好久没有使用标注工具了,应工作需要,补一篇,自己实践后,总结如下
1.labelme 简介
labelme 是一款图像标注工具,主要用于神经网络构建前的数据集准备工作,因为是用 Python 写的,所以使用前需要先安装 Python 集成环境 anaconda
2.anaconda 安装
anaconda下载地址如下:
[https://www.anaconda.com/products/distribution]
找到对应自己电脑操作系统位数的版本,直接下载,下载后安装,正常情况下,根据提示,一直 next 就可以,直到提示安装完成
3.labelme 安装
labelme 安装前,需要先创建 anaconda 虚拟环境 labelme,进入 Anaconda Prompt,输入如下命令,该命令表示创建虚拟环境 labelme
conda create -n labelme python=3.8
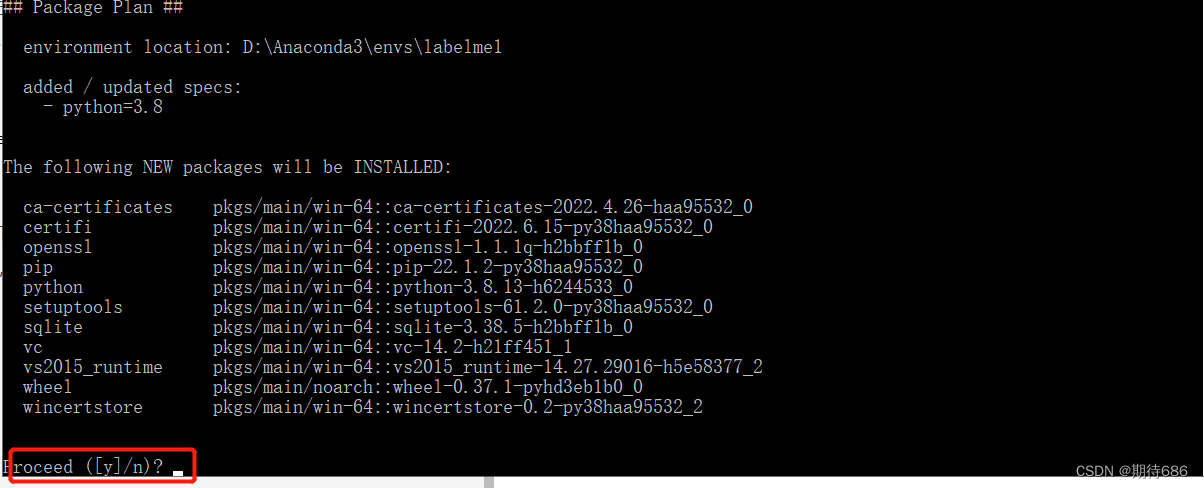
输入如上命令,会运行几秒钟,正式开始创建前,会出现([y]/n)?字样,表示是·否同意创建的意思,输入 y,按 enter,等待运行结束
输入:
conda env list
查看当前已安装的虚拟环境
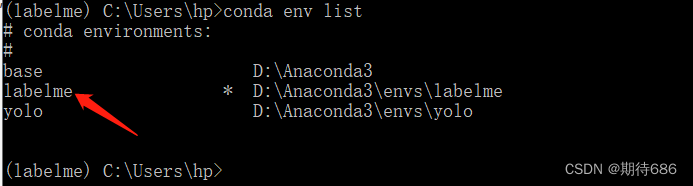
创建好虚拟环境后,需要激活,用如下命令
conda activate labelme
labelme 正常运转需要各种依赖的包,下面的 pypt 和 pillow 就是,它们用如下命令安装
conda install pyqt
conda install pillow
安装好 labelme 依赖的包之后,正式开始安装 labelme,用如下命令,先用 conda 命令,如果安装不成功,则用 pip 命令
conda install labelme=3.16.2
