



一、VOC2007数据集
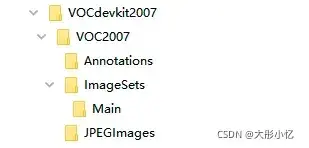
VOC2007数据集的文件结构如下图所示。
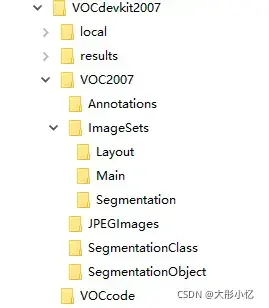
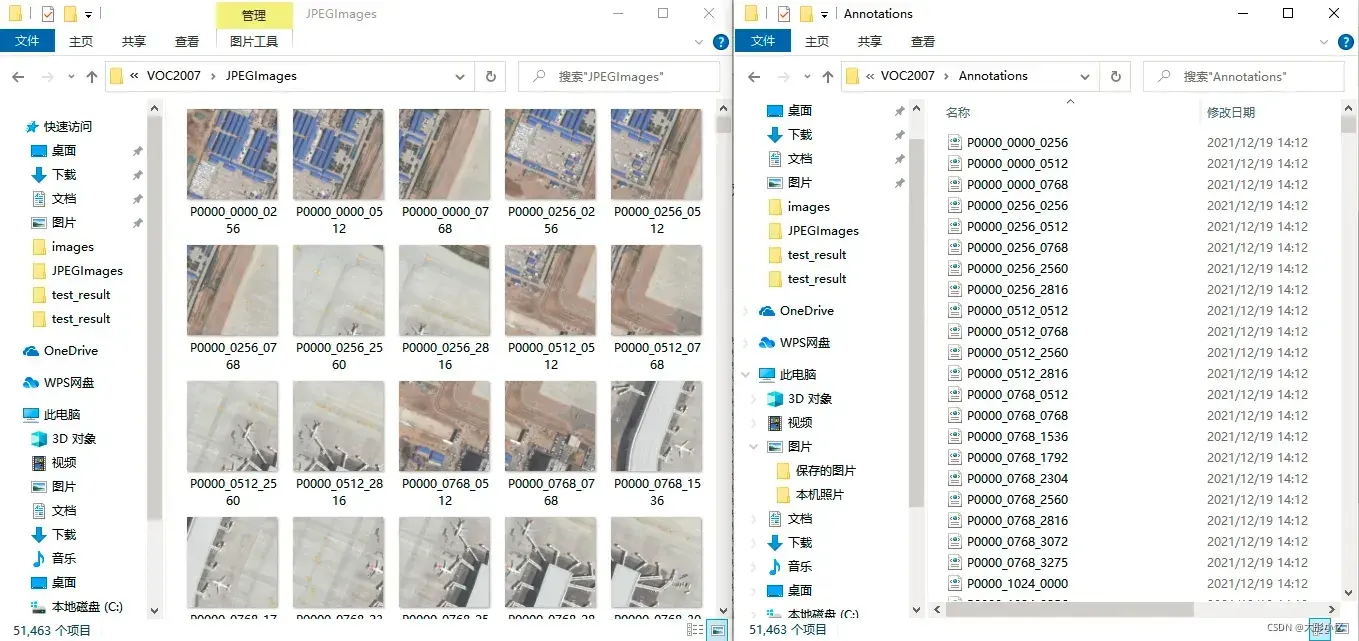
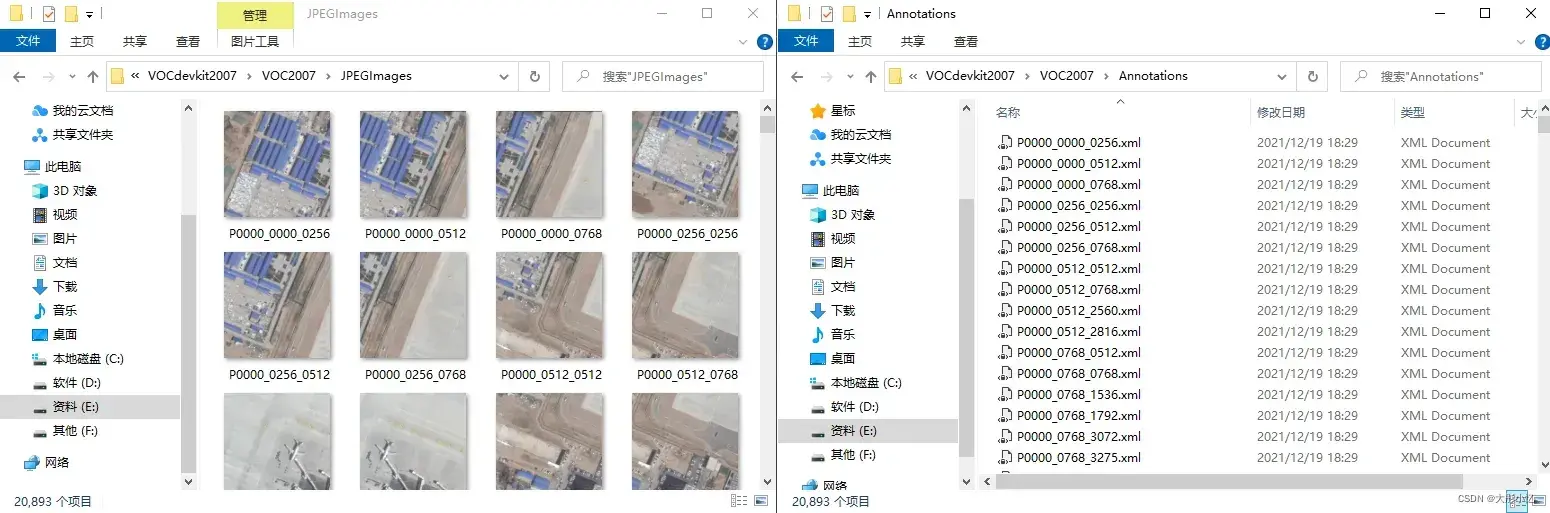
其中,文件夹Annotations中存放的是图像的标注信息的xml文件,命名从000001.xml开始;文件夹ImageSets中存放的是图像划分的集合的txt文件,目标检测任务对应的train、val、trainval、test数据集的txt文件存放在Main文件夹中;文件夹JPEGImages中存放的是所有图片的jpg文件,命名从000001.jpg开始;文件夹SegmentationClass和SegmentationObject中存放的是其他任务的数据信息。
文件夹Annotations中存放的某一张图像的标注信息的xml文件里面的内容如下所示。
<annotation>
<folder>VOC2007</folder>
<!--文件名-->
<filename>000007.jpg</filename>
<!--数据来源-->
<source>
<!--数据来源-->
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<!--来源是flickr,一个雅虎的图像分享网站,下面是id,对于我们没有用-->
<image>flickr</image>
<flickrid>194179466</flickrid>
</source>
<!--图片的所有者,也没有用-->
<owner>
<flickrid>monsieurrompu</flickrid>
<name>Thom Zemanek</name>
</owner>
<!--图像尺寸,宽、高、长-->
<size>
<width>500</width>
<height>333</height>
<depth>3</depth>
</size>
<!--是否用于分割,0表示用于,1表示不用于-->
<segmented>0</segmented>
<!--下面是图像中标注的物体,每一个object包含一个标准的物体-->
<object>
<!--物体名称,拍摄角度-->
<name>car</name>
<pose>Unspecified</pose>
<!--是否被裁减,0表示完整,1表示不完整-->
<truncated>1</truncated>
<!--是否容易识别,0表示容易,1表示困难-->
<difficult>0</difficult>
<!--bounding box的四个坐标-->
<bndbox>
<xmin>141</xmin>
<ymin>50</ymin>
<xmax>500</xmax>
<ymax>330</ymax>
</bndbox>
</object>
</annotation>
关于VOC2007数据集的其他详细信息可见→VOC2007数据集详细分析。
二、DOTA数据集
DOTA数据集的官方链接→DOTA数据集链接。
DOTA数据集(全称A Large-scale Dataset for Object DeTection in Aerial Images)是用于航拍图像中的目标检测的大型图像数据集, 它可用于发现和评估航拍图像中的物体。 对于DOTA数据集,它包含来自不同传感器和平台的2806个航拍图像。每个图像的大小在大约800×800到4000×4000像素的范围内,并且包含各种比例,方向和形状的对象。这些DOTA图像由航空影像解释专家分类为15个常见对象类别。完全注释的DOTA图像包含188、282个实例,每个实例都由任意(8自由度)四边形标记。
目前DOTA数据集有三个版本:
- DOTA-v1.0:包含15个常见类别,2,806个图像和188,282个实例。DOTA-V1.0中的训练集,验证集和测试集的比例分别为1/2,1 / 6和1/3。
plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field and swimming pool. - DOTA-v1.5:使用了与DOTA-v1.0相同的图像,但是非常小的实例(小于10像素)也有注释。此外,还增加了一个新的类别”container crane”。它总共包含403,318个实例。图像和数据集分割的数量与DOTA-v1.0相同。该版本是为了与IEEE CVPR 2019联合举办的2019 DOAI航拍图像目标检测挑战赛发布的。
plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, swimming pool and container crane. - DOTA-v2.0:收集更多Google地球,GF-2卫星和空中图像。DOTA-v2.0中有18个常见类别,11,268个图像和1,793,658个实例。与DOTA-V1.5相比,它进一步增加了新类别的”airport”和”helipad”。DOTA的11,268个图像分为训练、验证、测试验证和测试挑战集。
plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, swimming pool, container crane, airport and helipad.
DOTA数据集的文件结构如下图所示。
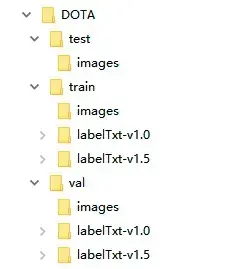
数据集DOTA文件夹下有train、val、test三个文件夹。文件夹train、val下各有images、labelTxt-v1.0、labelTxt-v1.5三个文件夹,文件夹test下只有images一个文件夹。
其中images文件夹中存放的是遥感图像,如下图所示。

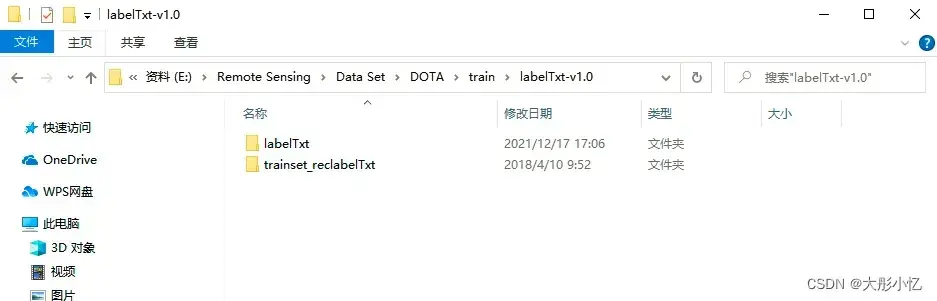
labelTxt-v1.0文件夹中存放的是DOTA v1.0版本的标签信息,如下图所示,有labelTxt、trainset_reclabelTxt两个文件夹。labelTxt文件夹中存放的是obb(定向边界框)标签信息,trainset_reclabelTxt文件夹中存放的是hbb(水平边界框)标签信息。

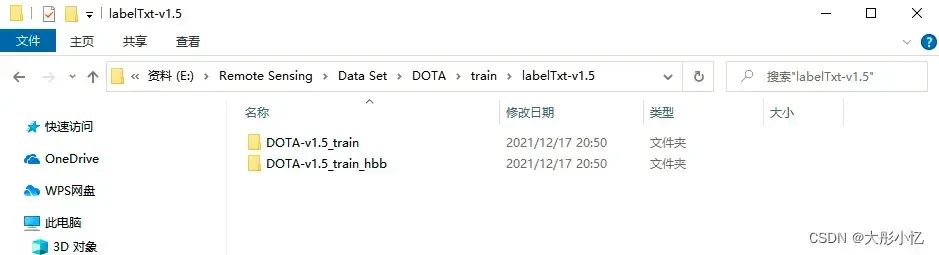
labelTxt-v1.5文件夹中存放的是DOTA v1.5版本的标签信息,与labelTxt-v1.0文件夹类似,如下图所示,该文件夹下有存放obb(定向边界框)标签信息的文件夹DOTA-v1.5_train和存放hbb(水平边界框)标签信息的文件夹DOTA-v1.5_train_hbb。


三、将DOTA数据集的格式转换成VOC2007数据集的格式
使用Python将DOTA数据集的格式转换成VOC2007数据集的格式需要进行以下操作。
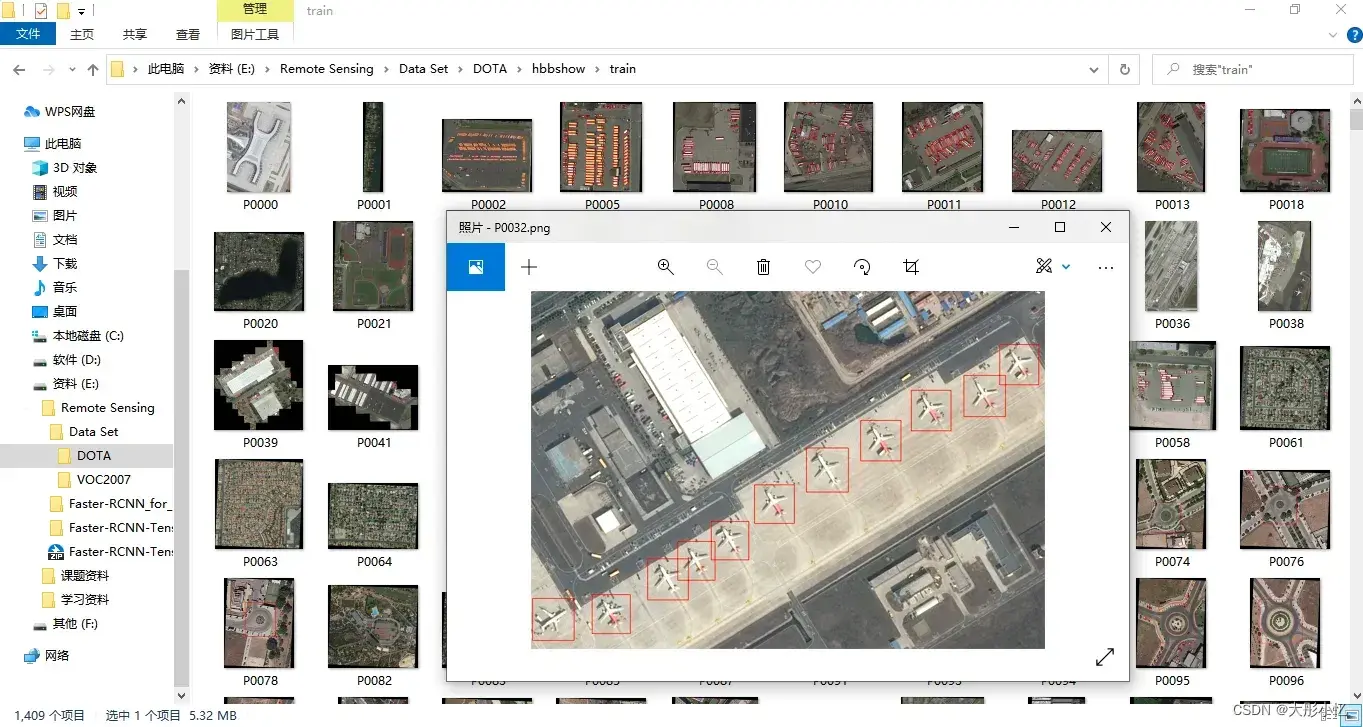
- 首先可以对DOTA数据集中图片的ground truth进行可视化,可视化的代码
visual_DOTA.py及结果如下所示。
import cv2
import os
import numpy as np
thr=0.95
def custombasename(fullname):
return os.path.basename(os.path.splitext(fullname)[0])
def GetFileFromThisRootDir(dir,ext = None):
allfiles = []
needExtFilter = (ext != None)
for root,dirs,files in os.walk(dir):
for filespath in files:
filepath = os.path.join(root, filespath)
extension = os.path.splitext(filepath)[1][1:]
if needExtFilter and extension in ext:
allfiles.append(filepath)
elif not needExtFilter:
allfiles.append(filepath)
return allfiles
def visualise_gt(label_path, pic_path, newpic_path):
results = GetFileFromThisRootDir(label_path)
for result in results:
f = open(result,'r')
lines = f.readlines()
if len(lines)==0: #如果为空
print('文件为空',result)
continue
boxes = []
for i,line in enumerate(lines):
#score = float(line.strip().split(' ')[8])
#if i in [0,1]: #如果可视化DOTA-v1.5,前两行不需要,跳过,取消注释;如果可视化DOTA-v1.0,前两行需要,注释掉这两行代码
# continue
name = result.split('/')[-1]
box=line.strip().split(' ')[0:8]
