一点就分享系列(实践篇5-上篇)[持续更新!全网首发]yolov7解析
一点就分享系列(实践篇5-下篇)依旧全网首发—Yolov5项目爆肝升级High-level集结!逐一任务介绍,附赠模型通用修改方法和部署教程。
近期为什么不更新?
因为在做别的方向的探索,比如动捕 、抠图、nerf等任务的学习,所以检测研究会停滞、毕竟这年头不能只搞high-level
新闻版块【实时更新说明和近期计划】—->>项目地址
2022/9/30 项目更新内容移步—>>>>>>>该章节实践篇5-下篇
2022/9/25 更新内容
0. High-levlel 检测、分类、分割、关键点检测功能模块整合完成,移步GIT或者最新博客
1.分割代码结合V5和V7的代码进行了合并DEBUG调试,训练部分待验证,另外注意力层训练过程中,没法收敛或者NAN的情况,排除代码问题,需要在超参文件yaml里,先对学习衰减率从0.1变成0.2 ,比如GAM,因为用了注意力头训练周期加到400EPOCH左右就可以训练。
2.去年的decoupled结构虽然能提点,不过FLOPS增加的太多,目前用V5作者分支的解耦头替换,效果待验证。
3.融合了代码做了部分的优化,这里看了下V7的代码优化较差,后续会集成精简版本的分类、分割、检测、POSE检测的结构,目前已经完成了一部分工作,更新频繁有问题欢迎反馈和提供实验结果。
前言
yolov7来了,话不多说,强行回归,之前提到的一些nanodet/yolox的优化技巧,没想到V7也做了,这样挺好,减少了不少工作量,大体今天上午看了下主要是两部分核心:网络结构和辅助训练分支,从V7仓库适配了下代码,才发现缝合度极度严重,其实就是魔改版的V5,不过仍旧有值得学习的东西,同时想起V6(mt),让我明白一个道理:做事情一定要快!于是下午我就把V7之于V5的区别对比了下,并基于我自己的魔改版V5仓库进行了V7的添加,基本全程没什么大坑,还是比较容易的,分享在我的github上,代码是集成好的。目前V7其实是没有V5一些代码细节更好的,代码和文章持续更新请放心!还是有不少优化的地方,(还是老规矩:有问题留言或者私信,比较急的挂git issue,最近更新频繁,有问题在所难免)
后续打脸~!7月22号了!,每天都要花几个小时调试源码,更新博客会慢很多,还是以GIT上程序为主吧,由于V7本身存在很多BUG也是一直修复,加上我适配V5后有些代码冲突,也是不停在修改,光在这搬砖的,目前大部分的训练各种V7结构的模型BUG都修复了,再就是V7官方就现在还在改BUG呢,所以大家也谅解下,V5作者是不断优化代码,因此我还是以V5的代码优化为基准出发。*
基于最新的YOLOV5定期更新的,为什么要用yolov5修改?
1. 因为v7也是基于某一时间的V5代码上基础改的(因为这个作者的YOLOR当初也是基于V5做的添加),这样更利于快速上手,事实上从代码层面来讲本来也是基于v5的,很多共同的也没必要再复述
2. yolv5不断更新工程代码的规范,优化了不少小BUG和程序的问题
3. 学习进步
4. 同样参考基于yolov5的人体姿态关键点检测的Paper以及开源。
common.py代码比较多,后续会规范整理!此时此刻,我差点想改个名字叫YOLOV5+7 =12? ,V7的yaml结构我放在了这里:
先补充下YoloV7的大致使用:
比如你想训练yolov7的P5-model直接run,注意官方将这个分离成了两部分,更直接一些。
python train.py --cfg models/v7_cfg/training/yolov7.yaml --weights yolov7.pt --data (custom datasets)
P6-modle ,run:
python train.py --cfg models/v7_cfg/training/yolov7w6.yaml --imgsz 1280 --weights 'yolov7-w6_training.pt' --data (custom datasets) --aux_ota_loss --hyp data/hyps/hyp.scratch-v7.custom.yaml
权重我挂在百度云上了!yolov7 预训练权重打包链接:yolov7 预训练权重打包链接 提取码:v7v7
请注意:由于我删除了P6模型里的Reorg操作其实就是Focus(在我看来这个操作是没必要的),所以你需要重新训练或者微调下,如果你想使用V7原始权重,你只需要在YAML里改回去
使用需知:如何重参数化YOLOV7模型
这里以yolov7为例,我们看这段提供的代码,
- 训练training/下的yaml结构后,你的初始权重 xxx_training.pt会变成xxx.pt,你需要加载训练好的权重yolov7xxx.pt,具体也可以参考重参数结构的脚本
- 然后使用deploy的模型去加载你训练的权重,改变层索引和结构,这样可以推理并且完成加速。
具体看官方tools/下的reparameterization.ipynb或者我的代码下的reparameterization.Py ,参考使用,后续会优化整理下便于使用。
nc=80
anchors=3
device = select_device('0', batch_size=1)
