1、计算矩阵的相似性的任务就是找到一个度量,量化矩阵相似程度
1.1将矩阵展开成一维向量,计算两向量的乘积再除以他们的模长。
def mtx_similar1(arr1:np.ndarray, arr2:np.ndarray) ->float:
'''
计算矩阵相似度的一种方法。将矩阵展平成向量,计算向量的乘积除以模长。
:param arr1:矩阵1
:param arr2:矩阵2
:return:实际是夹角的余弦值,ret = (cos+1)/2
'''
farr1 = arr1.ravel()
farr2 = arr2.ravel()
len1 = len(farr1)
len2 = len(farr2)
if len1 > len2:
farr1 = farr1[:len2]
else:
farr2 = farr2[:len1]
numer = np.sum(farr1 * farr2)
denom = np.sqrt(np.sum(farr1**2) * np.sum(farr2**2))
similar = numer / denom
return (similar+1) / 2 # 姑且把余弦函数当线性
1.2相减之后对元素取平方再求和。因为如果越相似那么为0的会越多,平方和越小越相似。
def mtx_similar2(arr1:np.ndarray, arr2:np.ndarray) ->float:
'''
如果矩阵大小不一样会在左上角对齐,截取二者最小的相交范围。
:param arr1:矩阵1
:param arr2:矩阵2
:return:相似度(0~1之间)
'''
if arr1.shape != arr2.shape:
minx = min(arr1.shape[0],arr2.shape[0])
miny = min(arr1.shape[1],arr2.shape[1])
differ = arr1[:minx,:miny] - arr2[:minx,:miny]
else:
differ = arr1 - arr2
numera = np.sum(differ**2)
denom = np.sum(arr1**2)
similar = 1 - (numera / denom)
return similar
1.3欧几里得距离
def mtx_similar3(arr1:np.ndarray, arr2:np.ndarray) ->float:
'''
:param arr1:矩阵1
:param arr2:矩阵2
:return:相似度(0~1之间)
'''
if arr1.shape != arr2.shape:
minx = min(arr1.shape[0],arr2.shape[0])
miny = min(arr1.shape[1],arr2.shape[1])
differ = arr1[:minx,:miny] - arr2[:minx,:miny]
else:
differ = arr1 - arr2
dist = np.linalg.norm(differ, ord='fro')
len1 = np.linalg.norm(arr1)
len2 = np.linalg.norm(arr2) # 普通模长
denom = (len1 + len2) / 2
similar = 1 - (dist / denom)
return similar
1.4应用
推荐算法的相似物品推荐等等…
在算法相似度量中又有以下几种计算方法:
1、同现相似度
2、欧式距离相似度
3、余弦相似度
4、皮尔逊相关系数(Pearson)
5、修正余弦相似度(Adjusted Cosine)
6、汉明距离(Hamming Distance)
7、曼哈顿距离(Manhattan Distance)

4、皮尔逊相关系数
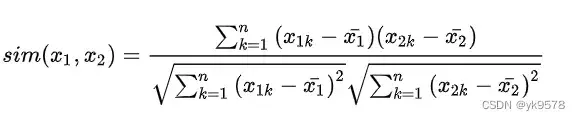
皮尔逊相关系数公式实际上就是在计算夹角余弦之前将两个向量减去各个样本的平均值,达到中心化的目的。从知友的回答可以明白,皮尔逊相关函数是余弦相似度在维度缺失上面的一种改进方法。
# python实现皮尔逊相关系数
def Pearson(x,y):
sum_XY = 0.0
sum_X = 0.0
sum_Y = 0.0
normX = 0.0
normY = 0.0
count = 0
for a,b in zip(x,y):
count += 1
sum_XY += a * b
sum_X += a
sum_Y += b
normX += a**2
normY += b**2
if count == 0:
return 0
# denominator part
denominator = (normX - sum_X**2 / count)**0.5 * (normY - sum_Y**2 / count)**0.5
if denominator == 0:
return 0
return (sum_XY - (sum_X * sum_Y) / count) / denominator
# numpy简化实现皮尔逊系数
def Pearson(dataA,dataB):
# 皮尔逊相关系数的取值范围(-1 ~ 1),0.5 + 0.5 * result 归一化(0 ~ 1)
return 0.5 + 0.5 * np.corrcoef(dataA,dataB,rowvar = 0)[0][1]
# 余弦相似度、修正余弦相似度、皮尔逊相关系数的关系
# Pearson 减去的是每个item i 的被打分的均值
def Pearson(dataA,dataB):
avgA = np.mean(dataA)
avgB = np.mean(dataB)
sumData = (dataA - avgA) * (dataB - avgB).T # 若列为向量则为 dataA.T * dataB
denom = np.linalg.norm(dataA - avgA) * np.linalg.norm(dataB - avgB)
# 归一化
return 0.5 + 0.5 * (sumData / denom)
5、汉明距离
汉明距离表示的是两个字符串(相同长度)对应位不同的数量。比如有两个等长的字符串 str1 = “11111” 和 str2 = “10001” 那么它们之间的汉明距离就是3(这样说就简单多了吧。哈哈)。汉明距离多用于图像像素的匹配(同图搜索)。
def hammingDistance(dataA,dataB):
distanceArr = dataA - dataB
return np.sum(distanceArr == 0)# 若列为向量则为 shape[0]
6、曼哈顿距离
没错,你也是会曼哈顿计量法的人了,现在开始你和秦风只差一张刘昊然的脸了。想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,那么驾驶的最近距离并不是直线距离,因为你不可能横穿房屋。所以,曼哈顿距离表示的就是你的实际驾驶距离,即两个点在标准坐标系上的绝对轴距总和。
# 曼哈顿距离(Manhattan Distance)
def Manhattan(dataA,dataB):
return np.sum(np.abs(dataA - dataB))
print(Manhattan(dataA,dataB))
文章出处登录后可见!
已经登录?立即刷新