box = np.array(box,dtype = np.float64)
#if float(score)>thr:
boxes.append(box)
boxes = np.array(boxes,np.float64)
f.close()
filepath=os.path.join(pic_path, name.split('.')[0]+'.png')
im=cv2.imread(filepath)
#print line3
for i in range(boxes.shape[0]):
box =np.array( [[boxes[i][0],boxes[i][1]],[boxes[i][2],boxes[i][3]], \
[boxes[i][4],boxes[i][5]],[boxes[i][6],boxes[i][7]]],np.int32)
box = box.reshape((-1,1,2))
cv2.polylines(im,[box],True,(0,0,255),2)
cv2.imwrite(os.path.join(newpic_path,result.split('/')[-1].split('.')[0]+'.png'),im)
#下面是有score的
# x,y,w,h,score=box.split('_')#
# score=float(score)
# cv2.rectangle(im,(int(x),int(y)),(int(x)+int(w),int(y)+int(h)),(0,0,255),1)
# cv2.putText(im,'%3f'%score, (int(x)+int(w),int(y)+int(h)+5),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
# cv2.imwrite(newpic_path+filename,im)
if __name__ == '__main__':
pic_path = 'E:/Remote Sensing/Data Set/DOTA/train/images/' #样本图片路径
label_path = 'E:/Remote Sensing/Data Set/DOTA/train/labelTxt-v1.0/trainset_reclabelTxt/'#DOTA标签的所在路径
newpic_path= 'E:/Remote Sensing/Data Set/DOTA/hbbshow/train/' #可视化保存路径
if not os.path.isdir(newpic_path):
os.makedirs(newpic_path)
visualise_gt(label_path, pic_path, newpic_path)

-
新建一个与VOC2007数据集的文件结构类似的DOTA数据集文件结构,只保留我们需要的部分。
-
由于DOTA数据集中有的图片纵横比太大,不能直接用于后续的训练,所以需要对DOTA数据集进行切割。将数据集中的图片切割为600
DOTA_VOC.py及结果如下所示。


import os
import imageio
from xml.dom.minidom import Document
import numpy as np
import copy, cv2
def save_to_xml(save_path, im_width, im_height, objects_axis, label_name, name, hbb=True):
im_depth = 0
object_num = len(objects_axis)
doc = Document()
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
folder = doc.createElement('folder')
folder_name = doc.createTextNode('VOC2007')
folder.appendChild(folder_name)
annotation.appendChild(folder)
filename = doc.createElement('filename')
filename_name = doc.createTextNode(name)
filename.appendChild(filename_name)
annotation.appendChild(filename)
source = doc.createElement('source')
annotation.appendChild(source)
database = doc.createElement('database')