# model trained by cfg/training/*.yaml
# 注意这里官方给的yolov7.pt,这里会误导一些朋友出现问题,如果你用官方直接的yolov7.py是错误的,因为yolov7.pt是作者重参数的最终推理模型,头部的yoloR的key已经被移除了,你可以使用yolov7_traing.pt或者是你通过traing下的yaml所生成的权重,然后训练后会存为yolov7.pt,这个才是作者想表达的意思。
ckpt = torch.load('yolov7_training.pt', map_location=device)
# reparameterized model in cfg/deploy/*.yaml
model = Model('models/v7_cfg/deploy/yolov7.yaml', ch=3, nc=80).to(device)
#print(model)
# copy intersect weights
state_dict = ckpt['model'].float().state_dict()
exclude = []
intersect_state_dict = {k: v for k, v in state_dict.items() if k in model.state_dict() and not any(x in k for x in exclude) and v.shape == model.state_dict()[k].shape}
model.load_state_dict(intersect_state_dict, strict=False)
model.names = ckpt['model'].names
model.nc = ckpt['model'].nc
for i in state_dict:
print(i)
#print(intersect_state_dict)
# reparametrized YOLOR 将yolor头部的权重赋值
for i in range((model.nc+5)*anchors):
model.state_dict()['model.105.m.0.weight'].data[i, :, :, :] *= state_dict['model.105.im.0.implicit'].data[:, i, : :].squeeze()
model.state_dict()['model.105.m.1.weight'].data[i, :, :, :] *= state_dict['model.105.im.1.implicit'].data[:, i, : :].squeeze()
model.state_dict()['model.105.m.2.weight'].data[i, :, :, :] *= state_dict['model.105.im.2.implicit'].data[:, i, : :].squeeze()
model.state_dict()['model.105.m.0.bias'].data += state_dict['model.105.m.0.weight'].mul(state_dict['model.105.ia.0.implicit']).sum(1).squeeze()
model.state_dict()['model.105.m.1.bias'].data += state_dict['model.105.m.1.weight'].mul(state_dict['model.105.ia.1.implicit']).sum(1).squeeze()
model.state_dict()['model.105.m.2.bias'].data += state_dict['model.105.m.2.weight'].mul(state_dict['model.105.ia.2.implicit']).sum(1).squeeze()
model.state_dict()['model.105.m.0.bias'].data *= state_dict['model.105.im.0.implicit'].data.squeeze()
model.state_dict()['model.105.m.1.bias'].data *= state_dict['model.105.im.1.implicit'].data.squeeze()
model.state_dict()['model.105.m.2.bias'].data *= state_dict['model.105.im.2.implicit'].data.squeeze()
# model to be saved
ckpt = {'model': deepcopy(model.module if is_parallel(model) else model).half(),
'optimizer': None,
'training_results': None,
'epoch': -1}
# save reparameterized model
torch.save(ckpt, 'models/v7_cfg/deploy/yolov7.pt')
(如果代码有BUG 。iussue上留言,今天被MT的V6刺激到黑化,程序是有CI 原则上不会有大问题,后续会完善额外的模型CI)
一点就分享系列(实践篇5-上篇)
一句话综述yolov7到底是什么!
千篇一律的东西我不想做,因为能看这个文章的人,基本都看过YOLOV5了,那么为什么我说yolov7只是yolov5的plus?