#conda 安装命令如果出错也可以使用 pip 命令,使用逻辑等号"=="
pip install labelme==3.16.2
#也可以直接
conda install labelme
# 或者
pip install labelme
中间有可能会再次出现([y]/n)?,也有可能不出现,玄学,如果出现,则和之前的操作一样,输入y,按下 enter,等待安装结束。如果不出现,运行一段时间后,如果看到有 successfully installed labelme 等字样,则表示安装成功
这一步一定要注意安装的版本号,如果直接安装 labelme 不标注版本号在后续 json 到 dataset 的时候会出现异常,一般来说3.16的版本都可以
4.labelme 使用
以后每次使用 labelme 时,都需要桌面搜索进入 anaconda prompt,用如下命令激活 labelme 环境
activate labelme
用如下命令打开 labelme
labelme
输入如上命令后,会弹出 labelme 操作界面,如下:
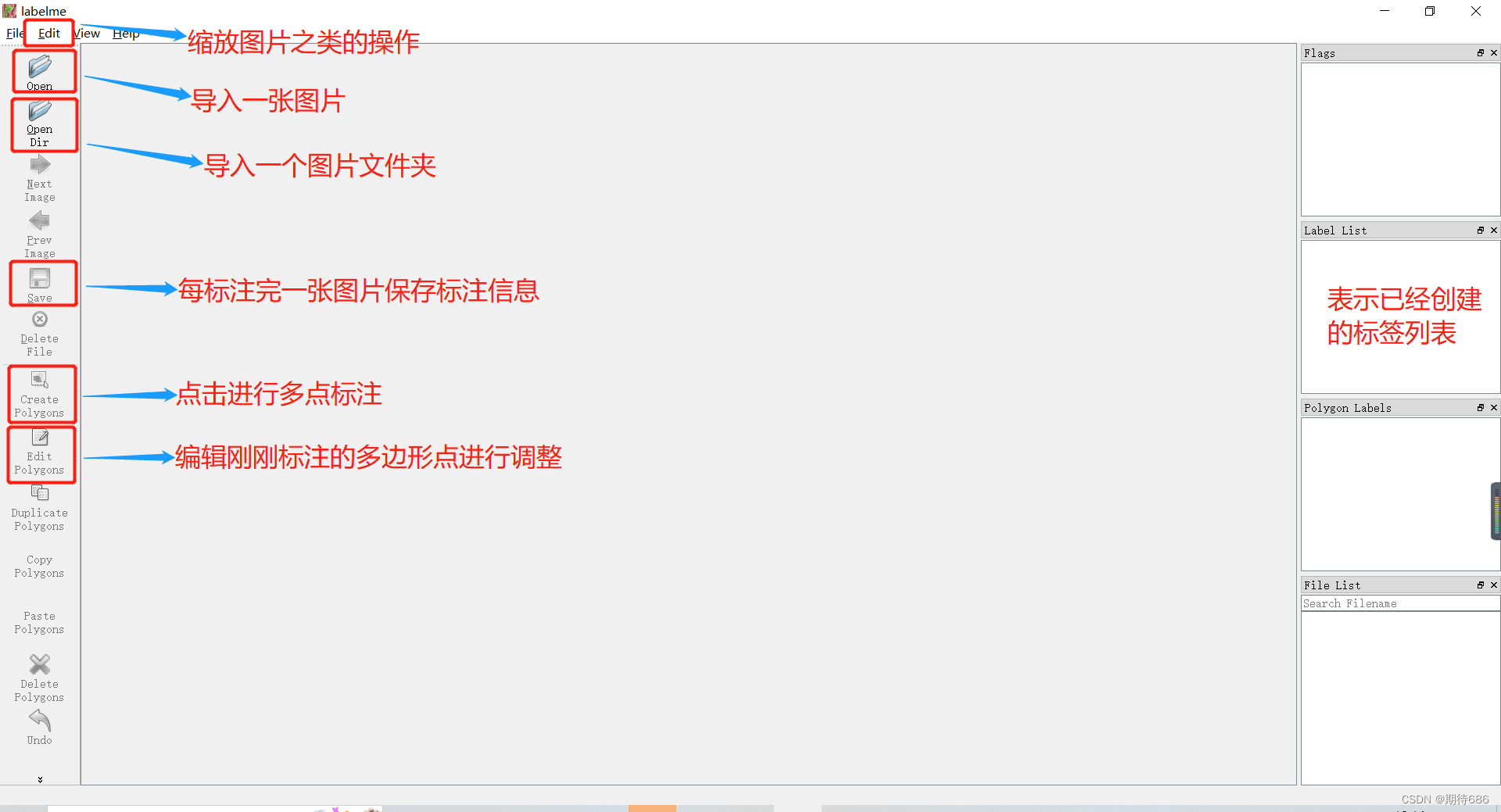
5.图片打标实例
点击 Open Dir,选择待标注图片所在文件夹,批量导入
根据需求,选择圆、矩形、多边形(默认)等开始标注,一般为多边形
一个区域标注完成后,会自动弹出对话框,键入标签名称
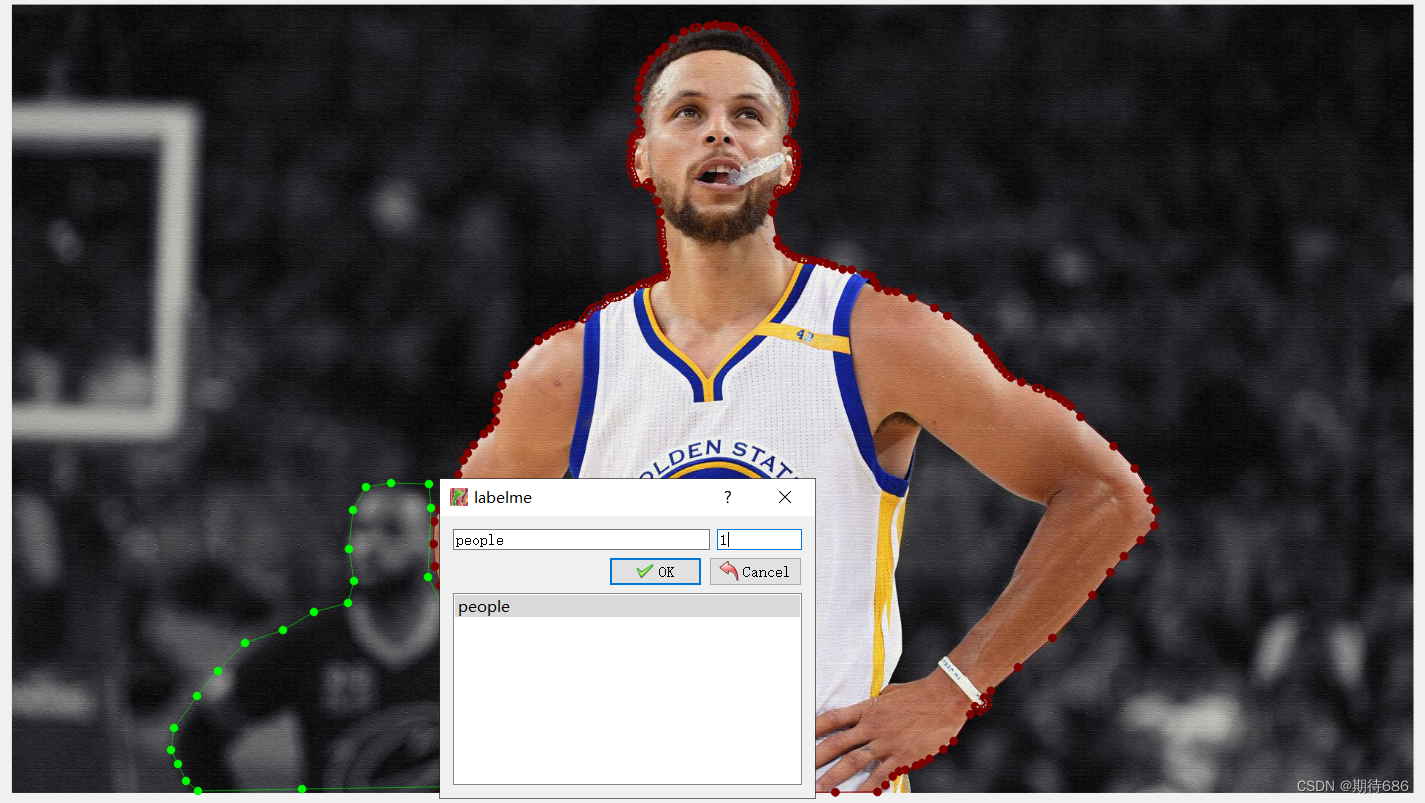
所有区域标注完成后,点击左侧栏 Save,会自动保存对应的 json 数据
生成的 json 文件批量转成我们需要的数据格式
1.找到 json_to_dataset.py 文件,打开,替换为如下代码
import argparse
import json
import os
import os.path as osp
