

前段时间接触了一些目标跟踪的场景,本文主要汇总目标跟踪的常用评估指标,主要包括下面几类:
容易理解的概念:FP、FN、TP、id switch、ML、MT
更加综合的概念:MOTA、IDF1、MOTP、HOTA
主要的介绍集中在HOTA,因为这个评估指标比较新,我能看到的讲解都比较少一点,所以展开详细介绍一下。这个评估指标在2021年提出就迅速被采用,可见其综合评估能力强悍。
受限于篇幅,关于MOTA实际使用时需要的GT格式、预测格式以及测试代码,另外开一篇文章详细展开。
码字不易,多多鼓励,这些内容多是基于自己的学习理解,如有错误,欢迎理性探讨~
一、基本的概念
目标框Det:
针对检测任务而言,每帧都会检测到目标框predDet,对于行人任务来说,目标框就是行人。groundTruth中(GT)也会记录每帧的目标框gtDet。
轨迹track:
多帧中属于同一个人的目标框连接起来就构成了这个人的轨迹,每个人的轨迹都有独一无二的轨迹编号(track id)。在gt中,一条轨迹由track id和每帧中的属于该轨迹的目标框构成。在预测过程中,不同帧中的目标框会根据该跟踪算法的分析被匹配到不同的pred track id中,预测的track id和gt中的track id并不一定完全相同,且有可能因为检测效果不佳或者跟踪算法不佳,一条gt track可能被分成多条pred track,也可能产生跟踪的丢失等情况。
匹配(match):
在指标评估阶段,提到匹配,表示目标框的匹配和轨迹的匹配,按照不同的语义进行区分理解。
目标框的匹配只针对单帧中的目标检测任务而言。对于每一帧检测到的目标框predDet,评估算法通过IOU或者其他度量算法(这个具体怎么计算由评估指标决定,一般是通过IOU),与GT中的gtDet进行一对一的匹配。比如下面会提到的单一评估指标中的TP指标( True positive),用于统计每一帧中满足匹配关系的(gtDet,predDet)数量总和。这里不考虑该predDet的轨迹是否和gtDet的轨迹一致的问题,只是单纯的考虑在这一帧中predDet-gtDet是否满足IOU大于阈值。这里可以理解为这个指标是用于评估这套检测跟踪算法的检测误差的。
轨迹的匹配是针对预测轨迹和真实轨迹的匹配的。比如一条pred track通过评估算法被匹配到一条GT track,虽然他们的track id不同,目标框的定位在每帧中也不一定完全一致(可能存在检测模型的定位误差),但是这两条轨迹被认为是匹配的。
关联(Association):
目标框-轨迹级别的关系称为关联,将一组prDets分配相同的ID并认为他们被关联到了相同的轨迹上。匹配是同一级别之间的,比如目标框和目标框之间,轨迹和轨迹之间;而关联是目标框和轨迹之间的;这两个概念不要搞混。
错误类型概述
直观上来看,主要的错误类型可以分为三类,检测误差、定位误差和关联误差。
检测误差有两种情况,GT中应该有的box,预测结果中不没有;GT中没有的box,预测结果中出现了。
定位误差是predbox的位置没有和gtDetbox对齐好。
关联误差有两种情况,给两个不属于同一个轨迹的predDet赋予了相同的predID;给两个属于同一个轨迹的predDet赋予了不同的predID.
2013年一篇评估指标研究报告分析在多目标跟踪任务中存在五种error type,分别是False negatives, False positives, Fragmentation, Mergers and Deviation。
对于模型的开发者来说,单一的指标比如false negtive rate,false positive rate,fragmentation,mostly-tracked,mostly lost,partially-tracked这些指标可以在调试的时候找到模型的瓶颈和优化点;但是对于终端用于也就是模型的调用者来说,需要一个唯一的均衡评估的指标来帮助判断,从众多模型中选择最佳的模型来应用。
二、单一的评估指标
属于检测误差的指标如下:
FP: false positive,表示GT中不存在的目标框,但是预测得到了该目标框;于是这个目标框是误判的。
FN: false negtive,表示GT中存在目标框,但是预测没有可以和GT匹配的目标框;于是是漏检的,也就是真实GT被miss了。
TP: True positive,表示GT中存在这个目标框,预测有可以和这个GT匹配的目标框,他们构成了一个TP对(predDet,gtDet)。这里不考虑pred的轨迹是否和GT的轨迹一致的问题。只是单纯的考虑是否构成了一对prBox-gtBox的匹配。
属于关联误差的指标如下:
id switch:
目标框的track ID跳变的情况,这发生在真实的轨迹trackA可能因为遮挡或者重合,导致的预测track ID跳变或者消失一段时间后重新分配一个ID的情况。这样的结果是一个gt track在预测中会存在多个pred track_id。
注意:
IDSW的概念是针对TP来说的,一个匹配(prDet和gtDet),从已经知道GT的旁观者角度来看,对于gt trackA,如果当前帧上匹配的prID和前一帧上该trackA被分配的prID不一样,那么认为trackA的id产生了一次跳变,id_switch+1。一帧上可能存在多个轨迹的跳变,记录所有时间帧上的所有跳变的总和为IDSW。显然我们希望跟踪模型稳定,因此需要这个值尽量的小。
IDSW只和前一帧上的该gt trackA的对应的TP有关,和更久之前的id变换无关。
消失一段时间后重新分配一个ID的情况只会记录一次IDSW,因为IDSW只发生在TP上,不发生在FN上。举个例子,如果gt trackA在前一帧的目标框是缺失的,那么这种情况属于检测误差中的FN,n那么在上一帧中就没有该gt trackA的TP,所以不会有id switch+1.只有到当前帧,该轨迹的目标框重新出现,评估者发现了该轨迹的pred track id产生变化,因此才会有id switch+1.
ML( Mostly Lost)
表示的是满足Ground Truth在小于20%的时间内匹配成功的track,在所有追踪目标中所占的比例。
MT(Mostly Tracked)
表示的是满足Ground Truth在至少80%的时间内都成功匹配的track,在所有追踪目标中所占的比例。
FM(Fragmentation)
FM计算的是跟踪有多少次被打断,也就是Ground Truth的track没有被匹配上,换句话说:每当轨迹将其状态从跟踪状态变为未跟踪状态,并在稍后跟踪上相同的轨迹时,就会对FM进行计数。
关于定位误差的指标
定位相似度指标是在目标检测级别的,一般对于2Dbox/3D box和分割mask任务来说,会采用IOU指标,这个指标就不做具体展开了,在目标检测领域很常用,范围在[0-1]之间
三、综合的评估指标
综合的评估指标会考虑更多的因素。评估指标的最终目的是为获得pred轨迹集合和GT轨迹集合的相似度,这并不是一个定义良好的问题,有很多不同的方式来计算相似度(毕竟这是计算两个连续轨迹集合的相似度)。这个指标的设计很重要,指标决定了不同的错误相对于最终得分的贡献度。部分指标会有不同的偏好,比如MOTA偏向于检测指标,因为竞赛benchmark(也就是刷榜)采用这类指标,这就会引导开发者将模型开发的重点移动到评估指标的侧重项上,因此选择一个均衡评估的指标是很有必要的,可以改善行业发展方向。(上述内容引用自论文HOTA的个人翻译)
MOTA
MOTA指标是针对上面提到的FN,FP,IDSW指标的一个综合,具体的公式如下:

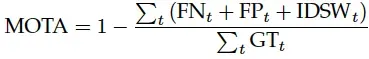
GT为一帧上的所有GTbox的数量。
那么mota指标综合考虑轨迹中的FN、FP、IDSW的现象。如果错误的情况较多,那么MOTA的值可以小于0.
这个评估指标比较依赖于目标检测的性能,同时对于ID跳变只关注跳变的次数,没有关注到id的准确性。
比如下面这段10帧的gt和两段track(假设对应框bbox都完美对应没有FN和FP,这里仅显示ID信息)
truth :1-1-1-1-1-1-1-1-1-1
track1:1-1-2-2-3-3-4-4-5-5
track2:1-1-2-2-1-1-2-2-1-1
其MOT指标计算结果都是0.6,但是track2的表现会更加好一点。这种情况需要采用IDF1指标来进行补充。
IDF1指标
IDF1指标是2016年提出的,最开始应用于多路摄像头多目标跟踪任务的评估,目前在单路摄像头任务的评估中也广泛使用,这个指标只要用于评估检测框和轨迹关联的准确性,这弥补了MOTA过于重视目标检测准确性的缺陷。
MOTA主要评估的FP,FN都是在考虑检测级别的性能度量。IDF1主要在轨迹级别进行一对一的匹配。这样就会衍生出新的概念
IDTP:(这部分内容先略过,国内的博客解析的不是那么清晰,我去看看论文再尝试自己讲解一下)
IDFP
IDFN
中的TP、FP、FN这些指标,是考虑进ID信息的,而MOTA中仅IDSW项考虑了ID信息。从这个角度讲,IDF1对轨迹中ID信息的准确性更敏感。

