点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【BEV综述】获取论文!
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
1摘要
以视觉为中心的俯视图(BEV)感知最近受到了广泛的关注,因其可以自然地呈现自然场景且对融合更友好。随着深度学习的快速发展,许多新颖的方法尝试解决以视觉为中心的BEV感知,但是目前还缺乏对该领域的综述类文章。本文对以视觉为中心的BEV感知及其扩展的方法进行了全面的综述调研,并提供了深入的分析和结果比较,进一步思考未来可能的研究方向。如下图所示,目前的工作可以根据视角变换分为两大类,即基于几何变换和基于网络变换。前者利用相机的物理原理,以可解释性的方式转换视图。后者则使用神经网络将透视图(PV)投影到BEV上。
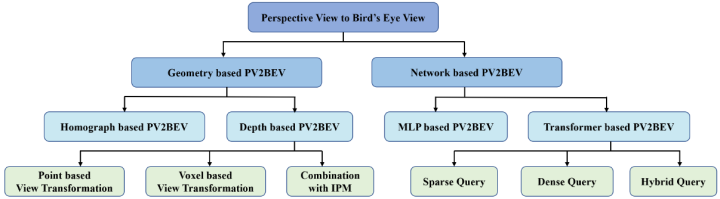
2BEV感知任务
以视觉为中心的BEV感知指的是基于多个视角的图像序列,算法需要将这些透视图转换为BEV特征并进行感知,如输出物体的3D检测框或俯视图下的语义分割。相比于LiDAR,视觉感知的语义信息更丰富,但缺少准确的深度测量。
最常见的BEV感知便是3D检测,根据输入数据模态的不同,又可以划分为以下三种:
基于图像;
基于LiDAR;
基于多模态。
另一种常见感知是BEV分割:
地图分割(Map Segmentation);
车道线分割。
3基于几何变换的PV2BEV
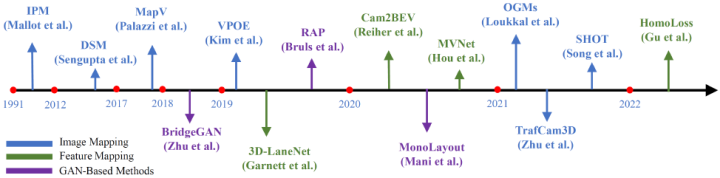
传统方案直接利用几何投影将透视图转换为BEV。进一步可以划分为基于同形异体和基于深度的PV2BEV。前者包括简化几何关系的早期工作或仅关注地面感知的近期工作;后者则更适用于实际场景。
基于同形异体的PV2BEV
3D空间中的点可以通过透视映射转换到图像空间,反之则存在困难。逆透视映射(IPM)[1]则解决了上述问题。IPM是将前视图转换为俯视图的开创性工作。该变换利用相机旋转单应性和各向异性缩放[34],其中单应矩阵可以由相机的内外参推导出来。一些工作[35]使用CNN提取PV图像的语义特征,并估计图像中的垂直消影点和地平面消影线(地平线)来确定单应矩阵。经过IPM操作转换到BEV后,进一步可以进行如光流估计/检测/分割/运动预测/规划等下游任务。VPOE[36]使用Yolov3[37]作为检测主干来估计BEV下的车辆位置和方向。在实际应用中,相机的内外参可能无法获取,TrafCam3D[39] 基于双视角的网络结构提出了一种鲁棒的单应映射,来缓解IPM失真的问题。
但由于IPM极度依赖地面假设(flat-ground assumption,即所有点都在地面上的假设),所以基于IPM的方法通常无法准确检测位于地平面上方的物体,如建筑物、车辆和行人。一些方法利用丰富的语义信息缓解上述问题。OGMs[40]将PV中车辆的历史轨迹转换到BEV上,以遵循单应性的地面假设,进而避免了车身位于地面之上造成的失真。遵循这个想法,BEVStitch[41] 使用双分支来分割车辆和道路的轨迹,并分别通过IPM将它们转换为BEV,之后拼接为完整的BEV路线图。
和上述在预处理或后处理阶段使用IPM不同,也有一些方法将IPM融入到网络的训练中。Cam2BEV[44] 使用 IPM转换每个视角的特征图,从多个车载摄像头获取给定图像的整体BEV语义图。MVNet[45]基于IPM将2D特征投影到共享的BEV空间中,以融合多视角特征,并使用大卷积核来解决行人检测中的遮挡问题。
由于正视图和鸟瞰图之间的差距较大且变形严重,仅使用IPM不足以在BEV中获取无失真的图像或语义图。BridgeGAN[48]将单应视角作为中间视角,并提出了一种基于多个GAN网络的模型来学习PV和BEV之间的交叉视角转换。利用生成式对抗网络(GAN)[49]来增强生成的BEV图像的真实性。
总结
