1 FCN网络介绍
FCN(Fully Convolutional Networks,全卷积网络) 用于图像语义分割,它是首个端对端的针对像素级预测的全卷积网络,自从该网络提出后,就成为语义分割的基本框架,后续算法基本都是在该网络框架中改进而来。
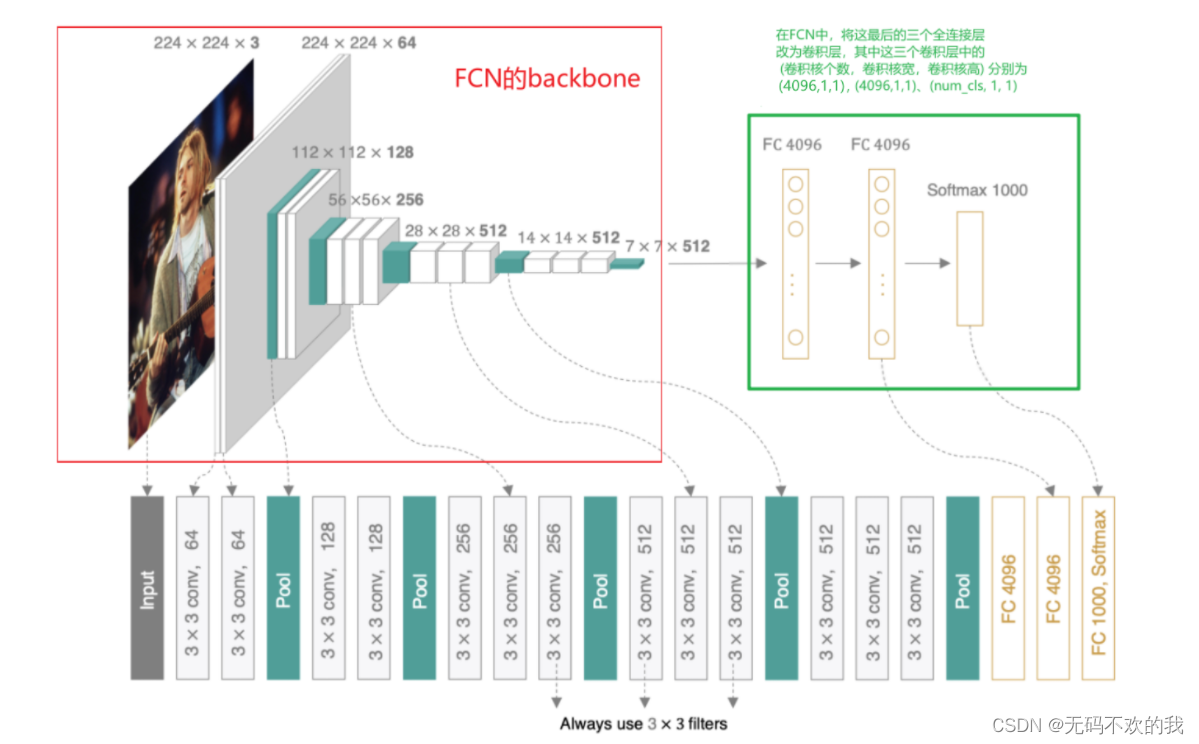
对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割
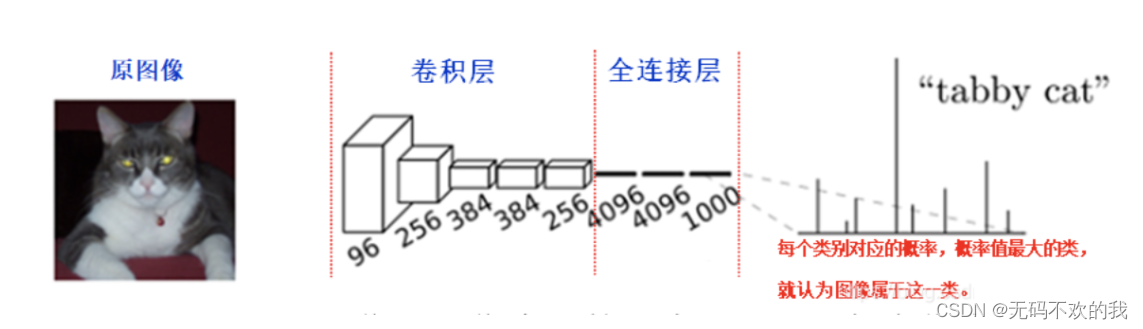
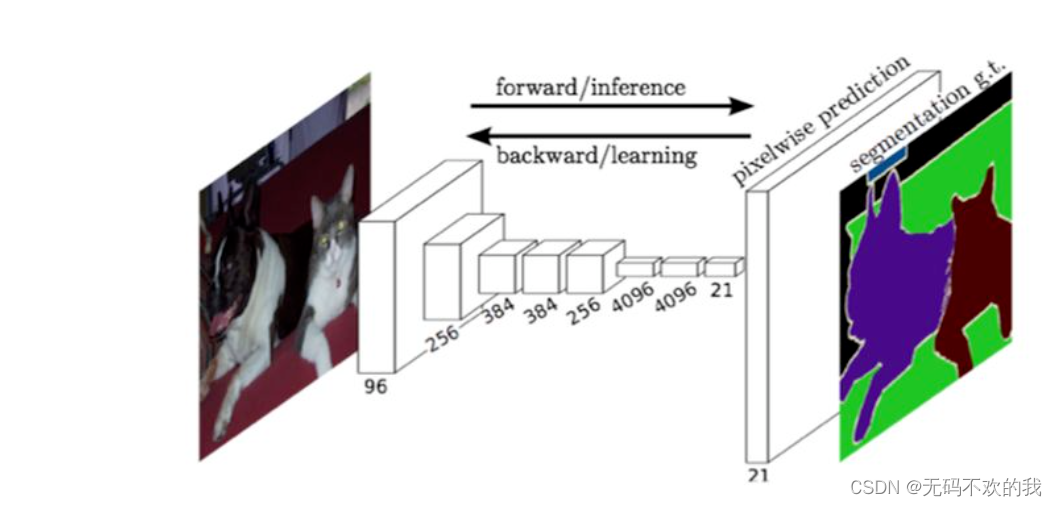
FCN对图像进行像素级的分类,与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN提出可以把后面几个全连接都换成卷积(这样就可以接受任意尺寸的输入图像),这样就可以获得一张2维的feature map,然后采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上使用softmax进行逐像素分类。下图是用于语义分割所采用的全卷积网络(FCN)的结构示意图:
在下图中,输入图像经过卷积和池化之后,得到的 feature map 宽高相对原图缩小了32倍,提取特征之后"特征长方体"的宽高为原图像的 1/32,为了得到与原图大小一致的输出结果,需要对其进行上采样(upsampling),(图中最终输出的"厚度"是 21,因为类别数是 21,每一层可以看做是原图像中的每个像素属于某类别的概率)。
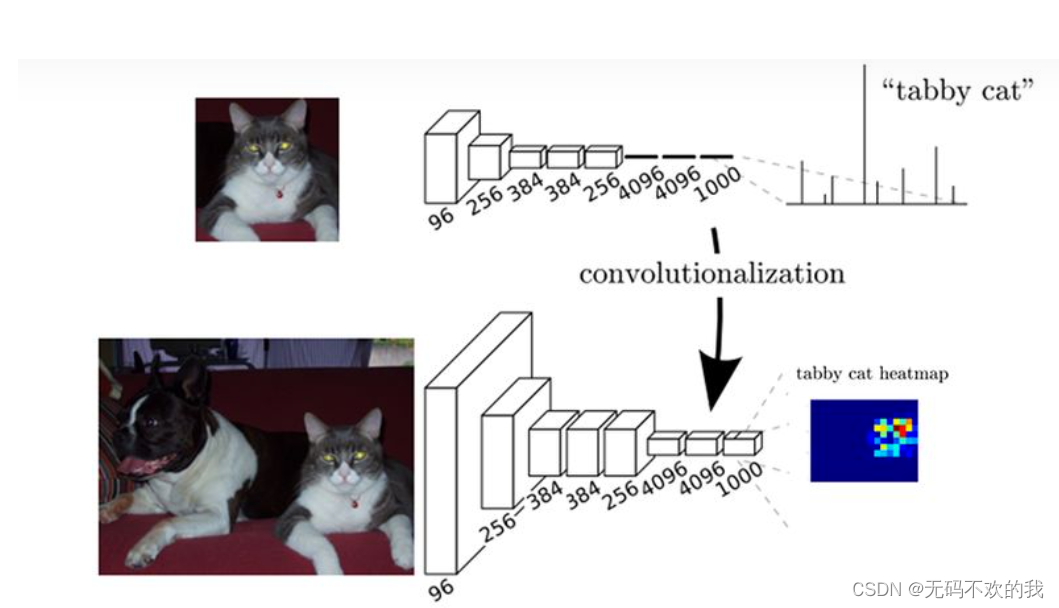
简单的来说,FCN与CNN的区别在于把于FCN将CNN最后的全连接层换成卷积层,然后再进行上采样,得到与与输入大小相同的图像,然后使用softmax获得每个像素点的分类信息,从而解决了分割问题,如下图所示:
2 网络结构
FCN是一个端到端,像素对像素的全卷积网络,用于进行图像的语义分割。整体的网络结构分为两个部分:全卷积部分和上采样部分。
下面我们以backbone为vgg16的FCN为例进行讲解,所以在讲解FCN之前,我们先回顾一下vgg16的结构:
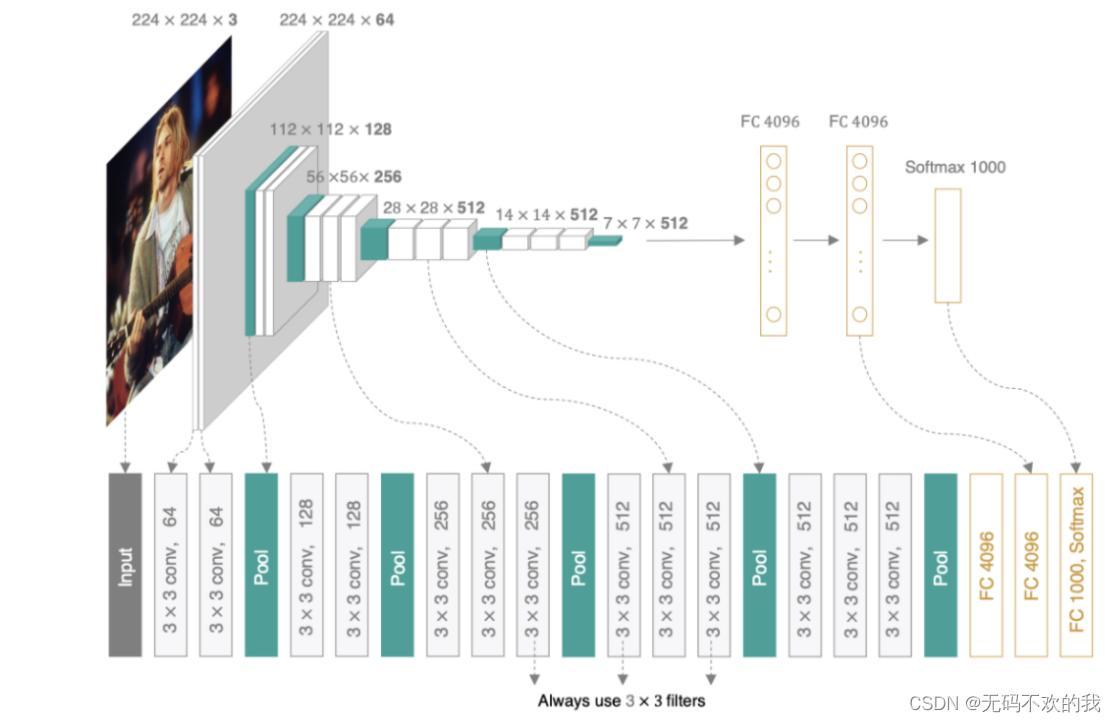