database.appendChild(doc.createTextNode('The VOC2007 Database'))
source.appendChild(database)
annotation_s = doc.createElement('annotation')
annotation_s.appendChild(doc.createTextNode('PASCAL VOC2007'))
source.appendChild(annotation_s)
image = doc.createElement('image')
image.appendChild(doc.createTextNode('flickr'))
source.appendChild(image)
flickrid = doc.createElement('flickrid')
flickrid.appendChild(doc.createTextNode('322409915'))
source.appendChild(flickrid)
owner = doc.createElement('owner')
annotation.appendChild(owner)
flickrid_o = doc.createElement('flickrid')
flickrid_o.appendChild(doc.createTextNode('knautia'))
owner.appendChild(flickrid_o)
name_o = doc.createElement('name')
name_o.appendChild(doc.createTextNode('yang'))
owner.appendChild(name_o)
size = doc.createElement('size')
annotation.appendChild(size)
width = doc.createElement('width')
width.appendChild(doc.createTextNode(str(im_width)))
height = doc.createElement('height')
height.appendChild(doc.createTextNode(str(im_height)))
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode(str(im_depth)))
size.appendChild(width)
size.appendChild(height)
size.appendChild(depth)
segmented = doc.createElement('segmented')
segmented.appendChild(doc.createTextNode('0'))
annotation.appendChild(segmented)
for i in range(object_num):
objects = doc.createElement('object')
annotation.appendChild(objects)
object_name = doc.createElement('name')
object_name.appendChild(doc.createTextNode(label_name[int(objects_axis[i][-1])]))
objects.appendChild(object_name)
pose = doc.createElement('pose')
pose.appendChild(doc.createTextNode('Unspecified'))
objects.appendChild(pose)
truncated = doc.createElement('truncated')
truncated.appendChild(doc.createTextNode('1'))
objects.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult.appendChild(doc.createTextNode('0'))
objects.appendChild(difficult)
bndbox = doc.createElement('bndbox')
objects.appendChild(bndbox)
if hbb:
x0 = doc.createElement('xmin')
x0.appendChild(doc.createTextNode(str((objects_axis[i][0]))))
