


文章目录
1. 通信系统
在学习深度学习的编码器-解码器之前,先引入通信系统中的编码与解码、调制与解调。
- 通信是为了交流消息,交流消息需要保证接受方收到的和发出方所发送的信息一致。可是,通信过程中存在干扰!
- 原始信号(模拟信号):指通信系统中,发送端原始形成的、波形起伏多样、无规则的信号,容易被干扰(失真)。
- 因此需要给信号进行加工,使其即不容易被干扰、波形不严重变形。
所以就有了编码与解码、调制与解调:
- 在发送端,信源编码 对原始信号
- 利用调制技术进一步加强信号,得到中间信号
- 在接收端,信道解码 ,信源解码 逆操作得到输出信号
- 从而完成一个高保真、高效率的信号传输。

编码方式:反向不归零编码,曼彻斯特编码,密勒编码,修正密勒码,差错控制编码。
调制方式:振幅键控,频移键控,相位键控,副载波调制。
参考
2. 编码器Encoder-解码器Decoder
2.1 导言
在机器学习中,很多问题可以抽象出类似的模型:
机器翻译:将一种语言的句子转化成另外一种语言的句子。
自动摘要:为一段文字提取出摘要。
为图像生成文字解说:将图像数据转化成文字数据。
直接用一个函数
因此,先将输入数据编码与解码过程:原始信号
2.2 Encoder-Decoder架构
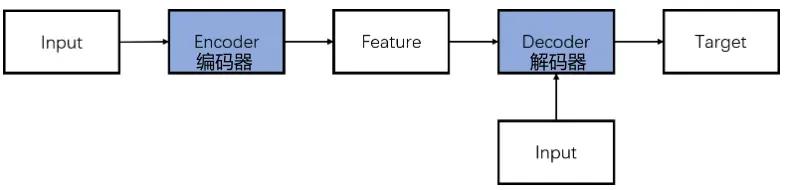
编码器-解码器(Encoder-Decoder)是深度学习模型的抽象概念。许多模型都基于这一架构,比如CNN,RNN,LSTM和Transformer等。
- 编码器(Encoder):负责将输入(Input)转化为特征(Feature)
- 解码器(Decoder):负责将特征(Feature)转化为目标(Target)

- CNN(卷积神经网络):可以当作解码器Decoder,可以不接受输入Input。

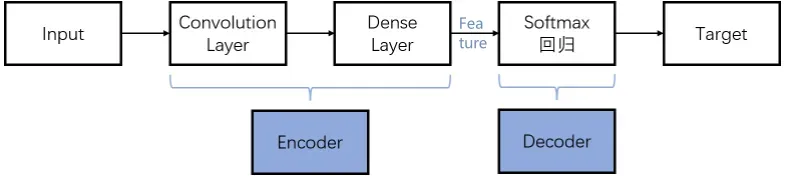
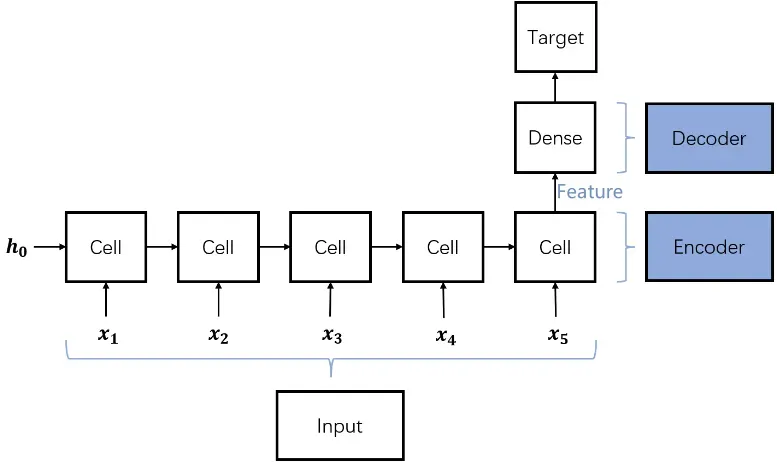
- RNN(循环神经网络):可以当作解码器Decoder,接受输入Input。