最直接的就是从git代码上可以看出基本是“”集百家之所长",代码大概是今年5月份yolov5的版本基础上结合了自己的修改(别问我为什么知道,每周维护更新!),那么我很有底气的可以量化来说,同时也为后续大家看yolov7打通整体思路,一句话总结:
yolov7的代码= 5月之前的yolov5工程版本基础上+ v7作者YOLOR的改进(YOLOV4的AB佬)+总结新的重参数网络结构和算子/加入最近才开源的swinv2等算子结构+辅助检测分支/对应的LOSS标签匹配策略+模型结构的增加和解析引起的代码调整,包含初始化权重参数、优化器等
带来了性能的提升以及FLOPS的增加,最终综合来看还是一次进化,一些问题,比如调整NMS等一些参数和Trick在数据集上产生虚高精度,这里不过多讨论,本篇宗旨:抱着学习的态度去积累
通过看代码,可以看出V7还在做实验来验证一些结构,其次其实主体就是这些区别,接下来就是细化yolov7的各个细节,这部分可以慢慢在整理,梳理和总结学习。
yolov7存在过高的flops,但是仍旧具备不错的推理速度,完全依赖于重参数结构,让我们看看模型结构。
再次强调注意事项:
我的GIT加入的YOLOV7也是不断更新的,但是代码并不和V7完全一模一样,因为代码还在不断更新所以我举个例子:
比如V7的P6结构中,REORG我删除了,因为这FOCUS一样,所以我这部分还是使用YOLOV5的[-1, 1, Conv, [64, 6, 2, 2] 去替代Reorg,所以需要自己从新训练下模型。
一、模型结构—>保持性能,提升速度
1. 核心改动一V7的核心结构-RepVgg
设计初衷:结构重参数化,解耦训练和推理的逻辑,提升最终的推理速度和优化内存,先补一下regvgg的背景吧,其实这里也可以看出做轻量化模型设计的最近很火的一个思想就是降低mac!
3×3卷积非常快。在GPU上,3×3卷积的计算密度(理论运算量除以所用时间)可达1×1和5×5卷积的四倍。
单路架构非常快,因为并行度高。同样的计算量,“大而整”的运算效率远超“小而碎”的运算。
单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用。
单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
训练时候是多分支,推理时候为单路结构,这样降低mac成本,再结合3X3卷积在GPU上的速度优势,RepVgg的block每层都加了平行的1×1卷积分支和恒等映射分支,这里和resnet不完全一样。
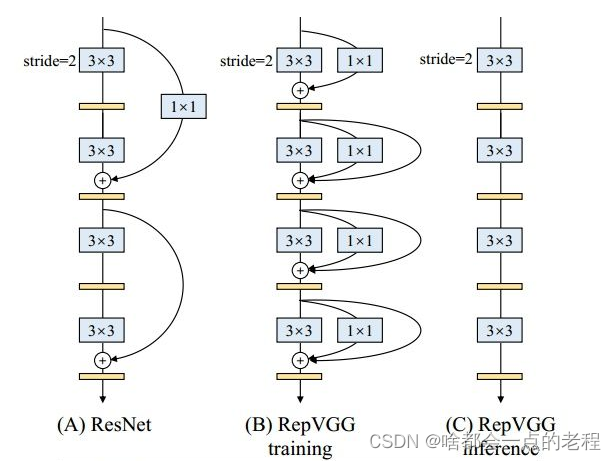
然后核心就是如何从多分支转为单路用于推理部署,来看看REPVGG怎么做的?
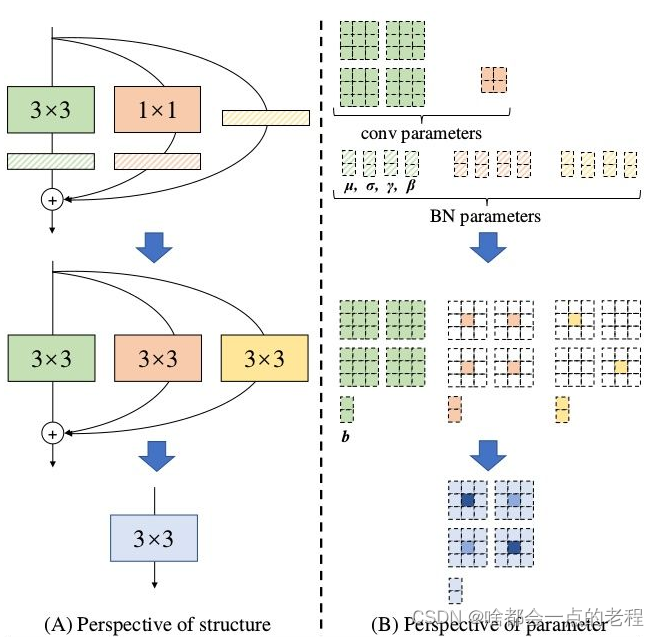
(先声明下,算子融合这部分torch都是有实现的)
- conv和BN融合,这个老生常谈, 融合过程是conv带有bias的,目的就是推理时候进行加速
- 1×1和3×3卷积融合,如何对齐?
以3X3卷积为基准,因为1×1的Conv等价于卷积核多个0的3X3卷积,而indentity相当于单位矩阵的1×1卷积,那么同样等价于3×3卷积.
