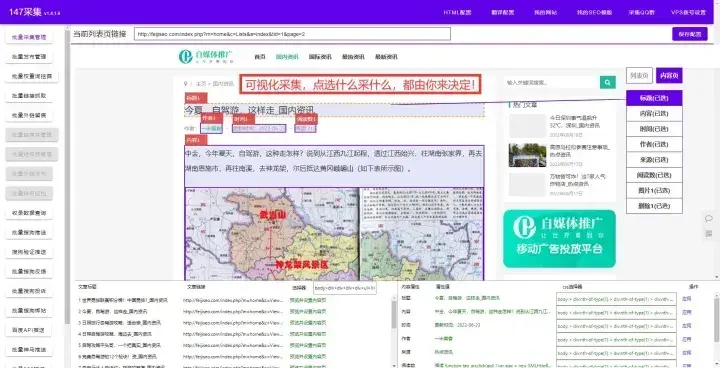
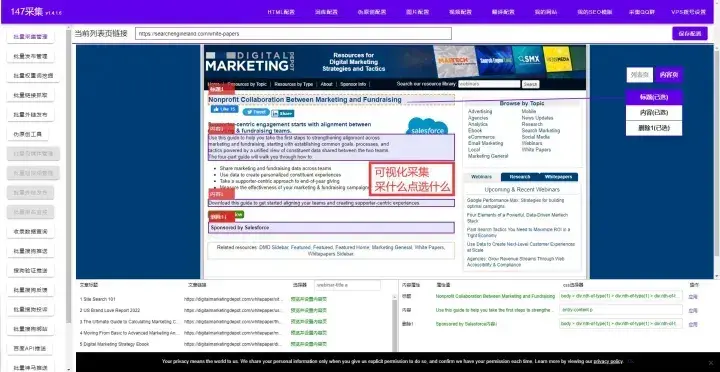
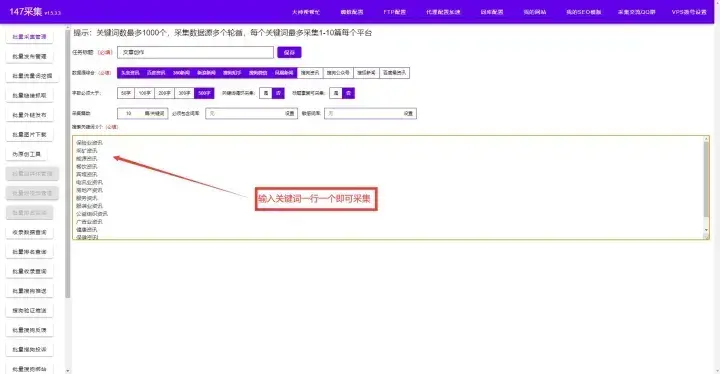
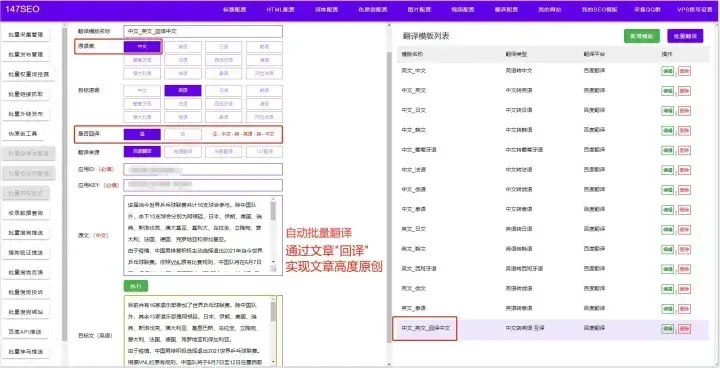
Python爬虫可通过查找一个或多个域的所有 URL 从 Web 收集数据。Python 有几个流行的网络爬虫库和框架。大家熟知的就是python爬取网页数据,对于没有编程技术的普通人来说,怎么才能快速的爬取网站数据呢?今天给大家分享的这款免费爬虫软件让您可以轻松地爬取网页指定数据,不需要你懂任何技术,只要你点点鼠标,就会采集网站任意数据!从此告别复复制和粘贴的工作,爬取的数据可导出为Txt文档 、Excel表格、MySQL、SQLServer、 SQlite、Access、HTML网站等(PS:如果你爬取的是英文数据还可以使用自动翻译)
本文中,我们将首先介绍不同的爬取策略和用例。然后我们将使用两个库在 Python 中从头开始构建一个简单的网络爬虫:Requests和Beautiful Soup。接下来,我们将看看为什么最好使用像Scrapy这样的网络爬虫框架。最后,我们将使用Scrapy构建一个示例爬虫,以从 IMDb 收集电影元数据,并了解Scrapy如何扩展到具有数百万页面的网站。
什么是网络爬虫?
