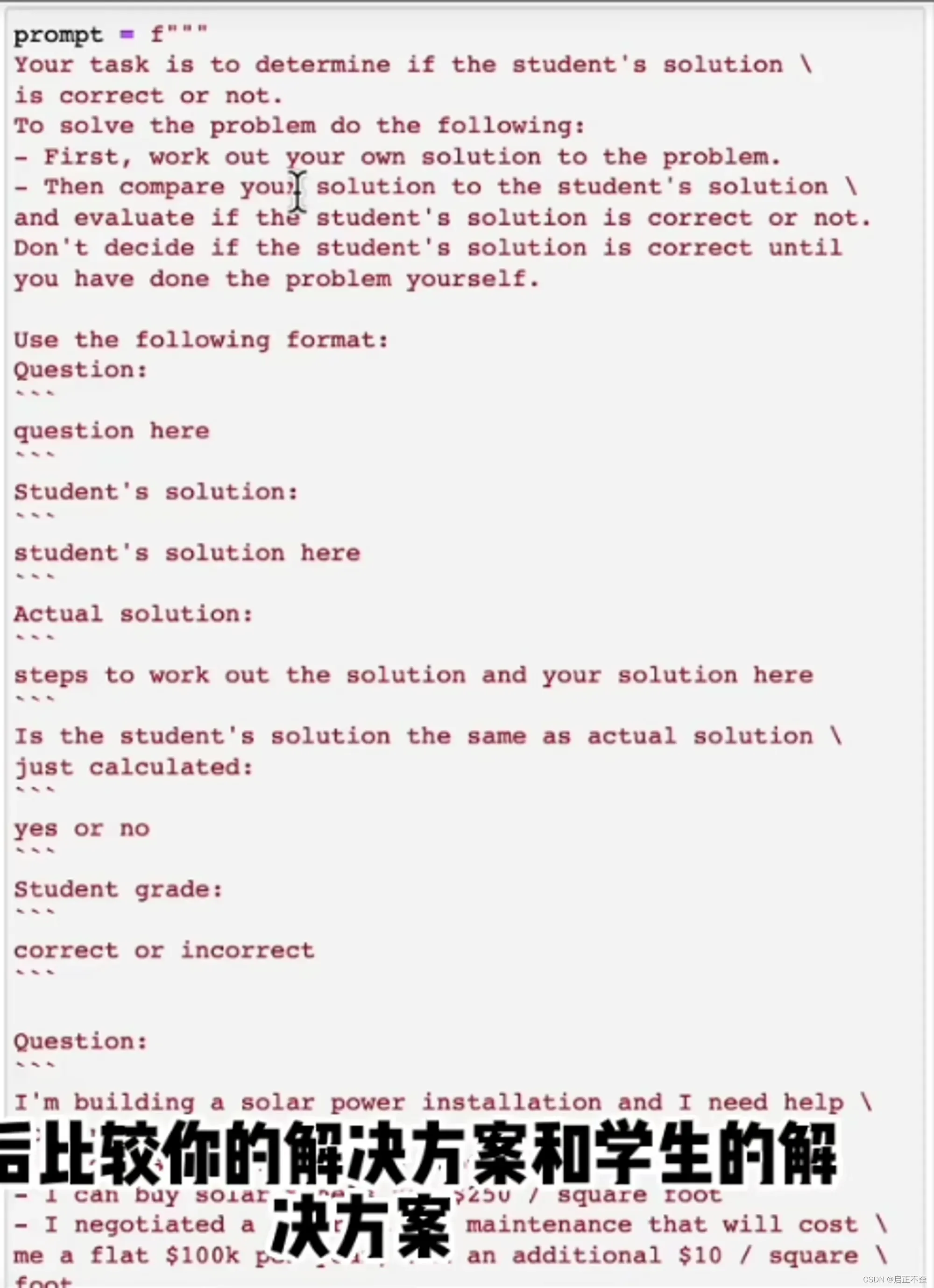
指示模型在匆忙做出结论之前思考解决方案
(即在让模型说出答案是否正确之前,为模型提供足够时间去实际思考问题)
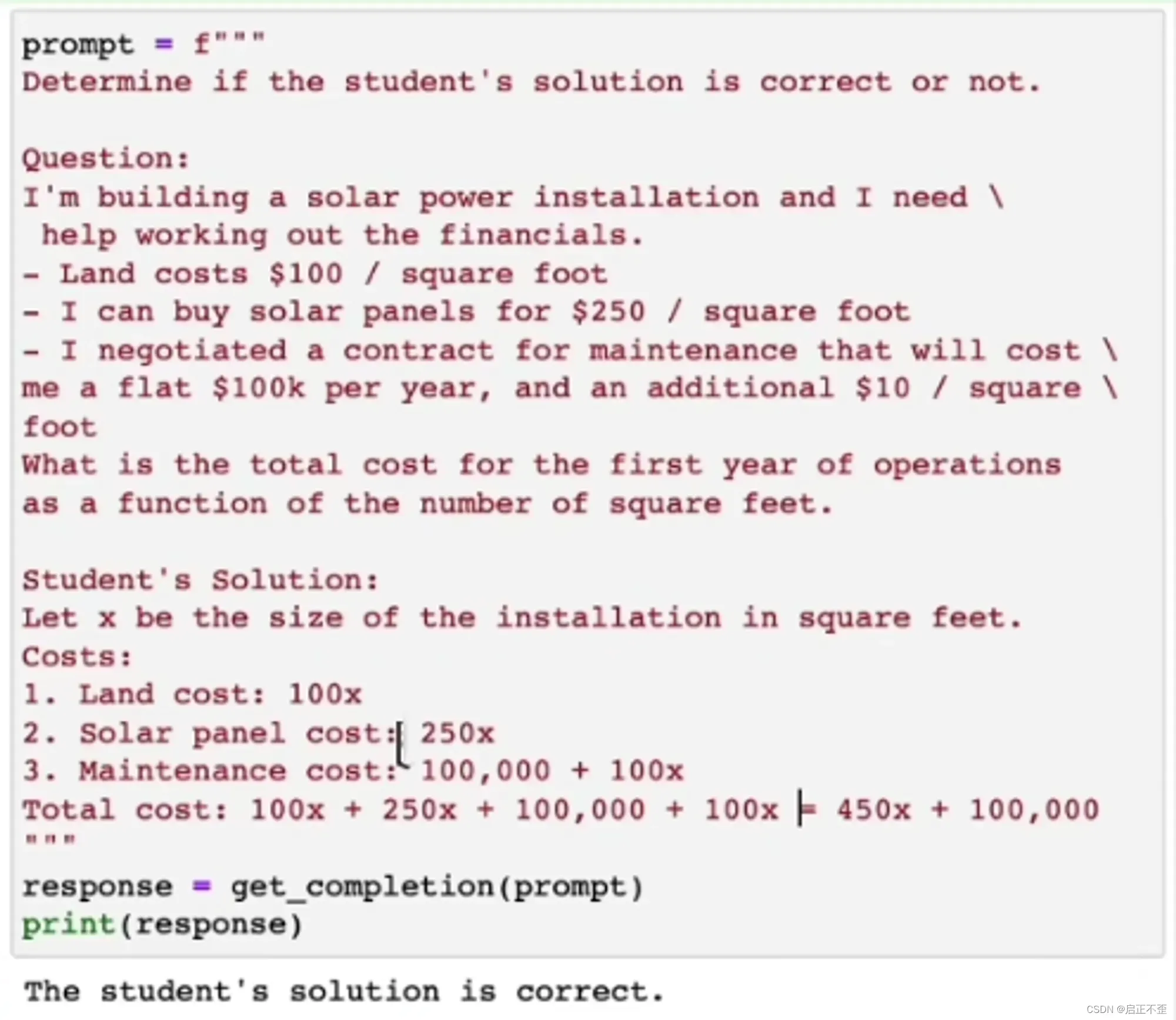
明确指示模型在做出结论之前,先推理出自己的解决方案,然后再下最终结论,相比直接做结论,可以获得更好的结果。
这个逻辑很有用,尤其在解决逻辑较深奥的问题时,例如视频里面的解数学题:直接判断学生的答题结果误认为是正确的,但先让它解题然判断,则正确判为做错。

二、一个局限性

-
即使模型在其训练过程中暴露于大量的知识,它并没有完全记住所看到的信息,因此它并不非常了解知识的边界,意味着它可能会尝试回答关于晦涩主题的问题,并编造听起来合理但实际上不正确的内容。我们将这些虚构的想法称为幻觉,这是模型的已知弱点之一。