只需要把1×1的卷积padding成3×3的卷积就行,这样就可以完成single_path - 总体融合
在3×3的卷积形式上对齐后,我们可以进行直接融合即对应相加。激活函数RELU因为涉及到数值精度,应该需要量化,所以没有融合激活函数。 - 检测头融合
yolov7的结构一部分是在yolor的基础上构建的,那么作者最近释放出了yolov7的检测头融合部分。
为了便于大家理解,我们先看下conv和bn的融合代码,
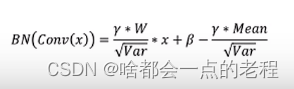
对照融合后的计算公式和代码,本质上还是卷积的线性计算,所以同理这个模型里的操作都可以转化。
def fuse_conv_and_bn(conv, bn):
# Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
fusedconv = nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
# Prepare filters
w_conv = conv.weight.clone().view(conv.out_channels, -1)
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var))) # 得到融合计算的第一项权重项
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))# #压缩维度拷贝权重
# Prepare spatial bias# 得到融合计算的第二项权重项
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias #判断有无bias初始化
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))# 得到融合计算的第二项偏置项
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn) ## 得到融合计算的组合权重和偏置项=融合的计算公式
return fusedconv
那么同理,我们可以类比其他的融合思路和形式。
其实以上思路就是跟tensorrt的网络加速优化有类似的地方,只不过trt做了更多的变换,包含激活函数的融合,垂直和水平融合,包含取消一些没必要的层比如concat。
总结repvgg,等效结构变换带来推理速度的质变,值得学习,参考TRT的融合或许可以做的更好。
yolov7的论文中对这个结构进行了再一次的调整,为了缓解dense网络的性能下降问题,如图:
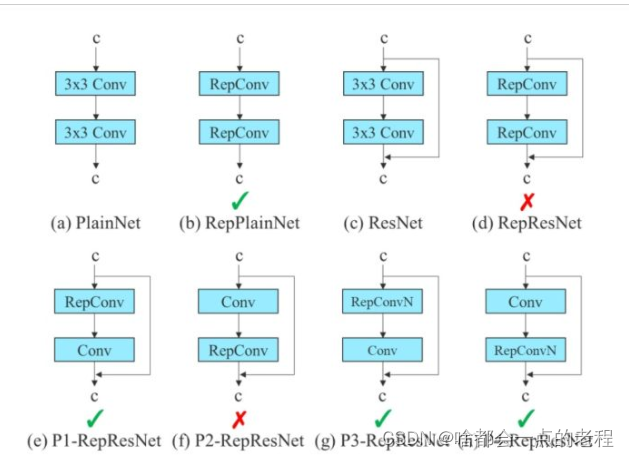
使用(b)中的RepConv的Block,没有并行分支,作者团队发现有的identity 连接是不需要,并且不需要在conv和repconv直接进行indentity,这也算贡献吧,然后我们以yolov7中的几个yaml来熟悉下其结构,因为网络结构是IDetect ,是有yolor的结构
这里再概述下:YOLOV7的深层p6版本最后头部选用了基于yolor和aux辅助检测层的变体,来提升性能,【代码的话比较长!到现在了,我相信这种基础的模块代码大家都能看得明白,至于其中的SPPCSPC等结构的卷积、池化计算大家直接看源码】,直接上仓库的代码链接:common.py算子块,现在请大家仔细看下这个"训练版本"yaml的结构!
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
其中repConv的推理融合代码fuse_repvgg_block()如下:
目的就是把模型的repconv算子块变成普通的3X3 conv.
def fuse_repvgg_block(self):
if self.deploy:
return
print(f"RepConv.fuse_repvgg_block")
#初始化fuse后的结构算子值
self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1])
self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
rbr_1x1_bias = self.rbr_1x1.bias
weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight, [1, 1, 1, 1])
# Fuse self.rbr_identity :先判断是不是有同输出的shortcut直接的X block结构,如果是要做成sing-path的结构
if (isinstance(self.rbr_identity, nn.BatchNorm2d) or isinstance(self.rbr_identity, nn.modules.batchnorm.SyncBatchNorm)):
# print(f"fuse: rbr_identity == BatchNorm2d or SyncBatchNorm")
identity_conv_1x1 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=self.groups,
bias=False)
#拷贝, 以3X3卷积为基准,因为1x1的Conv等价于卷积核多个0的3X3卷积,而indentity相当于单位矩阵的1x1卷积,那么同样等价于3x3卷积.