2.3 详细介绍
2.3.1 PCA 主成分分析
PCA是一种无监督数据降维算法。将一个高维的向量 公式1实现数据降维。降维过程类似于编码器,将高维向量
有时,我们需要从降维后的向量 公式2实现数据重构。数据重构和数据降维算法相反,重构过程类似于解码器,从低维向量
2.3.2 Auto-Encoder AE 自动编码器
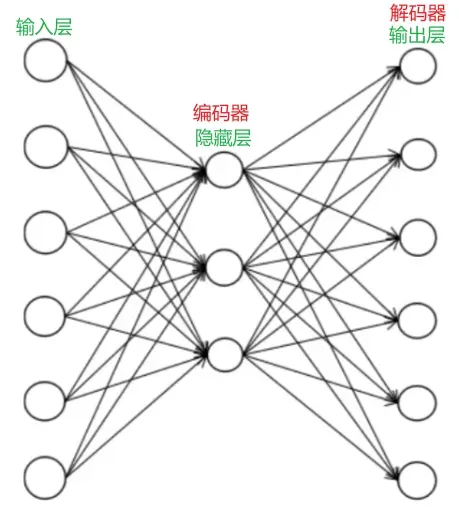
AE 是一种特殊的神经网络,用于特征提取和数据降维。最简单的自动编码器由一个输入层,一个隐含层,一个输出层组成。隐含层的映射充当编码器,输出层的映射充当解码器。
训练时编码器(隐藏层)对输入向量 解码器(输出层)对编码向量
训练完成之后,在预测时只使用编码器而不再需要解码器,编码器的输出结果被进一步使用,用于分类,回归等任务。

如果 公式3:
2.3.3 Variational Auto-Encoder VAE 变分自动编码器
变分自动编码器是一种深度生成模型,用于生成图像,声音等的数据,类似于 GAN 生成对抗网络。变分自动编码器和自动编码器有很大的不同,二者的目的完全不同。
考虑数据生成问题,比如写字,写出MNIST数据集这样的手写数字


如果先收集训练样本,然后让算法原样输出样本(写字),生成的样本没有多样性。解决思路如下:

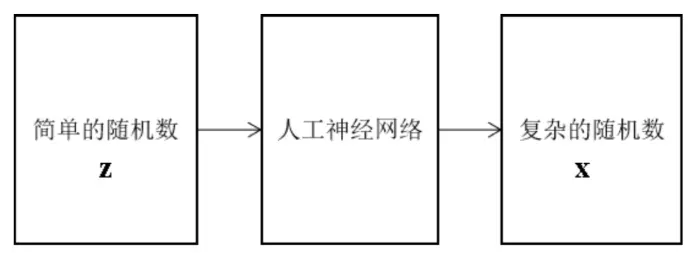
简单的随机数的生成:首先从文字图像中学习特征,然后对特征进行随机扰动,生成新的样本。变分自动编码器采用了该思路。其结构如下图所示:

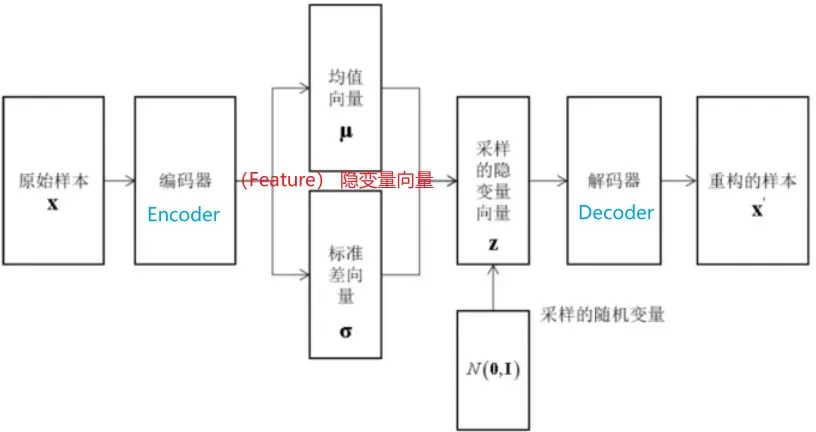
编码器和解码器同时训练,训练时的目标为公式4的右端:
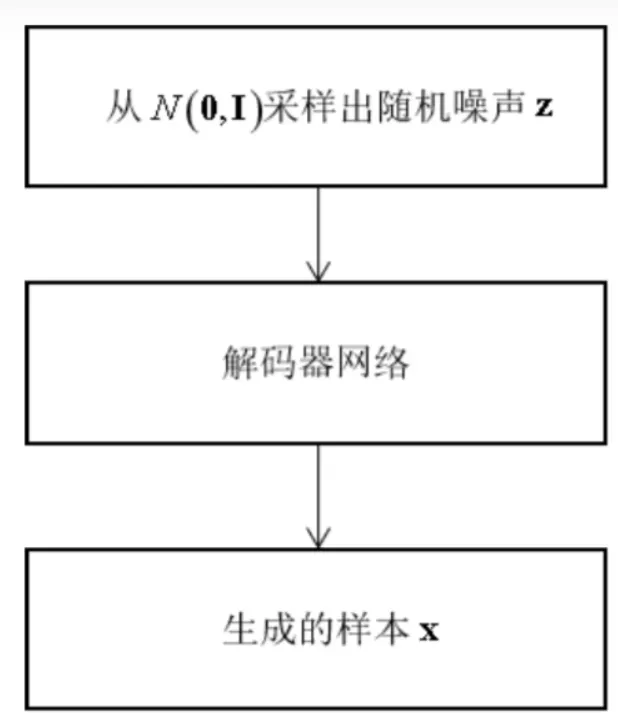
训练完成之后,预测阶段可以直接生成样本。首先,从正态分布

2.3.4 密集预测-全卷积网络
图像分割的目标是确定图像中每个像素属于什么物体,即对所有像素进行分类,是一个逐像素预测的密集预测问题。
卷积网络 CNN 的不足:(1)在进行多次卷积和池化后会缩小图像的尺寸,最后的输出结果无法对应到原始图像中的每一个像素。(2)卷积层后面接的全连接层将图像映射成固定长度的向量,与分割任务不符。
全卷积网络 FCN 的优点:(1)采用反卷积运算,从前面的卷积特征图像中得到与原始输入图像尺寸相等的输出图像。(2)去掉了卷积神经网络中的全连接层,用卷积代替。
全卷积网络 FCN 从卷积特征图像预测出输入图像每个像素的类别。网络能够接受任意尺寸的输入图像,并产生相同尺寸的输出图像,输入图像和输出图像的像素一一对应。这种网络支持端到端、像素到像素的训练。
FCN的前半部分是卷积层和池化层,充当编码器,从输入图像中提取特征。网络的后半部分是反卷积层,充当解码器,从特征中解码出结果图像。典型的网络结构如下图所示


SegNet语义分割网络 的前半部分是编码器,由多个卷积层和池化层组成。网络的后半部分为解码器,由多个上采样层和卷积层构成。解码器的最后一层是softmax层,用于对像素进行分类。