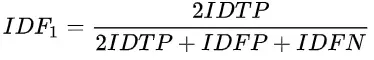
MOTP指标
MOTA主要评估的是检测能力,但是没有评估定位能力(localization),MOTP作为补充主要评估的位置误差的一个指标。需要注意的是,这个指标只在TP上进行。
dti表示t帧上的第i个匹配(目标框级别的匹配)的定位精度,这个值一般是越大表示精度越高。
ct表示t帧上的总匹配数量。


4. HOTA指标
2021年新发布的一个多目标跟踪评估指标。这个指标可以是一个均衡考虑检测准确率、匹配准确率,定位准确率的单一指标,也可以拆分为5个单独的sub-metrics,每个子指标单独的评估某个方面的性能。
一个好的均衡评估的指标需要可以同时兼具两个特点,一个是单调性,另一个是每种error type的可微分性。这两个特性在HOTA之前,并没有其他的指标可以拥有。而HOTA可以分解为decompose下面的五个sub-metrics,这五个指标很好的评估了上面提到的五个error-type.分别是Detection Recall, Detection Precision,Association Recall, Association Precision和Localisation Accuracy。同时证明HOTA对于这五个指标来说都是严格单调。
4.1 符号定义
gtDets/prDets:真实的目标框/预测目标框
gtIDs/prIDs:真实track id/预测track id
gtTraj/prTraj:真实轨迹/预测轨迹。无论是真实轨迹还是预测轨迹都具有唯一的gtID或者prID
gtCL/prCL:真实类别/预测类别。常用于多类目标跟踪的场景,这里先不做展开。
匹配的规则,同一帧上的一对一匹配(bijective matching),每个gtDets最多匹配一个prDet,匹配规则至少需要满足gtDet和prDet的overlap大于指定的阈值$\alpha$,匹配的目标函数是通过分配算法(往往是匈牙利算法)使得匹配的分数最高。
4.2 HOTA中涉及的统计概念
HOTA指标在涉及到detection level上的一些概念都和MOTA中的概念定义保持一致,比如TP,FN,FP。相比于MOTA着重关注于检测上的误差,HOTA在评估关联关系(association)的时候,需要引入新的概念:
4.2.1 TPAs (True Positive Associations):
首先需要明确,TPA是一个集合的概念,更进一步的TPA中保存的是TP的集合,并且一个TPA是针对一个特定的TP来说的、和它相关的其他TP的集合。
具体来说,如果一个视频中统计存在20个TP(真实视频的TP数量远超这个),对于每个TP都会有一个TPA集合,那么这个视频就会有20个TPA集合。前面提到,一个TP是一个匹配的(predDet,gtDet)对,其中的predDet会有一个关联轨迹的prID,其中的gtDet也会有对应的轨迹gtID,那么对于一个TP来说,就绑定了四个概念(prDet,gtDet,prID,gtID)。对于一个指定的TP对,我们用符号c来表示,它的TPA集合中保存了满足下面要求的其他帧中的TP:
拥有和c相同的prID
拥有和c相同的gtID
也就是说,在其它帧中和该TP属于相同的真实轨迹ID(gtID相同)和相同预测prID的TP的集合。


为啥是其他帧,而不是当前帧,这是因为在当前帧中gtID和predID都是唯一分配的。这个概念应该可以理解吧,属于一个人的轨迹不可能在同一帧中出现在两个地方,毕竟不是量子跟踪……
4.2.2 FNAs (False Negative Associations):
对于一个TP(prDet,gtDet)来说,用标志c来表示,他的FNA表示两类集合:
(1)和c拥有相同的gtID(c),但是预测目标框分配了不同的prID的TP的集合:也就是原本属于同一条轨迹的两个匹配被分配在不同的预测轨迹上。
(2)FN数据,也就是目标检测漏检的目标框的集合