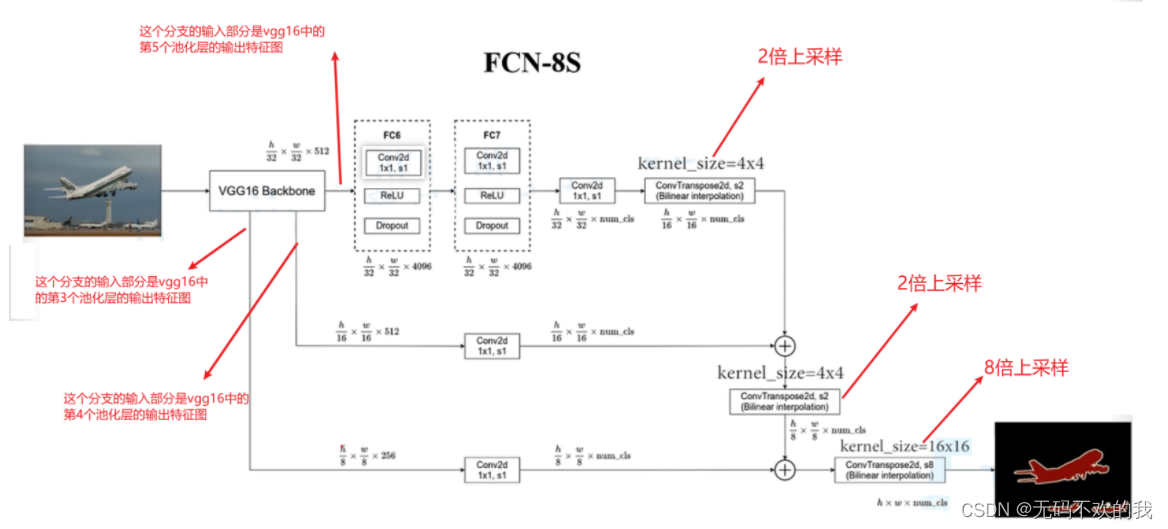
而在FCN中,使用了vgg16的卷积部分作为backbone,并将vgg16的最后三个全连接层也改为卷积层。除此之外,还增加了上采样部分,这里是使用转置卷积进行上采样
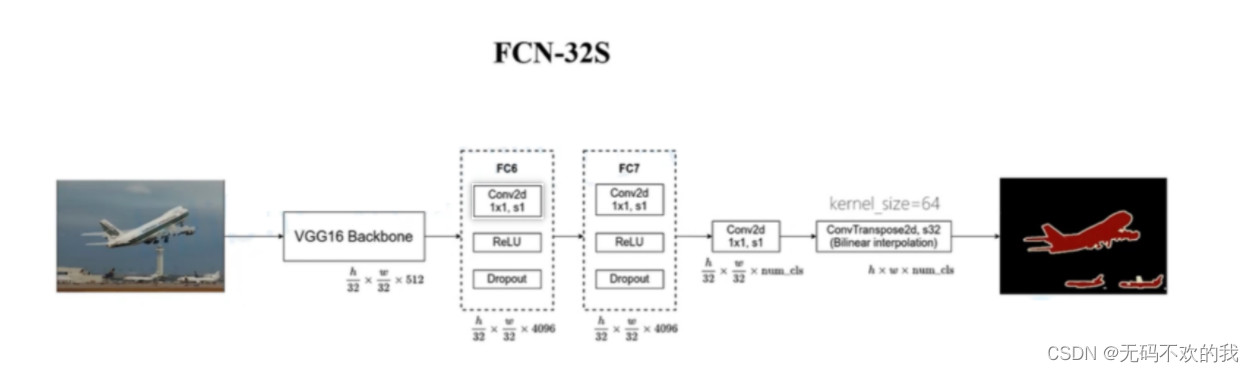
下图是FCN-32S的结构图:它使用了vgg16的卷边部分作为backbone,并将vgg16的最后三个全连接层也改为卷积层。在上采样部分,它使用步长为32的转置卷积将特征图上采样32倍,还原成原图大小。注意,在原论文对应的源代码中,使用双线性插值的参数来初始化转置卷积参数。
但是FCN-32S模型的缺点是在上采样的过程中,一次性将最后的特征图上采样32倍,此时由于最后一层的特征图太小,所以在上采样的过程中会损失很多细节。
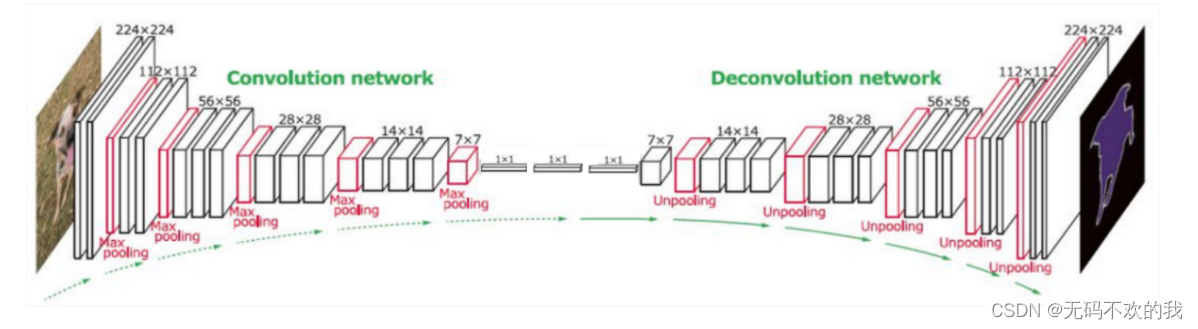
语义分割模型大部分都是编码-解码框架的。通过编码器不断将输入不断进行下采样达到信息浓缩(下采样),而解码器则负责上采样来恢复输入尺寸(上采样)。VGG、ResNet、MobileNet、Inception和DenseNet等,均可作为编码器,用于分割时的信息编码。
