

本章介绍python是数组库——numpy的使用。numpy数组对于表格的学习具有很重要的作用,特别是pandas,学好numpy,为pandas打好基础。
目录
1. 创建数组
(1)np.array()
array(object, dtype=None, *, copy=True, order='K', subok=False, ndmin=0,like=None)object:一个序列,可为列表或者元组。
dtype:numpy内部数据类型,可以把数据转换为整数或者浮点数,可以选择int,int32,int64,float,float32,float64等。
copy:复制object序列,默认为True。当object是数组时,复制副本就不会影响原数组。
order:创建数组的布局形式。
subok:默认为False。是否使用内部数组类型。
ndmin:指定数组的维度。
like:创建维度像xxx一样数组。
直接创建数组,可以键入列表、元组。用的最多的参数只有前两个。
import numpy as np
arr = np.array([1,2,3,4,5])
print(arr)
print(type(arr))
print(arr.dtype)

传入元组也可以,自己动手试试。数组在 “外观” 上的不同在于列表是用逗号隔开,而数组是用空格隔开;在本质上的不同在于数组是一组同类数据的组合(全是数字或者全是字符串),而列表可以为不同类别。
加入同时传入数字和字符串,那么该数组的格式数据类型为字符串。如:
arr = np.array([1,2,'大',4,5])
print(arr)
print(type(arr))
print(arr.dtype)

type()函数是python的内置函数,用于判断整个变量是什么数据类型;arr.dtype是numpy的函数,用于判断数组中的数据属于什么数据类型。
(2)np.arange()
arange(start, stop, step, dtype=None, *, like=None) 连续范围创建。start:开始(包含)。
stop:结束(不包含)。
step:步长(间距)。
dtype:numpy内部数据类型。
like:创建维度像xxx一样数组。
arr = np.arange(1,9)
# arr = np.array([1,2,3,4,5,6,7,8,9]) # 一样
# arr = np.array(range(1,9)) # 一样
print(arr)
arr_2 = np.arange(1,9,2)
print(arr_2)

2. 创建多维数组
(1)创建二维数组
arr = np.array([[1,2,3,4],
[5,6,7,8]])
print(arr)

二维可以理解为一个平面,也可以理解为一个几行几列的表格。
(3)创建多维数组
arr = np.array([[[1,2,3,4],[5,6,7,8]],
[[10,11,12,13],[14,15,16,17]]])
print(arr)

该例子为创建三维数组,就是多个平面(二维)叠加嘛。
3. 创建特殊数组
(1)np.ones()
np.ones(shape, dtype=None, order='C', *, like=None) 创建一个shape形状的全是1的数组。shape:形状,几行几列。
arr = np.ones([2,3])
print(arr)

如果想得到整数,可设置数组数据类型:
arr = np.ones([2,3],dtype='int32')
print(arr)

创建一个2行3列的1数组。
(2)np.zeros()
arr = np.zeros([2,3])
print(arr)

创建一个2行3列的零数组。
(3)np.full()
np.full(shape, fill_value, dtype=None, order='C', *, like=None) 创建一个shape形状的全是特定值的数组。arr = np.full([2,3],520)
print(arr)

创建一个指定形状指定数值的数组。
(4)np.eye()
np.eye(N, k=0, dtype=<class 'float'>) 创建对角线为1,其余为0的数组。N:数组的规模 形状 几行几列(行数=列数)
k:哪条边全是1?对角线上下方(+ -)第k条线全是1,其余全是0。
dtype:内部数据类型。
a = np.eye(N=3,k=0)
print(a)
print('-'*35)
b = np.eye(N=3,k=1)
print(b)

如图,N=3则3行3列;k=0则是对角线全是1,其余全是0;k=1则是对角线上方第k条线全是1,其余全是0;k=-1则是对角线下方第k条线全是1,其余全是0……
(5)np.diag()
np.diag(a, k=0) 生成对角线元素是a的数组。a:可以是一个列表、元组等。
k:哪条边全是1?对角线上下方(+ -)第k条线的元素是a,其余全是0。
a = [1,2,3]
b = np.diag(a)
print(b)