4.2.3 FPAs (False Positive Associations):
对于一个TP,用标志c来表示,他的FNA表示两类集合:
(1)和c属于相同的prID(c)的TP对,但是其中的gtDet对应的gtID是不同的: 也就是原本是两个不同轨迹上的匹配框被分在了一个轨迹上。
(2)FP集合,也就是目标检测多检测到的目标框的集合

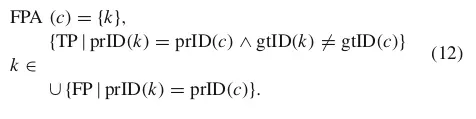
这样我们就已经了解了六个概念: 检测相关的TPs, FPs, FNs以及和association相关的TPAs, FPAs, FNAs。
4.3 理解和公式
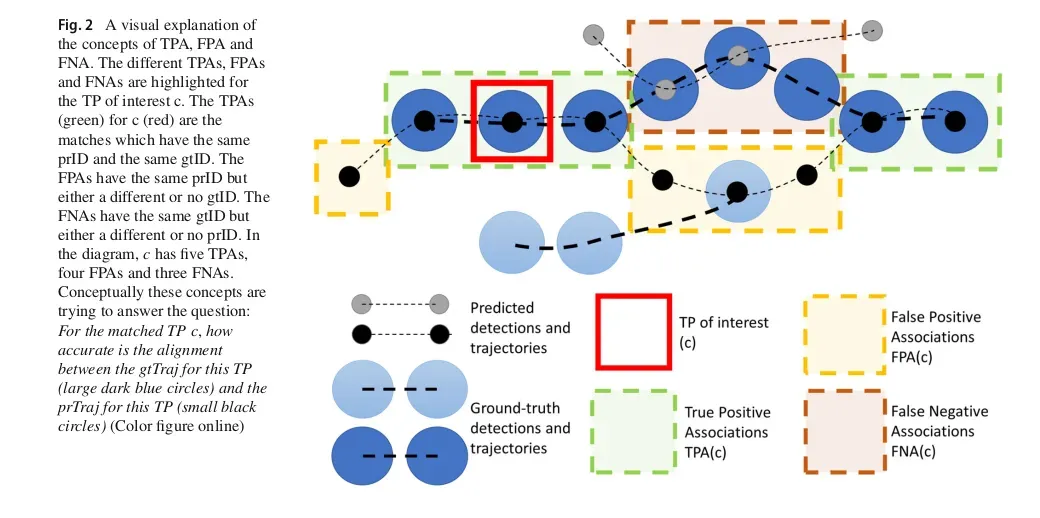
用下面这张图来实际理解一下这些概念,这张图足以描述比较复杂的真实情况了:其中蓝色圆圈圈表示真实的轨迹,这里一共有两条真实轨迹。实心黑色小圈和灰色小圈构成预测的轨迹,这里有两条预测的轨迹。
再次重申,上面的TPAs, FPAs, FNAs概念都是针对一个指定的TP来说。
比如针对下图中红色矩形的TP来说,他的TPAs是绿色虚线框部分的TP(predDet、gtDet)对,这些匹配TP拥有相同的predID和gtID(属于同一条轨迹);
棕色虚线框框表示FNAs集合,因为这些TP虽然和红色框的TP具有相同的gtID,但是预测的prID却不同(被预测成别的轨迹上的匹配了),或者是被漏检了(FN);
黄色虚线框表示FPAs,因为他们被预测成和红色矩形框具有相同的prID,但是真实并不属于同一条轨迹;或者是检测器多检测了一个不存在的目标框(最左边的那个目标框).

