一、前言
Encoder-decoder 模型提供了最先进的结果,可以对语言翻译等 NLP 任务进行排序。多步时间序列预测也可以视为 seq2seq 任务,可以使用编码器-解码器模型。 本文提供了一个Encoder-decoder模型来解决 Kaggle 的时间序列预测任务以及获得前 10% 结果所涉及的步骤。
模型实现灵感来自Pytorch seq2seq翻译教程,时间序列预测思路主要来自Kaggle类似比赛的获奖方案。
二、数据
使用的数据集来自过去的Kaggle竞赛——Store Item需求预测挑战,给出过去5年(从2013年到2017年)来自10家不同商店的50件商品的销售数据,预测未来3个月内每件商品的销量( 01/01/2018 至 31/03/2018)。 这是一个多步多站点时间序列预测问题。

提供的特征非常少:
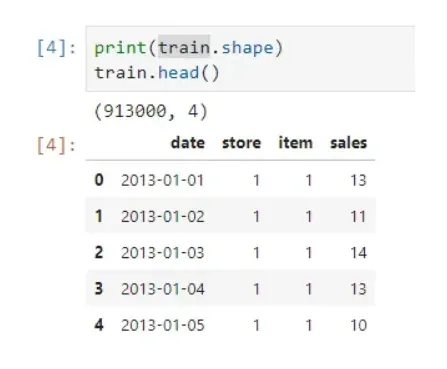
有 500 个独特的商店项目组合,这意味着我们要预测 500 个时间序列。
三、数据预处理
(1)特征工程
深度学习模型擅长自行发现特征,因此可以将特征工程保持在最低限度。
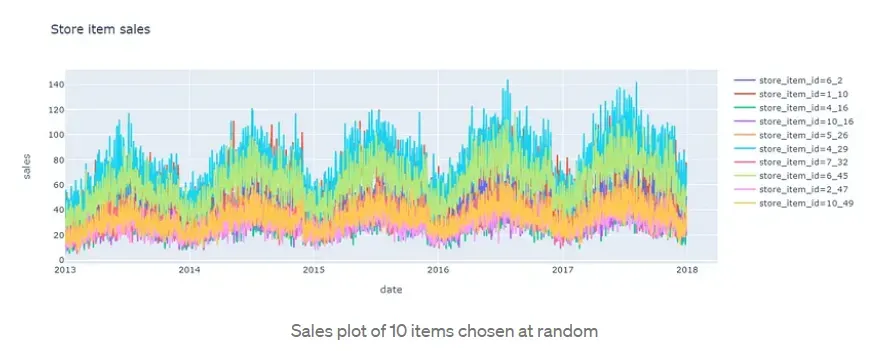
从图中可以看出,我们的数据具有每周和每月的季节性以及每年的趋势,为了捕捉这些,向模型提供了 DateTime 特征。 为了更好地捕捉每件商品的年度销售趋势,还提供了年度自相关。
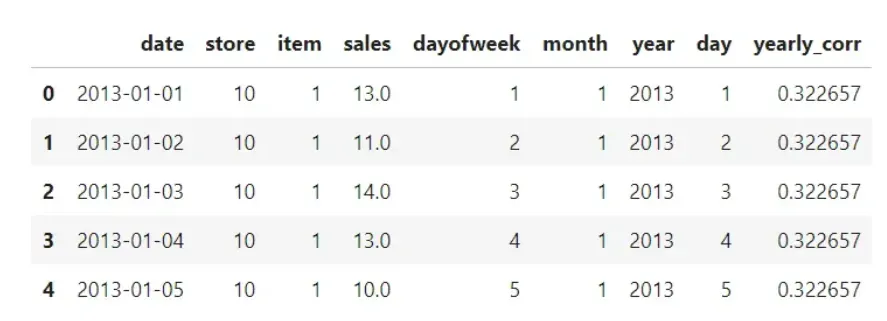
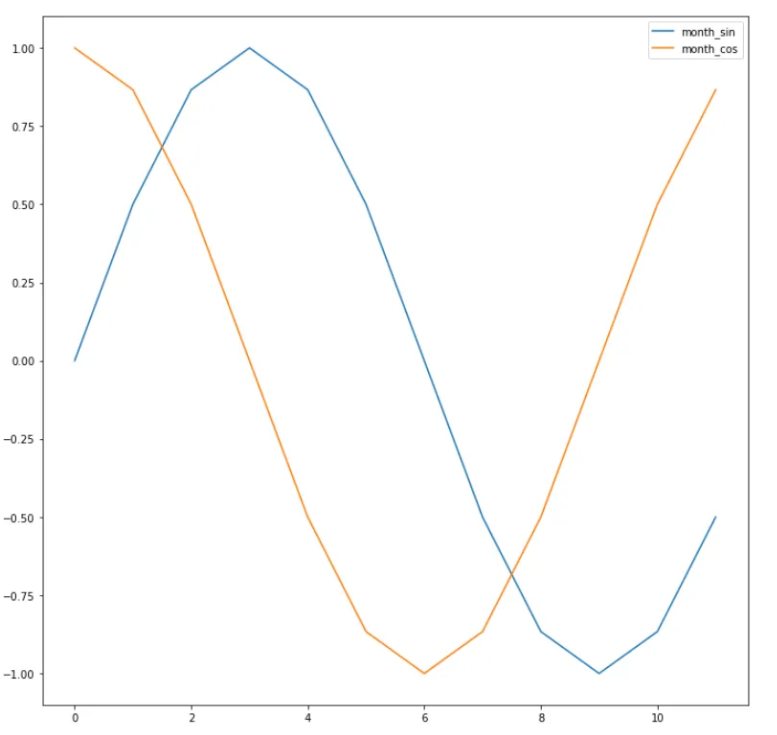
许多这些特征本质上是周期性的,为了向模型提供此信息,对 DateTime 特征应用了正弦和余弦变换。
所以最终的特征集如下所示。
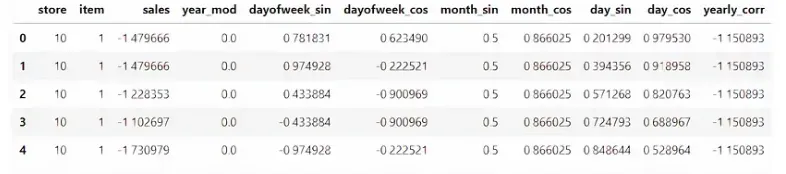
(2)数据缩放
神经网络期望所有特征的值都在同一尺度上,因此数据缩放成为强制性的。 每个时间序列的值都是独立标准化的。 每年的自相关和年份也被归一化。
(3)序列构建
编码器-解码器模型以一个序列作为输入并返回一个序列作为输出,因此我们必须将我们拥有的平面数据帧转换为序列。
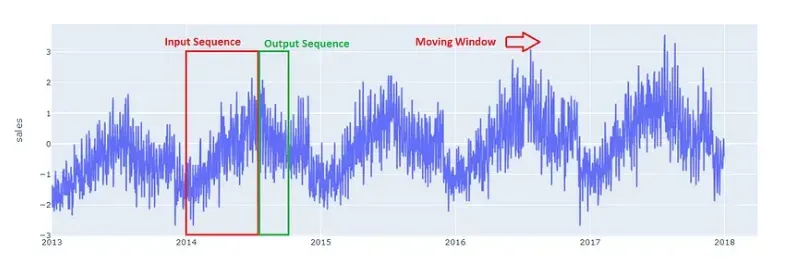
输出序列的长度固定为 90 天,以满足我们的问题要求。 输入序列的长度必须根据问题的复杂性和可用的计算资源来选择。 对于这个问题,选择了 180(6 个月)的输入序列长度。 序列数据是通过对数据集中的每个时间序列应用滑动窗口来构建的。
(4)数据集和数据加载器
Pytorch 提供了方便的抽象——数据集和数据加载器——将数据馈送到模型中。 数据集将序列数据作为输入,并负责构建要提供给模型的每个数据点。 它还负责处理提供给模型的不同类型的特征,这部分将在下面详细解释。
class StoreItemDataset(Dataset):
def __init__(self, cat_columns=[], num_columns=[], embed_vector_size=None, decoder_input=True, ohe_cat_columns=False):
super().__init__()
self.sequence_data = None
self.cat_columns = cat_columns
self.num_columns = num_columns
self.cat_classes = {}
self.cat_embed_shape = []
self.cat_embed_vector_size = embed_vector_size if embed_vector_size is not None else {}
self.pass_decoder_input=decoder_input
self.ohe_cat_columns = ohe_cat_columns
self.cat_columns_to_decoder = False
def get_embedding_shape(self):
return self.cat_embed_shape
def load_sequence_data(self, processed_data):
self.sequence_data = processed_data