Web 爬取和Web 抓取是两个不同但相关的概念。网页抓取是网页抓取的一个组成部分,抓取器逻辑找到要由抓取器代码处理的 URL。
网络爬虫以要访问的 URL 列表开始,称为种子。对于每个 URL,爬虫在 HTML 中查找链接,根据某些条件过滤这些链接并将新链接添加到队列中。提取所有 HTML 或某些特定信息以由不同的管道处理。
在实践中,网络爬虫只访问一部分页面,具体取决于爬虫预算,这可以是每个域、深度或执行时间的最大页面数。许多网站都提供了一个robots.txt文件来指明网站的哪些路径可以被抓取,哪些是禁止抓取的。还有sitemap.xml,它比 robots.txt 更明确一些,专门指示机器人应抓取哪些路径并为每个 URL 提供额外的元数据。
流行的网络爬虫用例包括:
搜索引擎(例如 Googlebot、Bingbot、Yandex Bot……)收集 Web 重要部分的所有 HTML。此数据已编入索引以使其可搜索。
SEO 分析工具在收集 HTML 的基础上还收集元数据,如响应时间、响应状态以检测损坏的页面以及不同域之间的链接以收集反向链接。
价格监控工具爬行电子商务网站以查找产品页面并提取元数据,尤其是价格。然后定期重新访问产品页面。
Common Crawl 维护着一个开放的 Web 爬网数据存储库。例如,2022 年 5 月的档案包含 34.5 亿个网页。
PyCharm 是 Python 的专用 IDE,地位类似于 Java 的 IDE Eclipse。功能齐全的集成开发环境同时提供收费版和免费版,即专业版和社区版。PyCharm 是安装最快的 IDE,且安装后的配置也非常简单,因此 PyCharm 基本上是数据科学家和算法工程师的首选 IDE。Pycharm是一款功能强大的Python IDE,凭借其强大的编辑和调试功能,以及丰富的插件等功能,受到了广大开发者的青睐。Pycharm也可以用来爬取网页数据,下面就介绍一下pycharm爬取网页数据的方法。
首先,我们需要安装相应的插件,使用pycharm爬取网页数据需要安装Requests和Beautiful Soup这两个插件。在pycharm中打开setting,然后在Plugins选项中搜索Requests和Beautiful Soup,安装完成后重启pycharm,安装完毕。
接下来,我们需要定义一个函数用来爬取网页信息,代码如下:
def get_html(url):
r = requests.get(url)
if r.status_code == 200:
return r.text
else:
return None
这个函数的作用是获取网页的源码,参数url表示要爬取的网页地址,r.text表示网页的源码,r.status_code表示网页的状态码,如果状态码为200表示网页获取成功,则将网页源码返回,否则返回None。
接下来,我们需要定义一个函数来解析网页源码,获取网页里面的数据,代码如下:
def parse_html(html):
soup = BeautifulSoup(html, ‘lxml’)
title = soup.find(‘title’).string # 获取网页的标题
content = soup.find(‘div’, class_=’content’).get_text() # 获取网页的内容
data = {
‘title’: title,
‘content’: content
}
return data
这个函数用来解析网页源码,使用Beautiful Soup解析网页源码,然后使用find方法来获取网页标题和内容,最后将获取的数据保存到字典中,返回字典。
最后,我们需要定义一个函数来调用上面定义的两个函数,实现爬取网页数据的目的,代码如下:
def main(url):
html = get_html(url) # 获取网页的源码
data = parse_html(html) # 解析网页源码,获取数据
print(data) # 打印结果

这个函数用来调用上面定义的两个函数,实现爬取网页数据的目的,参数url表示要爬取的网页地址,最后将爬取到的数据打印出来。
以上就是pycharm爬取网页数据的方法,使用pycharm可以很方便的爬取网页数据,节省了大量的开发时间,提高了开发效率。
文章出处登录后可见!