再如 k=1 (对角线上方第1条线的元素是a,其余全是0):
a = (1,2,3)
b = np.diag(a,k=1)
print(b)

4. 数组模板创建数组
(1)np.ones_like()
np.ones_like(a, dtype=None, order='K', subok=True, shape=None) 以一个数组为模板,创建一个和它形状一样,值是1的数组。arr = np.array([[1,2,3],[4,5,6]])
print(arr)
print('-'*70)
a = np.ones_like(arr)
print(a)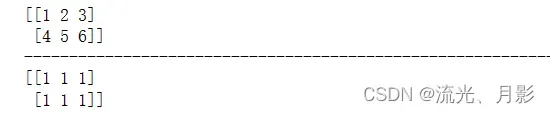

此案例以arr数组为模板,创建一个形状像arr的,数值全是one即1的数组。
(2)np.zeros_like()
np.zeros_like(a, dtype=None, order='K', subok=True, shape=None) 以一个数组为模板,创建一个和它形状一样,值是0的数组。
arr = np.array([[1,2,3],[4,5,6]])
print(arr)
print('-'*70)
a = np.zeros_like(arr)
print(a)

(3)np.full_like()
np.full_like(a, fill_value, dtype=None, order='K', subok=True, shape=None) 以一个数组为模板,创建一个和它形状一样,值是指定数值的数组。arr = np.array([[1,2,3],[4,5,6]])
print(arr)
print('-'*70)
a = np.full_like(arr,520)
print(a)

5. 数组的属性
| arr.shape | 返回一个数组的形状,即几行几列。 |
| arr.size | 返回一个数组中所有数据元素的数目。 |
| arr.ndim | 返回数据是几维的。 |
arr = np.array([[[1,2,3,4],[5,6,7,8]],
[[10,11,12,13],[14,15,16,17]]])
print(arr)
print('-'*70)
print(arr.shape)
print(arr.size)
print(arr.ndim)

可见该三维数组是由2个平面,每个平面由2行,每行由4个元素组成的。元素总数是16个。是三维数组。
6. numpy中的 random随机库
(1)随机数生成
np.random.randint(low, high=None, size=None, dtype=int)low:最小值(包括)。
high:最大值(不包括)。
size:数量,形状等
dtype:数据类型。
ran = np.random.randint(1,51,(2,3))
print(ran)

通过随机数创建一个2行3列的数组。numpy中的随机数有点在于可以设置数组的形状(几行几列等),而随机数库random一次只能得到一个。
其他随机数函数的用法和 random库的用法是一样的,可以在random库了解更多random的函数。需要注意的是,在random库中,是包括左右边界的;而在np.random中是不包括右边界的。
(2)np.random.choice()
np.random.choice(a,size) 在a中随机选取size数量的元素,元素之间有可能重复。a可以为一个数,也可以是一个列表。若是一个数,则表示为 range(0,a)。
a = np.random.choice(10,(3,2))
print(a)

(3)np.random.shuffle()
np.random.shuffle(a) 洗牌,把数组a随机打乱。注意该函数是直接作用于a的,如果重新定义变量,得到的会是None。如果想赋给新变量,可以使用 np.random.permutation函数。
a = np.random.choice(10,(3,2))
print(a)
print('-'*50)
np.random.shuffle(a)
print(a)