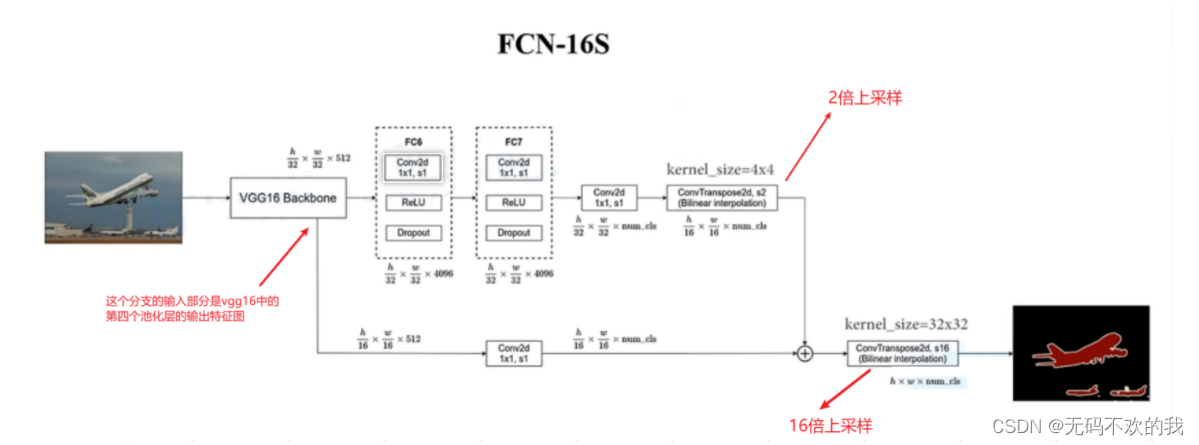
下图是FCN-16S的结构图,它在FCN-32S的基础上增加了一个分支,这个分支的输入部分是vgg16中的第四个池化层的输出特征图。最后将两个分支的输出相加,然后进行16倍上采样,还原到原图大小。
下图是FCN-8S的结构图,它在FCN-16S的基础上增加了一个分支,这个分支的输入部分是vgg16中的第3个池化层的输出特征图。最后将三个分支的输出相加,然后进行8倍上采样,还原到原图大小。
总结:
如果只利用反卷积对最后一层的特征图进行上采样得到原图大小的分割,由于最后一层的特征图太小,会损失很多细节。因而提出增加Skips(跳层连接结构)将最后一层的预测(有更富的全局信息)和更浅层(有更多的局部细节)的预测结合起来。
如果忽略部分细节,FCN-32S, FCN-16S, FCN-8S的结构可以用下图来概括:
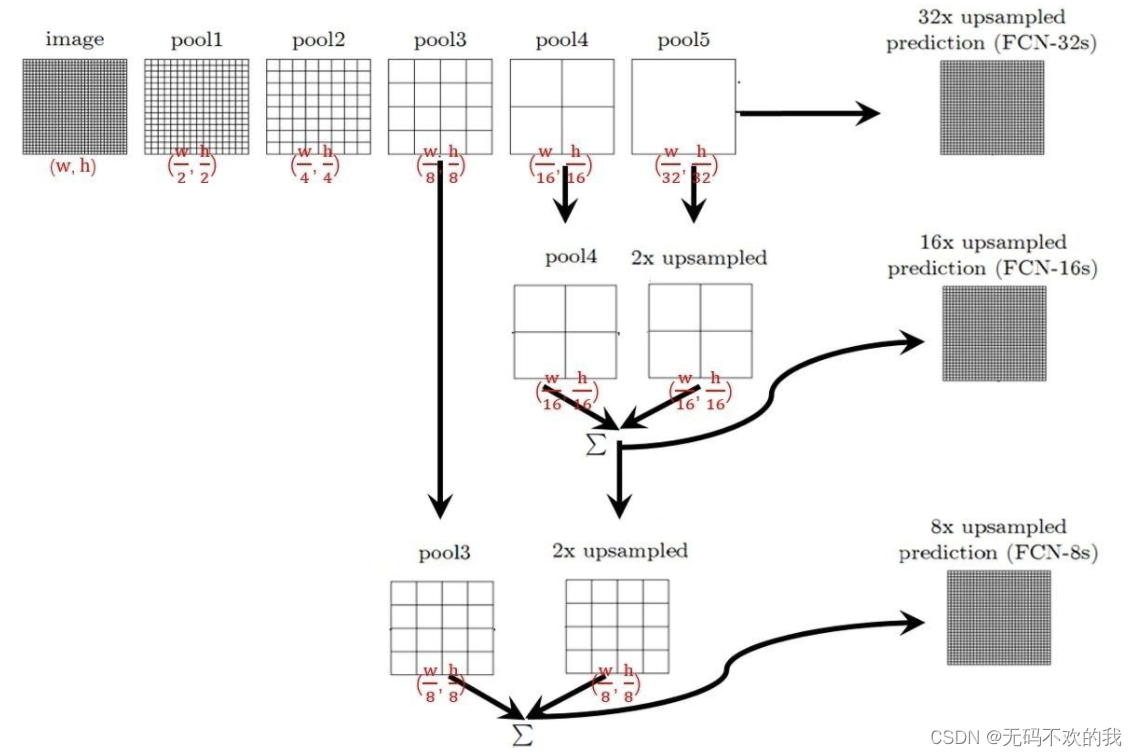