bndbox.appendChild(x0)
y0 = doc.createElement('ymin')
y0.appendChild(doc.createTextNode(str((objects_axis[i][1]))))
bndbox.appendChild(y0)
x1 = doc.createElement('xmax')
x1.appendChild(doc.createTextNode(str((objects_axis[i][2]))))
bndbox.appendChild(x1)
y1 = doc.createElement('ymax')
y1.appendChild(doc.createTextNode(str((objects_axis[i][5]))))
bndbox.appendChild(y1)
else:
x0 = doc.createElement('x0')
x0.appendChild(doc.createTextNode(str((objects_axis[i][0]))))
bndbox.appendChild(x0)
y0 = doc.createElement('y0')
y0.appendChild(doc.createTextNode(str((objects_axis[i][1]))))
bndbox.appendChild(y0)
x1 = doc.createElement('x1')
x1.appendChild(doc.createTextNode(str((objects_axis[i][2]))))
bndbox.appendChild(x1)
y1 = doc.createElement('y1')
y1.appendChild(doc.createTextNode(str((objects_axis[i][3]))))
bndbox.appendChild(y1)
x2 = doc.createElement('x2')
x2.appendChild(doc.createTextNode(str((objects_axis[i][4]))))
bndbox.appendChild(x2)
y2 = doc.createElement('y2')
y2.appendChild(doc.createTextNode(str((objects_axis[i][5]))))
bndbox.appendChild(y2)
x3 = doc.createElement('x3')
x3.appendChild(doc.createTextNode(str((objects_axis[i][6]))))
bndbox.appendChild(x3)
y3 = doc.createElement('y3')
y3.appendChild(doc.createTextNode(str((objects_axis[i][7]))))
bndbox.appendChild(y3)
f = open(save_path,'w')
f.write(doc.toprettyxml(indent = ''))
f.close()
class_list = ['plane', 'baseball-diamond', 'bridge', 'ground-track-field',
'small-vehicle', 'large-vehicle', 'ship',
'tennis-court', 'basketball-court',
'storage-tank', 'soccer-ball-field',
'roundabout', 'harbor',
'swimming-pool', 'helicopter'] # DOTA v1.0有15个类别;DOTA v1.5有16个类别,比DOTA v1.0多一个container-crane类别
def format_label(txt_list):
format_data = []
for i in txt_list[0:]: # 处理DOTA v1.0为txt_list[0:];处理DOTA v1.5改为txt_list[2:]
format_data.append(
[int(float(xy)) for xy in i.split(' ')[:8]] + [class_list.index(i.split(' ')[8])]