知识点:一维打乱元素,二维只打乱行的顺序,三维只打乱块的顺序。大家也可以亲自去试试。
(4)np.random.permutation()
np.random.permutation(a) 作用和 np.random.shuffle(a)一样,但该函数可以对洗牌后的数组赋予新变量,使原数组不发生改变。
a = np.random.choice(10,(3,2))
print(a)
print('-'*50)
b = np.random.shuffle(a) # 无法赋予给新变量b,若赋予,会得到None
print(b)
print('-'*50)
c = np.random.permutation(a) # 可以赋予给新变量c
print(c)

shuffle 和 permutation 的区别在于:前者是在原来是数组上打乱;后者是新定义一个变量(如c),使新变量改变,而原数组不变。
7. 数组维度/形状的转换/转置
(1)arr.reshape()
arr.reshape(shape, order='C') 把数组转换为shape形状。arr = np.arange(1,25)
print(arr)
print('-'*70)
a = arr.reshape(3,8)
print(a)
print('-'*70)
b = a.reshape(4,6)
print(b)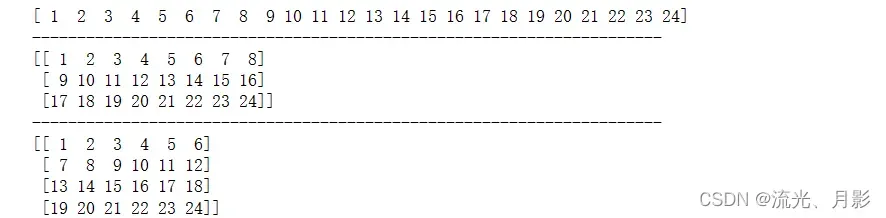

可把1行的arr转成二维 3行8列,把3行8列的a转成4行6列的b。但是需要注意,最终数组的总数必须一样,就如案例中arr总元素数为24个,转换后的a,b总数都需要是24个,也就是说,假如是二维,那么 行数X列数 要等于总数。
如果想把多维转为一维,可以用 reshape:
arr = np.arange(1,25).reshape(4,6)
print(arr)
print('-'*70)
a = arr.reshape(1,24)
print(a)
print('-'*70)
b = arr.reshape(24)
print(b)

a与b的区别在于a还是二维的,b是一维的。(最简单的方法,看几维可看开头的 [ 数 )
(2)arr.flatten()
arr.flatten(order='C') 直接把多维转为一维(无论它是几维)arr = np.arange(1,25).reshape(3,8)
print(arr)
print('-'*70)
a = arr.flatten()
print(a)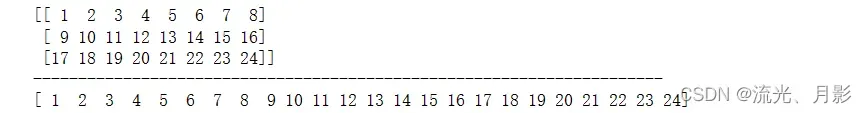

(3)arr.T 或 arr.transpose() 二维数组转置
a = np.arange(21).reshape(7,3)
print(a)
print('-'*70)
print(a.transpose()) # 也可以简写成 a.T

数组转置使数组以对角线 \ 为轴翻转。
8. 数组的运算
(1)数组和数字之间的加减乘除
a = np.array([1,4,5,3,8,6]).reshape(2,3)
print(a)
print('-'*70)
b = a*5
print(b)

数组对一个数字进行加减乘除时,也是对数组内的每一个数产生作用的,即案例中数组的每一个数都乘以5。
(2)数组与数组之间的加减乘除(形状一样 个案对位)
a = np.array([1,4,5,3,8,6]).reshape(2,3)
b = np.array([2,0,7,5,8,1]).reshape(2,3)
print(a)
print('-'*70)
print(b)
print('-'*70)
print(a*b)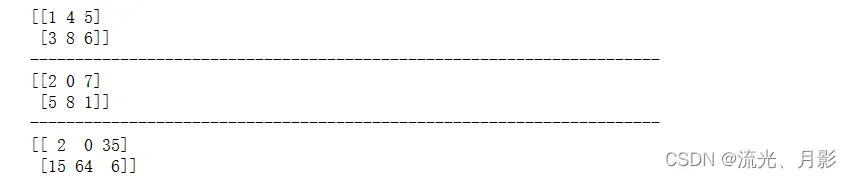