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()
#构建单位阵的1x1卷积
identity_conv_1x1.weight.data.fill_(0.0)
identity_conv_1x1.weight.data.fill_diagonal_(1.0)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)
# print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
bias_identity_expanded = identity_conv_1x1.bias
weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight, [1, 1, 1, 1])
else:
# print(f"fuse: rbr_identity != BatchNorm2d, rbr_identity = {self.rbr_identity}")
bias_identity_expanded = torch.nn.Parameter( torch.zeros_like(rbr_1x1_bias) )
weight_identity_expanded = torch.nn.Parameter( torch.zeros_like(weight_1x1_expanded) )
self.rbr_dense.weight = torch.nn.Parameter(self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
self.rbr_reparam = self.rbr_dense
self.deploy = True
if self.rbr_identity is not None:
del self.rbr_identity
self.rbr_identity = None
if self.rbr_1x1 is not None:
del self.rbr_1x1
self.rbr_1x1 = None
if self.rbr_dense is not None:
del self.rbr_dense
self.rbr_dense = None
1.1这里简单过下,V7引入的新算子
1. SPPCSPC :类似于V5的SPPF结构
2. MP:conv和MP的结构,其实就是maxpooling和CONV+BN+silu的一个two-path组合
3. ELAN1:基于ELAN设计的E-ELAN 用expand、shuffle、merge
cardinality来实现在不破坏原有梯度路径的情况下不断增强网络学习能力的能力。
除此之外,在YOLOV7的仓库中还集成了swinv1、swinv2、yolor等模块构建模型,这里就不做过多介绍了,详情直接看官方或者我的仓库中的models/common.py。
2.核心改动一 辅助检测头分支—–提升训练性能
看过nano系列的Assign Guidance Module, 这一做法为了缓解轻量化目标检测网络的小检测头设计的训练不稳定问题,之前很多人问我怎么提升我也是说过加辅助分支这点,只是自己还没来得及想好怎么加和实现,正好来看看V7的做法:
由于检测头的深度降低后,模型性能会受到比较大的退化影响,正样本的质量很差,导致训练的MAP上不去,所以使用aux head帮助检测出一些好的正样本去匹配,辅助yolov7的head训练,这里叫Lead head。
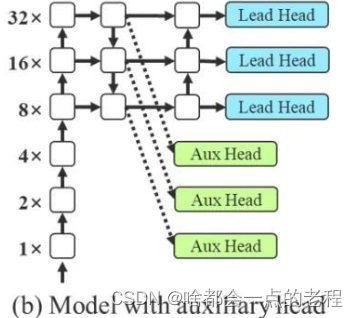
上图(b)是带aux辅助分支的检测器结构,是比较常规的辅助结构。在深度网络的训练中,目前如yolov5等检测器,通过gt和预测的box计算CIOU等以IOU为基准的软标签分配来训练模型,一般的做法为:两端head单独去分配标签。
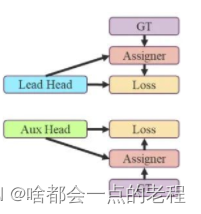
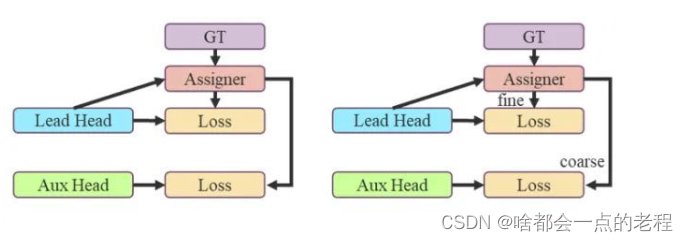
这里yolov7和naodet的作者设计的区别是:辅助aux Head是不如lead head的,也就是主检测的lead Head 的预测去引导辅助aux Head,也就是上图中利用aux head的大量低质量的正样本anchor进行一次coarse to fine ,因为aux召回率较高,找出更多的样本lead head再进行fine,来看一下,这里说下,yolov7在训练中主要引入了带有yolor的检测头有和aux的辅助检测头。
2.1 模型训练设计思路和结构
解耦化设计,因为这些组件是可以自己搭配的这才是最重要的,所以一定要清楚下面的设计结构。这里让我们分别看下,同时也是改动部分在yolo.py的几个检测头,YOLOV7中的模型结构简单规划为两大类基础(方便理解)
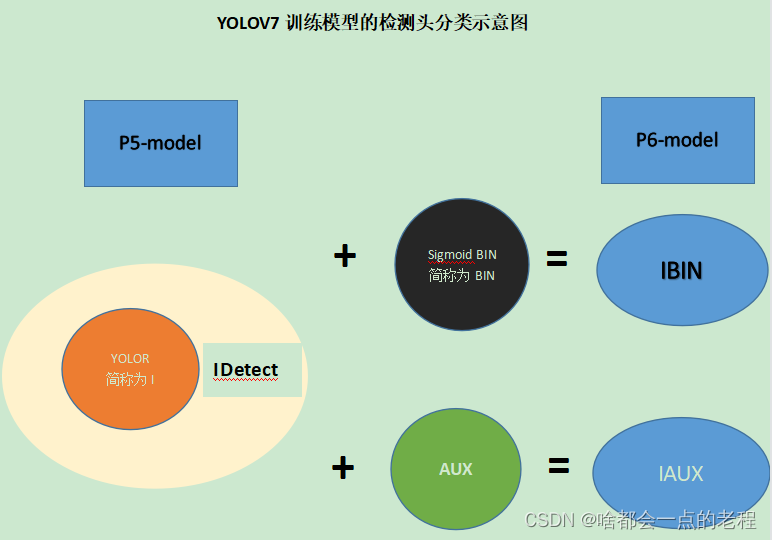
这样你可以yaml中看出目前可以训练的版本是:
P5-model对应官方的yolov7、yolov7x、yolov7-tiny,训练头使用的是Idetect(YOLOR的内积算子);
P6-model对应官方训练的结构中除P5的模型,其余的yolov7-x6x.yaml的结构,head部分有IBINDetect、IAuxDetect等,也就是P6的网络才有辅助Aux-head部分的辅助分支。
IDetect 模块-yolor的模型
以V7作者的成名作YOLOR为基础的 Implicit加入,这里对于yolor不做过多解析(因为我也没仔细看过,有空补一下哈),简单来说YOLOR中的隐式知识结合卷积特征映射和乘法,代码比较简单,我对YOLOR的影响就是在深层模型上确实精度提高有效。即唯一区别:加入了Yolor的Head.
通过引入加法,可以使神经网络预测中心坐标的偏移量。还可以引入乘法来自动搜索锚点的超参数集,这是基于锚点的对象检测器经常需要的。此外,可以分别使用点乘和concat来执行多任务特征选择和为后续计算设置前提条件。
##### yolor #####
class ImplicitA(nn.Module):
def __init__(self, channel, mean=0., std=.02):
super(ImplicitA, self).__init__()
self.channel = channel
self.mean = mean
self.std = std
self.implicit = nn.Parameter(torch.zeros(1, channel, 1, 1))
nn.init.normal_(self.implicit, mean=self.mean, std=self.std)
def forward(self, x):
return self.implicit + x
class ImplicitM(nn.Module):
def __init__(self, channel, mean=0., std=.02):
super(ImplicitM, self).__init__()
self.channel = channel
self.mean = mean
self.std = std
self.implicit = nn.Parameter(torch.ones(1, channel, 1, 1))
nn.init.normal_(self.implicit, mean=self.mean, std=self.std)
def forward(self, x):
return self.implicit * x
class IDetect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(IDetect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
#self.ia就是与隐式表征相加
#self.im就是与隐式表征相乘
self.ia = nn.ModuleList(ImplicitA(x) for x in ch)
self.im = nn.ModuleList(ImplicitM(self.no * self.na) for _ in ch)
class IDetect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(IDetect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.ia = nn.ModuleList(ImplicitA(x) for x in ch)
self.im = nn.ModuleList(ImplicitM(self.no * self.na) for _ in ch)
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
"""
对于每层FPN的输出每个通道先加上一个隐式表征,
然后经过预测头的卷积,再每个通道乘以一个隐式表征;
"""
x[i] = self.m[i](self.ia[i](x[i])) # conv
x[i] = self.im[i](x[i])
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
IBIN-Detect(这部分模型和训练 ,作者并未公开这个模型的结果,所以我后续会详细补充,核心就是LOSS)
在IDetect的基础上加入了SigmoidBIN 损失函数,这个结构目前在V7的实验中没有使用和公开!(后续通过训练实验我会补充的更详细点)通过SigmoidBin这个函数,是 BCEWithLogitsLoss、 MSELoss组成的优化函数,通过该loss函数组合对w、h生成的softlabel去进行优化,在该函数里讲w和h的tensor长度定为22,那么整体就是额外的 44长度,加上NC和x、y,如果nc=80,那么每一个anchor预测的长度为:44+80+3=127.
