文章目录
- 1 比赛介绍
- 2 Python组竞赛规则及说明
- 3 试题及答案
- 3.1 成绩统计
- 3.2 FJ字符串
- 3.3 K好数
- 3.4 N皇后
- 3.5 2N皇后
- 3.6 sin之舞
- 3.7 不同子串
- 3.8 成绩排名
- 3.9 承压计算
- 3.10乘积尾零
- 3.11 单词分析
- 3.12 等差数列
- 3.13 等差素数列
- 3.14 递归倒置字符数组
- 3.15 递增三元组
- 3.16 第几个幸运数
- 3.17 调手表
- 3.18 队列操作
- 3.19 方格分割
- 3.20 分解质因数
- 3.21 分数
- 3.22 复数求和
- 3.23 购物单
- 3.24 龟兔赛跑预测
- 3.25 合根植物
- 3.26 换钞票
- 3.27 回形取数
- 3.28 金陵十三钗
- 3.29 矩阵乘法
- 3.30 矩阵面积交
- 3.31 矩阵求和
- 3.32 门牌制作
- 3.33 迷宫
- 3.34 迷宫2
- 3.35 年号字串
- 3.36 跑步锻炼
- 3.37 平面切分
- 3.38 全球变暖
- 3.39 蛇形填数
- 3.40 石子游戏
- 3.41 时间转换
- 3.42 数的读法
- 3.43 数的分解
- 3.44 数列求值
- 3.45 数位递增的数
- 3.46 数字9
- 3.47 数字三角形
- 3.48 特别数的和
- 3.49 特殊回文数
- 3.50 完美的代价
- 3.51 完全二叉树的权值
- 3.52 晚会节目单
- 3.53 芯片测试
- 3.54 幸运顾客
- 3.55 序列计数
- 3.56 寻找2020
- 3.57 杨辉三角
- 3.58 叶节点数
- 3.59 音节判断
- 3.60 预测身高
- 3.61 约数个数
- 3.62 长草
- 3.63 长整数加法
- 3.64 装饰珠
- 3.65 字符串操作
- 3.66 字符串对比
- 3.67 字符串跳步
- 3.68 最长公共子序列(LCS)
- 3.69 最长滑雪道
- 3.70 最长字符序列(同LCS)
1 比赛介绍
蓝桥杯大赛的举办得到了教育部、工业和信息化部有关领导的高度重视,相关司局的大力支持,也得到了各省教育厅和各有关院校的积极响应,更得到了参赛师生的广泛好评,参赛学校超过 1200 余所,参赛规模已达四十万人次,取得了良好的社会效果。
省级在我们学校为B类,国家级则为A类,省级中获一等奖的可参加国家级,因此比赛含金量高,建议大家好好把握😊
其中个人赛软件类分:
- C/C++程序设计(研究生组、大学A组、B组、C组)
- Java软件开发(研究生组、大学A组、B组、C组)
- Python程序设计(大学组)
2 Python组竞赛规则及说明
2.1 组别
本次竞赛不分组别。所有研究生、重点本科、普通本科和高职高专院校均可报名该组,统一评奖。
2.2 竞赛赛程
全国选拔赛时长:4 小时。
总决赛时长:4 小时。
详细赛程安排以组委会公布信息为准。
2.3 竞赛形式
个人赛,一人一机,全程机考。选手机器通过局域网连接到赛场的竞赛服务器。选手答题过程中无法访问互联网,也不允许使用本机以外的资源(如USB 连接)。竞赛系统以“服务器-浏览器”方式发放试题、回收选手答案。
2.4 参赛选手机器环境
选手机器配置:
X86兼容机器,内存不小于 4G ,硬盘不小于 60G
操作系统:Windows7 及以上
编程环境:
编译器:Python 3.8.6
编辑器:IDLE Python 自带编辑器
2.5 试题形式
竞赛题目完全为客观题型。根据选手所提交答案的测评结果为评分依据。共有两种题型。
结果填空题
题目描述一个具有确定解的问题。要求选手对问题的解填空。
不要求解题过程,不限制解题手段(可以使用任何开发语言或工具,甚至是手工计算),只要求填写最终的结果。最终的解是一个整数或者是一个字符串,最终的解可以使用ASCII 字符表达。
编程大题
题目包含明确的问题描述、输入和输出格式,以及用于解释问题的样例数据。
编程大题所涉及的问题一定是有明确客观的标准来判断结果是否正确,并可以通过程序对结果进行评判。果进行评判。
选手应当根据问题描述,编写程序(使用 Python 编写)来解决问题,在评测时选手的程序应当从标准输入读入数据,并将最终的结果输出到标准输出中。
在问题描述中会明确说明给定的条件和限制,明确问题的任务,选手的程序应当能解决在给定条件和限制下的所有可能的情况。在给定条件和限制下的所有可能的情况。
选手的程序应当具有普遍性,不能只适用于题目的样例数据。
为了测试选手给出解法的性能,评分时用的测试用例可能包含大数据量的压力测试用例,选手选择算法时要尽可能考虑可行性和效率问题。
2.6 试题考查范围试题考查范围
Python程序设计基础:包含使用 Python编写程序的能力。该部分不考查选手对某一语法的理解程度,选手可以使用自己喜欢的语句编写程序。
计算机算法:枚举、排序、搜索、计数、贪心、动态规划、图论、数论、博弈论、概率论、计算几何、字符串算法等。
数据结构:数组、对象/结构、字符串、队列、栈、树、图、堆、平衡树结构、字符串、队列、栈、树、图、堆、平衡树/线段树、复杂数据线段树、复杂数据结构、嵌套数据结构等。
2.7 答案提交
选手只有在比赛时间内提交的答案内容是可以用来评测的,比赛之后的任何提交均无效。
选手应使用考试指定的网页来提交代码,任何其他方式的提交(如邮件、U盘)都不作为评测依据。
选手可在比赛中的任何时间查看自己之前提交的代码,也可以重新提交任何题目的答案,对于每个试题,仅有最后的一次提交被保存并作为评测的依据。在比赛中,评测结果不会显示给选手,选手应当在没有反馈的情况下自行设计数据调试自己的程序。
对于每个试题,选手应将试题的答案内容拷贝粘贴到网页上进行提交。
Python程序仅可以使用Python自带的库,评测时不会安装其他的扩展库。
程序中应只包含计算模块,不要包含任何其他的模块,比如图形、系统接口调用、系统中断等。对于系统接口的调用都应通过标准库来进行。
程序中引用的库应该在程序中以源代码的方式写出,在提交时也应当和程序的其他部分一起提交。
2.8 评分
全部使用机器自动评分。对于结果填空题,题目保证只有唯一解,选手的结果只有和解完全相同才得分,出现格式错误或有多余内容时不得分。
对于编程大题,评测系统将使用多个评测数据来测试程序。每个评测数据有对应的分数。选手所提交的程序将分别用每个评测数据作为输入来运行。对于某个评测数据,如果选手程序的输出与正确答案是匹配的,则选手获得该评测数据的分数。
评测使用的评测数据一般与试题中给定的样例输入输出不一样。因此建议选手在提交程序前使用不同的数据测试自己的程序。
提交的程序应严格按照输出格式的要求来输出,包括输出空格和换行的要求。如果程序没有遵循输出格式的要求将被判定为答案错误。请注意,程序在输出的时候多输出了内容也属于没有遵循输出格式要求的一种,所以在输出的时候请不要输出任何多余的内容,比如调试输出。
3 试题及答案
试题由本人从历年搜集并附了程序解答,由于本人编程能力有限,可能有错或并非最优解,欢迎指正!
当初本人刷完题,将解答过程分享给老魏,最终老魏获得了省二(成为我心中的阴影😢),说明刷题还是有一定帮助,希望大家能认真做好每一题。
3.1 成绩统计
题目描述
小蓝给学生们组织了一场考试,卷面总分为100分,每个学生的得分都是一个0到100的整数。如果得分至少是60分,则称为及格。如果得分至少为85分,则称为优秀。请计算及格率和优秀率,用百分数表示,百分号前的部分四舍五入保留整数。
输入描述
输入的第一行包含一个整数 n (1≤n≤
),表示考试人数。接下来n行,每行包含一个0至100的整数,表示一个学生的得分。
输出描述
输出两行,每行一个百分数,分别表示及格率和优秀率。百分号前的部分四舍五入保留整数。
n = int(input())
# 及格的数量
passNum = 0
# 优秀的数量
goodNum = 0
for _ in range(n):
score = int(input())
if score >= 60:
passNum += 1
if score >= 85:
goodNum += 1
print(str(round(passNum/n*100))+'%')
print(str(round(goodNum/n*100))+'%')
3.2 FJ字符串
题目描述
FJ在沙盘上写了这样一些字符串:
A1 = “A”
A2 = “ABA”
A3 = “ABACABA”
A4 = “ABACABADABACABA”
… …
你能找出其中的规律并写所有的数列AN吗?
输入描述
仅有一个数:N ≤ 26。
输出描述
请输出相应的字符串AN,以一个换行符结束。输出中不得含有多余的空格或换行、回车符。
输入样例
3
输出样例
ABACABA
n = int(input())
result = ''
for i in range(n):
result = result + chr(ord('A') + i) + result
print(result)
3.3 K好数
题目描述
如果一个自然数N的K进制表示中任意的相邻的两位都不是相邻的数字,那么我们就说这个数是K好数。求L位K进制数中K好数的数目。例如K = 4,L = 2的时候,所有K好数为11、13、20、22、30、31、33 共7个。由于这个数目很大,请你输出它对1000000007取模后的值。
输入描述
输入包含两个正整数,K和L。
输出描述
输出一个整数,表示答案对1000000007取模后的值。
输入样例
4 2
输出样例
7
对于30%的数据,KL <= 106;
对于50%的数据,K <= 16, L <= 10;
对于100%的数据,1 <= K, L <= 100。
K, L = map(int, input().split())
count = 0
# dp[i][j]表示i + 1位上存放j的方法个数。
dp = [[0 for _ in range(K)] for _ in range(L)]
# 当只有一位时不管这位放哪个数字都只有一种方法
for i in range(0, K):
dp[0][i] = 1
# 当位数大等2位时
for i in range(1, L):
# 以2为数为例,j为十位,m为个位
for j in range(K):
for m in range(K):
# 不相邻才能存放
if abs(j - m) != 1:
# 当前位数的放j情况的总个数 = 当前位置放j的个数 + 上一位置放[0,k)的总个数
dp[i][j] = dp[i][j]+dp[i-1][m]
dp[i][j] %= 1000000007
# 不断递归下去,如三位数放k进制的个数 = 三位数的最高位(看成十位)放k进制的个数+两位数(看成一个整体为个位)放k进制的个数
# L位数K好数的总个数
# i从1开始排除L位为最高位放0的情况
for i in range(1, K):
count += dp[L-1][i]
count %= 1000000007
print(count)
3.4 N皇后
题目描述
在N*N的方格棋盘放置了N个皇后,使得它们不相互攻击(即任意2个皇后不允许处在同一排,同一列,也不允许处在与棋盘边框成45角的斜线上。
你的任务是,对于给定的N,求出有多少种合法的放置方法。
输入描述
输入N。
输出描述
输出一个整数,表示总共有多少种放法。
# 递归回溯思想解决n皇后问题,cur代表当前行,从0开始一行行遍历
def queen(A, cur=0):
# 判断上行放置的棋子是否有问题,如果有则回退
for row in range(cur-1):
# 由于是一行行遍历肯定不存在同行,只需检测是否同列和同对角线
# 若在该列或对角线上存在其他皇后
if A[row] - A[cur-1] == 0 or abs(A[row] - A[cur-1]) == cur - 1 - row:
# 该位置不能放
return
# 所有的皇后都正确放置完毕,输出每个皇后所在的位置
if cur == len(A):
print(A)
return
# 行数=列数,遍历每列
for col in range(len(A)):
# 当前行存储皇后所在的列数
A[cur] = col
# 继续放下一个皇后
queen(A, cur+1)
# n为8,就是著名的八皇后问题啦
n = int(input())
# 初始传入8行的数组
queen([None] * n)
3.5 2N皇后
题目描述
给定一个n*n的棋盘,棋盘中有一些位置不能放皇后。现在要向棋盘中放入n个黑皇后和n个白皇后,使任意的两个黑皇后都不在同一行、同一列或同一条对角线上,任意的两个白皇后都不在同一行、同一列或同一条对角线上。问总共有多少种放法?n小于等于8。
输入描述
输入的第一行为一个整数n,表示棋盘的大小。
接下来n行,每行n个0或1的整数,如果一个整数为1,表示对应的位置可以放皇后,如果一个整数为0,表示对应的位置不可以放皇后。
输出描述
输出一个整数,表示总共有多少种放法。
输入样例
4
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
输出样例
2
输入样例
4
1 0 1 1
1 1 1 1
1 1 1 1
1 1 1 1
输出样例
0
# 先放置白皇后, cur代表当前行,从0开始一行行遍历
def w_queen(cur=0):
# 判断上行放置的棋子是否有问题,如果有则回退
for row in range(cur-1):
# 由于是一行行遍历肯定不存在同行,只需检测是否同列和同对角线
# 若在该列或对角线上存在其他皇后
if w_pos[row] - w_pos[cur-1] == 0 or abs(w_pos[row] - w_pos[cur-1]) == cur - 1 - row:
# 该位置不能放
return
# 当前颜色皇后都正确放置完毕
if cur == n:
# 放置另一种颜色的皇后
b_queen(0)
return
# 遍历每列
for col in range(n):
# 如果该位置为1,则可以放置其子
if chessboard[cur][col] == 1:
# 记录该棋子存放位置
w_pos[cur] = col
# 继续放下一个皇后
w_queen(cur+1)
# 再放置黑皇后,与白皇后同理
def b_queen(cur=0):
global count
for row in range(cur-1):
if b_pos[row] - b_pos[cur-1] == 0 or abs(b_pos[row] - b_pos[cur-1]) == cur - 1 - row:
return
if cur == n:
# 两种颜色皇后放置完毕,记录次数
count += 1
return
for col in range(n):
# 如果该位置为1且没有放白皇后,则可以放置其子
if chessboard[cur][col] == 1 and w_pos[cur] != col:
b_pos[cur] = col
b_queen(cur+1)
# 输入
n = int(input())
# 初始化棋盘
chessboard = [[] for _ in range(n)]
for i in range(n):
arr = input().split()
for j in range(n):
chessboard[i].append(int(arr[j]))
# 用于记录白皇后位置
w_pos = [0 for _ in range(n)]
# 用于记录黑皇后位置
b_pos = [0 for _ in range(n)]
# 初始化多少种放法
count = 0
# 开始放置皇后
w_queen(0)
# 输出多少种放法
print(count)
3.6 sin之舞
题目描述
最近FJ为他的奶牛们开设了数学分析课,FJ知道若要学好这门课,必须有一个好的三角函数基本功。所以他准备和奶牛们做一个“Sine之舞”的游戏,寓教于乐,提高奶牛们的计算能力。
不妨设
An=sin(1–sin(2+sin(3–sin(4+…sin(n))…)
Sn=(…(A1+n)A2+n-1)A3+…+2)An+1
FJ想让奶牛们计算Sn的值,请你帮助FJ打印出Sn的完整表达式,以方便奶牛们做题。
输入描述
仅有一个数:N<201。
输出描述
请输出相应的表达式Sn,以一个换行符结束。输出中不得含有多余的空格或换行、回车符。
输入样例
3
输出样例
((sin(1)+3)sin(1–sin(2))+2)sin(1–sin(2+sin(3)))+1
def A(k, n):
if k == n:
return
print('sin(%d' % (k + 1), end='')
# 若后边还有式子,判断是输出+号还是-号
if k + 1 != n:
if k % 2 == 1:
print('+', end='')
else:
print('-', end='')
# 若到底了,则输出n个')'结束
else:
print(')'*n, end='')
k += 1
A(k, n) # 递归调用自身
n = int(input())
for i in range(n):
# 第一项n-1个括号开始
if i == 0:
print('('*(n-1), end='')
# 后续An+n-i)
A(0, i+1)
print('+%d' % (n-i), end='')
# 最后一项加完整数之和不必再输出右括号
if i != n - 1:
print(')', end='')
3.7 不同子串
题目描述
一个字符串的非空子串是指字符串中长度至少为1的连续的一段字符组成的串。例如,字符串aaab有非空子串a, b, aa, ab, aaa, aab, aaab,一共7个。 注意在计算时,只算本质不同的串的个数。请问,字符串0100110001010001有多少个不同的非空子串?