- 对于FCN-32s,直接对pool5 feature进行32倍上采样,再对上采样后的图像的每个点做softmax 获得最终的分割图。
- 对于FCN-16s,首先对pool5 feature进行2倍上采样获得,然后再将其与pool4 feature逐点相加,最后将相加的feature进行16倍上采样,再对上采样后的图像的每个点做softmax获得最终的分割图。
- 对于FCN-8s,首先进行pool5 feature进行2倍上采样,然后再将相加后的结果与pool4 feature逐点相加,得到的结果再与经过2倍上采样后的pool3 feature 逐点相加,最后将相加后featrue进行8倍上采样,再对上采样后的图像的每个点做softmax获得最终的分割图。
下面有一张32倍,16倍和8倍上采样得到的结果图对比:

可以看到随着上采样做得越多,分割结果越来越精细。
3 上采样原理简单介绍
上采样部分将最终得到的特征图上采样得到原图像大小的语义分割结果。
在这里采用的上采样方法是反卷积(Deconvolution),也叫做转置卷积(Transposed Convolution):
- 反卷积是一种特殊的正向卷积
- 通俗的讲:对输入特征图按照一定的比例补0后来扩大特征图的尺寸,再进行正向卷积获取一个尺寸比原始特征图更大的特征图 。
如下图所示:输入图像尺寸为3×3,经过补0后变成5×5,经过padding后变成7×7,卷积核kernel为3×3,步长strides=2,填充padding=1,对补0后的图像进行卷积后虽然相对于补0后的图像变小了,但是相对于原始图像却变大了,这样就达到了对原始图像进行上采用的效果
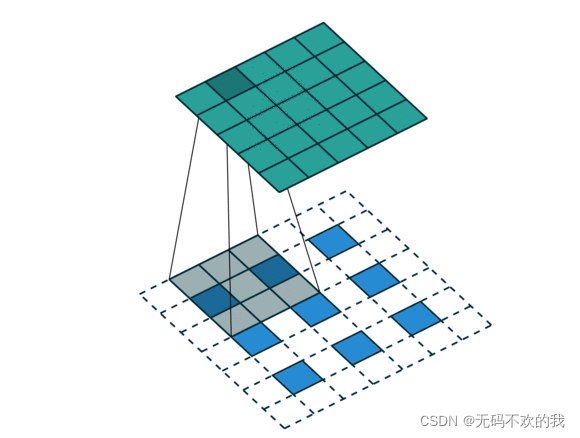
假设反卷积的输入是n x n (在本例中是3×3),反卷积的输出为mxm(在本例中是5×5),padding=p(在本例中是p=1),stride=s(在正常卷积中步长是卷积每次移动的大小,但是在反卷积中,卷积每次移动的大小都是1,所以这里的步长stride并不是卷积每次移动的大小,它是输入特征图中间填充0的个数加1,在本例中,stride=s=2,s-1=1,所以中间填充0个数是1,如果stride=1,则不填充0),kernel_size = k(在本例中是k=3)。
那么此时反卷积的输出就为:
m=s(n−1)+k−2pm=s(n−1)+k−2p
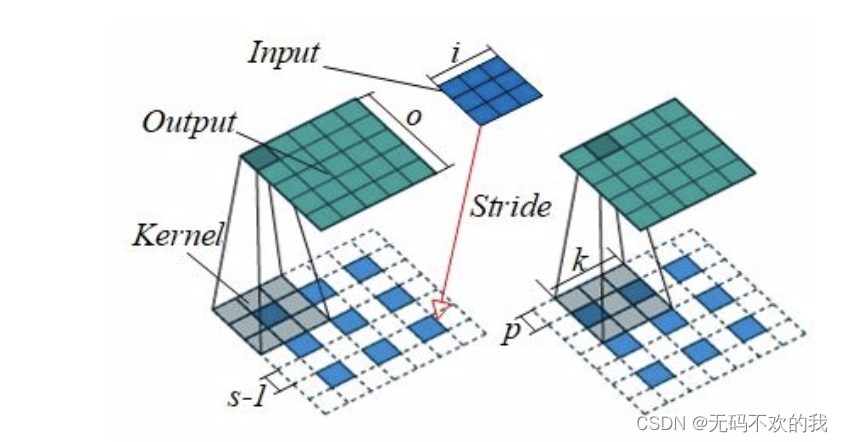
与正向卷积不同的是,要先根据步长strides对输入的内部进行填充,这里strides可以理解成输入放大的倍数,而不能理解成卷积移动的步长。
这样我们就可以通过反卷积实现上采样。
4 代码实现
- 导入必须依赖包
import torch
from torchvision import models
from torch import nn
import torch.nn.functional as F
import numpy as np
- 双线性插值:因为论文中提到了使用双线性插值的参数来初始化转置卷积参数(这种方法了解即可,因为在后面的论文中很少使用该方法)。所以这里首先用代码实现双线性插值方法
def bilinear_kernel(in_channels, out_channels, kernel_size):
"""Define a bilinear kernel according to in channels and out channels.