这里我也有点小问题,正在等作者答复,他训练部分没有给出这个结构的训练样例,不过换汤不换药,我只是好奇为什么是21,V7作者的答复是开放性的选择:”可以将 bin _ count 更改为任何你想使用的值。在我们的实验中,21 ~ 41得到类似的结果,而 < 21在 数据集上得到的结果稍差一点。“
IAUX-Detect
依旧在yolor的基础上,加入辅助的aux_head,这也是YOLOV7的第二个核心点
class IAuxDetect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(IAuxDetect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch[:self.nl]) # output conv
"""
这里添加一个辅助head
"""
self.m2 = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch[self.nl:]) # output conv
self.ia = nn.ModuleList(ImplicitA(x) for x in ch[:self.nl])
self.im = nn.ModuleList(ImplicitM(self.no * self.na) for _ in ch[:self.nl])
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](self.ia[i](x[i])) # conv
x[i] = self.im[i](x[i])
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
"""
aux 的输出
"""
x[i+self.nl] = self.m2[i](x[i+self.nl])
x[i+self.nl] = x[i+self.nl].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
"""
测试推理阶段主取主lead-head的预测结果
"""
return x if self.training else (torch.cat(z, 1), x[:self.nl])
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
训练样本匹配策略——YOLOV7的动态样本匹配
在上述一直分析的辅助头的结构后,那么趁热打铁,我们要看v7中对应的正负样本样本匹配计算:
由于辅助head只在V7中出现,那么其实V7的匹配策略也对应上述我自己画的图,不同的头部结构模型对应不同的样本匹配以及LOSS函数,只不过这里添加的LOSS函数匹配策略:ComputeLossOTA(对应普通的P5模型)、 ComputeLossBinOTA(对应sigmoidBin函数的结构模型)、ComputeLossAuxOTA(对应普通的P6模型)
上述我们提到过关于v7的aux head, 在论文中我们可以知道,作者设计的aux_head性能是小于本身的lead_head的,也就是aux_head作为辅助初筛,为了提高召回率,这里是有二阶段的检测器的思想的。
主要匹配还是使用了Yolov5的跨网格预测+yoloX中的SIMOTA的策略:
- 每个GT与设定的9个anchors的匹配过程中, 宽和高比,在其较大值小于阈值时,该anchor作为正样本.
- YOLOV5的扩充策略——跨网格预测 :同时也会加快收敛,在一个网格内会被根据规则来判断gt-BOX中心点外的跨网格的相邻两个网格的作为正样本,正样本就+2.
- 计算当前GT有top 10的Iou,将top10的Iou进行和Sum,就为当前GT的K取值;
- 通过计算GT和anchor的LOSS,保留最小的前K个,这里损失函数的分类权重,作者是作了权重衰减的调整.
- 去掉一个GT匹配得到多个GT的样本情况,通过逻辑判断代码中有体现
在此基础上,由于V7有辅助的AUX分支,那么同理,AUX head也需要进行一次类似上述的匹配机制,这里为了便于理解要上部分V7的代码,我们拿出yolov7 带有OTA的的build_targets函数来分析下,顺便看看和V5的比对:
结合我们上述所讲的:对Aux-head辅助我们知道是比lead-head设计的更加coarse,故从代码中我们看出它在aux版本的匹配策略中,尝试了更大幅度的跨网格预测,提供更多的正样本,这样提高召回率的设计。
```bash
def build_targets(self, p, targets, imgs):
#indices, anch = self.find_positive(p, targets)
indices, anch = self.find_3_positive(p, targets) """ 这里是V7自己封装的,其实就是跨网格预测定义正样本"""
#indices, anch = self.find_4_positive(p, targets)
#indices, anch = self.find_5_positive(p, targets)
#indices, anch = self.find_9_positive(p, targets)
matching_bs = [[] for pp in p]
matching_as = [[] for pp in p]
matching_gjs = [[] for pp in p]
matching_gis = [[] for pp in p]
matching_targets = [[] for pp in p]
matching_anchs = [[] for pp in p]
nl = len(p)
for batch_idx in range(p[0].shape[0]):
b_idx = targets[:, 0]==batch_idx
this_target = targets[b_idx]
if this_target.shape[0] == 0:
continue
txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
txyxy = xywh2xyxy(txywh)
pxyxys = []
p_cls = []
p_obj = []
from_which_layer = []
all_b = []
all_a = []
all_gj = []
all_gi = []
all_anch = []
for i, pi in enumerate(p):
b, a, gj, gi = indices[i]
idx = (b == batch_idx)
b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
all_b.append(b)
all_a.append(a)
all_gj.append(gj)
all_gi.append(gi)
all_anch.append(anch[i][idx])
from_which_layer.append(torch.ones(size=(len(b),)) * i)
fg_pred = pi[b, a, gj, gi]
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
grid = torch.stack([gi, gj], dim=1)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i] #/ 8.
#pxy = (fg_pred[:, :2].sigmoid() * 3. - 1. + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i] #/ 8.
