

文章目录
- 快速上手Django(九) -django 上传文件request.FILES,下载文件
- 一、Django下载文件
- 1. Django下载文件方案和思路
- 2. HttpResponse、StreamingHttpResponse和FileResponse区别和选择
- StreamingHttpResponse和FileResponse对象的对比和选择
- 使用HttpResponse
- 使用StreamingHttpResponse
- 生成器函数
- 使用FileResponse
- django 使用FileResponse限制文件下载大小
- 3. postman下载文件请求
- postman报错 Maximum response size reached
- 二、django 上传文件request.FILES
- 三、Django 读取excel里的数据导入到数据库表中(使用第三方库openxl)
- django+xlsxwriter导出excel
- 四、参考
快速上手Django(九) -django 上传文件request.FILES,下载文件
一、Django下载文件
在实际的项目中很多时候需要用到下载功能,如导excel、pdf或者文件下载。
1. Django下载文件方案和思路
- 将文件作为响应返回给用户:这是最常用的下载文件方法。你可以编写一个视图函数,在该函数中将文件作为响应返回给用户。
- 使用第三方库,如您需要支持断点续传或并发下载等功能,则 django-downloadview 库
最常见和主流的下载文件方式是将文件作为响应返回给用户。这种方法简单易行,可以在 Django 中轻松实现,并且可用于绝大多数情况。
2. HttpResponse、StreamingHttpResponse和FileResponse区别和选择
Django 提供三种方式实现文件下载功能,分别是:HttpResponse、StreamingHttpResponse和FileResponse
- HttpResponse 是所有响应的核心类,它的底层功能类是HttpResponseBase。
- StreamingHttpResponse 是在HttpResponseBase 的基础上进行继承与重写的,它实现流式响应输出(流式响应输出是使用Python的迭代器将数据进行分段处理并传输的),适用于大规模数据响应和文件传输响应。
- FileResponse 是在StreamingHttpResponse 的基础上进行继承与重写的,它实现文件的流式响应输出,只适用于文件传输响应。
HttpResponse 实现文件下载存在很大弊端,其工作原理是将文件读取并载入内存,然后输出到浏览器上实现下载功能。如果文件较大,该方法就会占用很多内存。对于下载大文件,Django推荐使用StreamingHttpResponse 和FileResponse 方法,这两个方法将下载文件分批写入服务器的本地磁盘,减少对内存的消耗。
StreamingHttpResponse和FileResponse对象的对比和选择
StreamingHttpResponse对象需要一个生成器函数来按需生成要发送的数据块。FileResponse对象支持直接读取文件并以块的形式生成响应数据。
由于FileResponse对象使用Python内置的文件迭代器进行分块传输,因此它对文件大小有一定的限制(默认情况下为django.http.response.FILE_CHUNK_SIZE配置)。如果您需要传输超过该限制的文件,则需要使用StreamingHttpResponse对象进行流式传输。
使用HttpResponse
使用HttpResponse
import os
from django.http import HttpResponse
def download_file(request):
file_path = '/path/to/my/file.txt'
if os.path.exists(file_path):
with open(file_path, 'rb') as f:
file_data = f.read()
response = HttpResponse(file_data, content_type='application/octet-stream')
response['Content-Disposition'] = 'attachment; filename="{}"'.format(os.path.basename(file_path))
return response
else:
return HttpResponse("Sorry, the file you requested does not exist.")
设置content_type和Content-Disposition头文件以指示浏览器将文件作为附件下载。
使用HttpResponse对象读取整个文件并将其存储为内存中的字符串,这意味着对于大型文件可能会消耗大量的内存资源。如果您需要下载大文件,可能需要使用其他更高级的技术,例如流式传输或分块下载。
由于本地文件路径可以被注入攻击者的恶意代码,因此必须小心处理。确保仅允许下载特定目录中的文件。
总结:下载大文件时,该方法不太适用!