答案
100
str1 = '0100110001010001'
var = []
for i in range(1, len(str1)+1):
for j in range(len(str1) - i + 1):
if str1[j:j+i] not in var:
var.append(str1[j:j+i])
print(len(var))
3.8 成绩排名
题目描述
小明刚经过了一次数学考试,老师由于忙碌忘记排名了,于是老师把这个光荣的任务交给了小明,小明则找到了聪明的你,希望你能帮他解决这个问题。
输入描述
第一行包含一个正整数N,表示有个人参加了考试。接下来N行,每行有一个字符串和一个正整数,分别表示人名和对应的成绩,用一个空格分隔。
输出描述
输出一共有N行,每行一个字符串,第i行的字符串表示成绩从高到低排在第i位的人的名字,若分数一样则按人名的字典序顺序从小到大。
输入样例
3
aaa 47
bbb 90
ccc 70
输出样例
bbb
ccc
aaa
人数<=100,分数<=100,人名仅包含小写字母。
n = int(input())
inf = [list(input().split()) for _ in range(n)]
information.sort(key=lambda x: x[0]) # 先排姓名,按字母顺序
information.sort(key=lambda x: int(x[1]), reverse=True) # 后排成绩,从大到小
for i in range(n):
print(information[i][0])
3.9 承压计算
题目描述
X星球的高科技实验室中整齐地堆放着某批珍贵金属原料。
每块金属原料的外形、尺寸完全一致,但重量不同。
金属材料被严格地堆放成金字塔形。其中的数字代表金属块的重量(计量单位较大)。
最下一层的X代表30台极高精度的电子秤。假设每块原料的重量都十分精确地平均落在下方的两个金属块上,
最后,所有的金属块的重量都严格精确地平分落在最底层的电子秤上。
电子秤的计量单位很小,所以显示的数字很大。工作人员发现,其中读数最小的电子秤的示数为:2086458231
请你推算出:读数最大的电子秤的示数为多少?
注意:需要提交的是一个整数,不要填写任何多余的内容。
pyramid.txt:
7
5 8
7 8 8
9 2 7 2
8 1 4 9 1
8 1 8 8 4 1
7 9 6 1 4 5 4
5 6 5 5 6 9 5 6
5 5 4 7 9 3 5 5 1
7 5 7 9 7 4 7 3 3 1
4 6 4 5 5 8 8 3 2 4 3
1 1 3 3 1 6 6 5 5 4 4 2
9 9 9 2 1 9 1 9 2 9 5 7 9
4 3 3 7 7 9 3 6 1 3 8 8 3 7
3 6 8 1 5 3 9 5 8 3 8 1 8 3 3
8 3 2 3 3 5 5 8 5 4 2 8 6 7 6 9
8 1 8 1 8 4 6 2 2 1 7 9 4 2 3 3 4
2 8 4 2 2 9 9 2 8 3 4 9 6 3 9 4 6 9
7 9 7 4 9 7 6 6 2 8 9 4 1 8 1 7 2 1 6
9 2 8 6 4 2 7 9 5 4 1 2 5 1 7 3 9 8 3 3
5 2 1 6 7 9 3 2 8 9 5 5 6 6 6 2 1 8 7 9 9
6 7 1 8 8 7 5 3 6 5 4 7 3 4 6 7 8 1 3 2 7 4
2 2 6 3 5 3 4 9 2 4 5 7 6 6 3 2 7 2 4 8 5 5 4
7 4 4 5 8 3 3 8 1 8 6 3 2 1 6 2 6 4 6 3 8 2 9 6
1 2 4 1 3 3 5 3 4 9 6 3 8 6 5 9 1 5 3 2 6 8 8 5 3
2 2 7 9 3 3 2 8 6 9 8 4 4 9 5 8 2 6 3 4 8 4 9 3 8 8
7 7 7 9 7 5 2 7 9 2 5 1 9 2 6 5 3 9 3 5 7 3 5 4 2 8 9
7 7 6 6 8 7 5 5 8 2 4 7 7 4 7 2 6 9 2 1 8 2 9 8 5 7 3 6
5 9 4 5 5 7 5 5 6 3 5 3 9 5 8 9 5 4 1 2 6 1 4 3 5 3 2 4 1
X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X
arr = []
k = 0
file = open('pyramid.txt', 'r')
for line in file.readlines():
arr.append(list(map(int, line.split())))
arr.append([0]*30)
for i in range(1, 30):
for j in range(i):
arr[i][j] += arr[i - 1][j] / 2
arr[i][j + 1] += arr[i - 1][j] / 2
print(2086458231 / min(arr[-1]) * max(arr[-1]))
3.10乘积尾零
题目描述
如下的10行数据,每行有10个整数,请你求出它们的乘积的末尾有多少个零?注意:需要提交的是一个整数,表示末尾零的个数。不要填写任何多余内容。
num.txt:
5650 4542 3554 473 946 4114 3871 9073 90 4329
2758 7949 6113 5659 5245 7432 3051 4434 6704 3594
9937 1173 6866 3397 4759 7557 3070 2287 1453 9899
1486 5722 3135 1170 4014 5510 5120 729 2880 9019
2049 698 4582 4346 4427 646 9742 7340 1230 7683
5693 7015 6887 7381 4172 4341 2909 2027 7355 5649
6701 6645 1671 5978 2704 9926 295 3125 3878 6785
2066 4247 4800 1578 6652 4616 1113 6205 3264 2915
3966 5291 2904 1285 2193 1428 2265 8730 9436 7074
689 5510 8243 6114 337 4096 8199 7313 3685 211
with open('num.txt') as file:
lines = file.readlines()
file.close
res = 0
for line in lines:
for num in line.split():
if res == 0:
res = int(num)
else:
res *= int(num)
count = 0
for i in str(res)[::-1]:
if i != '0':
break
count += 1
print(count)
3.11 单词分析
题目描述
小蓝正在学习一门神奇的语言,这门语言中的单词都是由小写字母组成,
有些单词很长,远远超过正常英文单词的长度。小蓝学了很长时间也记不住一些单词,
他准备不再完全记忆这些单词,而是根据单词中哪个字母出现的最多来分辨单词。
请你帮助小蓝,给了一些单词后,帮助他找到出现最多的字母和这个字母出现的次数。
输入描述
输入一行包含一个单词,单词只有小写英文字母组成。
输出描述
输出两行,第一行包含一个英文字母,表示单词中出现最多的字母是哪个。 如果有多个字母出现的次数相等,输出字典序最小的那个。 第二行包含一个整数,表示出现的最多的那个字母在单词中出现的次数。
输入样例
lanqiao
输出样例
a
2
输入样例
longlonglongistoolong
输出样例
o
6
word = input()
mapNum = {}
# 次数最多的字母
maxV = None
# 最多次数
maxNum = 0
for v in word:
if v not in mapNum:
mapNum[v] = 1
else:
mapNum[v] += 1
keys = sorted(mapNum.keys())
for key in keys:
if mapNum[key] > maxNum:
maxV = key
maxNum = mapNum[key]
print(maxV)
print(maxNum)
3.12 等差数列
题目描述
数学老师给小明出了一道等差数列求和的题目。但是粗心的小明忘记了一部分的数列,只记得其中N个整数。
现在给出这N个整数,小明想知道包含这N个整数的最短的等差数列有几项?
输入描述
输入的第一行包含一个整数N。
第二行包含N个整数A1,A2,···,AN。(注意A1~AN并不一定是按等差数列中的顺序给出)
输出描述
输出一个整数表示答案。
输入样例
5
2 6 4 10 20
输出样例
10
样例说明
包含2、6、4、10、20的最短的等差数列是2、4、6、8、10、12、14、16、18、20。
n = int(input())
arr = list(map(int, input().split()))
min_gap = float("inf")
# 先排序
arr.sort()
# 找出等差数列的步长(各相邻数差值最小的)
for i in range(1, n):
if arr[i] - arr[i-1] < min_gap:
min_gap = arr[i] - arr[i-1]
# 等差数列长度为(某项-首项)/步长+1
res = (arr[-1] - arr[0]) // min_gap + 1
print(res)
3.13 等差素数列
题目描述
2,3,5,7,11,13,…是素数序列。
类似:7,37,67,97,127,157 这样完全由素数组成的等差数列,叫等差素数数列。
上边的数列公差为30,长度为6。2004年,格林与华人陶哲轩合作证明了:存在任意长度的素数等差数列。
这是数论领域一项惊人的成果!有这一理论为基础,请你借助手中的计算机,满怀信心地搜索:
长度为10的等差素数列,其公差最小值是多少?