数组与数组之间的加减乘除 前提是数组的形状必须符合 “行/列对位” 或者 “个案对位” 原则,如果不符合,会报错 ” operands could not be broadcast together with shapes (6,) (2,3) ” 。”个案对位” 即该数组的每个数都对应另一数组的每个数,两数组的行数都相同,列数也都相同。
在符合原则的条件下,数组之间的运算都是对应位置的值进行加减乘除,除法要注意除数数组不含0。注意,这里说的是数组之间,并不是数学中的矩阵,因为数学中矩阵的乘法并非对应位置相乘。一旦涉及到线性代数矩阵的运算,就不应该用np.array(),而是用np.matrix(),调用方法和加+减-乘*除/运算的使用方法是一样的。特别是乘法*,两np.matrix()相乘* 与 两np.array()相乘*的结果是不一样的,非常明显,np.matrix()得出的结果才符合数学中的矩阵。
(3)数组与数组之间的加减乘除(形状不一样 但行/列对位)
” 行对位 ” 即单行/列的数组的长度和另一个数组每行/每列的长度是一样的。如:


a = np.array([[1,3,4,6,5,9],[4,3,8,5,1,6]])
b = np.array([6,4,7,4,9,1])
print(a)
print('-'*70)
print(b)
print('-'*70)
print(a+b) 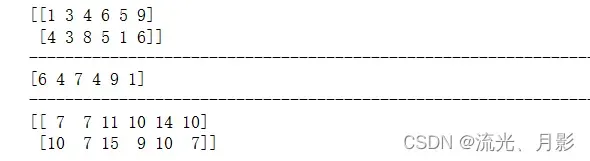

这种数组的运算是a数组的每一行都加上b数组,减乘除也一样,每一行为单位,动手试试。有一个特点,必须有一个数组是单行/单列的。
9. 数据选取/数据切片
(1)一维数组
a = np.arange(10)
print(a)
print('-'*30)
print(a[4:]) # 取第5个及以后的数
print('-'*30)
print(a[4]) # 取第5个

(2)二维数组
arr[row,column]
a = np.arange(1,21).reshape(4,5)
print(a)
print('-'*30)
print(a[2,:]) # 行:取第3行及以后,列:全部。当列为全部时也可简写成a[2]
print('-'*30)
print(a[:,1]) # 行:全部,列:第1列。

在arr[row,column]中,row为行,column为列,先行后列。选择多行多列如下:
a = np.arange(1,21).reshape(4,5)
print(a)
print('-'*30)
print(a[2:,:]) # 选取第3行到最后,也可写成a[2:]
print('-'*30)
print(a[:,:-1]) # 选取全部行 列到倒数第二列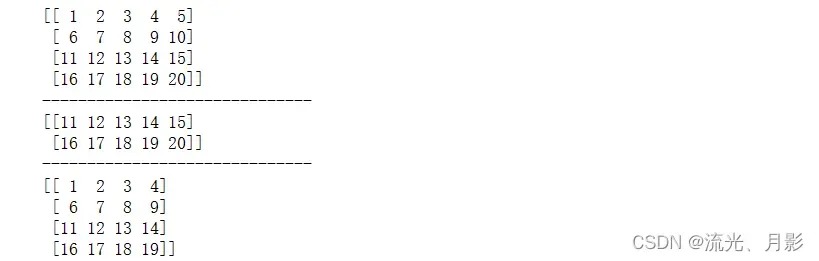

10. 神奇索引
上面取多行/多列都是连续的,如3到倒数第二行。对于取非连续的行/列,需要用到神奇索引,神奇索引表现为两个 [[ 去离散取值。
(1)一维
a = np.arange(21)
print(a)
print('-'*70)
print(a[[3,5,7,8,10]]) # 取a中的第4,6,8,9,11个数

(2)二维
① 取行
a = np.arange(21).reshape(7,3)
print(a)
print('-'*70)
print(a[[1,3,5],:]) # 取第1,3,5行(从0开始)。当列全取时,也可写成a[[1,3,5]]