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = xywh2xyxy(pxywh)
pxyxys.append(pxyxy)
pxyxys = torch.cat(pxyxys, dim=0)
if pxyxys.shape[0] == 0:
continue
p_obj = torch.cat(p_obj, dim=0)
p_cls = torch.cat(p_cls, dim=0)
from_which_layer = torch.cat(from_which_layer, dim=0)
all_b = torch.cat(all_b, dim=0)
all_a = torch.cat(all_a, dim=0)
all_gj = torch.cat(all_gj, dim=0)
all_gi = torch.cat(all_gi, dim=0)
all_anch = torch.cat(all_anch, dim=0)
"""计算gtbox和经过第一步筛选出来的anchor索引对应的网络预测结果的IOU,取log作为iou_loss;
同计算分类LOSS,为后续OTa需要的LOSS做准备
"""
pair_wise_iou = box_iou(txyxy, pxyxys)
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8) #
top_k, _ = torch.topk(pair_wise_iou, min(10, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
gt_cls_per_image = (
F.one_hot(this_target[:, 1].to(torch.int64), self.nc)
.float()
.unsqueeze(1)
.repeat(1, pxyxys.shape[0], 1)
)
num_gt = this_target.shape[0]
cls_preds_ = (
p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
y = cls_preds_.sqrt_()
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(
torch.log(y/(1-y)) , gt_cls_per_image, reduction="none"
).sum(-1)
del cls_preds_
"""得到COST,按照SIM-OTA的设计,构建匹配矩阵根据LOSS动态计算,Lcls和Lreg比例是1:3 """
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_iou_loss)
matching_matrix = torch.zeros_like(cost)
"""给每个gt分配正样本,同时确定每个gt要分配几个正样本,# 取cost排名最小的前dynamic_k个anchor作正样本"""
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(
cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
)
matching_matrix[gt_idx][pos_idx] = 1.0
del top_k, dynamic_ks
anchor_matching_gt = matching_matrix.sum(0)
""" 针对一个anchor匹配了2个gt情况进行处理"""
if (anchor_matching_gt > 1).sum() > 0:
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0) #正样本,跟第几个gt更匹配
from_which_layer = from_which_layer[fg_mask_inboxes]
all_b = all_b[fg_mask_inboxes]
all_a = all_a[fg_mask_inboxes]
all_gj = all_gj[fg_mask_inboxes]
all_gi = all_gi[fg_mask_inboxes]
all_anch = all_anch[fg_mask_inboxes]
this_target = this_target[matched_gt_inds]
for i in range(nl):
layer_idx = from_which_layer == i
matching_bs[i].append(all_b[layer_idx])
matching_as[i].append(all_a[layer_idx])
matching_gjs[i].append(all_gj[layer_idx])
matching_gis[i].append(all_gi[layer_idx])
matching_targets[i].append(this_target[layer_idx])
matching_anchs[i].append(all_anch[layer_idx])
for i in range(nl):
if matching_targets[i] != []:
matching_bs[i] = torch.cat(matching_bs[i], dim=0)
matching_as[i] = torch.cat(matching_as[i], dim=0)
matching_gjs[i] = torch.cat(matching_gjs[i], dim=0)
matching_gis[i] = torch.cat(matching_gis[i], dim=0)
matching_targets[i] = torch.cat(matching_targets[i], dim=0)
matching_anchs[i] = torch.cat(matching_anchs[i], dim=0)
else:
matching_bs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_as[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gjs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gis[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_targets[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_anchs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
find_x_positive 这个和V5是一样的 就是选取V5的跨网格预测选出候选正样本,不多赘述
def find_3_positive(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
indices, anch = [], []
gain = torch.ones(7, device=targets.device).long() # normalized to gridspace gain
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(self.nl):
anchors = self.anchors[i]
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain
if nt:
# Matches
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
# Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
anch.append(anchors[a]) # anchors
return indices, anch
故在ComputeLossAuxOTA中,该函数中唯一不同的就是上述所说的跨度,因为是带有aux的所以需要再为aux的分支匹配一次也就是5个正样本的高召回匹配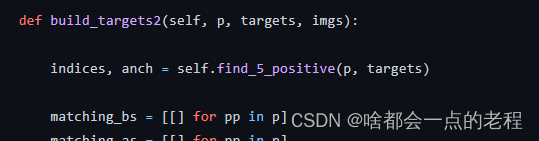
那么可以总结如下,YOLOV7的匹配机制,一句话解释!:
yolov5的样本匹配+simota的动态计算+(根据模型选择是否带有AUX,那么就要额外的进行一次样本定义和匹配计算)
文章出处登录后可见!