# {'x0': int(i.split(' ')[0]),
# 'x1': int(i.split(' ')[2]),
# 'x2': int(i.split(' ')[4]),
# 'x3': int(i.split(' ')[6]),
# 'y1': int(i.split(' ')[1]),
# 'y2': int(i.split(' ')[3]),
# 'y3': int(i.split(' ')[5]),
# 'y4': int(i.split(' ')[7]),
# 'class': class_list.index(i.split(' ')[8]) if i.split(' ')[8] in class_list else 0,
# 'difficulty': int(i.split(' ')[9])}
)
if i.split(' ')[8] not in class_list :
print ('warning found a new label :', i.split(' ')[8])
exit()
return np.array(format_data)
def clip_image(file_idx, image, boxes_all, width, height):
# print ('image shape', image.shape)
if len(boxes_all) > 0:
shape = image.shape
for start_h in range(0, shape[0], 256):
for start_w in range(0, shape[1], 256):
boxes = copy.deepcopy(boxes_all)
box = np.zeros_like(boxes_all)
start_h_new = start_h
start_w_new = start_w
if start_h + height > shape[0]:
start_h_new = shape[0] - height
if start_w + width > shape[1]:
start_w_new = shape[1] - width
top_left_row = max(start_h_new, 0)
top_left_col = max(start_w_new, 0)
bottom_right_row = min(start_h + height, shape[0])
bottom_right_col = min(start_w + width, shape[1])
subImage = image[top_left_row:bottom_right_row, top_left_col: bottom_right_col]
box[:, 0] = boxes[:, 0] - top_left_col
box[:, 2] = boxes[:, 2] - top_left_col
box[:, 4] = boxes[:, 4] - top_left_col
box[:, 6] = boxes[:, 6] - top_left_col
box[:, 1] = boxes[:, 1] - top_left_row
box[:, 3] = boxes[:, 3] - top_left_row
box[:, 5] = boxes[:, 5] - top_left_row
box[:, 7] = boxes[:, 7] - top_left_row
box[:, 8] = boxes[:, 8]
center_y = 0.25*(box[:, 1] + box[:, 3] + box[:, 5] + box[:, 7])
center_x = 0.25*(box[:, 0] + box[:, 2] + box[:, 4] + box[:, 6])
# print('center_y', center_y)
# print('center_x', center_x)
# print ('boxes', boxes)
# print ('boxes_all', boxes_all)
# print ('top_left_col', top_left_col, 'top_left_row', top_left_row)
cond1 = np.intersect1d(np.where(center_y[:]>=0 )[0], np.where(center_x[:]>=0 )[0])
cond2 = np.intersect1d(np.where(center_y[:] <= (bottom_right_row - top_left_row))[0],
np.where(center_x[:] <= (bottom_right_col - top_left_col))[0])
idx = np.intersect1d(cond1, cond2)
