


文章目录
边界框回归(Bounding-Box Regression)
本篇博客实际上参考了CSDN另一篇博客写的 这是链接。但那篇博客的排版和语言表达实在是太烂了,公式错误也很多,以至于我花了很多时间才看明白。我将自己的思考结果记录下来,供大家参考。
一、边界框回归简介
那么边界框回归所要做的就是利用某种映射关系,使得候选目标框(region proposal)





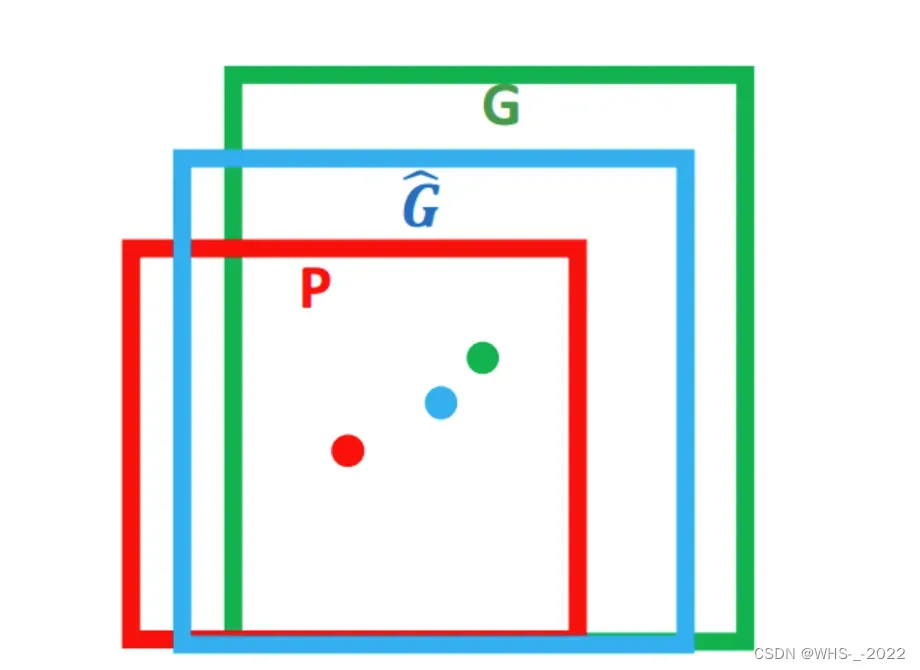

边界框回归过程图像表示如图1所示。在图1中红色框代表候选目标框,绿色框代表真实目标框,蓝色框代表边界框回归算法预测目标框。红色圆圈代表选候选目标框的中心点,绿色圆圈代表选真实目标框的中心点,蓝色圆圈代表选边界框回归算法预测目标框的中心点。
二、边界框回归细节
RCNN论文里指出,边界框回归是利用平移变换和尺度变换来实现映射 。平移变换的计算公式如下:

尺度变换的计算公式如下:
其中
其中:













可以看出,上述模型就是一个Ridge回归模型。在RCNN中,边界框回归要设计4个不同的Ridge回归模型分别求解

回归模型的输入是什么?是
这个四维张量吗?

真正的输入是这个窗口对应的 CNN 特征,也就是 R-CNN 中的


三、相关问题思考
1. 为什么使用相对坐标差?
在式
中 ,那么为什么要将真实框的中心坐标与候选框的中心坐标的差值分别除以宽高呢?
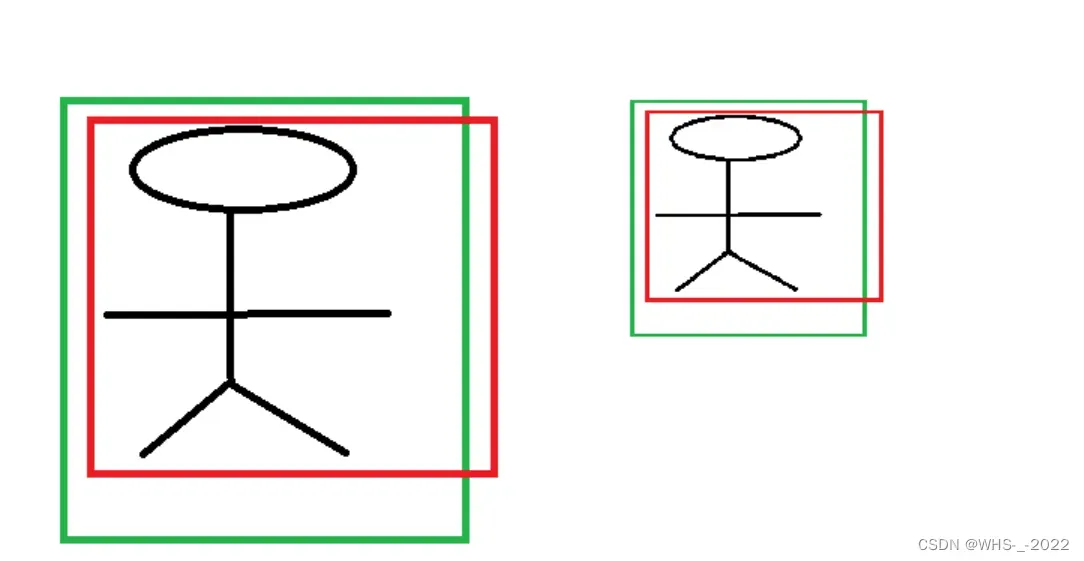

接下来的讨论中,我们假设边界框的回归使用绝对坐标。
首先我们假设两张尺寸不同,但内容相同的图像,图像如图2所示。我们假设经过CNN提取的特征分别为
理论上来说,CNN得出的特征




关于CNN是否有尺度不变性,这篇论文有说明过Object Detection in 20 Years: A Survey
因此,我们必须对
2. 为什么宽高比要取对数?
类比问题1,我们不禁要问为什么不直接使用宽高的比值作为目标进行学习,非得“多此一举”取对数?
线性函数输出的是一个实数,因为宽和高乘的倍数必须大于0,所以要取指数的形式,反过来就是取对数。
3. 为什么IoU较大时边界框回归可视为线性变换?
‘Rich feature hierarchies for accurate object detection and semantic segmentation’文章中曾经提到,IoU必须大于

知乎上一篇博客曾经尝试解释过这个问题 这是链接。


但我觉得是不合理的,当
和 时候,式 的后两项确实可以视为某种线性的变换。但我们要理解到,我们回归的输入量是 窗口对应的 CNN 特征,而不是四维张量 。所以这里分析原边界框的坐标和Ground-truth的边界框坐标是否是线性关系是没有意义的。



文章出处登录后可见!