def process_cat_columns(self, column_map=None):
column_map = column_map if column_map is not None else {}
for col in self.cat_columns:
self.sequence_data[col] = self.sequence_data[col].astype('category')
if col in column_map:
self.sequence_data[col] = self.sequence_data[col].cat.set_categories(column_map[col]).fillna('#NA#')
else:
self.sequence_data[col].cat.add_categories('#NA#', inplace=True)
self.cat_embed_shape.append((len(self.sequence_data[col].cat.categories), self.cat_embed_vector_size.get(col, 50)))
def __len__(self):
return len(self.sequence_data)
def __getitem__(self, idx):
row = self.sequence_data.iloc[[idx]]
x_inputs = [torch.tensor(row['x_sequence'].values[0], dtype=torch.float32)]
y = torch.tensor(row['y_sequence'].values[0], dtype=torch.float32)
if self.pass_decoder_input:
decoder_input = torch.tensor(row['y_sequence'].values[0][:, 1:], dtype=torch.float32)
if len(self.num_columns) > 0:
for col in self.num_columns:
num_tensor = torch.tensor([row[col].values[0]], dtype=torch.float32)
x_inputs[0] = torch.cat((x_inputs[0], num_tensor.repeat(x_inputs[0].size(0)).unsqueeze(1)), axis=1)
decoder_input = torch.cat((decoder_input, num_tensor.repeat(decoder_input.size(0)).unsqueeze(1)), axis=1)
if len(self.cat_columns) > 0:
if self.ohe_cat_columns:
for ci, (num_classes, _) in enumerate(self.cat_embed_shape):
col_tensor = torch.zeros(num_classes, dtype=torch.float32)
col_tensor[row[self.cat_columns[ci]].cat.codes.values[0]] = 1.0
col_tensor_x = col_tensor.repeat(x_inputs[0].size(0), 1)
x_inputs[0] = torch.cat((x_inputs[0], col_tensor_x), axis=1)
if self.pass_decoder_input and self.cat_columns_to_decoder:
col_tensor_y = col_tensor.repeat(decoder_input.size(0), 1)
decoder_input = torch.cat((decoder_input, col_tensor_y), axis=1)
else:
cat_tensor = torch.tensor(
[row[col].cat.codes.values[0] for col in self.cat_columns],
dtype=torch.long
)
x_inputs.append(cat_tensor)