② 取列
a = np.arange(21).reshape(7,3)
print(a)
print('-'*70)
print(a[:,[0,2]])

③ 对位取值
arr[ [行] , [列] ] 其中行数和列数必须相等,此函数是对位取值,如arr[ [0,2,4] , [1,3,5] ] 取到的是(第0行第1列)(第2行第3列)(第4行第5列)的数,共3个。


a = np.arange(30).reshape(5,6)
print(a)
print('-'*30)
print(a[[0,2,4],[1,3,5]]) # 取(第0行第1列)(第2行第3列)(第4行第5列)

对于多维的方法也类似,琢磨一下。
11. 数组元素的筛选/条件统计
(1)筛选出符合条件的值
rand = np.random.randint(1,50,(4,5))
a = np.array(rand)
print(a)
print('-'*70)
print(a < 20)
print('-'*70)
print(a[a<20])这次我们运用一下上面学到过的知识,随机数,随机产生20个4行5列的1到49范围内的数组。
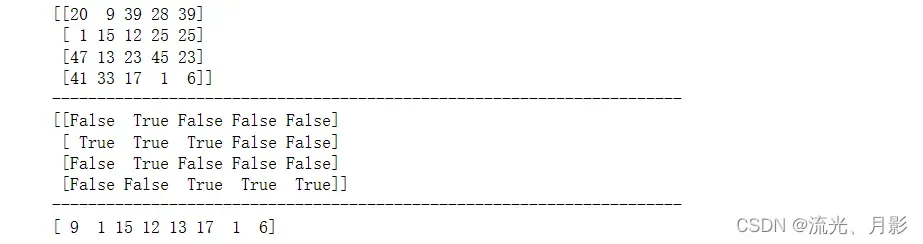

可见,当判断a<20时,得到的是每个数的布尔值(True or False)。随后便可以在a中选择这些数了,a[a<20] ,为True的数会被选上,而为False的数不会,返回的结果都是一维的。
(2)统计出符合条件的数的个数
在上面例子的基础上用 .sum()函数进行求和就可以。当 .sum()作用于布尔列表(True or False组成的列表)时,True会被认为是1,而False会被认为是0,所以条件出的是True的个数,也就是符合条件的个数。(暂时不考虑sum(b),因为这会是按列求和的,后续按轴求和时会讲到)
rand = np.random.randint(1,50,(4,5))
a = np.array(rand)
print(a)
print('-'*70)
b = a<20
print(b.sum())

那不符合条件的数呢?我们可以对布尔列表进行取反,那么True就变成False,False就变成True了。在布尔列表前加上~:
b = ~(a<20)
print(b.sum())(3)多条件筛选
a = np.arange(10).reshape(2,5)
print(a)
print('-'*30)
factor = (a % 2 == 0) & (a < 7)
print(a[factor])

多条件筛选出小于7的偶数。
12. 更改元素的值
(1)全局更改
直接对符合条件的数组元素进行赋值。如下把<5的数改为0,把 ≥ 5的数改为1:
a = np.arange(1,11).reshape(2,5)
print(a)
print('-'*70)
a[a < 5] = 0 # 把小于5的数改为0
a[a >= 5] = 1 # 把大于等于5的数改为1
print(a)

进行此类操作,需要特别注意先后顺序。如第5、6行不可以反过来,试想一下,如果先把≥5的数改为0,再把<5的数改为0,那么得到的全是0了。因为第一次把≥5的都改成了1,而这些被改成1的数在第二次时又被改成了0。
同样,我们可以想到在原有数值的基础上 加减乘除 某些数:
a = np.arange(1,11).reshape(2,5)
print(a)
print('-'*70)
a[a >= 5] += 100 # 这里变成 +=
a[a < 5] += 10 # 这里也是
print(a)

(2)局部更改(二次切片)
a = np.arange(1,21).reshape(4,5)
print(a)
print('-'*30)
a[:,3][a[:,3]>5] = 520
print(a)