# 判断是否为素数
def isprimy(n):
for i in range(2, int(float(n)**0.5) + 1):
if n % i == 0:
return False
return True
# 在一个范围里查找起点
for start in range(2, 4000):
# 不是素数则跳过
if not isprimy(start):
continue
# 查找公差
for diff in range(1, 400):
# 记录数列长度
count = 1
# 下一个数值
next = start + diff
# 若仍为素数
while(isprimy(next)):
# 长度加1
count += 1
# 继续判断下一个数
next += diff
# 若长度大等10,则找到
if count >= 10:
print('起点:', start,'公差:', diff)
exit()
3.14 递归倒置字符数组
题目描述
完成一个递归程序,倒置字符数组,并打印实现过程。
递归逻辑为:
当字符长度等于1时,直接返回
否则,调换首尾两个字符,再递归地倒置字符数组的剩下部分
输入描述
字符数组长度及该数组
输出描述
在求解过程中,打印字符数组的变化情况。
最后空一行,在程序结尾处打印倒置后该数组的各个元素。
输入样例
5 abcde
输出样例
ebcda
edcba
edcba
输入样例
1 a
输出样例
a
n, string = input().split()
if int(n) > 1:
l = 0
r = int(n) - 1
string = list(string)
while l <= r:
string[l], string[r] = string[r], string[l]
l += 1
r -= 1
print(''.join(string))
else:
print(string)
3.15 递增三元组
题目描述
在数列 a[1], a[2], …, a[n] 中,如果对于下标 i, j, k 满足 0<i<j<k<n+1 且 a[i]<a[j]<a[k],则称 a[i], a[j], a[k] 为一组递增三元组,a[j]为递增三元组的中心。
给定一个数列,请问数列中有多少个元素可能是递增三元组的中心。
输入描述
输入的第一行包含一个整数 n。
第二行包含 n 个整数 a[1], a[2], …, a[n],相邻的整数间用空格分隔,表示给定的数列。
输出描述
输出一行包含一个整数,表示答案。
输入样例
5
1 2 5 3 5
输出样例
2
样例说明
a[2]和a[4]可能是三元组的中心。
n = int(input())
arr = list(map(int, input().split()))
count = 0
# 记录该中心是否用过
data = []
for i in range(n):
for j in range(i + 1, n):
for k in range(j + 1, n):
if arr[i] < arr[j] < arr[k]:
if arr[j] not in data:
data.append(arr[j])
count += 1
print(count)
3.16 第几个幸运数
题目描述
到x星球旅行的游客都被发给一个整数,作为游客编号。
x星的国王有个怪癖,他只喜欢数字3,5和7。
国王规定,游客的编号如果只含有因子:3,5,7,就可以获得一份奖品。
前10个幸运数字是:3 5 7 9 15 21 25 27 35 45,因而第11个幸运数字是:49
小明领到了一个幸运数字 59084709587505。
去领奖的时候,人家要求他准确说出这是第几个幸运数字,否则领不到奖品。
请你帮小明计算一下,59084709587505是第几个幸运数字。
输出描述
输出一个整数表示答案。
MAX = 59084709587505
# MAX = 49
a = [3, 5, 7]
s = set()
tou = 1
while True:
for i in a:
t = tou * i
if t <= MAX:
s.add(t)
lst = sorted(s)
for i in lst:
if i > tou:
tou = i
break
if tou >= MAX:
break
print(len(s)) # 1905
3.17 调手表
题目描述
小明买了块高端大气上档次的电子手表,他正准备调时间呢。在 M78 星云,时间的计量单位和地球上不同,M78 星云的一个小时有 n 分钟。大家都知道,手表只有一个按钮可以把当前的数加一。在调分钟的时候,如果当前显示的数是 0 ,那么按一下按钮就会变成 1,再按一次变成 2 。如果当前的数是 n – 1,按一次后会变成 0 。作为强迫症患者,小明一定要把手表的时间调对。如果手表上的时间比当前时间多1,则要按 n – 1 次加一按钮才能调回正确时间。
小明想,如果手表可以再添加一个按钮,表示把当前的数加 k 该多好啊……
他想知道,如果有了这个 +k 按钮,按照最优策略按键,从任意一个分钟数调到另外任意一个分钟数最多要按多少次。注意,按 +k 按钮时,如果加k后数字超过n-1,则会对n取模。比如,n=10, k=6 的时候,假设当前时间是0,连按2次 +k 按钮,则调为2。
输入描述
一行两个整数 n, k,意义如题。
输出描述
一行一个整数。表示:按照最优策略按键,从一个时间调到另一个时间最多要按多少次。
输入样例
5 3
输出样例
2
样例说明
如果时间正确则按0次。否则要按的次数和操作系列之间的关系如下:
1:+1
2:+1, +1
3:+3
4:+3, +1
对于 30% 的数据 0 < k < n <= 5
对于 60% 的数据 0 < k < n <= 100
对于 100% 的数据 0 < k < n <= 100000
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
n, k = map(int, input().split())
res = 0
for i in range(1, n):
tmp = 0
while i >= k:
tmp += i // k
i %= k
tmp += i
if tmp > res:
res = tmp
print(res)
3.18 队列操作
题目描述
队列操作题。根据输入的操作命令,操作队列(1)入队、(2)出队并输出、(3)计算队中元素个数并输出。
输入描述
第一行一个数字N。
下面N行,每行第一个数字为操作命令:(1)入队、(2)出队并输出、(3)计算队中元素个数并输出。
输出描述
若干行每行显示一个2或3命令的输出结果。注意:2.出队命令可能会出现空队出队(下溢),请输出“no”,并退出。
输入样例
7
1 19
1 56
2
3
2
3
2
输出样例
19
1
56
0
no
n = int(input())
command = [list(map(int, input().split())) for _ in range(n)]
queue = []
print('输出:')
for i in command:
if i[0] == 1:
queue.append(i[1])
if i[0] == 2:
if len(queue) < 1:
print('no')
else:
print(queue.pop(0))
if i[0] == 3:
if len(queue) < 1:
print(0)
else:
print(len(queue))
3.19 方格分割
题目描述
6×6的方格,沿着格子的边线剪开成两部分。要求这两部分的形状完全相同。如图,就是可行的分割法。
试计算: 包括这3种分法在内,一共有多少种不同的分割方法。
注意:旋转对称的属于同一种分割法。
请提交该整数,不要填写任何多余的内容或说明文字。
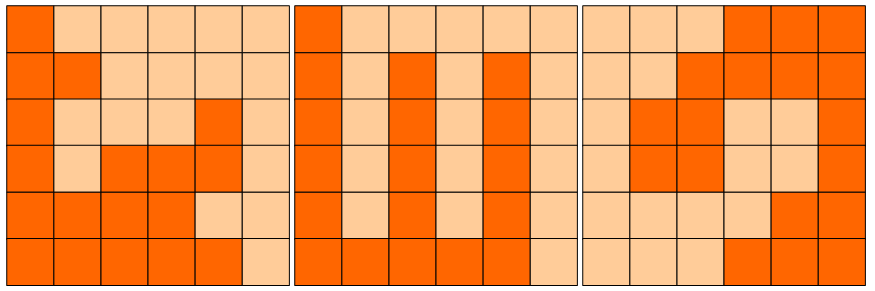
'''
因为两部分形状相同,则必定经过中间点
从中间点(3,3)出发,向两边按格点走,行走的方式有向上、向下、向左、向右
当其中一边达到边界,根据对称性,另一边也到达边界,则所有走过点的连线为一种分割方式
'''
def dfs(x, y):
global ans
# 到达边界,分割完成
if x == 0 or x == 6 or y == 0 or y == 6:
ans += 1
return
# 4个出行可能性
for xy in dirs:
# 出发后的新索引
tx = x + xy[0]
ty = y + xy[1]
# 当前位置未走过
if arr_map[tx][ty] == 0:
# 标记为走过
arr_map[tx][ty] = 1
# 两边出发,根据对称性,另一边也标记为走过
arr_map[6-tx][6-ty] = 1
# 到达新位置后, 继续搜寻下一步可能
dfs(tx, ty)
# 当进行到这步,则代表一种分割可能已经搜寻完,因此跳出了递归
# 则要将方格还原,进行下一种可能的搜寻
arr_map[tx][ty] = 0
arr_map[6-tx][6-ty] = 0
# 初始化方格代表(0,0)到(6,6)的位置
arr_map = [[0] * 7 for _ in range(7)]
# 4个方向
dirs = [(1,0), (-1,0), (0, 1), (0,-1)]
# 中间点置1 代表走过
arr_map[3][3] = 1
# 分割方法
ans = 0
# 从中间点索引往两边走
dfs(3,3)
# 由于旋转对称的属于同一种分割方法,故最终结果要除以4
print(ans//4)
3.20 分解质因数
题目描述
求出区间[a,b]中所有整数的质因数分解。
输入描述
输入两个整数a,b。
输出描述
每行输出一个数的分解,形如k=a1*a2*a3…(a1<=a2<=a3…,k也是从小到大的)
输入样例
3 10
输出样例
3=3
4=2*2
5=5
6=2*3
7=7
8=2*2*2
9=3*3
10=2*5
2<=a<=b<=10000
def factor(num):
# 遍历该数的可能因子
# 最大因子只到该数的开方
for i in range(2, int(float(num)**0.5)+1):
# 若能找到因子
if num % i == 0:
# 输出该因子
print(('%d*') % i, end='')
# 继续分解
factor(num // i)
return
# 若找不到,返回本身
print(num, end='')
a, b = map(int, input().split())
# 遍历该区间的数
for num in range(a, b+1):
print('%d='%num, end='')
factor(num)
print()
3.21 分数
题目描述
1/1 + 1/2 + 1/4 + 1/8 + 1/16 + …
每项是前一项的一半,如果一共有20项,
求这个和是多少,结果用分数表示出来。
类似:
3/2
当然,这只是加了前2项而已。分子分母要求互质。注意:
需要提交的是已经约分过的分数,中间任何位置不能含有空格。
请不要填写任何多余的文字或符号
# 最大公约数
def gcd(a, b):
while b != 0:
c = a % b
a = b
b = c
return a
# 分子
molecule = 0
# 因为1/1 + 1/2 + ... + 1/2^19通分后
# = 2^19/2^19 + 2^18/2^19 + ... + 1/2^19
# 则分子和为2^19 + 2^18 + ... + 1
for i in range(20):
molecule += 2 ** i
# 分母为2^19
gc = gcd(molecule, 2 ** 19)
# 输出约分后的结果
print(molecule // gc , '/', 2 ** 19 // gc, sep='')
3.22 复数求和
题目描述
从键盘读入n个复数(实部和虚部都为整数)用链表存储,遍历链表求出n个复数的和并输出。
输入样例
3
3 4
5 2
1 3
输出样例
9+9i
输入样例
7
1 2
3 4
2 5
1 8
6 4
7 9
3 7
输出样例
23+39i
n = int(input())
arr = [list(map(int, input().split())) for _ in range(n)]
real = 0
imaginary = 0
for i in range(n):
real += arr[i][0]
imaginary += arr[i][1]
print(real,'+',imaginary,'i', sep='')
3.23 购物单
题目描述
小明刚刚找到工作,老板人很好,只是老板夫人很爱购物。老板忙的时候经常让小明帮忙到商场代为购物。小明很厌烦,但又不好推辞。
这不,XX大促销又来了!老板夫人开出了长长的购物单,都是有打折优惠的。
小明也有个怪癖,不到万不得已,从不刷卡,直接现金搞定。
现在小明很心烦,请你帮他计算一下,需要从取款机上取多少现金,才能搞定这次购物。取款机只能提供100元面额的纸币。小明想尽可能少取些现金,够用就行了。
你的任务是计算出,小明最少需要取多少现金。
以下是让人头疼的购物单,为了保护隐私,物品名称被隐藏了。
**** 180.90 88折
**** 10.25 65折
**** 56.14 9折
**** 104.65 9折
**** 100.30 88折
**** 297.15 半价
**** 26.75 65折
**** 130.62 半价
**** 240.28 58折
**** 270.62 8折
**** 115.87 88折
**** 247.34 95折
**** 73.21 9折
**** 101.00 半价
**** 79.54 半价
**** 278.44 7折
**** 199.26 半价
**** 12.97 9折
**** 166.30 78折
**** 125.50 58折
**** 84.98 9折
**** 113.35 68折
**** 166.57 半价
**** 42.56 9折
**** 81.90 95折
**** 131.78 8折
**** 255.89 78折
**** 109.17 9折
**** 146.69 68折
**** 139.33 65折
**** 141.16 78折
**** 154.74 8折
**** 59.42 8折
**** 85.44 68折
**** 293.70 88折
**** 261.79 65折
**** 11.30 88折
**** 268.27 58折
**** 128.29 88折
**** 251.03 8折
**** 208.39 75折
**** 128.88 75折
**** 62.06 9折
**** 225.87 75折
**** 12.89 75折
**** 34.28 75折
**** 62.16 58折
**** 129.12 半价
**** 218.37 半价
**** 289.69 8折需要说明的是,88折指的是按标价的88%计算,而8折是按80%计算,余者类推。
特别地,半价是按50%计算。请提交小明要从取款机上提取的金额,单位是元。
答案是一个整数,类似4300的样子,结尾必然是00,不要填写任何多余的内容。
首先在把数据复制到记事本中,用Ctrl+H键替换,把****用空格替换,把7折、8折、9折替换为70、80、90,半价替换为50。
item.txt:
180.90 88
10.25 65
56.14 90
104.65 90
100.30 88
297.15 50
26.75 65
130.62 50
240.28 58
270.62 80
115.87 88
247.34 95
73.21 90
101.00 50
79.54 50
278.44 70
199.26 50
12.97 90
166.30 78
125.50 58
84.98 90
113.35 68
166.57 50
42.56 90
81.90 95
131.78 80
255.89 78
109.17 90
146.69 68
139.33 65
141.16 78
154.74 80
59.42 80
85.44 68
293.70 88
261.79 65
11.30 88
268.27 58
128.29 88
251.03 80
208.39 75
128.88 75
62.06 90
225.87 75
12.89 75
34.28 75
62.16 58
129.12 50
218.37 50
289.69 80
file = open('item.txt', 'r')
ans = 0
for line in file.readlines():
price, rate = map(float, line.split())
ans += price * rate / 100
file.close()
print(ans)
3.24 龟兔赛跑预测
题目描述
话说这个世界上有各种各样的兔子和乌龟,但是研究发现,所有的兔子和乌龟都有一个共同的特点——喜欢赛跑。于是世界上各个角落都不断在发生着乌龟和兔子的比赛,小华对此很感兴趣,于是决定研究不同兔子和乌龟的赛跑。他发现,兔子虽然跑比乌龟快,但它们有众所周知的毛病——骄傲且懒惰,于是在与乌龟的比赛中,一旦任一秒结束后兔子发现自己领先t米或以上,它们就会停下来休息s秒。对于不同的兔子,t,s的数值是不同的,但是所有的乌龟却是一致——它们不到终点决不停止。
然而有些比赛相当漫长,全程观看会耗费大量时间,而小华发现只要在每场比赛开始后记录下兔子和乌龟的数据——兔子的速度v1(表示每秒兔子能跑v1米),乌龟的速度v2,以及兔子对应的t,s值,以及赛道的长度l——就能预测出比赛的结果。但是小华很懒,不想通过手工计算推测出比赛的结果,于是他找到了你——清华大学计算机系的高才生——请求帮助,请你写一个程序,对于输入的一场比赛的数据v1,v2,t,s,l,预测该场比赛的结果。
输入描述
输入只有一行,包含用空格隔开的五个正整数v1,v2,t,s,l,其中(v1, v2<=100; t<=300; s<=10; l<=10000且为v1, v2的公倍数)
输出描述
输出包含两行,第一行输出比赛结果——一个大写字母“T”或“R”或“D”,分别表示乌龟获胜,兔子获胜,或者两者同时到达终点。
第二行输出一个正整数,表示获胜者(或者双方同时)到达终点所耗费的时间(秒数)。
输入样例
10 5 5 2 20
输出样例
D
4
输入样例
10 5 5 1 20
输出样例
R
3
输入样例
10 5 5 3 20
输出样例
T
4
v1, v2, t, s, l = map(int, input().split())
rabbit = 0
tortoise = 0
time = 0
flag = False
while True:
if rabbit == l or tortoise == l: # 如果兔子或乌龟到达终点,结束
break
if rabbit - tortoise >= t: # 兔子达到领先条件,休息
for i in range(s): # 休息时间按秒增加,乌龟路程按秒增加
tortoise += v2
time += 1
if tortoise == l:
# 兔子休息时,乌龟到达了终点,结束。
# 注意:有可能兔子在休息中,乌龟就到达了终点
# 所以休息时间未必循环完
# 如:兔子要休息10s,乌龟可能在兔子休息的第9s就到达了终点
# 这里的flag就起到提前结束的功能
flag = True
break
if flag: # 如果提前结束,则全部结束
break
time += 1 # 每走一秒,兔子和乌龟按相应速度增加相应距离
rabbit += v1
tortoise += v2
if rabbit > tortoise: # 谁先到达终点,谁的距离大
print('R')
elif rabbit < tortoise:
print('T')
else: # 相等则平局
print('D')
print(time)
3.25 合根植物
题目描述
w星球的一个种植园,被分成 m * n 个小格子(东西方向m行,南北方向n列)。每个格子里种了一株合根植物。
这种植物有个特点,它的根可能会沿着南北或东西方向伸展,从而与另一个格子的植物合成为一体。如果我们告诉你哪些小格子间出现了连根现象,你能说出这个园中一共有多少株合根植物吗?