Returns:
return a bilinear filter tensor
"""
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:kernel_size, :kernel_size]
bilinear_filter = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype=np.float32)
weight[range(in_channels), range(out_channels), :, :] = bilinear_filter
return torch.from_numpy(weight)
- VGG16网络搭建:因为FCN的骨干网络是VGG16,这里直接使用pytorch官方封装好的VGG进行FCN的搭建
pretrained_net = models.vgg16_bn(pretrained=True)
# 打印vgg16网络第一层
print(pretrained_net.features[0])
#输出结果如下
Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# 打印vgg16网络第一层的权重shape
print(pretrained_net.features[0].weight.shape)
#输出结果如下, 64个3*3*3的卷积核
torch.Size([64, 3, 3, 3])
# 打印vgg16网络第1-6层
print(pretrained_net.features[:7])
#输出结果如下;
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
#打印vgg的整体结构(不包括最后的全连接层)
print(pretrained_net.features)
#输出结果如下所示:
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU(inplace=True)
(27): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace=True)
(33): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(36): ReLU(inplace=True)
(37): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(38): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(39): ReLU(inplace=True)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace=True)
(43): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
- FCN代码构建:这里只实现FCN-8s
class FCN(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.stage1 = pretrained_net.features[:7]
self.stage2 = pretrained_net.features[7:14]
self.stage3 = pretrained_net.features[14:24]
self.stage4 = pretrained_net.features[24:34]
self.stage5 = pretrained_net.features[34:]
#1x1卷积用于调整通道数
self.conv_trans1 = nn.Conv2d(512, 256, 1)
self.conv_trans2 = nn.Conv2d(256, num_classes, 1)
#转置卷积用于上采样
# ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, **args)
# 8倍上采样
self.upsample_8x = nn.ConvTranspose2d(num_classes, num_classes, 16, 8, 4, bias=False)
#使用双线性插值对反卷积核进行初始化
self.upsample_8x.weight.data = bilinear_kernel(num_classes, num_classes, 16)
#2倍上采样
self.upsample_2x_1 = nn.ConvTranspose2d(512, 512, 4, 2, 1, bias=False)
#使用双线性插值对反卷积核进行初始化
self.upsample_2x_1.weight.data = bilinear_kernel(512, 512, 4)
#2倍上采样
self.upsample_2x_2 = nn.ConvTranspose2d(256, 256, 4, 2, 1, bias=False)
#使用双线性插值对反卷积核进行初始化
self.upsample_2x_2.weight.data = bilinear_kernel(256, 256, 4)
def forward(self, x):
s1 = self.stage1(x)
s2 = self.stage2(s1)
s3 = self.stage3(s2)
s4 = self.stage4(s3)
s5 = self.stage5(s4)
s5 = self.upsample_2x_1(s5)
add1 = s5 + s4
add1 = self.conv_trans1(add1)
add1 = self.upsample_2x_2(add1)
add2 = add1 + s3
output = self.conv_trans2(add2)
output = self.upsample_8x(output)
return output
- 做简单的测试
x = t.randn(1, 3, 352, 480)
net = FCN(12)
y = net(x)
print(y.shape)
#输出结果如下所示:
torch.Size([1, 12, 352, 480])
5 总结
- 优点
FCN网络可以实现端到端的预测,可以接受任意大小的输入图像尺寸(因为没有全连接层),比较高效。
- 局限性
得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊的,对图像中的细节不敏感。而且在对各个像素进行分类时,没有考虑像素与像素之间的关系。
文章出处登录后可见!