import base64
import warnings
import PIL.Image
import yaml
from labelme import utils
import cv2
import numpy as np
from skimage import img_as_ubyte
# from sys import argv
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
#freedom
list_path = os.listdir(json_file)
print('freedom =', json_file)
for i in range(0,len(list_path)):
path = os.path.join(json_file,list_path[i])
if os.path.isfile(path):
data = json.load(open(path))
img = utils.img_b64_to_arr(data['imageData'])
lbl, lbl_names = utils.labelme_shapes_to_label(img.shape, data['shapes'])
captions = ['%d: %s' % (l, name) for l, name in enumerate(lbl_names)]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(path).replace('.', '_')
save_file_name = out_dir
out_dir = osp.join(osp.dirname(path), out_dir)
if not osp.exists(json_file + '\\' + 'labelme_json'):
os.mkdir(json_file + '\\' + 'labelme_json')
labelme_json = json_file + '\\' + 'labelme_json'
out_dir1 = labelme_json + '\\' + save_file_name
if not osp.exists(out_dir1):
os.mkdir(out_dir1)
PIL.Image.fromarray(img).save(out_dir1+'\\'+save_file_name+'_img.png')
PIL.Image.fromarray(lbl).save(out_dir1+'\\'+save_file_name+'_label.png')
PIL.Image.fromarray(lbl_viz).save(out_dir1+'\\'+save_file_name+
'_label_viz.png')
if not osp.exists(json_file + '\\' + 'mask_png'):
os.mkdir(json_file + '\\' + 'mask_png')
mask_save2png_path = json_file + '\\' + 'mask_png'
################################
#mask_pic = cv2.imread(out_dir1+'\\'+save_file_name+'_label.png',)
#print('pic1_deep:',mask_pic.dtype)
mask_dst = img_as_ubyte(lbl) #mask_pic
print('pic2_deep:',mask_dst.dtype)