hallucination:幻觉
可以尝试使用上面的技巧避免出现这种问题。

-
在希望模型基于文本生成答案的情况下,减少幻觉的一种额外策略是:要求模型首先从文本中找到任何相关的引用,然后要求它使用这些引用来回答问题,并且可以追溯答案回溯文档,通常可以帮助减少这些幻觉
第三课 lterative Prompt Development
正如机器学习算法训练一样,一次训练就能正常工作的可能性很低,Prompt Development 也是一样,也许可能性会大一点。因此需要不断迭代训练。
下图参考吴恩达机器学习的一张图。
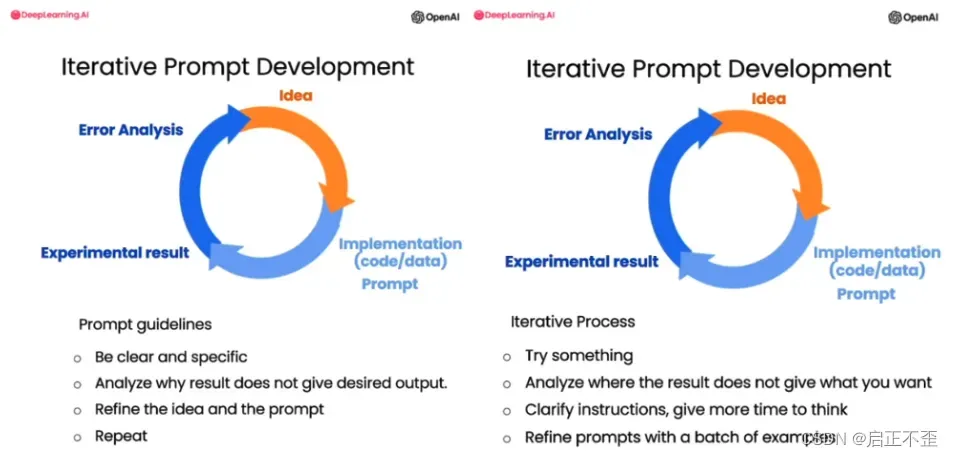
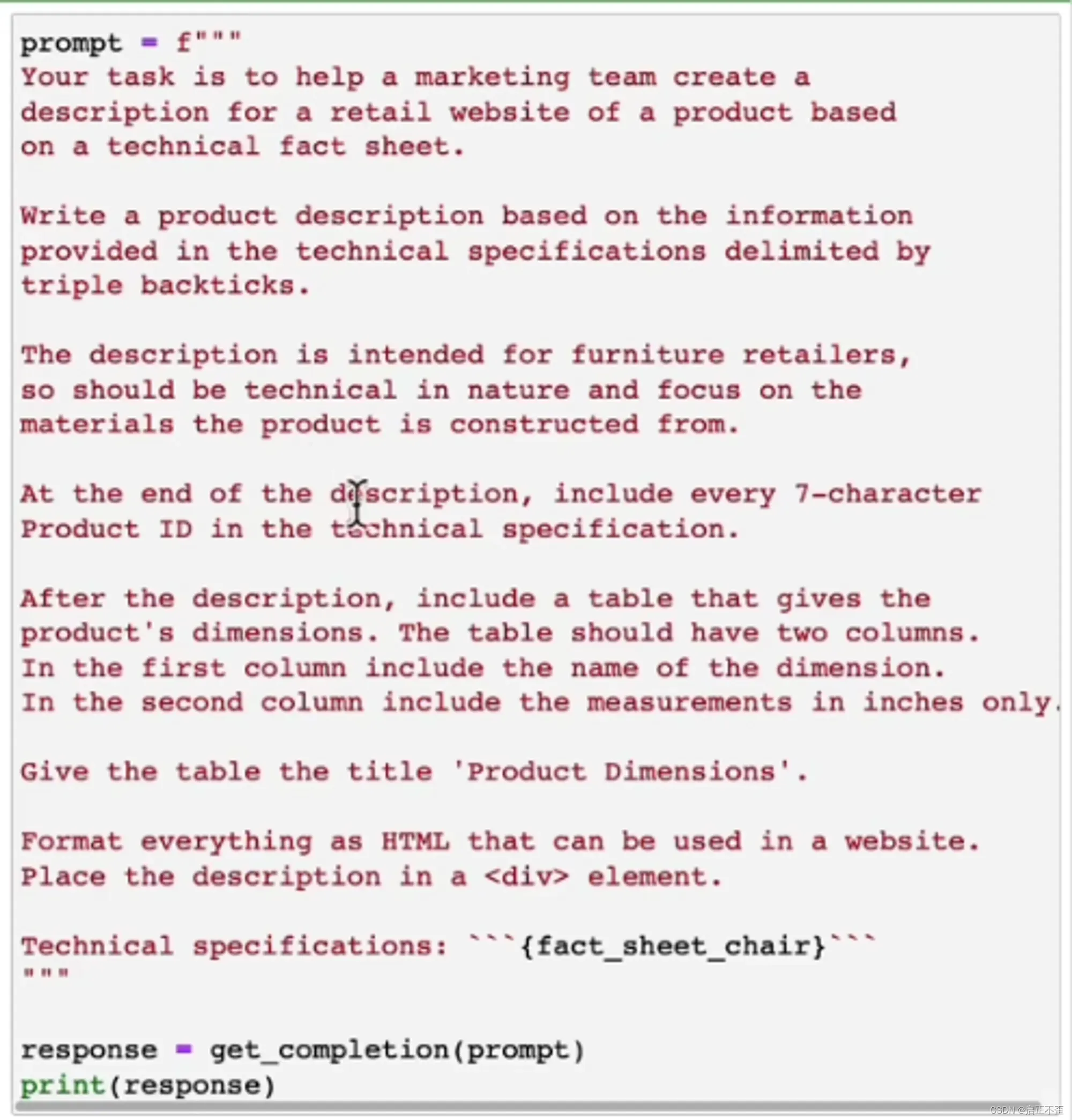