因此对于每个TP来说,都可以计算下面的association scores公式。

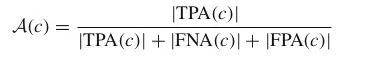
那么将所有的TP都计算一下这个公式,并统计所有时间帧中的TP,FN,FP,就可以得到HOTA的公式了。比如上图中的TP有8个,那么就分别计算每个TP的A(c)值,然后综合起来就可以得到HOTA值。


其中的alpha表示定位阈值,在目标检测之后,我们通过IOU等指标进行prbox和gtbox的匹配,需要满足的基本条件就是prbox和gtbox的IOU不能低于alpha。
在上述的计算中,我们可以看到一个参数alpha.这个参数是超参数,将这个参数从0.05开始每次递增0.05直到0.95,就可以得到19个不同超参情况下的HOTA指标。其平均值就是最终的HOTA指标。

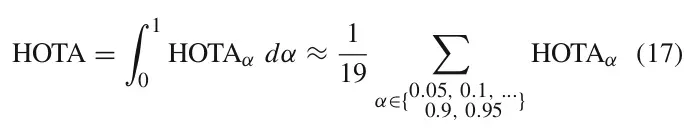


如果只是希望理解HOTA指标的含义,那么到上面为止已经介绍了HOTA公式中每个元素的含义了。在上述的定义中,所有检测框prDet和真实框gtDet都是一一对应的,符合bijectively matched原则。
4.4 一点延伸
在实际的操作中,开发者希望可以最大化HOTA指标,会采用另一个指标,这个指标不会严格要求bijectively matched原则。这里先看一下公式,下面会详细展开每个符号的含义。

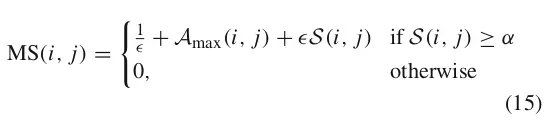
MS指标可以同时满足三个要求:
1. 最大化TP的数量
2. 最大化association scores的均值
3. 最大化定位的相似度localisation similarity(也就是最小化位置上的偏差)的均值
上述公式中的epsilon是一个很小的参数;
S(i,j)表示gtDet i和prDet j之间的定位相似度localisation similarity。其中的$\alpha$依旧是一个超参数。
Amax(i,j)表示在不需要满足bijectively matched条件的下的最大化association scores:

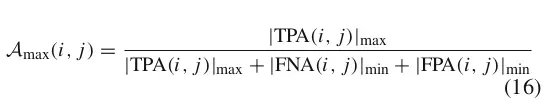
这个公式和上面提到的A(c)计算公式很像,只是下标变为了max,原本的用于表示一对一匹配的TP的符号c也变成了(i,j)。
具体介绍每个参数的含义
|TPA(i, j)| max:表示对于(gtDet_i,prDet_j)这对匹配TP来说,在不需要满足bijectively match情况下,它的最大TPA值。举个例子,在其他帧中,如果一个gtDet_m和一个predDet_n,满足如下三个条件
1. S>alpha
2. gtDet_m对应的gtID和gtDet_i的gtID相同
3. predDet_n对应的prID和prDet_j的prID相同
但是在bijectively match匹配中,也就是我们上面基础概念中提到的匹配,比如采用了IOU匹配指标,那么可能因为prDet_n有相似度更高的gtDet可以匹配,gtDet_m也有相似度更高的prDet可以匹配,于是并没有被认为是一个TP。那么在这里的|TPA(i,j)|_max中则会认可这种TP关系。
那么所有满足上述要求的帧数就是上述公式中计算的 |TPA(i, j)| max.
另外的两个参数也是类似的逻辑。那么可以认为对于每个匹配(i,j)来说,Amax就是association scores指标可以达到的上限。
到这里通用含义上的HOTA指标已经讲完啦。HOTA论文一共31页,讲到这里大概讲到第九页。论文后面的内容是关于HOTA指标拆分过程,他可以拆分为更加基础的指标用于平时训练的局部优化,这里我就不继续展开啦,有兴趣可以参考一下下面的参考文献5,查看具体的论文。
四、参考文章:
[多目标跟踪任务——评价指标](https://blog.csdn.net/qq_42191914/article/details/105057117)
[Multi-Target Multi-Camera Tracking (MTMC Tracking)评价指标](https://zhuanlan.zhihu.com/p/35391826)
[MOT Metrics—MOTA vs IDF1?](https://blog.csdn.net/qq_42191914/article/details/105057117)
[(HOTA)多目标跟踪MOT指标计算方法](https://blog.csdn.net/qq_45091388/article/details/127880003)
[HOTA: A Higher Order Metric for Evaluating Multi-object Tracking](https://link.springer.com/article/10.1007/s11263-020-01375-2)
文章出处登录后可见!