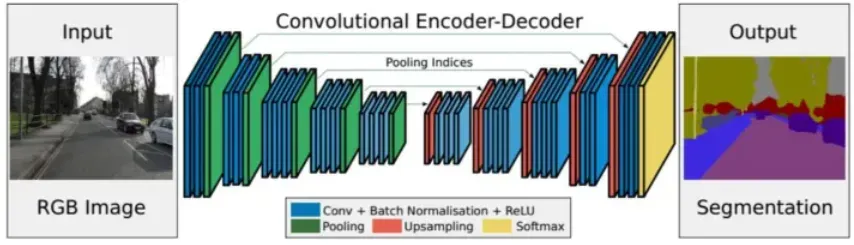
其中,编码器网络的作用是产生有语义信息的特征图像;解码器网络的作用是将编码器网络输出的低分辨率特征图像映射回输入图像的尺寸,以进行逐像素的分类。
2.3.5 序列到序列学习
有些问题输入序列和输出序列的长度不一定相等,而且输出序列的长度未知。
比如,机器翻译,将一种语言的句子翻译成另外一种语言之后,句子的长度即包括的单词数量一般是不相等的。英文 ”what’s your name” 是3个单词组成的序列,翻译成中文 “你叫什么名字”,是4个汉字词组成的序列。
标准的RNN无法处理这种输入序列和输出序列长度不相等的情况,解决这类问题的一种方法是序列到序列学习 Sequence to Sequence Learning,简称 seq2seq 技术。
seq2seq 框架包括两部分,分别称为编码器和解码器,它们都是循环神经网络。这里要完成的是从一个序列到另外一个序列的预测(映射):
编码器网络接受输入序列,把最后时刻 解码器网络每一时刻的输入值为
对于机器翻译而言,编码器依次接收源语言句子的每个词,到 eos 为止,最后得到语义向量 解码器首先输入 bos,即句子的开始,根据 bos 和

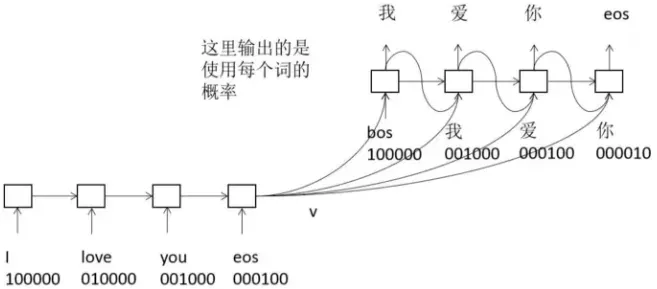
2.3.6 CNN与RNN的结合
FCN 是 CNN 和 CNN 的结合,seq2seq 是 RNN 和 RNN 的结合。
在编码器-解码器框架中,CNN和RNN可以结合,形成编码器-解码器架构,两者可灵活组合用于各种不同的任务。
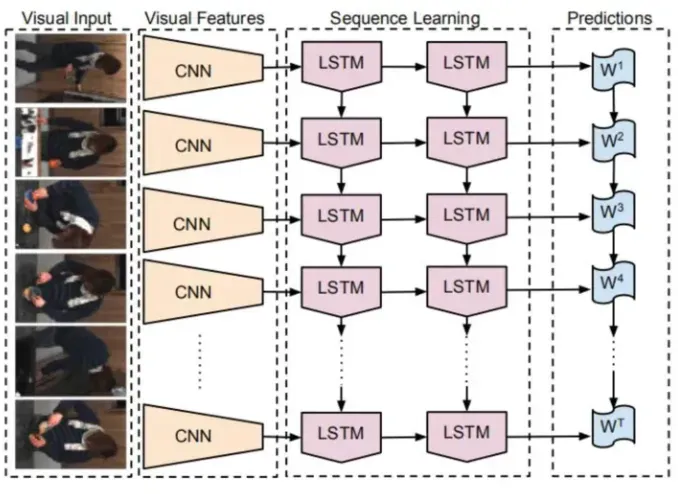
2.3.6.1 从图像到文字
从图像到文字的映射,是指为图像或视频生成文字解说。
(1)CNN 是编码器,用于提取出图像的语义特征。
(2)RNN是解码器,其输入为图像的语义特征,输出不固定长度的文字序列。结构如下图所示:

2.3.6.2 从文字到图像
用循环神经网络和深度卷积生成对抗网络可以将一段文字生成图像,将视觉概念从文字变成像素表示。如下图所示:


和机器翻译类似,采用编码器-解码器框架。
(1)通过一个 CNN 和一个 RNN 将文本转换成向量(文本的语义信息)输出,该输出和图像对应。
(2)在生成的文本向量基础上训练一个生成对抗网(深度卷积网络),负责生成图像。生成对抗网实现的映射为:
3. 其他
- Transformer中,
编码器在训练和测试时并行工作;解码器在训练时并行,测试时串行。Attention,参考Encoder-Decoder
文章出处登录后可见!