基于同形异体的方法依赖物理映射实现PV2BEV,可解释性强。IPM在下游感知任务的图像投影或特征投影中发挥作用。为了减少失真,语义信息、GAN都被得到了较广泛的应用以提升BEV特征的质量。核心映射通过矩阵乘法进行,不需要学习,简单明朗。但由于PV到BEV的真正转换并不适定(ill-posed),IPM仅通过硬假设解决了部分问题,PV整个特征图的有效BEV映射仍然有待验证和挖掘。下图对相关算法进行了概括总结。
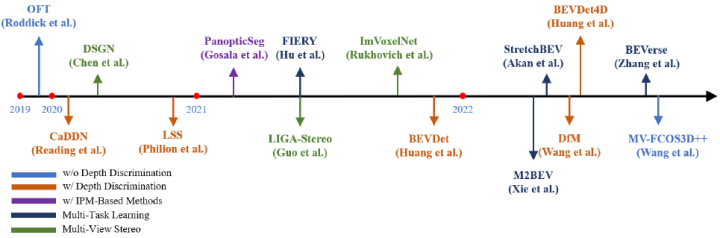
基于深度的PV2BEV
很明显,基于IPM的方法丢失了重要的高度信息。既然降维不行,那么将2D升维到3D便可以解决这个问题。而深度信息可以将2D像素或者特征提升到3D空间中,基于此,基于深度预测的PV2BEV也是一大研究热点。受此启发,本文首先比较这些工作的方法设计,包括视角变换的方法,是否包含深度监督,以及如何与IPM结合等等。
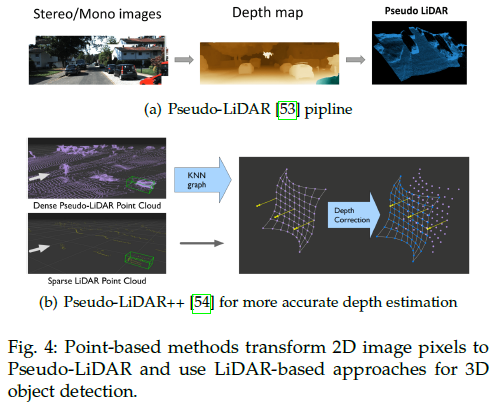
基于点的视角变换
基于深度的PV2BEV方法建立在明确的3D表示上,如上图所示。与基于LiDAR的3D检测一样,可以划分为基于点的方法和基于体素的方法。基于点的方法直接使用深度估计将像素转换为点云,并散射到连续的3D空间中。这种方式更直接、更容易的集成单目深度估计和基于LiDAR的3D检测的成熟经验。开创性的工作Pseudo-LiDAR [53],如下图所示,首先将深度图转换为伪LiDAR点,然后将其输入到基于LiDAR的3D检测器中。Pseudo-LiDAR++ [54]通过立体深度估计网络和损失函数提高了深度精度。AM3D [55]提出用互补的RGB特征来装饰伪点云。但是,上述方法存在两个通病:
数据泄露问题,验证集和测试集之间的性能差距是由于包含KITTI深度基准的数据泄露造成的[53、57]。
泛化问题,并且由于两个网络之间的梯度截断,在训练和部署期间可能会很复杂。
E2E Pseudo-LiDAR [58] 提出了一个Change-of-Representation(CoR)模块,实现了模型的端到端训练。尽管还有若干工作尝试解决这两个问题,但这种类型的方法本质上不如基于体素的方法,特别是对于大型室外场景。
基于体素的视角变换
与分布在连续3D空间中的点云相比,体素通过将3D空间离散化以构建用于特征变换的规则结构,从而为3D场景理解提供更有效的表示;之后的基于BEV的感知模块也可以直接附加。尽管它牺牲了局部的空间精度,但仍然在覆盖大规模场景结构信息方面更有效,并且与用于视角转换的端到端学习范式兼容。
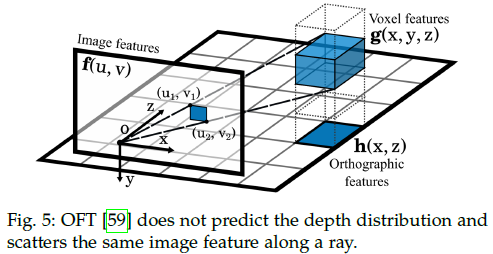
具体来说,该方案基于深度信息直接在相应的3D位置投射对应的2D特征(而不是点)。先前的工作通过将2D特征图与对应的深度预测结果进行外积来实现。早期的工作假设分布是均匀的,即沿一条射线的所有特征都是相同的,如上图所示[59]。OFT[59]建立了一个内部表示,以确定图像中的哪些特征与鸟瞰图上的位置有关。它在均匀的3D栅格中构建了一个体素特征图,并通过投影对应图像特征来累积填充体素。之后,通过沿y轴对体素特征求和得到正交特征图,后面使用CNN提取BEV特征进行3D目标检测。值得注意的是,对于图像上的每个像素,网络为其分配相同的3D预测表示,即预测深度上的均匀分布。这类方法通常不需要深度监督,并且可以通过端到端的方式在视角转换后学习网络中的深度或3D位置信息。
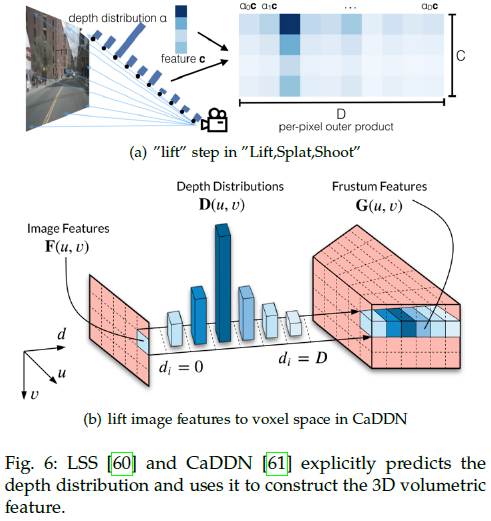
相比之下,另一种范式显示预测深度分布并用来构建3D特征。如下图所示,LSS[60]预测深度上的分类分布和上下文向量,他们的外积可以确定沿透视射线的每个点的特征,这些特征接近真实的深度分布。此外,其将所有相机的预测结果融到一个场景下,从而减小校准误差。BEVDet [62]遵循了LSS范式,并提出了一个用于从BEV进行多视角相机3D检测的框架,该框架由图像视角编码器、视角转换器、BEV编码器和检测头组成。后续的BEVDet4D [63]在基于多摄像头的3D检测中利用了时间线索。
文章出处登录后可见!