使用StreamingHttpResponse
使用StreamingHttpResponse对象可以解决使用HttpResponse下载大型文件时内存消耗过高的问题。与HttpResponse不同,StreamingHttpResponse不会一次性将整个文件加载到内存中,而是将数据流式传输到客户端。
import os
from django.http import StreamingHttpResponse
def download_file(request):
file_path = '/path/to/my/file.txt'
if os.path.exists(file_path):
def file_iterator(file_path, chunk_size=8192):
with open(file_path, 'rb') as f:
while True:
chunk = f.read(chunk_size)
if not chunk:
break
yield chunk
response = StreamingHttpResponse(file_iterator(file_path))
response['Content-Disposition'] = 'attachment; filename="{}"'.format(os.path.basename(file_path))
return response
else:
return HttpResponse("Sorry, the file you requested does not exist.")
StreamingHttpResponse 支持数据或文件输出,因此在使用时需要设置响应输出类型和方式。
我们创建了一个名为file_iterator的生成器函数,它将文件分成小块(默认大小为8KB)并以流式方式发送给客户端。然后,我们使用StreamingHttpResponse对象生成响应,并设置content_type和Content-Disposition头文件以指示浏览器将文件作为附件下载。最后,我们返回StreamingHttpResponse对象。
生成器函数
生成器是一种特殊类型的函数,在Python中通常用于逐步生成数据序列,而不是一次性生成整个序列。
生成器函数与普通函数的区别在于它们使用yield语句返回值而不是return语句。
当一个函数执行到yield语句时,它会暂停执行并将结果返回给调用者。下次调用该函数时,它会从上次停止的地方继续执行,直到再次遇到yield语句或函数结束为止。这样可以逐步生成数据,并避免一次性加载大量数据到内存中。
def my_generator():
for i in range(10):
yield i * 2
for x in my_generator():
print(x)
在这个例子中,my_generator()是一个生成器函数,它会生成0到18之间的偶数。在主循环中,我们通过迭代生成器来逐步生成数据并打印每个值。
总结,生成器函数是一种能够在需要时逐步生成数据的Python函数。当您需要处理大型文件或数据时,生成器函数非常有用,因为它们可以在需要时按块生成数据,并且可以避免一次性加载大量数据到内存中。
使用FileResponse
使用FileResponse对象可以有效地传输大型文件,并且它还提供了自动支持断点续传和范围请求等HTTP协议特性。
import os
from django.http import FileResponse
def download_file(request):
file_path = '/path/to/my/file.txt'
if os.path.exists(file_path):
response = FileResponse(open(file_path, 'rb'))
response['Content-Type'] = "application/octet-stream"
response['Content-Disposition'] = 'attachment; filename="{}"'.format(os.path.basename(file_path))
return response
else:
return HttpResponse("Sorry, the file you requested does not exist.")
设置content_type和Content-Disposition头文件以指示浏览器将文件作为附件下载。
设置了响应内容的 MIME 媒体类型为 “application/octet-stream”。这是一个用于任意二进制数据的二进制文件格式,并且表示响应内容应该被视为原始字节流。它被使用是因为返回作为响应的文件可以是任何类型的二进制文件,例如图像或文档。通过将内容类型设置为 “application/octet-stream”,浏览器会提示用户保存或打开文件,而不是尝试在浏览器窗口中显示它。
使用FileResponse对象时,Django会自动检测客户端是否支持范围请求(即断点续传),如果支持,它将启用自动断点续传功能。这意味着当用户暂停或取消下载时,他们可以在后续下载时从上次停止的地方继续。