cv2.imwrite(mask_save2png_path+'\\'+save_file_name+'_label.png',mask_dst)
##################################
with open(osp.join(out_dir1, 'label_names.txt'), 'w') as f:
for lbl_name in lbl_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=lbl_names)
with open(osp.join(out_dir1, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir1)
if __name__ == '__main__':
main()
2.替换好之后,找到 labelme_json_to_dataset.exe 这个文件,主要是复制它的路径
3.桌面搜索 anaconda,再次进入Anaconda Prompt,激活 labelme 环境,用如下命令
activate labelme
4.进入 labelme_json_to_dataset.exe 文件所在路径,也就是第2步你复制的路径,进入命令如下
cd D:\Anaconda3\envs\labelme\Scripts
5.输入 labelme_json_to_dataset.exe+空格+【你待转化的 json 文件所在路径】
labelme_json_to_dataset.exe 【你待转化的 json 文件所在路径】
等待运行,运行一段时间后,如果末尾出现以下红框所示,表示转换成功
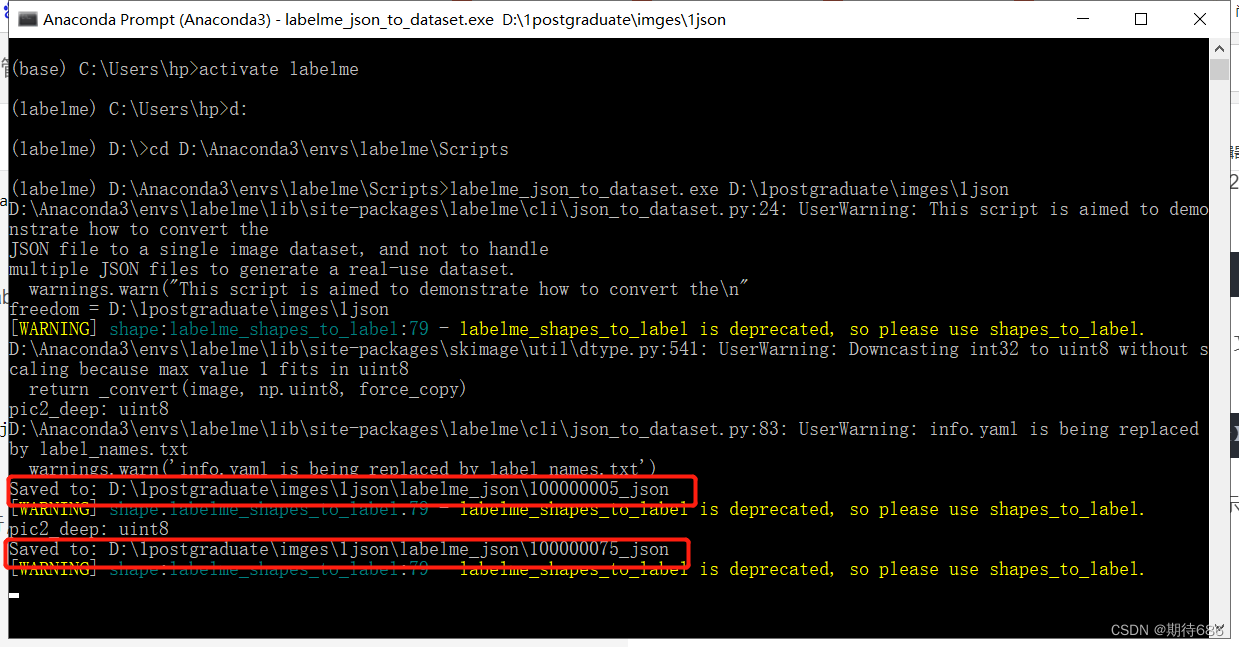
6.检查转换结果
如下显示,表示转换成功

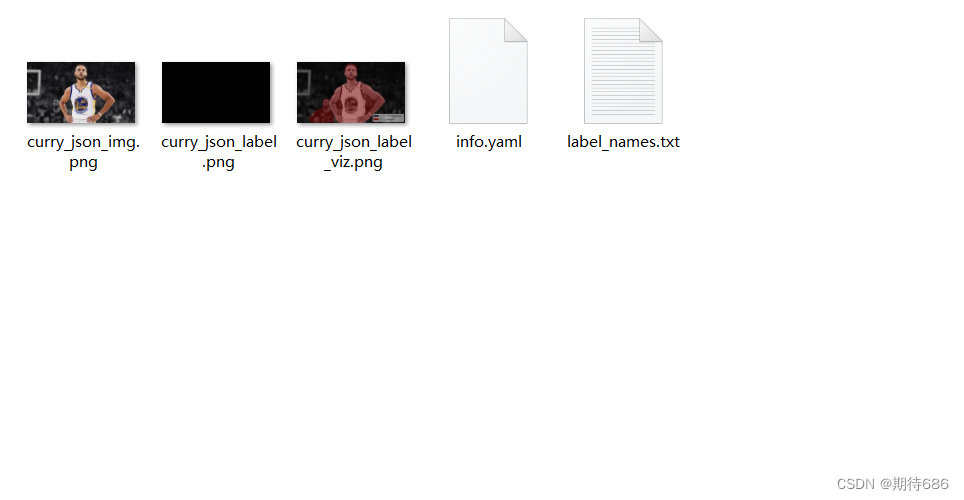
文章出处登录后可见!