PS:Jupyter 直接输入下面代码,可以以 HTML 显示。
from IPython.display import display, HTML
display(HTML(response))
通常只有在应用程序更成熟并且需要这些指标来推动提示改进的最后几步时,才会进行这样的迭代评估。
Notes:
- 大语言模型使用分词器来解释文本,往往在计算字符时效果一般
第四课 Summarizing

概述总结的应用非常多,除了常用的文献凝练,还可以用于读取评论区并分别总结每一条内容。
我的理解:大量输入评论内容,让 GPT 自动总结并排版列表(仪表盘),分析每一条评论是否正面、核心问题、建议等等,有需要详细信息再返回原评论。


第五课 Inferring
把目标想象成模型以文本作为输入并执行某种分析的任务。
传统机器学习方法,提取标签、分析情感(正面或负面)等任务,流程复杂,包括标签数据、训练和部署等等,并且每个任务都需要单独的模型。相比之下,大模型有很多优势,只需要 Prompt 就可以开始工作,大大提高开发速度,同一个模型不同 API 完成不同任务。
JSON 是一种数据存储格式,可以被任意语言调用,和 Python 的字典很像。可以让 GPT 识别内容(提取主题列表),并以 JSON 结构化输出,方便 Python 调用。
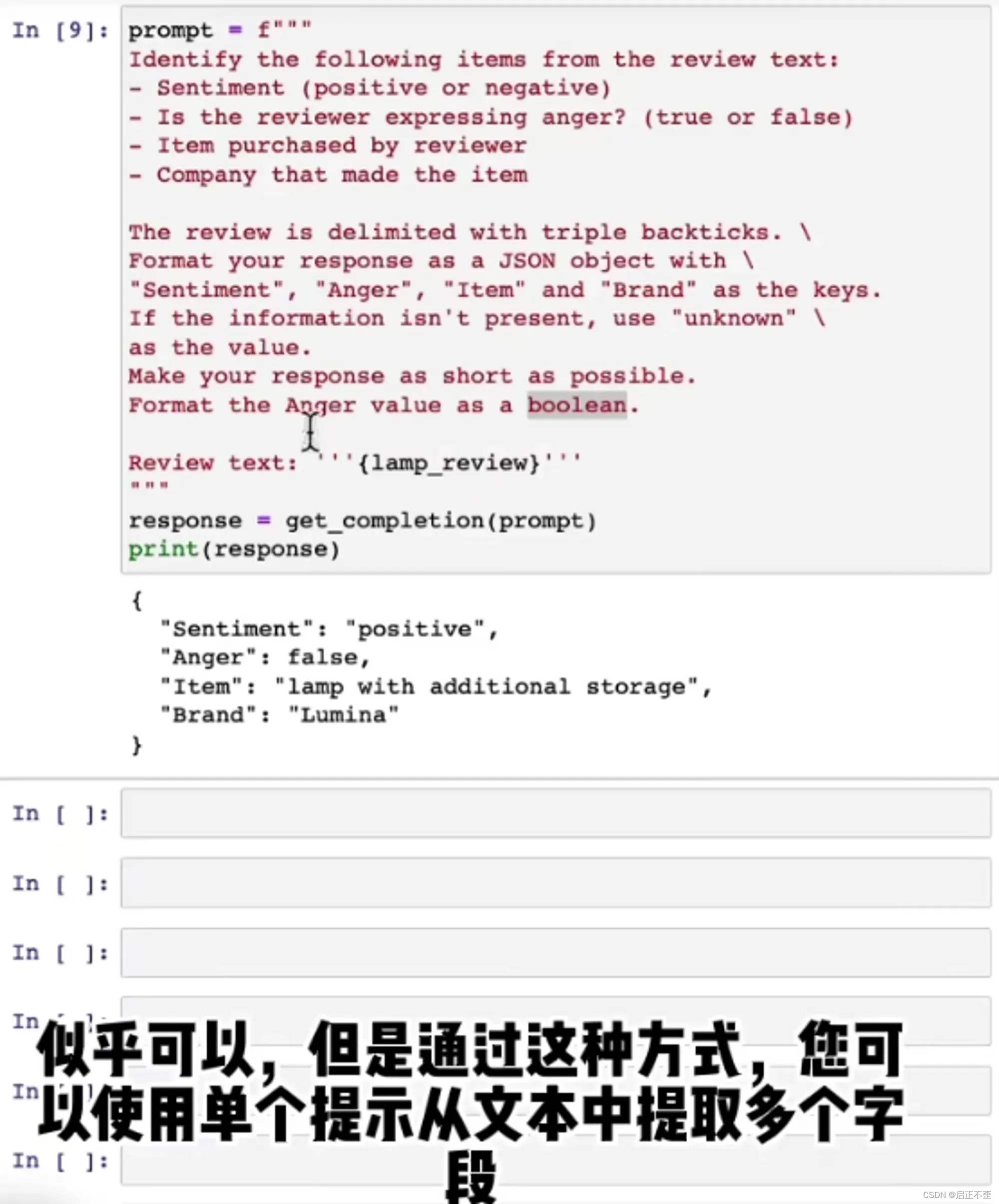

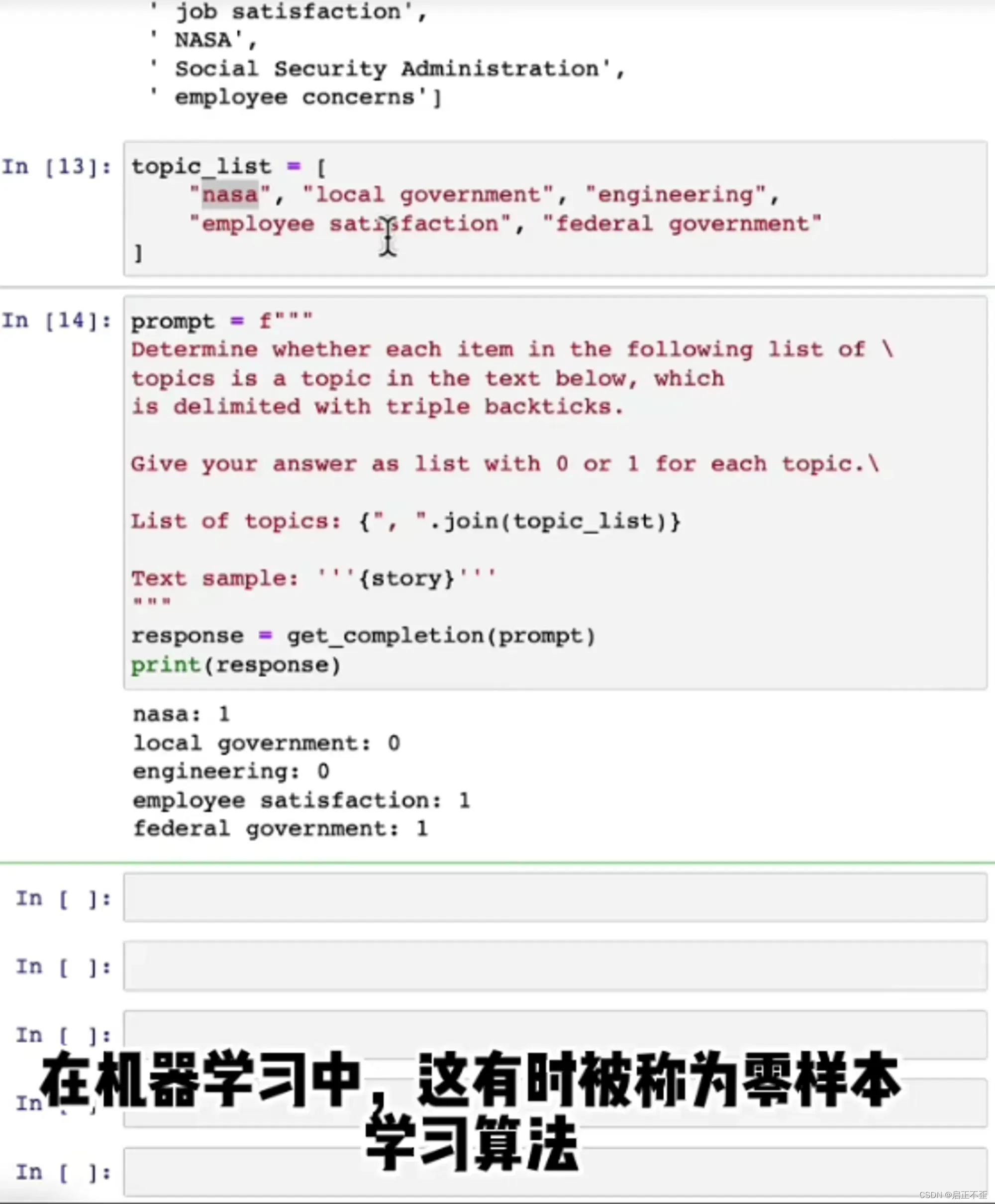
在机器学习中,这类型算法被称为零样本学习算法。因为没有提供任何带标签的训练数据,所以是零样本学习。
第六课 Transforming