(3)np.where() 条件更改
np.where(condition, T_value, F_value) 符合condition条件的改为T_value,否则改为F_value。也可以像 excel的 IF函数一样,否值可以继续嵌套自函数,如下:。
a = np.array([[1,3,6],[9,3,2],[1,4,3]])
print(a)
print('-'*35)
print(np.where(a>3,520,1314)) # 把>3的值改为520,其余改为1314
print('-'*35)
print(np.where(a>3,520,np.where(a>2,555,1314))) # 把>3的值改为520,>2的改为555,其他改为1314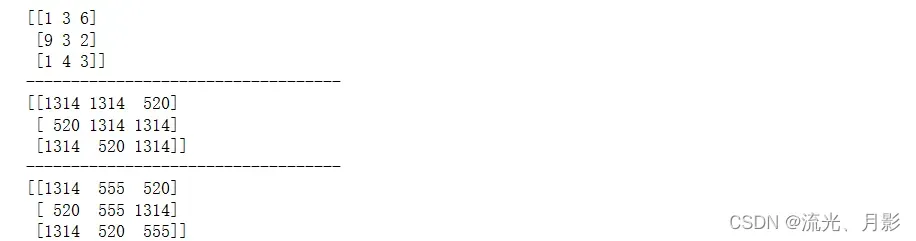

多条件时可以写多个条件表达式,必要时加()。需要保持不变的直接赋予元素组,如 把>3且<8的值改为520,其余保持不变:
a = np.array([[1,3,6],[9,3,2],[1,4,3]])
print(a)
print('-'*35)
print(np.where((a>3) & (a<8) ,520,a)) # 把>3且<8的值改为520,其余保持不变

13. 轴与数组元素的排序
(1)arr.sort(axis=1) 排序
np.random.seed(1)
a = np.random.randint(1,51,(3,4))
print(a)
print('-'*30)
a.sort(axis=1)
print(a)

这里设置random.seed是为了让每次输出的随机数相等。axis,即轴,在 .sort()函数中,当axis=1则行内元素从小到大排;当axis=0时则列内元素从小到大排。如下是axis=0的情况:


对于难理解的伙伴,可以两个都试试。
(2)arr.argsort() 排序对应的索引位置
np.random.seed(1)
a = np.random.randint(1,51,10)
print(a)
print('-'*40)
print(a.argsort())

该函数得到的是大小的排位。
(3)arr.argmax() 最大值所在的索引位置
np.random.seed(1)
a = np.random.randint(1,51,10)
print(a)
print('-'*40)
print(a.argmax())

最大值是44,44所在的位置索引是1。如果最大值有多个,那么只显示第一个最大值所在的位置索引。
(4)arr.argmin() 最小值所在的索引位置
np.random.seed(1)
a = np.random.randint(1,51,10)
print(a)
print('-'*40)
print(a.argmin())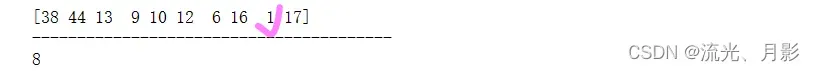

最小值是1,1所在的位置索引是8。同理,如果最小值有多个,那么只显示第一个最小值所在的位置索引。
(5)np.maximum()、np.minimum() 同位数比较取值
a = np.random.randint(1,50,10)
b = np.random.randint(1,50,10)
print(a)
print(b)
print('-'*50)
print(np.maximum(a,b))

在相同位置上,数组上下进行比较,取最大值。
14. 轴与数组的加法/乘法
(1)一维
a = np.random.randint(1,50,12)
print(a)
print('-'*50)
print(np.sum(a))

(2)二维
a = np.random.randint(1,50,12).reshape(3,4)
print(a)
print('-'*50)
print(np.sum(a,axis=0))

axis=0是输出为行。同理,axis=1是输出为列(只是显示为行而已):