django 使用FileResponse限制文件下载大小
思路:在创建 FileResponse 实例时设置 content_range 参数
file_path = '/path/to/file'
file_size = os.path.getsize(file_path)
max_size = 10 * 1024 * 1024 # 10 MB
if file_size > max_size:
content_range = 'bytes=0-{0}'.format(max_size - 1)
else:
content_range = None
response = FileResponse(open(file_path, 'rb'), content_type='application/octet-stream', content_range=content_range)
在上面的代码中,首先获取文件的大小,然后将最大大小设置为 10 MB。如果文件大小超过了最大大小,就将 content_range 设置为 ‘bytes=0-{max_size-1}’,表示只传输前 10 MB 的数据;否则,将 content_range 设置为 None,表示传输整个文件。
3. postman下载文件请求

在Postman中,”Send”按钮和”Send and Download”按钮发送的HTTP请求是相同的,它们只有在处理响应时的行为不同。
“Send”按钮只会在响应窗格中显示响应内容,而”Send and Download”按钮会将响应体直接下载到本地计算机。
在Postman中,”Send”按钮将发送请求并在响应窗口中显示响应内容,而”Send and Download”按钮将发送请求并直接下载响应体(如文件)。
如果您使用”Send”按钮发送请求,并且响应内容是文件,则该文件的内容将显示在响应面板中。 如果您希望下载该文件以在本地计算机上查看或处理它,则可以右键单击响应面板中的文件内容,然后选择“Save Response”选项来保存该文件。
相比之下**,如果您使用”Send and Download”按钮发送请求,则响应体将直接被下载到您的本地计算机,而不会在响应面板中显示。这种方法更适合下载大型文件或二进制数据等非文本数据。**
postman报错 Maximum response size reached
遇到了这个错误:
Error: Maximum response size reached
这是因为返回的信息太大了,超过了postman设置,
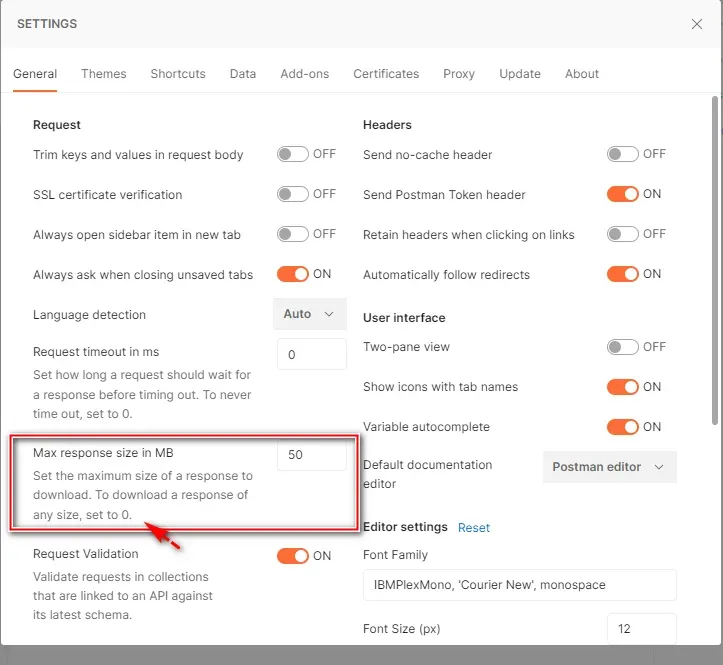
如上,我们可以把它设置为0,不限制。

二、django 上传文件request.FILES
Django在上传文件数据时,文件数据会被放置在request.FILES中。
注意:request.FILES只有在请求方法为POST,并且提交请求的具有enctype=”multipart/form-data”属性时才有效。否则,request.FILES将为空。
request.FILES是一个字典对象,包含所有上传文件,字典的Key是表单类的字段,默认Key是”file”。
request_file = request.FILES['file']
从request.FILES拿到文件是
class ‘django.core.files.uploadedfile.InMemoryUploadedFile 类的实例。InMemoryUploadedFile是一个文件对象的包装器。您可以使用InMemoryUploadedFile类的file属性访问文件对象。
file_in_memory # <InMemoryUploadedFile: xxx (xxx/xxx)>
file_object = file_in_memory.file
为了避免read()方法一次性读到内存中造成内存不足的问题,使用f.chunks()方式将文件分块处理。
三、Django 读取excel里的数据导入到数据库表中(使用第三方库openxl)
从Excel表批量导入数据到Django的数据库中一定要注意2条:
-
校验数据,因为Excel表格里的数据没有约束,经常会出现数据不符合数据表字段约束条件的情况,若不校验会导致大量数据读出来以后存数据库时报错,导致写进数据库的操作失败!
-
批量导入一定要开启事务。开启事务的批量导入有2个特点:要么全部导入成功,要么全部导入失败。
django+xlsxwriter导出excel
Xlsxwriter 使用 FileResponse类返回。
四、参考
Django实现excel导入导出
参考URL: https://blog.csdn.net/inteligent7/article/details/119920673
Django导出Excel文件并下载(前后端)
参考URL: https://www.jianshu.com/p/4d085f2e7a44
文章出处登录后可见!