if self.pass_decoder_input:
x_inputs.append(decoder_input)
y = torch.tensor(row['y_sequence'].values[0][:, 0], dtype=torch.float32)
if len(x_inputs) > 1:
return tuple(x_inputs), y
return x_inputs[0], y来自数据集的数据点被一起批处理并使用数据加载器提供给模型。
四、模型结构
编码器-解码器模型是循环神经网络 (RNN) 的一种形式,用于解决序列到序列问题。 encoder-decoder模型可以直观理解如下。
编码器-解码器模型由两个网络组成——编码器和解码器。 编码器网络学习(编码)捕获其特征或上下文的输入序列的表示,并给出一个向量。 该向量称为上下文向量。 解码器网络接收上下文向量并学习从中读取和提取(解码)输出序列。
在编码器和解码器中,编码和解码序列的任务都是由一系列循环单元处理的。 解决方案中使用的循环单元是门控循环单元 (GRU),以解决短记忆问题。 有关这方面的更多信息,请参阅 LSTM 和 GRU 的插图指南。
解决方案中使用的模型的详细架构如下所示。
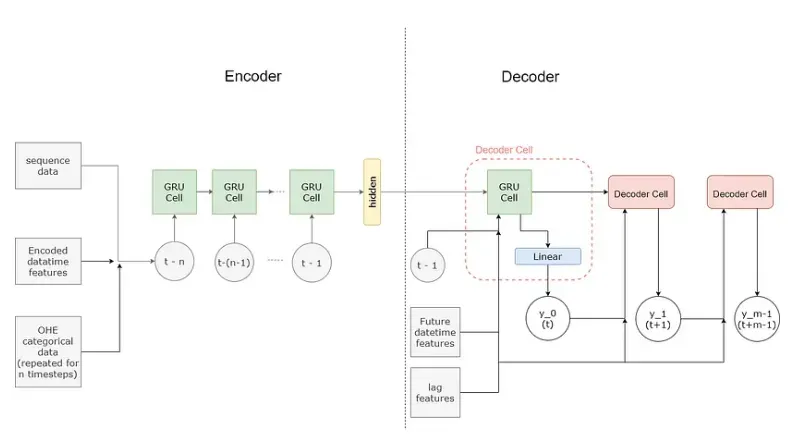
(1)编码器
编码器网络的输入是形状(序列长度,n_values),因此序列中的每个项目都由 n 个值组成。 在构造这些值时,不同类型的特征被区别对待。
时间相关特征——这些是随时间变化的特征,例如销售额和日期时间特征。 在编码器中,每个顺序时间相关值都被馈送到一个 RNN 单元中。
数值特征——不随时间变化的静态特征,例如序列的年度自相关。 这些特征在整个序列长度上重复出现,并被输入到 RNN 中。 重复和合并值的过程在数据集中处理。
分类特征——商店 id 和商品 id 等特征可以通过多种方式处理,每种方法的实现都可以在 encoders.py 中找到。 对于最终模型,分类变量被单热编码,在整个序列中重复,并被送入 RNN,这也在数据集中处理。
具有这些特征的输入序列被送入循环网络——GRU。 下面给出了使用的编码器网络的代码。
class RNNEncoder(nn.Module):
def __init__(self, rnn_num_layers=1, input_feature_len=1, sequence_len=168, hidden_size=100, bidirectional=False, device='cpu', rnn_dropout=0.2):
super().__init__()
self.sequence_len = sequence_len
self.hidden_size = hidden_size
self.input_feature_len = input_feature_len
self.num_layers = rnn_num_layers
self.rnn_directions = 2 if bidirectional else 1
self.gru = nn.GRU(
num_layers=rnn_num_layers,
input_size=input_feature_len,
hidden_size=hidden_size,
batch_first=True,
bidirectional=bidirectional,
dropout=rnn_dropout
)
self.device = device
def forward(self, input_seq):
ht = torch.zeros(self.num_layers * self.rnn_directions, input_seq.size(0), self.hidden_size, device=self.device)
if input_seq.ndim < 3:
input_seq.unsqueeze_(2)
gru_out, hidden = self.gru(input_seq, ht)
print(gru_out.shape)
print(hidden.shape)
if self.rnn_directions * self.num_layers > 1:
num_layers = self.rnn_directions * self.num_layers
