



方法1:使用dataframe.loc[]函数
通过这个方法,我们可以用一个条件或一个布尔数组来访问一组行或列。如果我们可以访问它,我们也可以操作它的值,是的!这是我们的第一个方法,通过pandas中的dataframe.loc[]函数,我们可以访问一个列并通过一个条件改变它的值。
语法: df.loc[ df["column_name"] == "some_value", "column_name" ] = "value"
some_value = 需要被替换的值 value = 应该被放置的值。
示例: 我们要把性别栏中的所有 “男性 “改为1。
import pandas as pd
import numpy as np
# data
data= {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
# 创建一个 Dataframe 对象
df = pd.DataFrame(data)
# 条件应用
df.loc[df["gender"] == "male", "gender"] = 1输出:
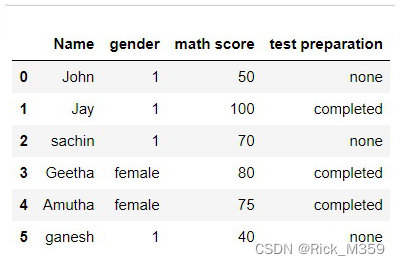
方法2:使用NumPy.where()函数
NumPy是一个非常流行的库,用于2D和3D数组的计算。它为我们提供了一个非常有用的方法where()来访问有条件的特定行或列。我们也可以用这个函数来改变某一列的特定值。
语法: df[“column_name”] = np.where(df[“column_name”]==”some_value”, value_if_true, value_if_false)
示例: 这个numpy.where()函数应该写上条件,如果条件为真,后面是值,如果条件为假,则是一个值。现在,我们要把性别栏中的所有 “女性 “改为0,”男性 “改为1。
import pandas as pd
import numpy as np
# data
data= {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
# 创建一个 Dataframe 对象
df = pd.DataFrame(data)
# 条件应用
df["gender"] = np.where(df["gender"] == "female", 0, 1)输出:

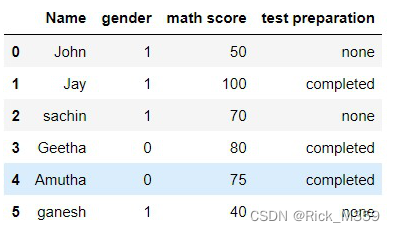
方法3:使用pandas掩码函数
Pandas的掩蔽函数是为了用一个条件替换任何行或列的值。
语法: df[‘column_name’].mask( df[‘column_name’] == ‘some_value’, value , inplace=True )
示例:使用这个屏蔽条件,将性别栏中所有的 “女性 “改为0。
import pandas as pd
import numpy as np
# data
data= {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
# 创建一个 Dataframe 对象
df = pd.DataFrame(data)
# 条件应用 1
df['gender'].mask(df['gender'] == 'female', 0, inplace=True)
# 条件应用 2
#df['math score'].mask(df['math score'] >=60 ,'good', inplace=True)输出:

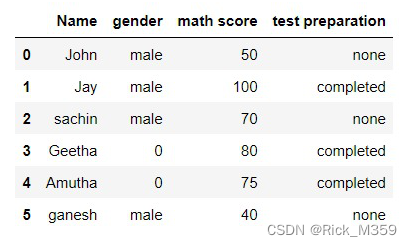
方法4:替换包含指定字符的字符串
语法 : data["列名"].mask(data.列名.str.contains(".*?某字符串"), "替换目标字符串", inplace=True)
import pandas as pd
import numpy as np
# data
data= {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, '良70', 80, '良75', 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
# 创建一个 Dataframe 对象
df = pd.DataFrame(data)
# 条件应用
data["math score"].mask(data.math score.str.contains(".*?良"), "良好", inplace=True)
文章出处登录后可见!
已经登录?立即刷新