

数据集和地图可以点赞关注收藏后评论区留下QQ邮箱或者私信博主要
聚类是一类机器学习基础算法的总称。
聚类的核心计算过程是将数据对象集合按相似程度划分成多个类,划分得到的每个类称为聚类的簇
聚类不等于分类,其主要区别在于聚类所面对的目标类别是未知的
k-means聚类也称为K均值聚类算法,是典型的聚类算法,对于给定的数据集和需要划分的类数K,算法根据距离函数进行迭代处理,动态 的把数据划分成K个簇,直到收敛为止,簇中心也称为聚类中心
先来个小例子
这个是通过聚类算法对鸢尾花数据集的预测结果
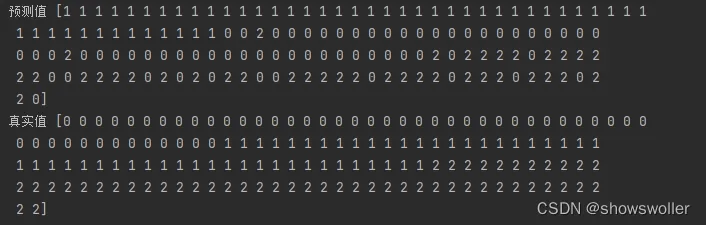

代码如下
from sklearn.cluster import KMeans
from sklearn import datasets
import numpy as np
iris=datasets.load_iris()
x=iris.data
y=iris.target
clf=KMeans(n_clusters=3)
model=clf.fit(x)
predicted=model.predict(x)
print("预测值",predicted)
print("真实值",y)
print()
同样地k-means聚类算法广泛地应用于人群分类,图像分割,物种聚类等等问题中
下面以一个物流配送问题为例进行详细讲解
问题描述:双十一期间,物流公司要给某城市的50个客户配送货物,假设公司只有5辆货车,客户的地理坐标在txt文件中,如何配送效率最高
问题分析:使用k-means算法,将地址数据分为5类,由于每一类客户地址相近,可以分配给同一台货车
原地图如下
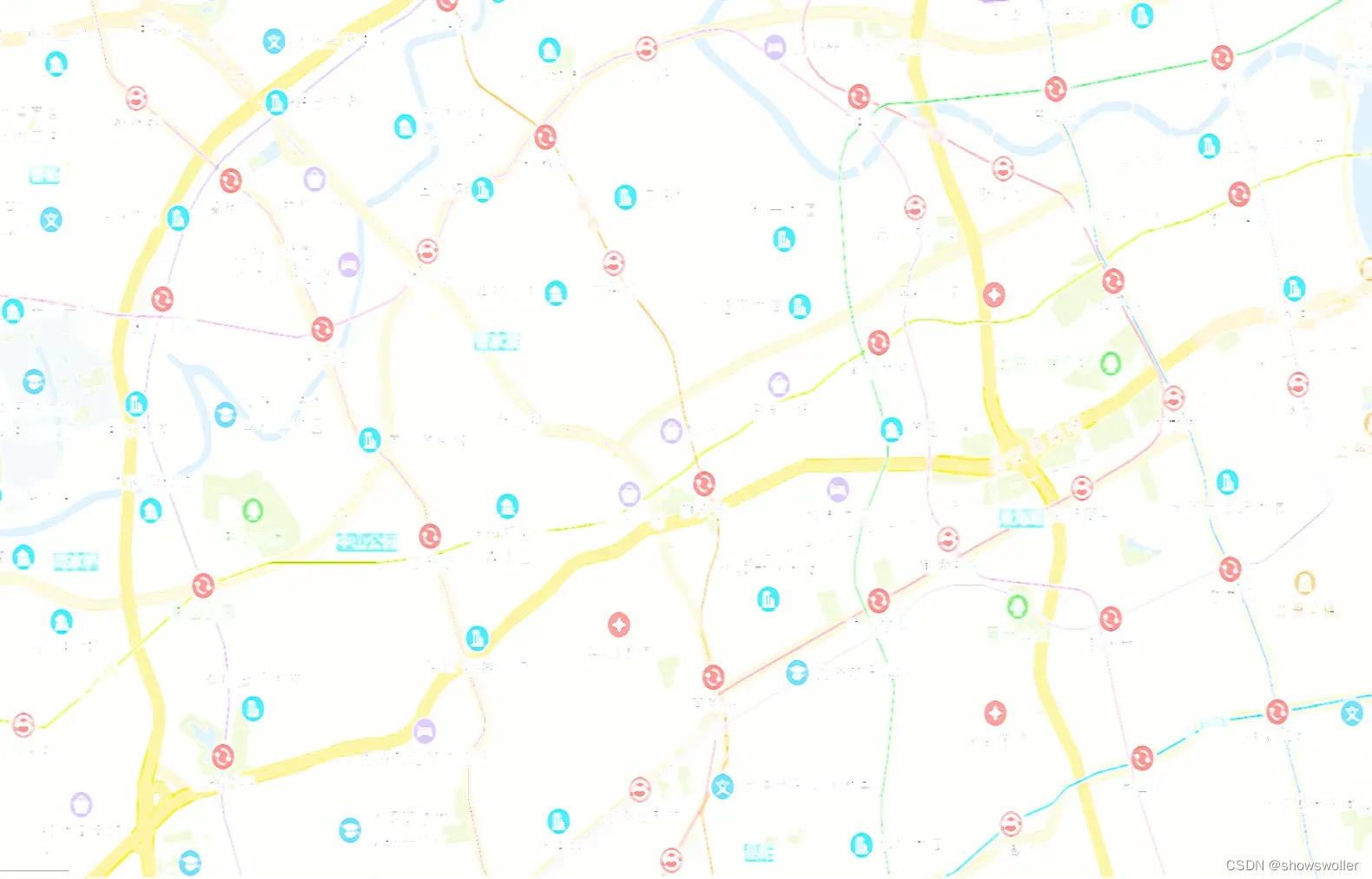

经过聚类分析后结果如下
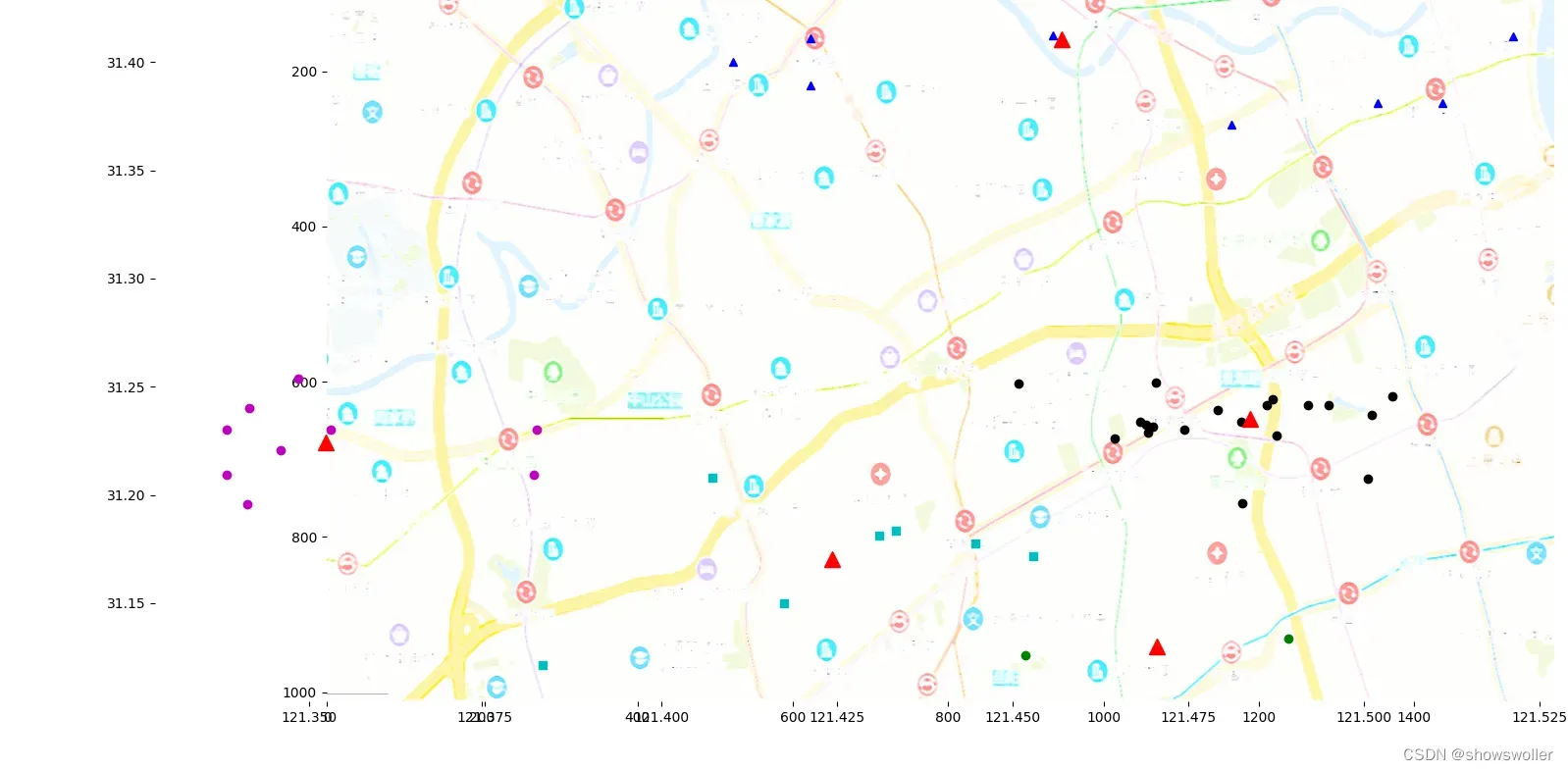

很明显根据客户的地址分为5个簇,每个簇由一台货车集中配送
源代码如下
#coding=utf-8
from numpy import *