数组的乘法 np.prod()和加法的原理一样,只需清楚轴向axis即可,需要用时自然会想到。
15. 轴与数组的累计加法/累计乘法
(1)一维
a = np.random.randint(1,50,12)
print(a)
print('-'*50)
print(np.cumsum(a))

累计加法就是前一个累计数加上当前的数的一个滚雪球法。如25是由4+21得到,49是由25+24得到,56是由49+7得到,66是由56+10得到……


(2)二维
a = np.random.randint(1,50,12).reshape(3,4)
print(a)
print('-'*50)
print(np.cumsum(a,axis=0))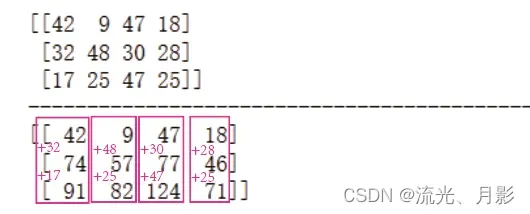

axis=0输出为行。同理,axis=1输出为列:


当累计加法乘法不添加轴向axis时,默认把数组变成一维,再进行累计加法乘法:
a = np.random.randint(1,50,12).reshape(3,4)
print(a)
print('-'*50)
print(np.cumsum(a))

乘法 np.cumprod()和加法的轴用法一样,可以动手试试。
16. 索引量统计 np.bincount()
a = np.array([4,5,5,3,1,4,4,4,0,5,1,3,4])
b = np.bincount(a)
print(b)![]()

该函数很多博主都解释不清楚,我也想了很久该如何才能讲得明白,最终还是觉得图表逐步讲解易理解:


首先得到该数组的最大值5,然后创建一个0到5的索引,分别统计0到5出现了几次,填在索引上方,没有的填0,就得到了结果 [1 2 0 2 5 3] 。
17. 数组合并
(1)np.vstack() 纵向合并
np.random.seed(1)
a = np.random.randint(1,50,(2,3))
b = np.random.randint(1,20,3)
print(a)
print('-'*35)
print(b)
print('-'*35)
c = np.vstack([a,b])
print(c)

(2)np.hstack() 横向合并
np.random.seed(1)
a = np.random.randint(1,50,(2,3))
b = np.random.randint(1,20,(2,1))
print(a)
print('-'*35)
print(b)
print('-'*35)
c = np.hstack([a,b])
print(c)

注意横向合并,b的形状需要是二维的,如果是一维的,会报错。
(3)np.concatenate() 纵向/横向合并
np.random.seed(1)
a = np.random.randint(1,50,(2,3))
b = np.random.randint(1,20,(1,3))
print(a)
print('-'*50)
print(b)
print('-'*50)
c = np.concatenate([a,b],axis=0)
print(c)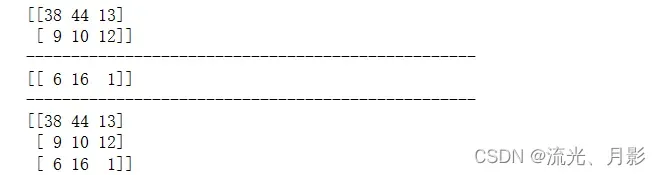

注意,无论是横向axis=1还是纵向axis=0,b数组都必须是二维的,如果是一维的,报错。可以 .reshape()把一维转换成几行几列的形状。当axis=1时:
np.random.seed(1)
a = np.random.randint(1,50,(2,3))
b = np.random.randint(1,20,(2,1)) # 这里变了
print(a)
print('-'*50)
print(b)
print('-'*50)
c = np.concatenate([a,b],axis=1) # 这里也变了
print(c)该函数相比于 np.vstack()和 np.hstack(),优点在于可以自己传入axis去控制轴向。但是需要更加注意数组的形状。
18. 数组拆分
(1)np.hsplit()
np.random.seed(1)
a = np.random.randint(1,50,(5,6))
print(a)
print('-'*35)
b,c = np.hsplit(a,2) # 第2列以后的会被拆走(保留0,1,2)
print(b)
print('-'*35)
print(c)