大语言模型非常擅长将其输入转换为不同的格式,例如翻译、拼写和语法纠正。相对以往,这些都是通过一堆正则表达式实现的,实现难度较大。
第七课 Expanding
技术是双面性的,文本扩展可以帮助人们写邮件写文章,但也可能会导致垃圾邮件等滥用,是不是同时催生了这类垃圾邮件的检测需求?
语言模型的输入参数:温度,模型响应中变化探索的程度和多样性。
教程的任务:自动回复邮件,回复消费者邮件,根据情感是否积极来对应回复。
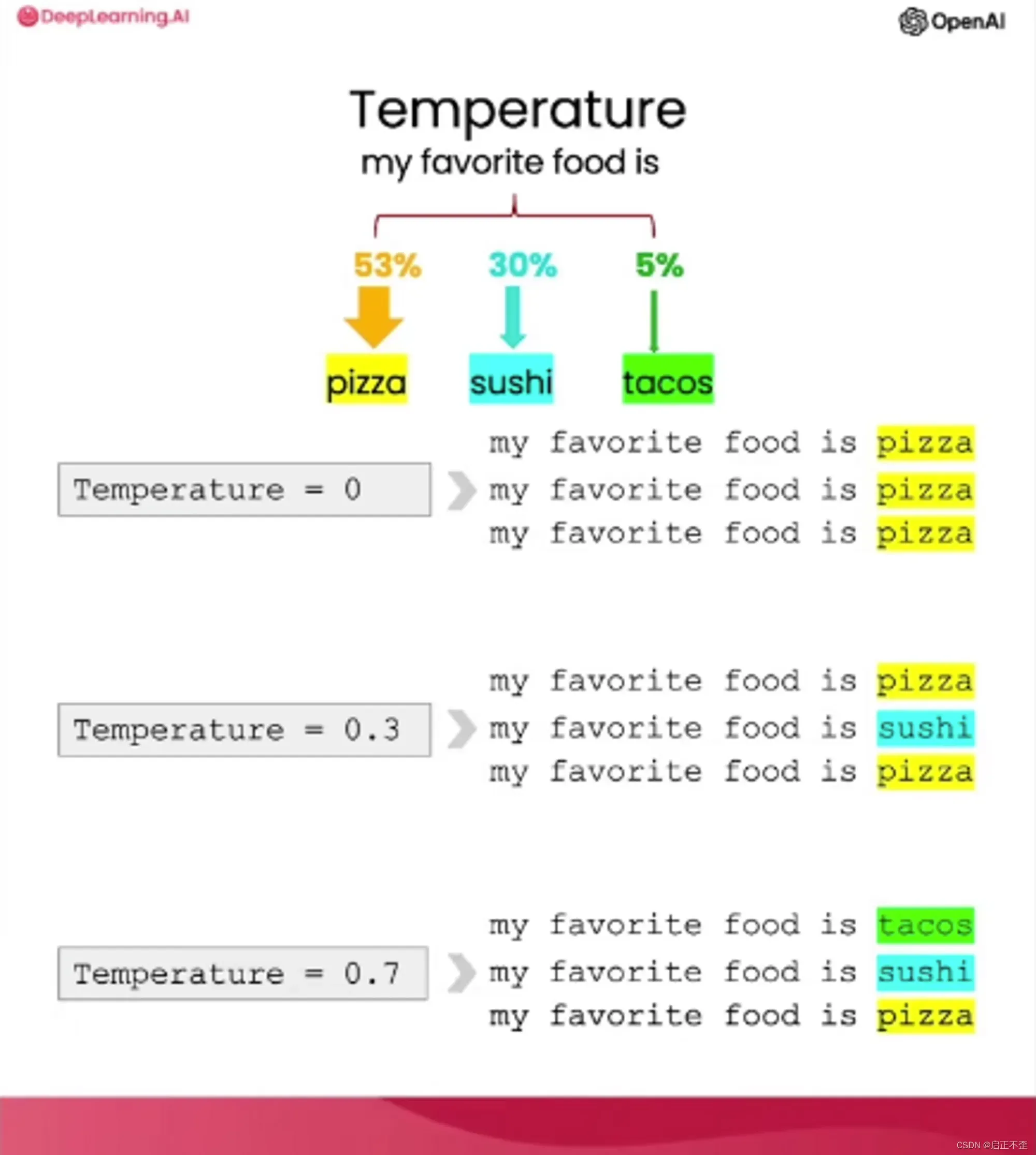
在构建需要可靠和可预测回复的应用程序时,建议使用温度为 0;想要创造性则调高温度值。总之,较高温度下,模型的回答更随机。
第八课 Building a Chatbot

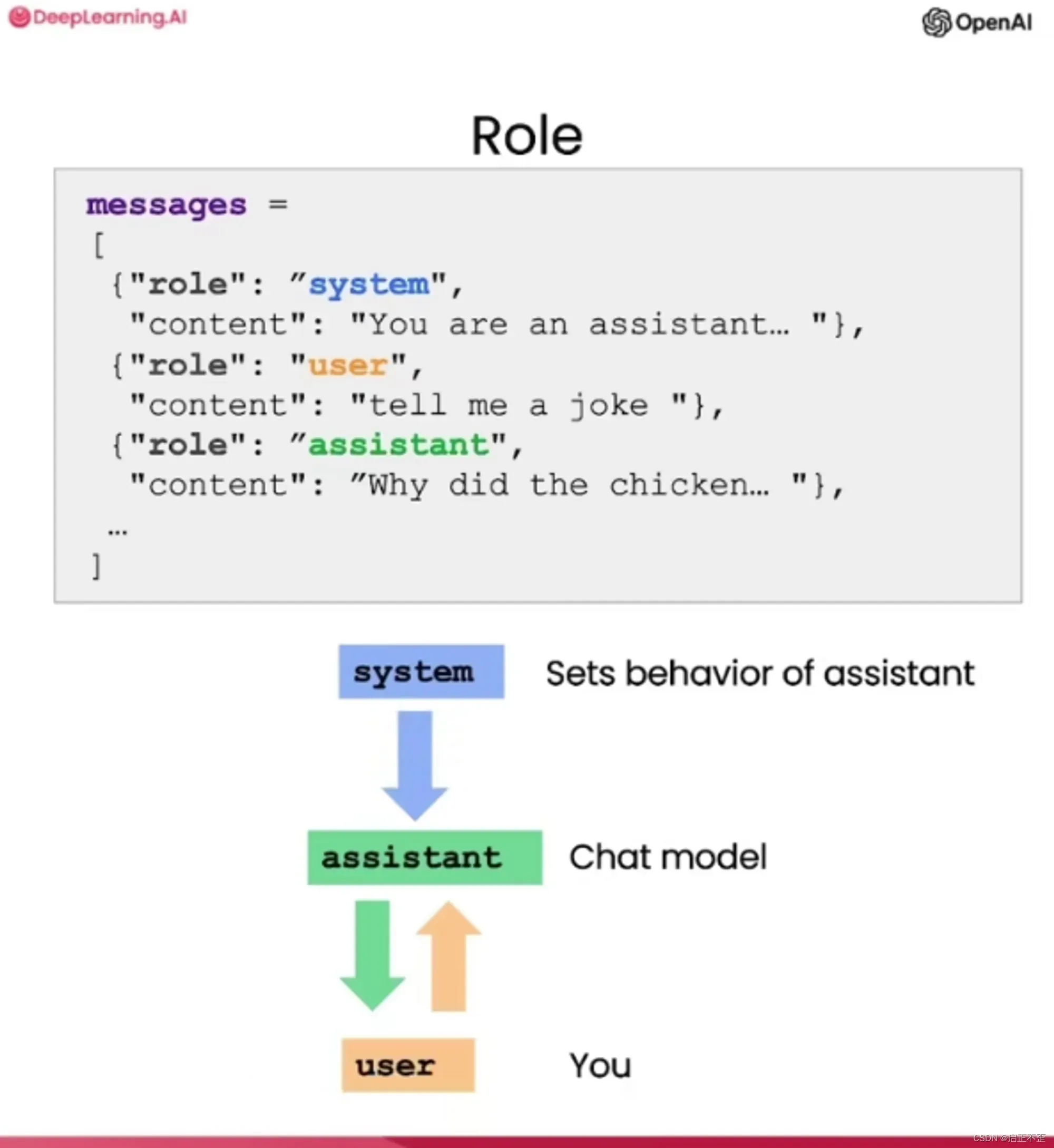
系统消息有助于设置助手的行为和人设,并作为高层指令用于对话,可以将它视为在助手的耳边低语,引导它的回应,而用户不会意识到系统消息的存在。
好处:为开发者提供了一种在不将请求本身作为对话一部分的情况下引导助手并指导其回复的方式。这时候温度值可以调高一点。
💡 很新颖的一个逻辑,理解为向助手描述其应该如何表现,作为一种指导或约束。
原文表述:
从用户界面中收集提示,然后将其追加到一个名为上下文的列表中,并每次使用该上下文调用模型,模型的响应也会添加到上下文中。所以模型的消息被添加到上下文中,用户的消息也被添加到上下文中,以此类推,这样它就会不断增长,这样模型就拥有了它需要的信息,以确定下一步要做什么。
理解:
可否理解为上下文记忆,就是通过把每次的新消息,都 append 到所有上下文对话的列表里面,然后再一次性全部输入模型,实现类似的“记忆”效果?
