

论文:LOFTR: Detector-Free Local Feature Matching with Transformers
链接: 论文地址
什么是特征匹配?
简单说,特征匹配就是对两张有关联的图像,把它们中的共同区域找出来。比如说,用相机拍摄某一个建筑物,但是拍摄的角度不一样,这就是有关联的图像,然后通过深度学习的神经网络把其中的相似部分找出来,也就是提取或者匹配其中相同的特征,如下图
特征匹配的应用场景有哪些?
如上个问题所说,通过特征匹配就可以得到两张图片的共同信息,也就是匹配很多点(图像是由很多像素点组成),然后就可以通过匹配的这些点进行反推,即反推相机的位置信息。

因为是用相机对相同物体的不同的角度进行拍摄,所以相机必然是经过平移或者旋转才能拍摄不同角度的照片。因此就能通过特征匹配的结果计算相机到底平移了多少米,或者旋转了多少角度。
因此,通过特征匹配可以实现机器人的导航和定位。其次,特征匹配还是三维重建的基础研究,因为在三维重建中就需要提供物体的位置信息。以及,特征匹配还能用在淘宝或者京东当中的搜同款。但是,特征匹配最重要的作用还是应用在导航和定位中。
传统的特征匹配
基于OpenCv,也能实现特征匹配,但是用的是传统的特征匹配算法。
传统特征匹配算法主要是基于关键点实现特征匹配。何为关键点?就是两幅图像当中一些特殊的点,比如说是图像中梯度变化比较大的点,或者是一些角点。如下图:
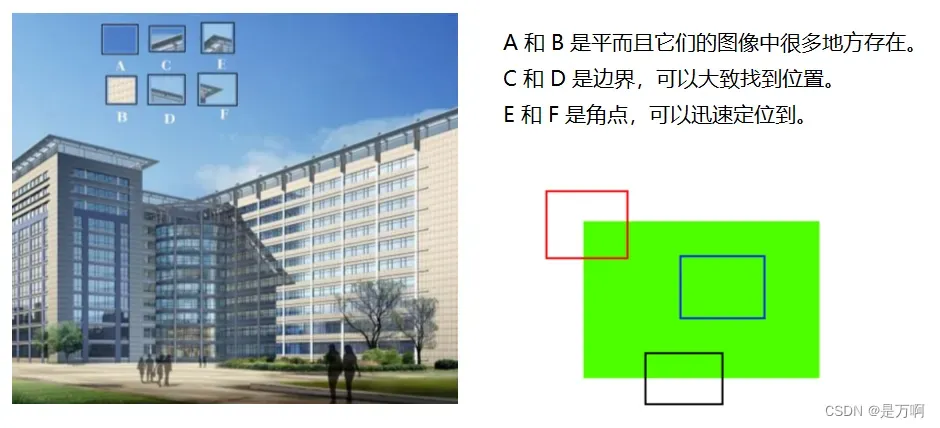
所以传统的特征匹配算法,第一步就是找到图像的关键点,然后基于关键点实现特征匹配。

但是这会存在一个问题。如上所说,传统算法是基于关键点实现特征匹配,所以在实现步骤上,它的第一步就是找两幅图像的关键点。但是,但是,但是,如果两幅图像没有很明显的关键点呢,也就是没有特殊点,怎么办?那就会导致特征匹配的任务进行不下去,所以这是传统的特征匹配算法的第一个瓶颈:太依赖于找图像中的关键点了,以至于没有关键点,特征匹配的任务就做不下去。
传统的特征匹配算法还有没有其他问题呢?举个例子,如下图

如图,左图有A1、B1两个不同的区域;右图有A2、B2。
传统的算法(LOFTR也是)是把图像信息转化为特征信息进行特征匹配,所以就需要把左图中A1和B1区域转化为特征向量,然后把右图的A2和B2区域也转化为特征向量,然后进行匹配。

观察上图,不管是A1、B1,还是A2、B2,它们都是背景信息,也就是说它们都是很相似的特征,所以就会有这样情况:本来是想着,A1匹配A2,B1匹配B2,但是由于它们的特征信息太接近(都是背景),所以就会有A1匹配了B2,B1匹配了A2的情况。这是传统匹配算法的第二个问题。即,对于相近的背景信息,或者相近的特征信息,匹配的效果的并不好。
LOFTR算法
优势:解决了上述传统算法中提出的两个瓶颈。在LOFTR中,第一步不需要去找图片中的特征点,因为它直接把图像分为很多个小区域,通过匹配小区域来实现特征匹配。
所以,在LOFTR当中,先做了这么一件事:不主动去找图片的特征了。因为图片的特征不好找,这就导致如果找不到两张图片的共同特征,那么特征匹配的任务根本就做不下去。
但是特征匹配,肯定是要依赖于图片中的共同特征,所以特征信息还是需要的。所以在LOFTR中实现“被动”找特征,这个“被动”是指:找特征这件事交给神经网络去做,也就是搞不定的事都交给神经网络,让神经网络去解决。
怎么理解这件事呢,我们生活在三维世界中,但是神经网络中的向量计算动不动就牵涉到几十、上百、上千或者上万维的计算,正所谓站的高,看得远,所以借助神经网络就能实现复杂问题的求解。
传统算法的第二个问题呢,是对于两个在同样背景下的点,或者多个在相同下背景点,由于它们的位置不同,所以它们也应该是不同的特征表示,但是传统算法这这方面做的并不好。
所以在LOFTR中,同样的思想,这件事不好解决,那就继续交给神经网络去解决,那LOFTR是通过什么样的方式解决的呢?
特征提取
特征提取,就是对输入的图像进行特征的提取。基本上,对图像研究的算法,比如图像分类算法、图像识别算法和图像分割算法,它们的第一步都是特征提取,因为只有提取了图像的特征,才能分析图片中的信息,然后用这些信息完成我们自己的任务。
同理,在LOFTR中,第一步也是特征的提取。

如图,输入两张图片,经过CNN卷积神经网络进行特征提取,得到一系列的特征图,然后拿出其中的1/8和1/2大小的特征图进行分析。

文章出处登录后可见!