输入描述
第一行,两个整数m,n,用空格分开,表示格子的行数、列数(1<m,n<1000)。
接下来一行,一个整数k,表示下面还有k行数据(0<k<100000)
接下来k行,第行两个整数a,b,表示编号为a的小格子和编号为b的小格子合根了。格子的编号一行一行,从上到下,从左到右编号。
比如:5 * 4 的小格子,编号:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
17 18 19 20
输入样例
5 4
16
2 3
1 5
5 9
4 8
7 8
9 10
10 11
11 12
10 14
12 16
14 18
17 18
15 19
19 20
9 13
13 17
输出样例
5
样例说明
其合根情况参考下图:
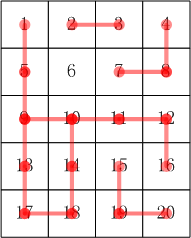
'''
并查集算法
'''
# 用于找到x的父节点
def rootFind(x):
p = x
#如果x的父节点不是他本身,就一直循坏到找到父节点为之
while x != pre[x]:
x = pre[x]
# 压缩路径,这个是优化的,所以可加可不加
while p != x: # 若当前节点不是父节点,找到父节点后,把沿途每个节点的根节点都设成父节点,使树变得扁平,以减小深度
p, pre[p] = pre[p], x
return x
m, n = map(int, input().split())
cnt = m * n
# pre列表中存储的是每个节点的父节点
pre = [i for i in range(cnt+1)]
k = int(input())
for i in range(k):
a,b = map(int, input().split())
roota = rootFind(a)
rootb = rootFind(b)
if roota != rootb:
# 如果父节点不一样就合并, 选任意一方为父
pre[roota] = pre[rootb]
#同时合并的话,集合就会少一个
cnt -= 1
print(cnt)
3.26 换钞票
题目描述
x星球的钞票的面额只有:100元,5元,2元,1元,共4种。
小明去x星旅游,他手里只有2张100元的x星币,太不方便,恰好路过x星银行就去换零钱。
小明有点强迫症,他坚持要求200元换出的零钞中2元的张数刚好是1元的张数的10倍,
剩下的当然都是5元面额的。银行的工作人员有点为难,你能帮助算出:在满足小明要求的前提下,最少要换给他多少张钞票吗?
(5元,2元,1元面额的必须都有,不能是0)
# 总共200元
total = 200
# 由于2元是1元的10倍,即扣掉5元钞票的钱数,应为21的倍数
# 要使换的钱数最少,则5元的钞票要多
for i in range(1, 200 // 21):
total -= 21
if total % 5 == 0:
# 共换了多少张钞票
count = 10 * i + i + total // 5
print(count)
break
3.27 回形取数
题目描述
回形取数就是沿矩阵的边取数,若当前方向上无数可取或已经取过,则左转90度。一开始位于矩阵左上角,方向向下。
输入描述
输入第一行是两个不超过200的正整数m, n,表示矩阵的行和列。接下来m行每行n个整数,表示这个矩阵。
输出描述
输出只有一行,共mn个数,为输入矩阵回形取数得到的结果。数之间用一个空格分隔,行末不要有多余的空格。
输入样例
3 3
1 2 3
4 5 6
7 8 9
输出样例
1 4 7 8 9 6 3 2 5
输入样例
3 2
1 2
3 4
5 6
输出样例
1 3 5 6 4 2
m, n = map(int, input().split())
matrix = [[] for _ in range(m)]
for i in range(m):
arr = input().split()
for j in range(n):
matrix[i].append(int(arr[j]))
# 初始位置
x, y = 0, 0
# 外框到里框的个数
for i in range(min(m, n)//2+1):
# 向下取数
while x < m and matrix[x][y] != -1:
print(matrix[x][y], end=' ')
matrix[x][y] = -1 # 将去过的位置置为-1
x += 1
# 上个循环结束后x多加一次要减回来
x -= 1
# 列值加1,因为第零列在上个循环已经输出,往右推一行
y += 1
# 向右取数
while y < n and matrix[x][y] != -1:
print(matrix[x][y], end=' ')
matrix[x][y] = -1 # 将去过的位置置为-1
y += 1
# 上个循环多加一次减回来
y -= 1
# 往上推一行
x -= 1
# 向上取数
while x >= 0 and matrix[x][y] != -1:
print(matrix[x][y], end=' ')
matrix[x][y] = -1 # 将去过的位置置为-1
x -= 1
# 上个循环使多减一次加回来
x += 1
# 往左推一行
y -= 1
# 向左取数
while y >= 0 and matrix[x][y] != -1:
print(matrix[x][y], end=' ')
matrix[x][y] = -1 # 将去过的位置置为-1
y -= 1
# 上个循环多加一次减回来
y += 1
# 向下推一行
x += 1
3.28 金陵十三钗
题目描述
在电影《金陵十三钗》中有十二个秦淮河的女人要自我牺牲代替十二个女学生去赴日本人的死亡宴会。为了不让日本人发现,自然需要一番乔装打扮。但由于天生材质的原因,每个人和每个人之间的相似度是不同的。由于我们这是编程题,因此情况就变成了金陵n钗。给出n个女人和n个学生的相似度矩阵,求她们之间的匹配所能获得的最大相似度。
所谓相似度矩阵是一个n*n的二维数组
like[i][j]。其中i, j分别为女人的编号和学生的编号,皆从0到n-1编号。like[i][j]是一个0到100的整数值,表示第i个女人和第j个学生的相似度,值越大相似度越大,比如0表示完全不相似,100表示百分之百一样。每个女人都需要找一个自己代替的女学生。最终要使两边一一配对,形成一个匹配。请编程找到一种匹配方案,使各对女人和女学生之间的相似度之和最大。
输入描述
第一行一个正整数n表示有n个秦淮河女人和n个女学生
接下来n行给出相似度,每行n个0到100的整数,依次对应二维矩阵的n行n列。
输出描述
仅一行,一个整数,表示可获得的最大相似度。
输入样例
4
97 91 68 14
8 33 27 92
36 32 98 53
73 7 17 82
输出样例
354
样例说明
最大相似度为91+92+98+73=354
对于70%的数据,n<=10
对于100%的数据,n<=13
# 本题类似n皇后问题,先列举出所有可能,在求其中和最大
def queen(cur=0):
global maxSum
# 判断上行的棋子放置是否有问题
for row in range(cur-1):
# 若该女学生已被其他女人匹配
if res[row] == res[cur-1]:
# 向上回溯
return
# 若匹配完毕
if cur == n:
# 算出当前排列的和
cur_sum = 0
for i in range(n):
cur_sum += matrix[i][res[i]]
# 储存最大和
if cur_sum > maxSum:
maxSum = cur_sum
return
# 遍历每列
for col in range(n):
# 设置秦淮河女人匹配的女学生
res[cur] = col
# 对下一个秦淮河女人进行匹配
queen(cur+1)
n = int(input())
# 相似度矩阵
matrix = [list(map(int, input().split())) for _ in range(n)]
res = [0 for _ in range(n)]
maxSum = 0
queen()
print(maxSum)
3.29 矩阵乘法
题目描述
给定一个N阶矩阵A,输出A的M次幂(M是非负整数)
例如:
A =
1 2
3 4
A的2次幂
7 10
15 22
输入描述
第一行是一个正整数N、M(1<=N<=30, 0<=M<=5),表示矩阵A的阶数和要求的幂数
接下来N行,每行N个绝对值不超过10的非负整数,描述矩阵A的值
输出描述
输出共N行,每行N个整数,表示A的M次幂所对应的矩阵。相邻的数之间用一个空格隔开
输入样例
2 2
1 2
3 4
输出样例
7 10
15 22
# 矩阵乘法
def mul_matrix(matrix1, matrix2, n):
# 存放乘法后的矩阵
res = [[] for _ in range(n)]
# 遍历每个元素
for i in range(n):
for j in range(n):
pos = 0
# 乘法后所得结果该位置的值等于两个数组该行和该列的加权
for c in range(n):
pos += matrix1[i][c] * matrix2[c][j]
res[i].append(pos)
return res
# 输入
n, m = map(int, input().split())
matrix = [[] for _ in range(n)]
for i in range(n):
arr = input().split()
for j in range(n):
matrix[i].append(int(arr[j]))
# 初始化单位矩阵
res = [[1 if i == j else 0 for j in range(n)] for i in range(n)]
# m次幂
for i in range(1, m+1):
res = mul_matrix(res, matrix, n)
# 输出结果
for i in range(n):
for j in range(n):
print(res[i][j], end=' ')
print()
3.30 矩阵面积交
题目描述
平面上有两个矩形,它们的边平行于直角坐标系的X轴或Y轴。对于每个矩形,我们给出它的一对相对顶点的坐标,请你编程算出两个矩形的交的面积。
输入描述
输入仅包含两行,每行描述一个矩形。
在每行中,给出矩形的一对相对顶点的坐标,每个点的坐标都用两个绝对值不超过的实数表示。
输出描述
输出仅包含一个实数,为交的面积。
输入样例
1 1 3 3
2 2 4 4
输出样例
1
rect1 = list(map(float, input().split()))
rect2 = list(map(float, input().split()))
x1 = max(min(rect1[0], rect1[2]), min(rect2[0], rect2[2]))
y1 = max(min(rect1[1], rect1[3]), min(rect2[1], rect2[3]))
x2 = min(max(rect1[0], rect1[2]), max(rect2[0], rect2[2]))
y2 = min(max(rect1[1], rect1[3]), max(rect2[1], rect2[3]))
# 交集的面积
inter = max(x2-x1, 0) * max(y2-y1, 0)
print(inter)
3.31 矩阵求和
题目描述
今天小明的任务是填满这么一张表: 表有n行n列,行和列的编号都从1算起。 其中第i行第j个元素的值是gcd(i, j)的平方,gcd表示最大公约数,以下是这个表的前四行的前四列:
1 1 1 1
1 4 1 4
1 1 9 1
1 4 1 16小明突然冒出一个奇怪的想法,他想知道这张表中所有元素的和。 由于表过于庞大,他希望借助计算机的力量。
输入描述
一行一个正整数n意义见题。
输出描述
一行一个数,表示所有元素的和。由于答案比较大,请输出模 (10^9 + 7)后的结果。
输入样例
4
输出样例
48
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KhPfAxjo-1654839635670)(https://raw.githubusercontent.com/Qiyuan-Z/blog-image/main/img/lanqiao/%E7%9F%A9%E9%98%B5%E6%B1%82%E5%92%8C.png)]
''' 方法一:暴力求解会超时
# 求最大公约数
def gcd(i, j):
while j !=0:
k = i % j
i, j = j, k
return i
n = int(input())
sum_arr = 0
mod = 10 ** 9 + 7
for i in range(1, n+1):
for j in range(1, n+1):
t = gcd(i, j) ** 2
sum_arr += t % mod
print(sum_arr)
'''
'''方法二:欧拉函数(线性筛法)推荐'''
MOD = 10 ** 9 + 7
# 欧拉函数
phi = []
# 存放[1, n/d]中,所有互质对的个数
sum_ = []
# 结果
ans = 0
def euler_table(n):
# 初始化
for _ in range(n + 1):
phi.append(0)
sum_.append(0)
# n=1时的欧拉函数为1
phi[1] = 1
# 求到n为止的欧拉函数(线性筛法)
for i in range(2, n + 1):
# ph[i]为0时代表没遍历过,则此时i为素数
if phi[i] == 0:
j = i
while j <= n:
# 先令phi[j] = j,则ph[j] / i = j / i = i^(k-1)
if phi[j] == 0:
phi[j] = j
# 当i是素数时 phi(i) = i-1
# phi(i^k) = i^(k-1) * (i-1)
# 这里j = i^k
phi[j] = phi[j] // i * (i - 1)
# 进行递推,求得相应的phi[j],使phi[j]上的值不再为0,那么下次遍历i时,若为0,则代表i为素数
j += i
sum_[1] = 1
# 递推,求互质对的个数
for i in range(2, n + 1):
sum_[i] = sum_[i - 1] + phi[i] * 2
n = int(input())
euler_table(n)
for i in range(1, n + 1):
# 将问题转化成了count(d)*d*d
ans = (ans + sum_[n // i] * i % MOD * i) % MOD
print(ans)
3.32 门牌制作
题目描述
小蓝要为一条街的住户制作门牌号。
这条街一共有 2020 位住户,门牌号从 1 到 2020 编号。
小蓝制作门牌的方法是先制作 0 到 9 这几个数字字符,最后根据需要将字符粘贴到门牌上,例如门牌 1017 需要依次粘贴字符 1、0、1、7,即需要 1 个字符 0,2 个字符 1,1 个字符 7。
请问要制作所有的 1 到 2020 号门牌,总共需要多少个字符 2?