# idx = np.where(center_y[:]>=0 and center_x[:]>=0 and center_y[:] <= (bottom_right_row - top_left_row) and center_x[:] <= (bottom_right_col - top_left_col))[0]
# save_path, im_width, im_height, objects_axis, label_name
if len(idx) > 0:
name="%s_%04d_%04d.png" % (file_idx, top_left_row, top_left_col)
print(name)
xml = os.path.join(save_dir, 'Annotations', "%s_%04d_%04d.xml" % (file_idx, top_left_row, top_left_col))
save_to_xml(xml, subImage.shape[1], subImage.shape[0], box[idx, :], class_list, str(name))
# print ('save xml : ', xml)
if subImage.shape[0] > 5 and subImage.shape[1] >5:
img = os.path.join(save_dir, 'JPEGImages', "%s_%04d_%04d.png" % (file_idx, top_left_row, top_left_col))
#cv2.imwrite(img, subImage)
cv2.imwrite(img, cv2.cvtColor(subImage, cv2.COLOR_RGB2BGR))
print ('class_list', len(class_list))
raw_images_dir = 'E:/Remote Sensing/Data Set/DOTA/train/images/'
raw_label_dir = 'E:/Remote Sensing/Data Set/DOTA/train/labelTxt-v1.0/trainset_reclabelTxt/'
save_dir = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/'
images = [i for i in os.listdir(raw_images_dir) if 'png' in i]
labels = [i for i in os.listdir(raw_label_dir) if 'txt' in i]
print ('find image', len(images))
print ('find label', len(labels))
min_length = 1e10
max_length = 1
for idx, img in enumerate(images):
print (idx, 'read image', img)
img_data = imageio.imread(os.path.join(raw_images_dir, img))
# if len(img_data.shape) == 2:
# img_data = img_data[:, :, np.newaxis]
# print ('find gray image')
txt_data = open(os.path.join(raw_label_dir, img.replace('png', 'txt')), 'r').readlines()
# print (idx, len(format_label(txt_data)), img_data.shape)
# if max(img_data.shape[:2]) > max_length:
# max_length = max(img_data.shape[:2])
# if min(img_data.shape[:2]) < min_length:
# min_length = min(img_data.shape[:2])
# if idx % 50 ==0:
# print (idx, len(format_label(txt_data)), img_data.shape)
# print (idx, 'min_length', min_length, 'max_length', max_length)
box = format_label(txt_data)
clip_image(img.strip('.png'), img_data, box, 600, 600)

- 对切割后得到的
