



Dataframe数据默认按索引排序,主要重排方法有:
1、 通过frame=frame.reindex([6,5,4,3,2,1,0]) 重排:
data_demo=pd.read_csv('dataset.csv')
data_demo=data_demo.iloc[:10,:]
data_demo
此时的数据为(这里仅展示部分数据):
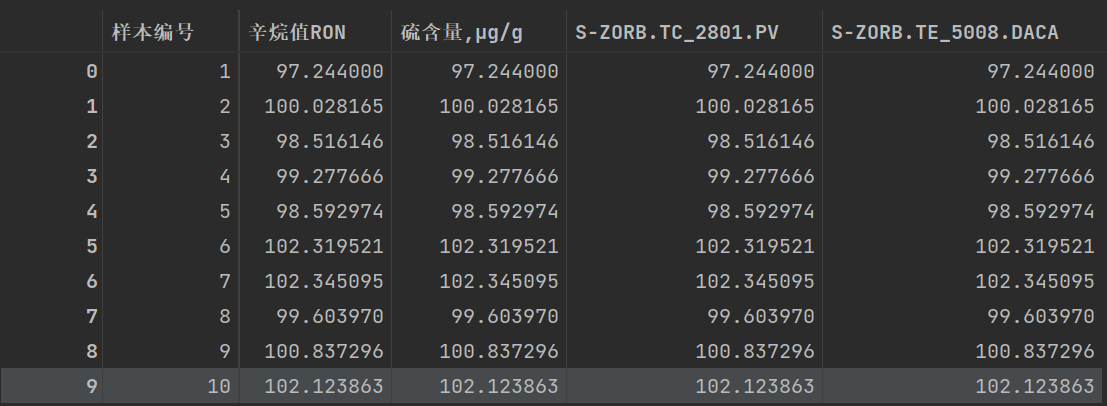
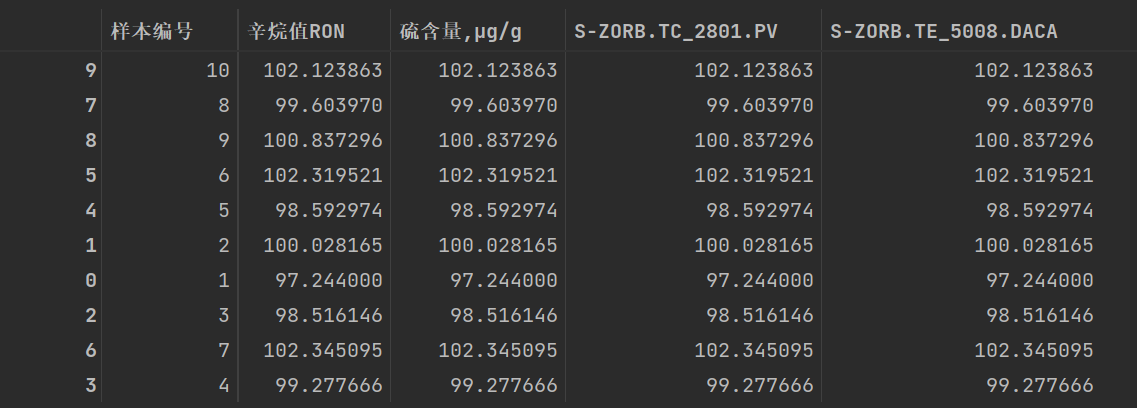
我们按照第一种方法排序,结果如下:

data_demo_1=data_demo.reindex([9,7,8,5,4,1,0,2,6,3])
data_demo_1
2、通过frame.sort_values(by=[‘height’],ascending=False):
按照height字段重排,默认按升序,需要降序时再加ascending=False参数。
如果数据是字符,则是按照字符编码排序,看起来好像没有规律。如果想看一个汉字的编码,可以使用'xx'.encode()的方法查看。
我们展示一下部分原数据:
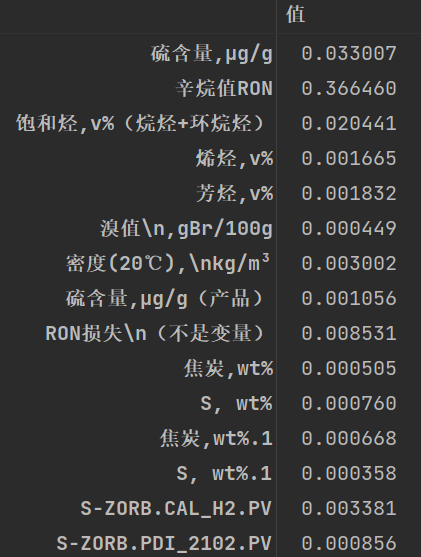