这是一道结果填空的题,你只需要算出结果后提交即可。
本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
count = 0
for num in range(1, 2021):
count += str(num).count("2")
print(count)
3.33 迷宫
题目描述
下图给出了一个迷宫的平面图,其中标记为 1 的为障碍,标记为 0 的为可 以通行的地方。
010000
000100
001001
110000迷宫的入口为左上角,出口为右下角,在迷宫中,只能从一个位置走到这 个它的上、下、左、右四个方向之一。 对于上面的迷宫,从入口开始,可以按DRRURRDDDR 的顺序通过迷宫, 一共 10 步。其中 D、U、L、R 分别表示向下、向上、向左、向右走。
对于下面这个更复杂的迷宫(30 行 50 列),请找出一种通过迷宫的方式, 其使用的步数最少,在步数最少的前提下,请找出字典序最小的一个作为答案。 请注意在字典序中D<L<R<U。
data.txt:
01010101001011001001010110010110100100001000101010
00001000100000101010010000100000001001100110100101
01111011010010001000001101001011100011000000010000
01000000001010100011010000101000001010101011001011
00011111000000101000010010100010100000101100000000
11001000110101000010101100011010011010101011110111
00011011010101001001001010000001000101001110000000
10100000101000100110101010111110011000010000111010
00111000001010100001100010000001000101001100001001
11000110100001110010001001010101010101010001101000
00010000100100000101001010101110100010101010000101
11100100101001001000010000010101010100100100010100
00000010000000101011001111010001100000101010100011
10101010011100001000011000010110011110110100001000
10101010100001101010100101000010100000111011101001
10000000101100010000101100101101001011100000000100
10101001000000010100100001000100000100011110101001
00101001010101101001010100011010101101110000110101
11001010000100001100000010100101000001000111000010
00001000110000110101101000000100101001001000011101
10100101000101000000001110110010110101101010100001
00101000010000110101010000100010001001000100010101
10100001000110010001000010101001010101011111010010
00000100101000000110010100101001000001000000000010
11010000001001110111001001000011101001011011101000
00000110100010001000100000001000011101000000110011
10101000101000100010001111100010101001010000001000
10000010100101001010110000000100101010001011101000
00111100001000010000000110111000000001000000001011
10000001100111010111010001000110111010101101111000
'''
path = [[0,1,0,0,0,0],
[0,0,0,1,0,0],
[0,0,1,0,0,1],
[1,1,0,0,0,0]]
'''
path =[]
with open("data.txt") as file:
contents = file.readlines()
for i in contents:
path.append(list(map(int, list(i.strip()))))
# 迷宫的实质就是一个矩阵,即用(x,y)即可表示迷宫内的任意一点,再用一个字符串w来表示路径。
class Node:
def __init__(self, x, y, w):
self.x = x # 记录横坐标
self.y = y # 记录纵坐标
self.w = w # 记录路径
def __str__(self):
return self.w # 输出路径
def up(node):
return Node(node.x - 1, node.y, node.w+"U") # 上的情况
def down(node):
return Node(node.x + 1, node.y, node.w+"D") # 下的情况
def left(node):
return Node(node.x, node.y - 1, node.w+"L") # 左的情况
def right(node):
return Node(node.x, node.y + 1, node.w+"R") # 右的情况
if __name__ == '__main__':
row, col = len(path), len(path[0]) # 矩阵的长和宽
visited = set() # 记录访问过的点
queue = []
node = Node(0, 0, "") # 设置起点
# 存放进队列
queue.append(node)
# 由于每次开始移动前先弹出,若后续没步走,则队列为0,结束
while len(queue) != 0:
moveNode = queue[0] # 设置当前移动点为moveNode
# 开始移动前先弹出
queue.pop(0)
moveStr = str(moveNode.x) + " "+ str(moveNode.y) # 用于记录当前坐标是否走过
# 若没走过则进行记录
if moveStr not in visited:
visited.add(moveStr)
if moveNode.x == row - 1 and moveNode.y == col - 1: # 若到达终点则输出且退出循环
print(len(moveNode.__str__())) # 输出步数
print(moveNode) # 打印路径
break
if moveNode.x < row - 1 : # 首先顺序为下,不能超出边界
# 若没有障碍物,则可以通行
if path[moveNode.x + 1][moveNode.y] == 0:
# 添加进队列
queue.append(down(moveNode))
if moveNode.y > 0: # 第二顺序是左
if path[moveNode.x][moveNode.y - 1] == 0:
queue.append(left(moveNode))
if moveNode.y < col - 1: # 第三顺序是右
if path[moveNode.x][moveNode.y + 1] == 0:
queue.append(right(moveNode))
if moveNode.x > 0: # 最后顺序是上
if path[moveNode.x - 1][moveNode.y] == 0:
queue.append(up(moveNode))
3.34 迷宫2
题目描述
X星球的一处迷宫游乐场建在某个小山坡上。它是由10×10相互连通的小房间组成的。房间的地板上写着一个很大的字母。
我们假设玩家是面朝上坡的方向站立,则:L表示走到左边的房间,R表示走到右边的房间,U表示走到上坡方向的房间,D表示走到下坡方向的房间。
X星球的居民有点懒,不愿意费力思考。他们更喜欢玩运气类的游戏。这个游戏也是如此!
开始的时候,直升机把100名玩家放入一个个小房间内。玩家一定要按照地上的字母移动。
请你计算一下,最后,有多少玩家会走出迷宫?而不是在里边兜圈子。
如果你还没明白游戏规则,可以参看一个简化的4×4迷宫的解说图:
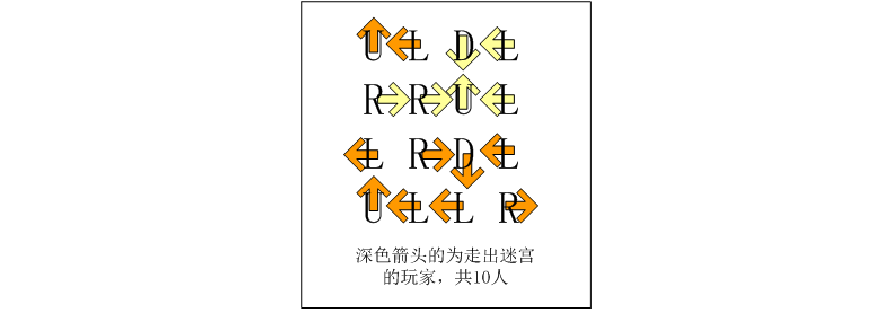
迷宫地图迷宫2.txt如下:
UDDLUULRUL
UURLLLRRRU
RRUURLDLRD
RUDDDDUUUU
URUDLLRRUU
DURLRLDLRL
ULLURLLRDU
RDLULLRDDD
UUDDUDUDLL
ULRDLUURRR
def dfs(x, y):
global count
global rows
global cols
# 走出迷宫,计数+1
if x < 0 or x > rows-1 or y < 0 or y > cols-1:
count += 1
return
# 若当前位置未走过,则标记为走过
if paths[x][y] == 0:
paths[x][y] = 1
# 若已走过,则代表回到原路,走不出迷宫,退出
else:
return
# 获取方向
direction = dataMap[x][y]
# 上
if direction == 'U':
dfs(x-1, y)
# 下
if direction == 'D':
dfs(x+1, y)
# 左
if direction == 'L':
dfs(x, y-1)
# 右
if direction == 'R':
dfs(x, y+1)
# 存储地图
dataMap = []
with open('迷宫2.txt', mode='r', encoding='utf-8') as f:
for line in f.readlines():
dataMap.append(list(line.strip()))
rows = len(dataMap)
cols = len(dataMap[0])
# 记录走出人数
count = 0
for x in range(rows):
for y in range(cols):
# 用于记录走过的轨迹,未走过为0,走过为1
paths = [[0]*cols for _ in range(rows)]
dfs(x, y)
print(count)
3.35 年号字串
题目描述
小明用字母A 对应数字1,B 对应2,以此类推,用Z 对应26。对于27以上的数字,小明用两位或更长位的字符串来对应,例如AA 对应27,AB 对应28,AZ 对应52,LQ 对应329。请问2019 对应的字符串是什么?
ans = ''
n = 2019
while n != 0:
t = n % 26
n = n // 26
ans += chr(64+t)
print(ans[::-1])
3.36 跑步锻炼
题目描述
小蓝每天都锻炼身体。
正常情况下,小蓝每天跑1千米。如果某天是周一或者月初(1日),为了激励自己,小蓝要跑2千米。如果同时是周一或月初,小蓝也是跑2千米。
小蓝跑步已经坚持了很长时间,从2000年1月1日周六(含)到2020年10月1日周四(含)。请问这段时间小蓝总共跑步多少千米
# 遍历日期可以用到datetime这个内置库
import datetime
# 一个是初始日期,一个是结束日期,因为range函数是半开半闭,所以结束日期要比要求的大一天
start = datetime.datetime(2000, 1, 1, 0, 0, 0)
end = datetime.datetime(2020, 10, 2, 0, 0, 0)
sum = 0
# 用结束日期-初始日期就能得到之间相差的天数。也就是遍历次数
for day in range(int((end - start).days)):
# 再用初始天数,加上每次遍历的天数,就可以得到当前日期
# 使用timedelta可以很方便的在日期上做天days,小时hour,分钟,秒,毫秒,微妙的时间计算
cur_date = start + datetime.timedelta(days=day)
# 用.strftime()方法可以访问这一天的各种参数
# 获取天数和星期,为1日或星期1跑2km
if (cur_date.strftime('%d')) == '01' or (cur_date.strftime('%w')) == '1':
sum += 2
# 否则为1km
else:
sum += 1
print(sum)
3.37 平面切分
题目描述
平面上有 N条直线,其中第i条直线是 y = Ai*x + B。
请计算这些直线将平面分成了几个部分。
输入描述
第一行包含一个整数N。
以下N行,每行包含两个整数Ai, Bi。
输出描述
一个整数代表答案。
输入样例
3
1 1
2 2
3 3
输出样例
6
# 在同一个平面内,如果添加的每一条直线互不相交,则每添加一条直线,就会增加一个平面;
# 当添加一条直线时,这条直线与当前平面内已有直线每产生一个不同位置的交点时
# 这条直线对平面总数量的贡献会额外增多一个
n = int(input())
lines = [tuple(map(int, input().split())) for _ in range(n)]
#这里是去掉重复直线
lines = list(set(lines))
n = len(lines)
#得到两条直线交点,若平行,返回None
def getnode(lines1, lines2):
A1 = lines1[0]
B1 = lines1[1]
A2 = lines2[0]
B2 = lines2[1]
if A1 - A2 == 0:
return
x = (B2 - B1) / (A1 - A2)
y = A1 * x + B1
return (x, y)
# 每条线对分割平面的贡献 默认为1,即两两平行
ci = [1] * n
# 交点去重
node = set()
for i in range(1, n):
node.clear()
# 判断新增加的线与之前线是否有交点
for j in range(i):
tmp = getnode(lines[i], lines[j])
if tmp == None: continue
node.add(tmp)
# 每有个交点贡献多1
ci[i] += len(node)
print(sum(ci) + 1)
3.38 全球变暖
题目描述
你有一张某海域NxN像素的照片,".“表示海洋、”#"表示陆地,如下所示:
....... .##.... .##.... ....##. ..####. ...###. .......其中"上下左右"四个方向上连在一起的一片陆地组成一座岛屿。例如上图就有2座岛屿。
由于全球变暖导致了海面上升,科学家预测未来几十年,岛屿边缘一个像素的范围会被海水淹没。具体来说如果一块陆地像素与海洋相邻(上下左右四个相邻像素中有海洋),它就会被淹没。
例如上图中的海域未来会变成如下样子:
....... ....... ....... ....... ....#.. ....... .......请你计算:依照科学家的预测,照片中有多少岛屿会被完全淹没。
输入描述
第一行包含一个整数N。 (1 <= N <= 1000)
以下N行N列代表一张海域照片。
照片保证第1行、第1列、第N行、第N列的像素都是海洋。
输出描述
一个整数表示答案。
输入样例
7
…
.##…
.##…
…##.
…####.
…###.
…
输出样例
1
'''
思路:
在接收初始图之后,首先搜索查找初始岛屿数,在找到一个岛屿后,对整个岛屿进行标记,防止重复计数。
随后再次进行搜索,如果有四周均为陆地的坐标,则标记此坐标未被淹没。
最后查找所有未被淹没的坐标,并将坐标所处的整个岛标记,防止重复计数。
初始岛屿数量减去未被淹没岛的数量,即为被淹没的岛的数量。
'''
'''例子1:
输入:
7
.......
.##....
.##....
....##.
..####.
...###.
.......
输出:
1
'''
'''例子2:
输入:
5
.....
.#.#.
..#..
.#.#.
.....
输出:
5
'''
# 用于搜寻岛屿的数量
def dfs(x, y):
# 如果该点是海洋或者已被访问过则跳过
if maps[x][y] == '.' or maps[x][y] == '1':
return
# 否则将该点标记为1,代表已访问过
maps[x][y] = '1'
# 搜索该点四周的点
dfs(x+1, y)
dfs(x-1, y)
dfs(x, y+1)
dfs(x, y-1)
n = int(input())
# 初始海洋照片
maps = [list(input()) for _ in range(n)]
# 初始岛屿个数
first_num = 0
# 剩余岛屿个数
res_num = 0
# 初始岛屿个数
for x in range(n):
for y in range(n):
if maps[x][y] == '#':
dfs(x, y)
first_num += 1
# 海域未来模样
for x in range(n):
for y in range(n):
# 照片保证第1行、第1列、第N行、第N列的像素都是海洋。
if x == 0 or x == n-1 or y == 0 or y == n-1 or maps[x][y] == '.':
continue
# 四周都是陆地则标记为2,代表该岛屿不会被淹没
if maps[x+1][y] != '.' and maps[x-1][y] != '.' and maps[x][y+1] != '.' and maps[x][y-1] != '.':
maps[x][y] = '2'
# 否则标记为3代表将被淹没
else:
maps[x][y] = '3'
# 最后查找剩余多少个岛屿
for x in range(n):
for y in range(n):
if maps[x][y] == '2':
dfs(x, y)
res_num += 1
# 输出淹没了多少座岛
print(first_num - res_num)
3.39 蛇形填数
题目描述
如下图所示,小明用从1开始的正整数“蛇形”填充无限大的矩阵。
1 2 6 7 15 …
3 5 8 14 …
4 9 13 …
10 12 …
11 …
…
容易看出矩阵第二行第二列中的数是5。请你计算矩阵中第20行第20列的数是多少?
lis = [[0 for i in range(40)] for j in range(40)]
num = 1 # 记录当前的数
for i in range(1, 41): # 层数
for j, k in zip(list(range(i)), list(range(num, num + i))):
if i % 2 == 0: # 偶数层
lis[j][i-j-1] = k
else:
lis[i-j-1][j] = k
num += i
print(lis[19][19])
3.40 石子游戏
题目描述
石子游戏的规则如下:
地上有n堆石子,每次操作可选取两堆石子(石子个数分别为x和y)并将它们合并,操作的得分记为(x+1)×(y+1),对地上的石子堆进行操作直到只剩下一堆石子时停止游戏。
请问在整个游戏过程中操作的总得分的最大值是多少?