(2)np.vsplit()
np.random.seed(1)
a = np.random.randint(1,50,(5,6))
print(a)
print('-'*35)
b = np.vsplit(a,(1,2))
print(b)

(3)np.split()
np.random.seed(1)
a = np.random.randint(1,50,(5,6))
print(a)
print('-'*35)
b = np.split(a,(1,2),axis=0)
print(b)

19.关于数学和统计的其他函数
| np.average() | 加权平均数。可传入参数 weights |
| np.mean() | 平均数。 |
| np.median() | 中位数。 |
都可以传入轴向 axis。
20. any()和all()
.any() 只要有一个是非0,则True,否则False。
.all() 全部都为非0才是True,否则False。
a = np.array([1,2,1,1,1,1,1,0])
print(a.any())
print(a.all())

在该数值型数组a中,只要有一个不是0,any()就返回True;只要有一个是0(所有都不为0才是True),all()就返回False。
另外,在布尔值组成的列表中,True表示1,False表示0,可以把True当作1,False当作0去判断:
a = np.array([True,True,True,False,False,True,True,False])
print(a.any())
print(a.all())

21. np.unique() 去重
a = np.array([1,2,1,1,1,1,1,0])
print(np.unique(a))![]()

np.unique() 函数在去重的同时,还附带排序功能,从小到大排列。该函数也可以传入轴向axis进行轴去重。当不传入axis时,若数组是多维的,返回结果依旧是一维。
22. np.in1d() 共同元素判断
np.in1d(ar1, ar2, assume_unique=False, invert=False) 判断ar1中的元素是否在ar2中。a = np.array([6,0,0,3,2,5,6])
print(np.in1d(a,[2,3,6]))![]()

如图,a中的第一个元素6在[2,3,6]中,所以返回True;第二个元素0不在[2,3,6]中,所以返回False……虽然用for循环去遍历判断也可以做到,但是相比于np.in1d(),代码量有所增加。根据自己的实际,能想到这个函数就用,如果想不到,直接用for循环去遍历判断也可以。
23. 浅拷贝与深拷贝
(1)浅拷贝
浅拷贝是新变量的对旧变量的直接指向,如果修改其中一个变量,其他的变量也会受到影响。如旧变量直接赋值新变量、筛选等:
a = np.array([6,0,0,3,2,5,6])
b = a # 浅拷贝
c = a[3:] # 浅拷贝

(2)深拷贝
深拷贝是通过对旧变量进行复制得到的副本,如果修改其中一个,其他不会受到影响。如 .copy():
a = np.array([6,0,0,3,2,5,6])
b = a.copy()

(3)对比浅拷贝与深拷贝
a = np.array([6,0,0,3,2,5,6])
b = a # 浅拷贝
b.sort() # 改变b
print(a)![]()

可见,浅拷贝改变b时,a也受到了影响,也跟着改变了。这是由于浅拷贝中,a和b都在同一个内存池,都指向于 [6 0 0 3 2 5 6] 数组,当改变b时,a自然也跟着变了,可参照上上上图的浅拷贝内存池去理解。
a = np.array([6,0,0,3,2,5,6])
b = a.copy() # 深拷贝
b.sort() # 改变b
print('数组a:',a)
print('数组b:',b)![]()

可见,深拷贝时改变b,a并没有受到影响。因为深拷贝使它们被放在了在不同的内存池中,可参照上上上图的深拷贝内存池去理解。
结尾
numpy是学习pandas的基础,有了numpy的知识后,你对学习pandas会如鱼得水。在生活和工作中,更多的是通过数组把数据转为pandas对象,而很少是直接对数组进行处理,因为pandas具有更高效的函数和方法。如果你对numpy不是很懂也没关系,起码得有个了解,有个印象,在学习pandas时就能 “一点就明” ,而不至于迷茫很久,特别是轴这一块。亲自动手操作,学完这里,再运用小半个月,相信你就可以直接进军pandas了。
文章出处登录后可见!