if self.rnn_directions > 1:
gru_out = gru_out.view(input_seq.size(0), self.sequence_len, self.rnn_directions, self.hidden_size)
gru_out = torch.sum(gru_out, axis=2)
hidden = hidden.view(self.num_layers, self.rnn_directions, input_seq.size(0), self.hidden_size)
if self.num_layers > 0:
hidden = hidden[-1]
else:
hidden = hidden.squeeze(0)
hidden = hidden.sum(axis=0)
else:
hidden.squeeze_(0)
return gru_out, hidden(2)解码器
解码器从编码器接收上下文向量,此外,解码器的输入是未来的日期时间特征和滞后特征。 模型中使用的滞后特征是前一年的值。 使用滞后特征背后的直觉是,鉴于输入序列被限制为 180 天,提供超过此时间范围的重要数据点将有助于模型。
与直接使用递归网络 (GRU) 的编码器不同,解码器是通过解码器单元循环构建的。 这是因为从每个解码器单元获得的预测作为输入传递给下一个解码器单元。 每个解码器单元由一个 GRUCell 组成,其输出被馈送到提供预测的全连接层。 来自每个解码器单元的预测被组合以形成输出序列。
class DecoderCell(nn.Module):
def __init__(self, input_feature_len, hidden_size, dropout=0.2):
super().__init__()
self.decoder_rnn_cell = nn.GRUCell(
input_size=input_feature_len,
hidden_size=hidden_size,
)
self.out = nn.Linear(hidden_size, 1)
self.attention = False
self.dropout = nn.Dropout(dropout)
def forward(self, prev_hidden, y):
rnn_hidden = self.decoder_rnn_cell(y, prev_hidden)
output = self.out(rnn_hidden)
return output, self.dropout(rnn_hidden)(3)Encoder-Decoder模型
编码器-解码器模型是通过将编码器和解码器单元包装到一个模块中来构建的,该模块处理两者之间的通信。
class EncoderDecoderWrapper(nn.Module):
def __init__(self, encoder, decoder_cell, output_size=3, teacher_forcing=0.3, sequence_len=336, decoder_input=True, device='cpu'):
super().__init__()
self.encoder = encoder
self.decoder_cell = decoder_cell
self.output_size = output_size
self.teacher_forcing = teacher_forcing
self.sequence_length = sequence_len
self.decoder_input = decoder_input
self.device = device
def forward(self, xb, yb=None):
if self.decoder_input:
decoder_input = xb[-1]
input_seq = xb[0]
if len(xb) > 2:
encoder_output, encoder_hidden = self.encoder(input_seq, *xb[1:-1])
else:
encoder_output, encoder_hidden = self.encoder(input_seq)
else:
if type(xb) is list and len(xb) > 1:
input_seq = xb[0]
encoder_output, encoder_hidden = self.encoder(*xb)
else:
input_seq = xb
encoder_output, encoder_hidden = self.encoder(input_seq)
prev_hidden = encoder_hidden
outputs = torch.zeros(input_seq.size(0), self.output_size, device=self.device)
y_prev = input_seq[:, -1, 0].unsqueeze(1)
for i in range(self.output_size):
step_decoder_input = torch.cat((y_prev, decoder_input[:, i]), axis=1)
if (yb is not None) and (i > 0) and (torch.rand(1) < self.teacher_forcing):
step_decoder_input = torch.cat((yb[:, i].unsqueeze(1), decoder_input[:, i]), axis=1)
rnn_output, prev_hidden = self.decoder_cell(prev_hidden, step_decoder_input)
y_prev = rnn_output
outputs[:, i] = rnn_output.squeeze(1)
return outputs五、模型训练
模型的性能在很大程度上取决于围绕优化、学习率计划等做出的训练决策。我将简要介绍它们中的每一个。
验证策略——横截面训练-验证-测试拆分不起作用,因为我们的数据是时间相关的。 依赖于时间的训练-验证-测试拆分会带来一个问题,即模型没有在最近的验证数据上进行训练,这会影响模型在测试数据中的性能。为了解决这个问题,模型根据 2014 年至 2016 年 3 年的过去数据进行训练,并预测 2017 年前 3 个月,用于验证和实验。 最终模型使用 2014 年至 2017 年的数据进行训练,并预测 2018 年前 3 个月的数据。最终模型基于验证模型训练中的学习,在没有验证的情况下以盲模式进行训练。
优化器——使用的优化器是 AdamW,它在许多学习任务中提供了结果状态。 更详细的 AdamW 分析可以在 Fastai 中找到。 探索的另一个优化器是 COCOBOptimizer,它没有明确设置学习率。 在使用 COCOBOptimizer 进行训练时,我观察到它比 AdamW 收敛得更快,尤其是在初始迭代中。 但最好的结果是使用 AdamW 和 One Cycle Learning 获得的。
学习率调度——使用了 1 个周期的学习率调度器。 通过使用循环学习的学习率查找器确定循环中的最大学习率。 使用的学习率查找器的实现来自库——pytorch-lr-finder。
使用的损失函数是均方误差损失,这与完成损失 — SMAPE 不同。 MSE 损失提供了比使用 SMAPE 更稳定的收敛。
编码器和解码器网络使用了单独的优化器和调度器对,从而改进了结果。
除了权重衰减之外,编码器和解码器都使用了 dropout 来对抗过度拟合。
构建了一个包装器来处理训练过程,能够处理多个优化器和调度器、检查点和 Tensorboard 集成。 相关代码可以在 trainer.py 中找到。
六、结果
下图显示了模型对 2018 年前 3 个月的商店单品的预测。
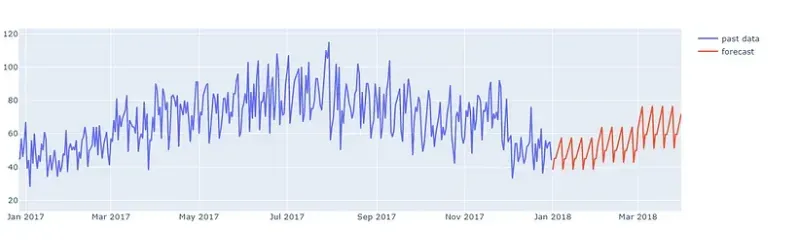
通过绘制所有项目的平均销售额和去除噪声的平均预测,可以更好地评估模型。 下图来自特定日期验证模型的预测,因此可以将预测与实际销售数据进行比较。
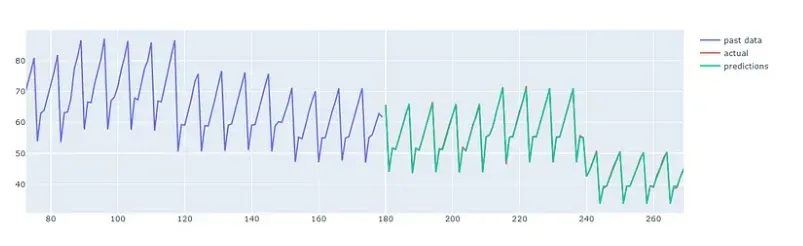
为了达到这个结果,我做了最少的超参数调整,所以还有更多的改进空间。 还可以通过探索注意力机制对模型进行进一步改进,进一步提升模型的记忆力。
七、代码资源
我把基于pytorch版本的时间序列预测代码已经上传至资源中,包括kaggle的数据,https://download.csdn.net/download/u010329292/87666790,供有需要的小伙伴下载学习。
文章出处登录后可见!