输入描述
输入数据的第一行为整数n,表示地上的石子堆数;第二行至第n+1行是每堆石子的个数。
输出描述
程序输出一行,为游戏总得分的最大值。
输入样例
10
5105
19400
27309
19892
27814
25129
19272
12517
25419
4053
输出样例
15212676150
1≤n≤1000,1≤一堆中石子数≤50000
# 堆数
n = int(input())
# 每堆石子的个数
data = [int(input()) for i in range(n)]
# 先排序
data.sort()
# 分数
result = 0
# 贪心算法,每次取最大两堆合并
while len(data) != 1:
result += (data[-1] + 1) * (data[-2] + 1)
data[-2] += data[-1]
data.pop(-1)
print(result)
3.41 时间转换
题目描述
给定一个以秒为单位的时间t,要求用H:M:S的格式来表示这个时间。H表示时间,M表示分钟,而S表示秒,它们都是整数且没有前导的“0”。例如,若t=0,则应输出是“0:0:0”;若t=3661,则输出“1:1:1”。
输入描述
输入只有一行,是一个整数t(0<=t<=86399)。
输出描述
输出只有一行,是以“H:M:S”的格式所表示的时间,不包括引号。
输入样例
0
输出样例
0:0:0
输入样例
5436
输出样例
1:30:36
t = int(input())
print('%d:%d:%d'%(t//3600, t%3600//60, t%3600%60))
3.42 数的读法
题目描述
Tom教授正在给研究生讲授一门关于基因的课程,有一件事情让他颇为头疼:一条染色体上有成千上万个碱基对,它们从0开始编号,到几百万,几千万,甚至上亿。比如说,在对学生讲解第1234567009号位置上的碱基时,光看着数字是很难准确的念出来的。
所以,他迫切地需要一个系统,然后当他输入1234567009时,会给出相应的念法:十二亿三千四百五十六万七千零九,用汉语拼音表示为shi er yi san qian si bai wu shi liu wan qi qian ling jiu,这样他只需要照着念就可以了。
你的任务是帮他设计这样一个系统:给定一个阿拉伯数字串,你帮他按照中文读写的规范转为汉语拼音字串,相邻的两个音节用一个空格符格开。
注意必须严格按照规范,比如说“10010”读作“yi wan ling yi shi”而不是“yi wan ling shi”,“100000”读作“shi wan”而不是“yi shi wan”,“2000”读作“er qian”而不是“liang qian”。
输入描述
有一个数字串,数值大小不超过2,000,000,000。
输出描述
是一个由小写英文字母,逗号和空格组成的字符串,表示该数的英文读法。
输入样例
1234567009
输出样例
shi er yi san qian si bai wu shi liu wan qi qian ling jiu
n = input()
# 数值读法
pin_yin = {'0': 'ling', '1': 'yi', '2': 'er', '3': 'san', '4': 'si', '5': 'wu',
'6': 'liu', '7': 'qi', '8': 'ba', '9': 'jiu'}
# 特殊位置读法
pin_yin_2 = {0: '', 1: 'shi', 2: 'bai', 3: 'qian', 4: 'wan', 5: 'shi',
6: 'bai', 7: 'qian', 8: 'yi', 9: 'shi'}
# 个位的索引
l = len(n) - 1
# 从最高位开始遍历
for i in range(len(n)):
# 当前位的值
cur = int(n[i])
# 当前位的值不为0时的读法
if cur != 0:
# 个位与当前位索引相差1,、5、9,即在十位,十万位,十亿位置且开头为1时
# 不读出1
# 如10, shi ; 100000, shi wan; 1000000000, shi yi
if cur == 1 and i == 0 and (l - i == 1 or l - i == 5 or l - i == 9):
print(pin_yin_2[l - i], end=' ')
continue
# 输出当前数的读法
print(pin_yin[n[i]], end=' ')
# 输出指定位置的读法
print(pin_yin_2[l - i], end=' ')
# 处理当前位的值为0的读法问题
else:
# 如果此0是在万位或亿位,则读出万或亿
# 如shi wan, shi yi
if l - i == 4 or l - i == 8:
print(pin_yin_2[l - i], end=' ')
# 如果后一位仍然为0,或者,当前是最后一位,则不读此0
elif (i < l and n[i + 1] == '0') or i == l:
continue
else:
# 否则才读出这个零
print(pin_yin['0'], end=' ')
3.43 数的分解
题目描述
把 2019 分解成 3 个各不相同的正整数之和,并且要求每个正整数都不包含数字 2 和 4,一共有多少种不同的分解方法?注意交换 3 个整数的顺序被视为同一种方法,例如 1000+1001+18 和 1001+1000+18 被视为同一种。
count = 0
# 因为三个数要各不相同 i从小到大 j从小到大并比i大,则为了保证不重,k也因比j大
for i in range(1, 2019):
if '2' not in str(i) and '4' not in str(i):
for j in range(i + 1, 2019):
if '2' not in str(j) and '4' not in str(j):
k = 2019 - i - j
if k > j and '2' not in str(k) and '4' not in str(k):
count += 1
print(count)
3.44 数列求值
题目描述
本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。
给定数列 1, 1, 1, 3, 5, 9, 17,⋯,从第 4 项开始,每项都是前 3 项的和。求第 20190324 项的最后 4 位数字。
f0=1
f1=1
f2=1
for i in range(3, 20190324):
result = (f0 + f1 + f2) % 10000
f0 = f1
f1 = f2
f2 = result
print(result)
3.45 数位递增的数
题目描述
一个正整数如果任何一个数位不大于右边相邻的数位,则称为一个数位递增的数,例如1135是一个数位递增的数,而1024不是一个数位递增的数。
给定正整数 n,请问在整数 1 至 n 中有多少个数位递增的数?
输入描述
输入的第一行包含一个整数n。
输出描述
输出一行包含一个整数,表示答案。
输入样例
30
输出样例
26
对于 40% 的评测用例,1 <= n <= 1000。
对于 80% 的评测用例,1 <= n <= 100000。
对于所有评测用例,1 <= n <= 1000000。
n = int(input())
count = 0
for i in range(1, n+1):
num = str(i)
if len(num) == 1:
count += 1
else:
flag = True
for j in range(len(num) - 1):
if num[j] > num[j+1]:
flag = False
break
if flag:
count += 1
print(count)
3.46 数字9
题目描述
在1至2019中,有多少个数的数位中包含数字9?
注意,有的数中的数位中包含多个9,这个数只算一次。例如,1999这个数包含数字9,在计算只是算一个数。
count = 0
for num in range(1, 2020):
if '9' in str(num):
count += 1
print(count)
3.47 数字三角形
题目描述
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gEFTOQq2-1654839635671)(https://raw.githubusercontent.com/Qiyuan-Z/blog-image/main/img/lanqiao/tri.png)]
图为一个数字三角形。 请编一个程序计算从顶至底的某处的一条路径,使该路径所经过的数字的总和最大。
● 每一步可沿左斜线向下或右斜线向下走;
● 1<三角形行数≤100;
● 三角形中的数字为整数0,1,…99;
输入描述
首先读到的是三角形的行数。
接下来描述整个三角形
输出描述
最大总和(整数)
输入样例
5
7
3 8
8 1 0
2 7 4 4
4 5 2 6 5
输出样例
30
def pathMax(path, x, y, leftNum, rightNum):
global n
# 添加当前路径
path.append(pyramid[x][y])
# 如果走到底返回
if x == n-1:
# 左下和右下次数相差不超过1,记录路径
if abs(leftNum - rightNum) <= 1:
paths.append(path)
return
pleft = []
pright = []
pleft += path
pright += path
# 左下走
pathMax(pleft, x+1, y, leftNum+1, rightNum)
# 右下走
pathMax(pright, x+1, y+1, leftNum, rightNum+1)
n = int(input())
pyramid = [list(map(int, input().split())) for _ in range(n)]
# 用于所有可能路径
paths = []
pathMax([], 0, 0, 0, 0)
res = 0
# 返回最大路径
for path in paths:
tmp = sum(path)
if tmp > res:
res = tmp
print(res)
3.48 特别数的和
题目描述
小明对数位中含有2 、 0 、 1 、 9 的数字很感兴趣(不包括前导 0 ),在 1 到 40 中这样的数包括 1 、 2 、 9 、 10 至 32 、 39 和 40 ,共 28 个,他们的和是 574 。请问,在1 到 n 中,所有这样的数的和是多少?
输入描述
输入一行包含一个整数n。
输出描述
输出一行,包含一个整数,表示满足条件的数的和。
输入样例
40
输出样例
574
res = 0
for i in range(1, int(input())+1):
if '2' in str(i) or '0' in str(i) or '1' in str(i) or '9' in str(i):
res += i
print(res)
3.49 特殊回文数
题目描述
123321是一个非常特殊的数,它从左边读和从右边读是一样的。
输入一个正整数n, 编程求所有这样的五位和六位十进制数,满足各位数字之和等于n 。
输入描述
输入一行,包含一个正整数n。
输出描述
按从小到大的顺序输出满足条件的整数,每个整数占一行。
输入样例
52
输出样例
899998
989989
998899
1<=n<=54
import time
n = int(input())
start = time.perf_counter()
#6位数,n一定为偶数
if (n % 2 == 0):
s = n // 2
if s <= 27:
for i in range(1, 10):
for j in range(10):
if (s - i - j) < 10 and (s - i - j) >= 0:
print(int(str(i)+str(j)+str(s-i-j)*2+str(j)+str(i)))
#5位数,n减去中间那个数一定为偶数
for i in range(9, -1, -1):
if (n - i) % 2 == 0:
s = (n - i) // 2
if s <= 18:
for j in range(1, 10):
if (s - j) >= 0 and (s - j) < 10:
print(int(str(j)+str(s-j)+str(i)+str(s-j)+str(j)))
end = time.perf_counter()
print(end - start)
3.50 完美的代价
题目描述
回文串,是一种特殊的字符串,它从左往右读和从右往左读是一样的。小龙龙认为回文串才是完美的。现在给你一个串,它不一定是回文的,请你计算最少的交换次数使得该串变成一个完美的回文串。
交换的定义是:交换两个相邻的字符,例如mamad
第一次交换 ad : mamda
第二次交换 md : madma
第三次交换 ma : madam (回文!完美!)