from matplotlib import pyplot as plt
import matplotlib; matplotlib.use('TkAgg')
def disteclud(veca,vecb):
return sqrt(sum(power(veca-vecb,2)))
def initcenter(dataset,k):
print('2.initalize cluster center')
shape=dataset.shape
n=shape[1]
classcenter=array(zeros((k,n)))
for j in range(n):
firstk=dataset[:k,j]
classcenter[:,j]=firstk
return classcenter
def mykmeans(dataset,k):
m=len(dataset)
clusterpoints=array(zeros((m,2)))
classCenter=initcenter(dataset,k)
clusterchanged=True
print('3.recompute and reallocated')
while clusterchanged:
clusterchanged=False
for i in range(m):
mindist=inf
minindex=-1
for j in range(k):
distji=disteclud(classCenter[j,:],dataset[i,:])
if distji<mindist:
mindist=distji;minindex=j
if clusterpoints[i,0]!=minindex:
clusterchanged=True
clusterpoints[i,:]=minindex,mindist**2
for cent in range(k):
ptsinclust=dataset[nonzero(clusterpoints[:,0]==cent)[0]]
classCenter[cent,:]=mean(ptsinclust,axis=0)
return classCenter,clusterpoints
def show(dataset,k,classCenter,clusterPoints):
print('4.load the map')
fig=plt.figure()
rect=[0.1,0.1,1.0,1.0]
axprops=dict(xticks=[],yticks=[])
ax0=fig.add_axes(rect,label='ax1',frameon=False)
imgp=plt.imread(r'C:\Users\Admin\Desktop\city.png')
ax0.imshow(imgp)
ax1=fig.add_axes(rect,label='ax1',frameon=False)
print('5.show the clusters')
numsamples=len(dataset)
mark=['ok','^b','om','og','sc']
for i in range(numsamples):
markindex=int(clusterPoints[i,0])%k
ax1.plot(dataset[i,0],dataset[i,1],mark[markindex])
for i in range(k):
markindex=int(clusterPoints[i,0])%k
ax1.plot(classCenter[i,0],classCenter[i,1],'^r',markersize=12)
plt.show()
print('1. load the dataset')
dataset=loadtxt(r'C:\Users\Admin\Desktop\testSet.txt')
k=5
classCenter,clssspoints=mykmeans(dataset,k)
show(dataset,k,classCenter,clssspoints)
数据集和地图可以点赞关注收藏后评论区留下QQ邮箱或者私信博主要
文章出处登录后可见!
已经登录?立即刷新