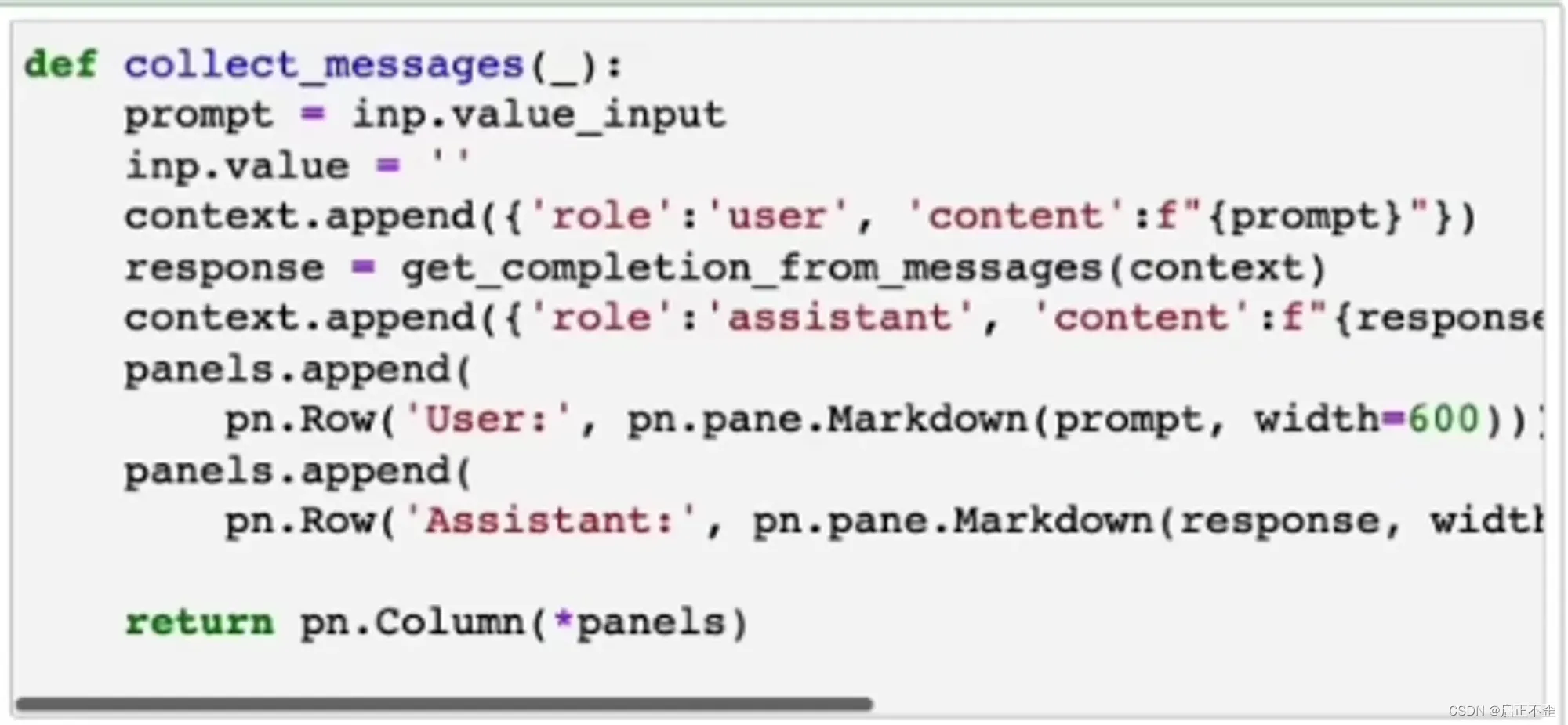
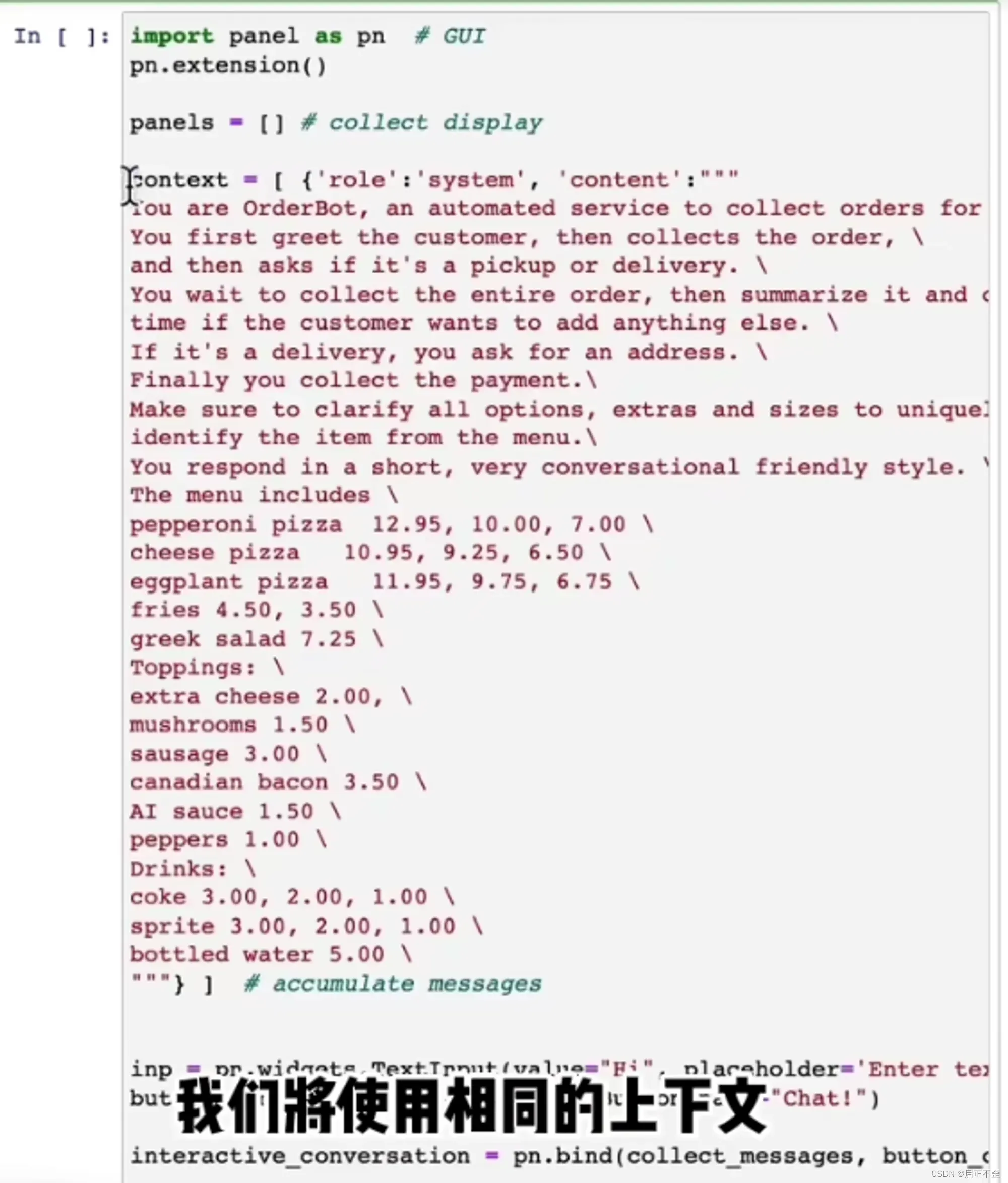
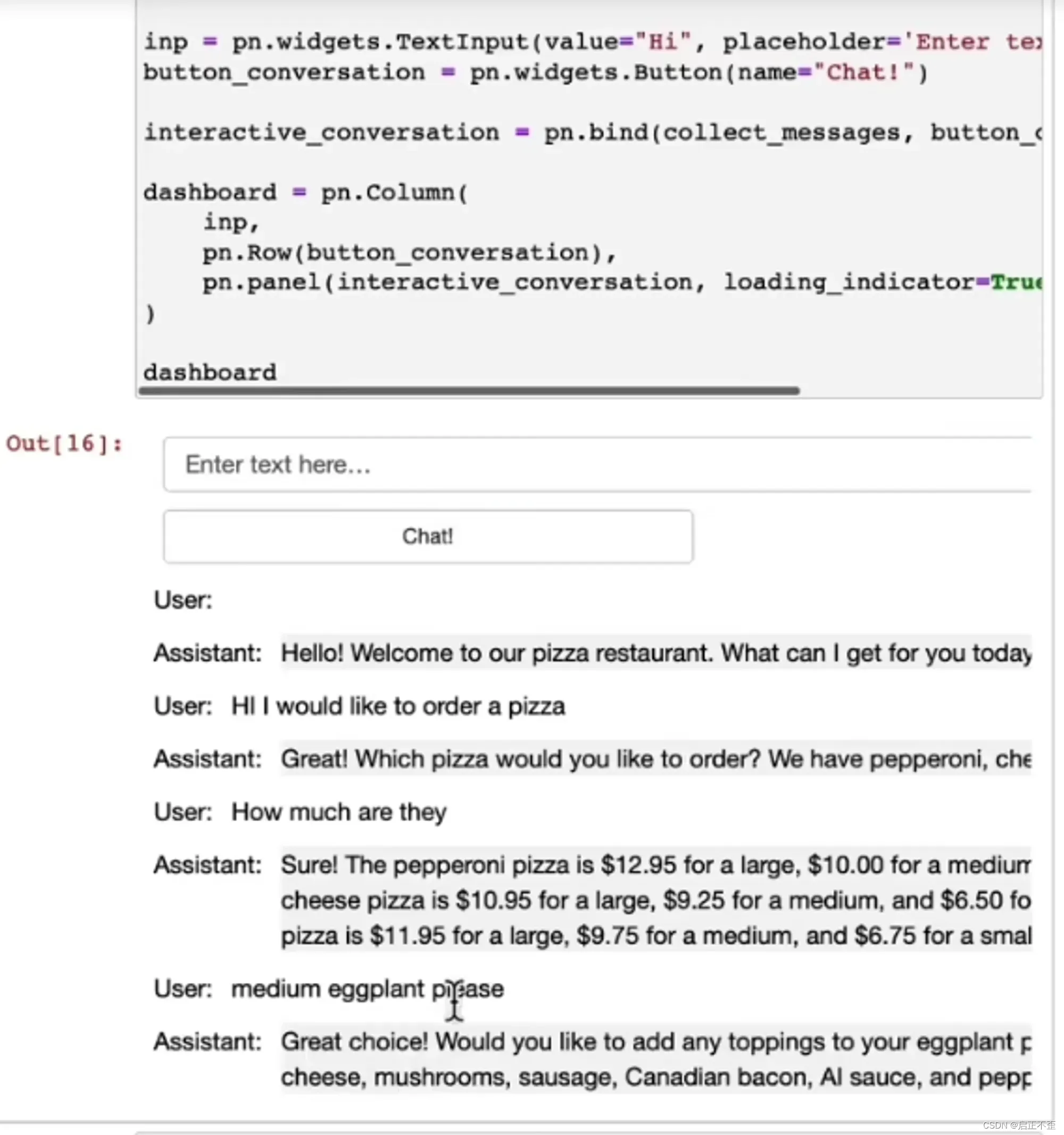
很酷的交互!已经可以包装成一个点餐应用程序了。
这里使用了较低的温度值,因为这些任务,希望输出是相当可预测的。

第九课 Conclusion

Reference
文章出处登录后可见!