输入描述
第一行是一个整数N,表示接下来的字符串的长度(N <= 8000)
第二行是一个字符串,长度为N.只包含小写字母
输出描述
如果可能,输出最少的交换次数。
否则输出Impossible
输入样例
5
mamad
输出样例
3
n = int(input())
arr = list(input())
# 统计出现奇数次的字符的个数
flag = 0
# 交换次数
count = 0
# 由于最后形成回文,只需遍历一半即可
for i in range(n//2):
# 从另一半寻找是否有字符与之相等
for j in range(n-1, i - 1, -1):
# 没找到
if j == i:
# 记录奇数个数的字符
flag += 1
# 如果有一个字符出现的次数是奇数次数,而且n是偶数,那么不可能构成回文
if n % 2 == 0 and flag == 1:
print('Impossible')
exit()
# 如果奇数次数的字符出现两个以上,那么不可能构成回文
if flag > 1:
print('Impossible')
exit()
# 若找到
elif arr[j] == arr[i]:
# 一直将其交换到对应位置
for j in range(j, n-1-i):
arr[j], arr[j+1] = arr[j+1], arr[j]
# 记录交换次数
count += 1
break
print(count)
3.51 完全二叉树的权值
题目描述
给定一棵包含 N 个节点的完全二叉树,树上每个节点都有一个权值,按从上到下、从左到右的顺序依次是 A1, A2, · · · AN,如下图所示:
现在小明要把相同深度的节点的权值加在一起,他想知道哪个深度的节点权值之和最大?如果有多个深度的权值和同为最大,请你输出其中最小的深度。
注:根的深度是 1。
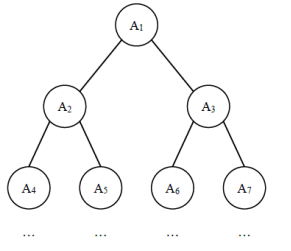
输入描述
第一行包含一个整数 N。
第二行包含 N 个整数 A1, A2, · · · AN 。
输出描述
输出一个整数代表答案。
输入样例
7
1 6 5 4 3 2 1
输出样例
2
对于所有评测用例, 1 ≤ N ≤ 100000, −100000 ≤ Ai ≤ 100000。
n = int(input())
data = list(map(int, input().split()))
# 二叉树深度
deep = 1
# 用于记录权值最大的深度
max_deep = deep
# 记录最大权重
max_sum = 0
# 深度为deep的完全二叉树节点个数为(2^n)-1
while 2 ** deep - 1 <= n:
# 当前深度的节点个数 = 当前深度完全二叉树的总个数-上层深度完全二叉树的总个数
data_sum = sum(data[2 ** (deep - 1) - 1: 2 ** deep - 1])
# 记录最大权重所在深度
if max_sum < data_sum:
max_sum = data_sum
max_deep = deep
deep += 1
# 输出最大权重所在深度
print(max_deep)
3.52 晚会节目单
题目描述
小明要组织一台晚会,总共准备了 n 个节目。然后晚会的时间有限,他只能最终选择其中的 m 个节目。
这 n个节目是按照小明设想的顺序给定的,顺序不能改变。
小明发现,观众对于晚会的喜欢程度与前几个节目的好看程度有非常大的关系,他希望选出的第一个节目尽可能好看,在此前提下希望第二个节目尽可能好看,依次类推。
小明给每个节目定义了一个好看值,请你帮助小明选择出 m 个节目,满足他的要求。
输入描述
输入的第一行包含两个整数 n, m ,表示节目的数量和要选择的数量。
第二行包含 n 个整数,依次为每个节目的好看值。
输出描述
输出一行包含 m 个整数,为选出的节目的好看值。
输入样例
5 3
3 1 2 5 4
输出样例
3 5 4
样例说明
选择了第1, 4, 5个节目。
对于 30% 的评测用例,1 <= n <= 20;
对于 60% 的评测用例,1 <= n <= 100;
对于所有评测用例,1 <= n<= 100000,0 <= 节目的好看值 <= 100000。
n, m = map(int, input().split())
tvlist = list(map(int, input().split()))
# 选最大
res = []
# 开始索引
index = 0
# 当前个数为0
count = 0
# 直到选满m个
while count < m:
# 从选出的值对应的索引序号后开始到n - m + count中选
res.append(max(tvlist[index: n - m + count + 1]))
index = tvlist[index: n - m + count + 1].index(res[count]) + index + 1
# 计数
count += 1
# 输出
print(*res)
# n,m =map(int,input().split())
# tvlist = list(map(int, input().split()))
# maxTv= tvlist.copy()
# maxTv.sort(reverse=True)
# maxTv = maxTv[:m]
# count = 0
# for tv in tvlist:
# if tv in maxTv:
# print(tv, end=' ')
# count += 1
# if count == m:
# break
3.53 芯片测试
题目描述
有n(2≤n≤20)块芯片,有好有坏,已知好芯片比坏芯片多。
每个芯片都能用来测试其他芯片。用好芯片测试其他芯片时,能正确给出被测试芯片是好还是坏。而用坏芯片测试其他芯片时,会随机给出好或是坏的测试结果(即此结果与被测试芯片实际的好坏无关)。
给出所有芯片的测试结果,问哪些芯片是好芯片。
输入描述
输入数据第一行为一个整数n,表示芯片个数。
第二行到第n+1行为n*n的一张表,每行n个数据。表中的每个数据为0或1,在这n行中的第i行第j列(1≤i, j≤n)的数据表示用第i块芯片测试第j块芯片时得到的测试结果,1表示好,0表示坏,i=j时一律为1(并不表示该芯片对本身的测试结果。芯片不能对本身进行测试)。
输出描述
按从小到大的顺序输出所有好芯片的编号
输入样例
3
1 0 1
0 1 0
1 0 1
输出样例
1 3
n = int(input())
arr = [[] for _ in range(n)]
for i in range(n):
arr_ = input().split()
for j in range(n):
arr[i].append(int(arr_[j]))
# 既然好芯片比坏芯片多,那么我们只需记录每一列0的个数就行了,若个数超过n/2,则此芯片为坏芯片
for j in range(n):
count = 0
for i in range(n):
if arr[i][j] == 0:
count += 1
if count > n / 2:
continue
print(j+1, end=' ')
3.54 幸运顾客
题目描述
为了吸引更多的顾客,某商场决定推行有奖抽彩活动。“本商场每日将产生一名幸运顾客,凡购买30元以上商品者均有机会获得本商场提供的一份精美礼品。”该商场的幸运顾客产生方式十分奇特:每位顾客可至抽奖台抽取一个幸运号码,该商场在抽奖活动推出的第i天将从所有顾客中(包括不在本日购物满30元者)挑出幸运号第i小的顾客作为当日的幸运顾客。该商场的商品本就价廉物美,自从有奖活动推出后,顾客更是络绎不绝,因此急需你编写一个程序,为他解决幸运顾客的产生问题。
输入描述
第1行一个整数N,表示命令数。
第2~N+1行,每行一个数,表示命令。如果x>=0,表示有一顾客抽取了号码x;如果x=-1,表示傍晚抽取该日的幸运号码。
输出描述
对应各命令-1输出幸运号码;每行一个号码。(两个相同的幸运号看作两个号码)
输入样例
6
3
4
-1
-1
3
-1
输出样例
3
4
4
共10组数据。
对100%的数据,N=所有命令为-1或int范围内的非负数,前i的命令中-1的数量不超过[i/2](向下取整)。
n = int(input())
# 存放号码
consumer = []
# 统计-1的个数
ans = 0
# 存放结果
res = []
for i in range(n):
data = int(input())
if data != -1:
consumer.append(data)
# 排序
consumer.sort()
else:
res.append(consumer[ans])
ans += 1
print(res)
3.55 序列计数
题目描述
小明想知道,满足以下条件的正整数序列的数量:
第一项为n;
第二项不超过n;
从第三项开始,每一项小于前两项的差的绝对值。
请计算,对于给定的n,有多少种满足条件的序列。
输入描述
输入一行包含一个整数n。
输出描述
输出一个整数,表示答案。答案可能很大,请输出答案除以10000的余数。
输入样例
4
输出样例
7
样例说明
以下是满足条件的序列:
4 1
4 1 1
4 1 2
4 2
4 2 1
4 3
4 4
对于 20% 的评测用例,1 <= n <= 5;
对于 50% 的评测用例,1 <= n <= 10;
对于 80% 的评测用例,1 <= n <= 100;
对于所有评测用例,1 <= n <= 1000。
# 用于派生下一项
def next_item(res):
new_res = []
# 当前序列最后两项的绝对差
ab = abs(res[-2] - res[-1])
# 若能派生出下一项
for i in range(1, ab):
# 则新序列为当前序列加下一项
new_res.append(res + [i])
return new_res
# 第一项
n = int(input())
# 用于记录序列
res_list = []
# 用于记录可派生项
accept_list = []
# 用于循环
temp_list = []
# 计数
count = 0
# 第二项
for i in range(1, n+1):
# 记录此时的第一项和第二项
res_list.append([n, i])
# 记录此时的序列用于循环
temp_list += res_list
while len(temp_list) > 0:
for res in temp_list: # 判断temp_list的每一项
next_ = next_item(res) # 判断这项可以再派生下一项
# 添加记录到accept_list
accept_list += next_
temp_list.clear() # 清空
res_list = accept_list + res_list # 把新派生出的项加到res_list,res_list此时已包含两项加新派生的项
temp_list += accept_list # 新派生的项加到temp_list进行下次循环用
accept_list.clear() # 清空
# 输出结果
for i in res_list:
print(i, end=' ')
print()
print(len(res_list) % 10000)
3.56 寻找2020
题目描述
小蓝有一个数字矩阵,里面只包含数字 0 和 2。小蓝很喜欢 2020,他想找到这个数字矩阵中有多少个 2020 。
小蓝只关注三种构成 2020 的方式:
• 同一行里面连续四个字符从左到右构成 2020。
• 同一列里面连续四个字符从上到下构成 2020。
• 在一条从左上到右下的斜线上连续四个字符,从左上到右下构成 2020。例如,对于下面的矩阵:
220000
000000
002202
000000
000022
002020
一共有 5 个 2020。其中 1 个是在同一行里的,1 个是在同一列里的,3 个是斜线上的。小蓝的矩阵比上面的矩阵要大,由于太大了,他只好将这个矩阵放在了一个文件里面,在试题目录下有一个文件
2020.txt,里面给出了小蓝的矩阵。请帮助小蓝确定在他的矩阵中有多少个 2020。
2020.txt:
220000
000000
002202
000000
000022
002020
nums, result=[], 0
with open("2020.txt") as f:
for line in f.readlines():
nums.append(list(line.strip()))
move=[[0, 1],[1, 0],[1, 1]]
for x in range(len(nums)):
for y in range(len(nums[0])):
for xx, yy in move:
num = str(nums[x][y])
for m in range(1, 4):
x_, y_= x + xx * m, y + yy * m
if 0 <= x_ < len(nums) and 0 <= y_ <len(nums[0]):
num += str(nums[x_][y_])
else:
break
if num == '2020':
result += 1
print(result)
3.57 杨辉三角
题目描述
杨辉三角形又称Pascal三角形,它的一个重要性质是:三角形中的每个数字等于它两肩上的数字相加。
下面给出了杨辉三角形的前4行:
1
1 1
1 2 1
1 3 3 1
给出n,输出它的前n行。
输入描述
输入包含一个数n。
输出描述
输出杨辉三角形的前n行。每一行从这一行的第一个数开始依次输出,中间使用一个空格分隔。请不要在前面输出多余的空格。
输入样例
4
输出样例
1
1 1
1 2 1
1 3 3 1
1 <= n <= 34。
n = int(input())
triangle_yang = [[0 for j in range(i+1)] for i in range(n)]
triangle_yang[0][0] = 1
for i in range(1, n):
# 每一行的第一列和最后一列为1
triangle_yang[i][0], triangle_yang[i][-1] = 1, 1
# 其余为两肩数值之和
for j in range(1, i):
triangle_yang[i][j] = triangle_yang[i-1][j-1] + triangle_yang[i-1][j]
for i in range(n): # 输出杨辉三角
for j in range(i+1):
print(triangle_yang[i][j], end=' ')
print()
3.58 叶节点数
题目描述
一棵包含有2019个结点的二叉树,最多包含多少个叶结点?
# n为深度
n = 1
while 2 ** n - 1 < 2019:
n += 1
# 2019节点多于深度为n-1的二叉树,小于深度为n的二叉树,通过普通的数学计算,可得最后层的叶子节点数
print(2 ** n - 1 - (2 ** (n - 1) - 1) - (2 ** n - 1 - 2019) // 2)
3.59 音节判断
题目描述
小明对类似于 hello 这种单词非常感兴趣,这种单词可以正好分为四段,第一段由一个或多个辅音字母组成,第二段由一个或多个元音字母组成,第三段由一个或多个辅音字母组成,第四段由一个或多个元音字母组成。
给定一个单词,请判断这个单词是否也是这种单词,如果是请输出yes,否则请输出no。
元音字母包括 a, e, i, o, u,共五个,其他均为辅音字母。
输入描述
输入一行,包含一个单词,单词中只包含小写英文字母。
输出描述
输出答案,或者为yes,或者为no。
输入样例
lanqiao
输出样例
yes
输入样例
world
输出样例
no
str1 = input()
alpha = ['a', 'e', 'i', 'o', 'u']
count = 0
flag = True
for i in range(len(str1)):
if str1[i] in alpha and str1[i-1] not in alpha:
count += 1
if count == 2 and str1[i] not in alpha:
flag = False
if(flag and count == 2):
print('yes')
else:
print('no')
3.60 预测身高
题目描述
生理卫生老师在课堂上娓娓道来:
你能看见你未来的样子吗?显然不能。但你能预测自己成年后的身高,有公式:
男孩成人后身高=(父亲身高+母亲身高)/ 2 * 1.08
女孩成人后身高=(父亲身高*0.923+母亲身高)/ 2
数学老师听见了,回头说:这是大样本统计拟合公式,准确性不错。
生物老师听见了,回头说:结果不是绝对的,影响身高的因素很多,比如营养、疾病、体育锻炼、睡眠、情绪、环境因素等。
老师们齐回头,看见同学们都正在预测自己的身高。
毛老师见此情形,推推眼镜说:何必手算,编程又快又简单…
约定:
身高的单位用米表示,所以自然是会有小数的。
男性用整数1表示,女性用整数0表示。
预测的身高保留三位小数
输入描述
用空格分开的三个数,整数 小数 小数
分别表示:性别 父亲身高 母亲身高
输出描述
一个小数,表示根据上述表示预测的身高(保留三位小数)
输入样例
1 1.91 1.70
输出样例
1.949
输入样例
0 1.00 2.077
输出样例
1.500
父母身高范围(0,3]
时间限制1.0秒
sex, dad, mom = map(float, input().split())
if int(sex) == 0:
height = (dad * 0.923 + mom) / 2
else:
height = (dad + mom) / 2*1.08
print('%.3f' % height)
3.61 约数个数
题目描述
1200000有多少个约数(只计算正约数)。
count = 0
# 根据对称,只要到根号即可
for i in range(1, int(float(1200000)**0.5) + 1):
if 1200000 % i == 0:
count += 2
print(count)
3.62 长草
题目描述
小明有一块空地,他将这块空地划分为 n 行 m 列的小块,每行和每列的长度都为 1。
小明选了其中的一些小块空地,种上了草,其他小块仍然保持是空地。
这些草长得很快,每个月,草都会向外长出一些,如果一个小块种了草,则它将向自己的上、下、左、右四小块空地扩展,这四小块空地都将变为有草的小块。
请告诉小明,k 个月后空地上哪些地方有草。
输入描述
输入的第一行包含两个整数 n, m。
接下来 n 行,每行包含 m 个字母,表示初始的空地状态,字母之间没有空格。如果为小数点,表示为空地,如果字母为 g,表示种了草。
接下来包含一个整数 k。
输出描述
输出 n 行,每行包含 m 个字母,表示 k 个月后空地的状态。如果为小数点,表示为空地,如果字母为 g,表示长了草。
输入样例
4 5
.g…
…
…g…
…
2
输出样例
gggg.
gggg.
ggggg
.ggg.