我们的目标是把“值”那一列进行排序:
data_RF_pre_100=data_RF.sort_values(by=['值'],ascending=False)
data_RF_pre_100
展示排序后的结果:
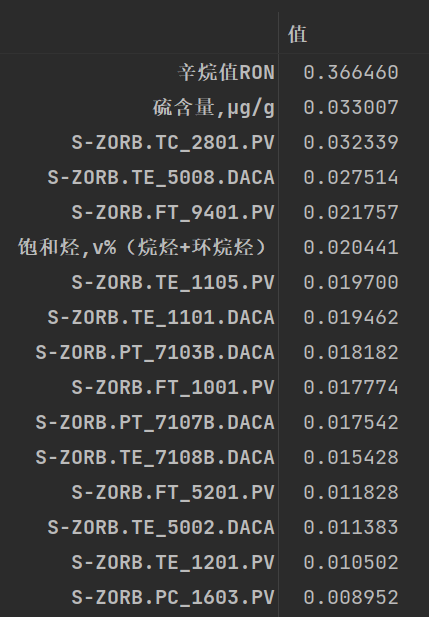
3、 通过frame.sort_values(by=[‘A’,‘B’],ascending=[False,True]):
先按A列再按B列排序,其中A列降序,B列升序
原数据:
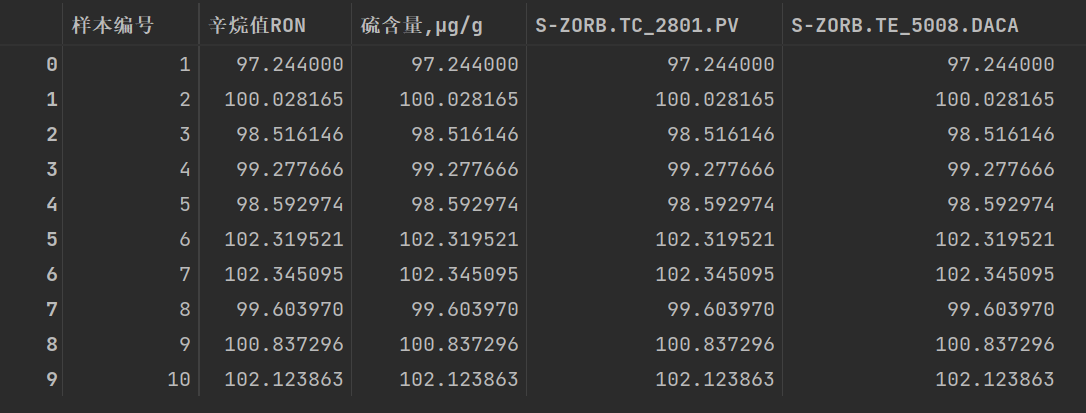
上面的排序方式:
data_demo_3=data_demo.sort_values(by=['辛烷值RON','硫含量,μg/g'],ascending=[False,True])
data_demo_3
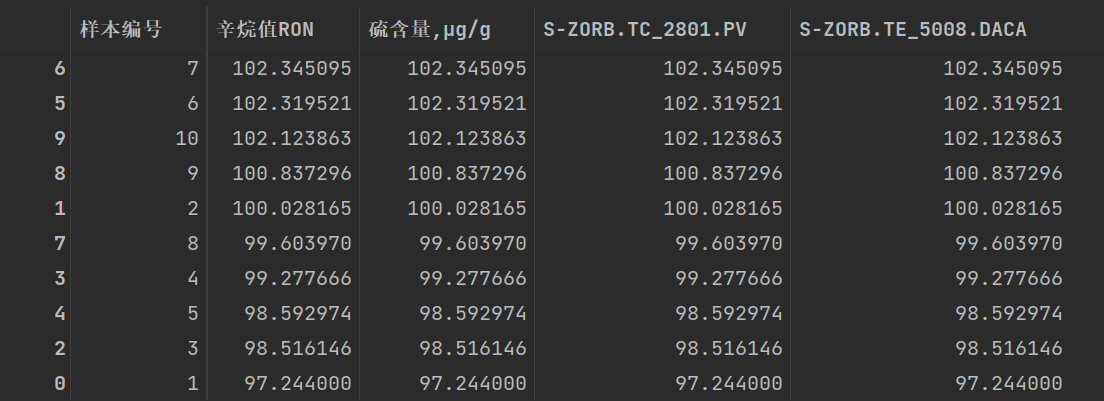

5、一些其他的细节问题:
排序完如果还想调整索引号为升序,则增加这样一句话:
frame.reset_index(drop=True)
如果不想删除原索引号,只增加一列新索引,则用:
frame.reset_index()
在任何时候,如果想恢复原来的索引排序,则用:
frame.sord_index()
列的重新排序,即是数据的重新选择:
frame[['A', 'B','C', 'D']]
文章出处登录后可见!
已经登录?立即刷新