def grow(x, y):
for offset in R:
x1 = x + offset[0]
y1 = y + offset[1]
if y1 >= 0 and y1 < m and x1 >= 0 and x1 < n and area[x1][y1] == '.':
area[x1][y1] = 'g'
flag[x1][y1] = 1
n, m = map(int, input().split())
area = [list(input()) for _ in range(n)]
k = int(input())
# 上下左右
R = [(-1, 0), (0, -1), (1, 0), (0, 1)]
# 长草月数
for month in range(k):
# 记录已经生长过的草位置
flag = [[0 for _ in range(m)] for _ in range(n)]
for i in range(n):
for j in range(m):
if area[i][j] == 'g' and flag[i][j] == 0:
flag[i][j] = 1
grow(i, j)
#输出第k月长草情况
for row in area:
print(''.join(row))
3.63 长整数加法
题目描述
输入两个整数a和b,输出这两个整数的和。a和b都不超过100位。
输入描述
输入包括两行,第一行为一个非负整数a,第二行为一个非负整数b。两个整数都不超过100位,两数的最高位都不是0。
输出描述
输出一行,表示a + b的值。
输入样例
20100122201001221234567890
2010012220100122
输出样例
20100122203011233454668012
arr1 = input()
arr2 = input()
# 比较两者长度,进行补0
length = len(arr1) - len(arr2)
if length > 0:
arr2 = '0' * length + arr2
else:
arr1 = '0' * (-length) + arr1
# 存放结果
result = [0 for i in range(len(arr1)+1)]
# 进位
k = 0
for i in range(len(arr1)):
# 从个位开始加,同时加上进位
sum = k + int(arr1[len(arr1)-i-1]) + int(arr2[len(arr1)-i-1])
# 从个位开始存放结果
result[len(arr1) - i] = sum % 10
# 设置进位
k = sum // 10
# 最高位进位
if k != 0:
result[0] = k
# 输出结果
for i in range(len(arr1)+1):
# 排除最高位为0的情况
if result[0] == 0 and i == 0:
continue
print(result[i], end='')
3.64 装饰珠
题目描述
在怪物猎人这一款游戏中,玩家可以通过给装备镶嵌不同的装饰珠来获取 相应的技能,以提升自己的战斗能力。
已知猎人身上一共有 6 件装备,每件装备可能有若干个装饰孔,每个装饰孔有各自的等级,可以镶嵌一颗小于等于自身等级的装饰珠 (也可以选择不镶嵌)。
装饰珠有 M 种,编号 1 至 M,分别对应 M 种技能,第 i 种装饰珠的等级为
,只能镶嵌在等级大于等于
对第 i 种技能来说,当装备相应技能的装饰珠数量达到个时,会产生
的价值,镶嵌同类技能的数量越多,产生的价值越大,即
。但每个技能都有上限
(1≤
的价值。
对于给定的装备和装饰珠数据,求解如何镶嵌装饰珠,使得 6 件装备能得到的总价值达到最大。
输入描述
输入的第 1 至 6 行,包含 6 件装备的描述。其中第i行的第一个整数
表示第i件装备的装饰孔数量。后面紧接着
第 7 行包含一个正整数 M,表示装饰珠 (技能) 种类数量。
第 8 至 M + 7 行,每行描述一种装饰珠 (技能) 的情况。每行的前两个整数(1≤
(1≤
。
其中1 ≤
输出描述
输出一行包含一个整数,表示能够得到的最大价值。
输入样例
1 1
2 1 2
1 1
2 2 2
1 1
1 3
3
1 5 1 2 3 5 8
2 4 2 4 8 15
3 2 5 10
输出样例
20
样例说明
按照如下方式镶嵌珠子得到最大价值 20,括号内表示镶嵌的装饰珠的种类编号:
1: (1)
2: (1) (2)
3: (1)
4: (2) (2)
5: (1)
6: (2)4 颗技能 1 装饰珠,4 颗技能 2 装饰珠
。
# curItem表示当前装备索引
# curHole表示当前孔洞索引
# holeNum表示当前装备孔洞总数量
# skillNums记录孔洞装备情况
def holeValue(skillNums, curItem, curHole, holeNum, phole):
# 遍历完所有孔,记录数据退出
if curHole == holeNum:
phole.append(skillNums)
return
# 当前孔位的装备容量
maxLimit = items[curItem][curHole+1]
for j in range(n):
# 如果技能等级小等容量,则可以装备
if skills[j][0] <= maxLimit:
tmp = []
tmp += skillNums
tmp[j] += 1
# 记录当前孔装备技能
holeValue(tmp, curItem, curHole+1, holeNum, phole)
# 搜索所有的可能价值
# skillNums用于封装各个技能的数量
# cur代表当前是第几号装备
def allValue(skillNums, cur):
# 遍历完所有装备,记录数据退出
if cur == 6:
values.append(skillNums)
return
# 用于记录每个孔位的可能装备情况
phole = []
# 所需该装备的所有可能装备情况
holeValue(skillNums, cur, 0, items[cur][0], phole)
# 进行下一个装备的搜索
for arr in phole:
allValue(arr, cur+1)
# 装备
items = [list(map(int, input().split())) for _ in range(6)]
n = int(input())
# 技能
skills = [list(map(int, input().split())) for _ in range(n)]
# 用于记录所有的可能价值
values = []
# 搜寻所有可能
allValue([0]*n, 0)
# 存放最大价值
maxValue = 0
# 遍历每种可能
for value in values:
tmp = 0
# 遍历每个技能的可能存放数量
for i in range(len(value)):
# 求取价值
index = min(value[i], skills[i][1])
if index > 0:
tmp += skills[i][index+1]
if tmp > maxValue:
maxValue = tmp
print(maxValue)
3.65 字符串操作
题目描述
给出一个字符串和多行文字,在这些文字中找到字符串出现的那些行。你的程序还需支持大小写敏感选项:当选项打开时,表示同一个字母的大写和小写看作不同的字符;当选项关闭时,表示同一个字母的大写和小写看作相同的字符。
输入描述
输入的第一行包含一个字符串S,由大小写英文字母组成。
第二行包含一个数字,表示大小写敏感的选项,当数字为0时表示大小写不敏感,当数字为1时表示大小写敏感。
第三行包含一个整数n,表示给出的文字的行数。
接下来n行,每行包含一个字符串,字符串由大小写英文字母组成,不含空格和其他字符。
输出描述
输出多行,每行包含一个字符串,按出现的顺序依次给出那些包含了字符串S的行。
输入样例
Hello
1
5
HelloWorld
HiHiHelloHiHi
GrepIsAGreatTool
HELLO
HELLOisNOTHello
输出样例
HelloWorld
HiHiHelloHiHi
HELLOisNOTHello
样例说明
在上面的样例中,第四个字符串虽然也是Hello,但是大小写不正确。如果将输入的第二行改为0,则第四个字符串应该输出。
s = input()
buttom = int(input())
rows = int(input())
arr = [input() for _ in range(rows)]
res = []
if buttom == 1:
for i in arr:
if s in i:
res.append(i)
else:
s = s.lower()
for i in arr:
if s in i.lower():
res.append(i)
for i in range(len(res)):
print(res[i])
3.66 字符串对比
题目描述
给定两个仅由大写字母或小写字母组成的字符串(长度介于1到10之间),它们之间的关系是以下4中情况之一:
1:两个字符串长度不等。比如 Beijing 和 Hebei
2:两个字符串不仅长度相等,而且相应位置上的字符完全一致(区分大小写),比如 Beijing 和 Beijing
3:两个字符串长度相等,相应位置上的字符仅在不区分大小写的前提下才能达到完全一致(也就是说,它并不满足情况2)。比如 beijing 和 BEIjing
4:两个字符串长度相等,但是即使是不区分大小写也不能使这两个字符串一致。比如 Beijing 和 Nanjing
编程判断输入的两个字符串之间的关系属于这四类中的哪一类,给出所属的类的编号。
输入描述
包括两行,每行都是一个字符串
输出描述
仅有一个数字,表明这两个字符串的关系编号
输入样例
BEIjing
beiJing
输出样例
3
str1 = input()
str2 = input()
if len(str1) != len(str2):
print(1)
else:
if str1 == str2:
print(2)
elif str1.lower() == str2.lower():
print(3)
else:
print(4)
3.67 字符串跳步
题目描述
给定一个字符串,你需要从第start位开始每隔step位输出字符串对应位置上的字符。
输入描述
第一行:一个只包含小写字母的字符串。
第二行:两个非负整数start和step,意义见上。
输出描述
一行,表示对应输出。
输入样例
abcdefg
2 2
输出样例
ceg
start从0开始计数。
字符串长度不超过100000。
s = input()
start, step = map(int, input().split())
print(s[start::step])
3.68 最长公共子序列(LCS)
题目描述
给定两个字符串,寻找这两个字串之间的最长公共子序列。
输入描述
输入两行,分别包含一个字符串,仅含有小写字母。
输出描述
最长公共子序列的长度。
输入样例
abcdgh
aedfhb
输出样例
3
样例说明
最长公共子序列为a,d,h。
字串长度1~1000。
str1 = input()
str2 = input()
# res[i][j]代表长度str1长度为i,str2长度为j时的最长公共子序列的长度
res = [[0 for _ in range(len(str2)+1)] for _ in range(len(str1)+1)]
# 从零开始递归
for i in range(len(str1)+1):
for j in range(len(str2)+1):
# 其中一个字符串长度为0时,最长公共子序列的长度为0
if i == 0 or j == 0:
res[i][j] = 0
# 否则若当前长度位置i和j的字符相等,则最长公共子序列的长度更新为i-1和j-1长度时最长公共子序列的长度+1
elif str1[i-1] == str2[j-1]:
res[i][j] = res[i - 1][j - 1] + 1
# 若当前长度位置i和j的字符不相等,则最长公共子序列的长度为最长的(i-1和j长度时的最长公共子序列长度,i和j-1长度时的最长公共子序列长度)
else:
res[i][j] = max(res[i - 1][j], res[i][j - 1])
# 返回最终长度时的最长公共子序列的长度
print(res[-1][-1])
3.69 最长滑雪道
题目描述
小袁非常喜欢滑雪, 因为滑雪很刺激。为了获得速度,滑的区域必须向下倾斜,而且当你滑到坡底,你不得不再次走上坡或者等待升降机来载你。 小袁想知道在某个区域中最长的一个滑坡。区域由一个二维数组给出。数组的每个数字代表点的高度。如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8FEEdpCY-1654839635672)(https://raw.githubusercontent.com/Qiyuan-Z/blog-image/main/img/lanqiao/image-20220302190226582.png)]
一个人可以从某个点滑向上下左右相邻四个点之一,当且仅当高度减小。在上面的例子中,一条可滑行的滑坡为24-17-16-1。当然25-24-23-…-3-2-1更长。事实上,这是最长的一条。
你的任务就是找到最长的一条滑坡,并且将滑坡的长度输出。 滑坡的长度定义为经过点的个数,例如滑坡24-17-16-1的长度是4。
输入描述
输入的第一行表示区域的行数R和列数C(1<=R, C<=10)。下面是R行,每行有C个整数,依次是每个点的高度h(0<= h <=10000)。
输出描述
只有一行,为一个整数,即最长区域的长度。
输入样例
5 5
1 2 3 4 5
16 17 18 19 6
15 24 25 20 7
14 23 22 21 8
13 12 11 10 9
输出样例
25
#递归搜索, 求该位置出发的最长路径
def dfs(x, y):
# 初始化为1
maxHeight = 1
# 该位置周边的四个点
offset = [[-1, 0], [1, 0], [0, -1], [0, 1]]
for i in offset:
# 下一个搜索点的横坐标
tx = x + i[0]
# 下一个搜索点的纵坐标
ty = y + i[1]
# 若超出边界,跳过
if tx < 0 or tx > R - 1 or ty < 0 or ty > C - 1:
continue
# 若不满足高度差,跳过
if arr[tx][ty] >= arr[x][y]:
continue
# 当前位置出发的最长路径只有两种情况
# 1.找不到满足条件的搜索点为它自身 2.下一个搜索点的最长路径+1
maxHeight = max(maxHeight, dfs(tx, ty) + 1)
return maxHeight
#输入
R, C = map(int, input().split())
arr = [list(map(int, input().split())) for _ in range(R)]
# 存放最长路径的结果
res = 0
for x in range(R):
for y in range(C):
res = max(res, dfs(x, y))
print(res)
3.70 最长字符序列(同LCS)
题目描述
设x(i), y(i), z(i)表示单个字符,则X={x(1)x(2)……x(m)},Y={y(1)y(2)……y(n)},Z={z(1)z(2)……z(k)},我们称其为字符序列,其中m,n和k分别是字符序列X,Y,Z的长度,括号()中的数字被称作字符序列的下标。
如果存在一个严格递增而且长度大于0的下标序列{i1,i2……ik},使得对所有的j=1,2,……k,有x(ij)=z(j),那么我们称Z是X的字符子序列。而且,如果Z既是X的字符子序列又是Y的字符子序列,那么我们称Z为X和Y的公共字符序列。
在我们今天的问题中,我们希望计算两个给定字符序列X和Y的最大长度的公共字符序列,这里我们只要求输出这个最大长度公共子序列对应的长度值。
举例来说,字符序列X=abcd,Y=acde,那么它们的最大长度为3,相应的公共字符序列为acd。
输入描述
输入一行,用空格隔开的两个字符串
输出描述
输出这两个字符序列对应的最大长度公共字符序列的长度值
输入样例
aAbB aabb
输出样例
2
a, b = input().split()
arr = [[0 for _ in range(len(b)+1)] for _ in range(len(a)+1)]
for i in range(len(a)+1):
for j in range(len(b)+1):
if i == 0 or j == 0:
arr[i][j] = 0
elif a[i-1] == b[j-1]:
arr[i][j] = arr[i-1][j-1] + 1
else:
arr[i][j] = max(arr[i][j-1], arr[i-1][j])
print(arr[-1][-1])
文章出处登录后可见!