./VOCdevkit2007/VOC2007/Annotations/文件夹下的xml文件进行处理,删除不符合要求的xml文件及./VOCdevkit2007/VOC2007/JPEGImages/文件夹下对应的图片。不符合要求的xml文件有以下三种情况:1. 标注目标为空;2. 所有标注目标的difficult均为1;3. 标注目标存在越界的问题(注:标注越界有六种情况 xmin<0、ymin<0、xmax>width、ymax>height、xmax<xmin、ymax<ymin)。处理xml文件的代码remove.py及结果如下所示。
import os
import shutil
import xml.dom.minidom
import xml.etree.ElementTree as ET
def custombasename(fullname):
return os.path.basename(os.path.splitext(fullname)[0])
def GetFileFromThisRootDir(dir,ext = None):
allfiles = []
needExtFilter = (ext != None)
for root,dirs,files in os.walk(dir):
for filespath in files:
filepath = os.path.join(root, filespath)
extension = os.path.splitext(filepath)[1][1:]
if needExtFilter and extension in ext:
allfiles.append(filepath)
elif not needExtFilter:
allfiles.append(filepath)
return allfiles
def cleandata(path, img_path, ext, label_ext):
name = custombasename(path) #名称
if label_ext == '.xml':
tree = ET.parse(path)
root = tree.getroot()
size=root.find('size')
width=int(size.find('width').text)
#print(width)
height=int(size.find('height').text)
#print(height)
objectlist = root.findall('object')
num = len(objectlist)
#print(num)
count=0
count1=0
minus=0
for object in objectlist:
difficult = int(object.find('difficult').text)
#print(difficult)
bndbox=object.find('bndbox')
xmin = int(bndbox.find('xmin').text)
#print(xmin)
ymin = int(bndbox.find('ymin').text)
#print(ymin)
xmax = int(bndbox.find('xmax').text)
#print(xmax)
ymax = int(bndbox.find('ymax').text)
#print(ymax)
if xmin<0 or ymin<0 or width<xmax or height<ymax or xmax<xmin or ymax<ymin: # 目标标注越界的六种情况
minus+=1
count = count1 + difficult
count1 = count
if num == 0 or count == num or minus != 0: # 不符合要求的三种情况
image_path = os.path.join(img_path, name + ext) #样本图片的名称
os.remove(image_path) #移除该标注文件
os.remove(path) #移除该图片文件
if __name__ == '__main__':
root = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/'
img_path = os.path.join(root, 'JPEGImages') #分割后的样本集
label_path = os.path.join(root, 'Annotations') #分割后的标签
ext = '.png' #图片的后缀
label_ext = '.xml'
label_list = GetFileFromThisRootDir(label_path)
for path in label_list:
cleandata(path, img_path, ext, label_ext)

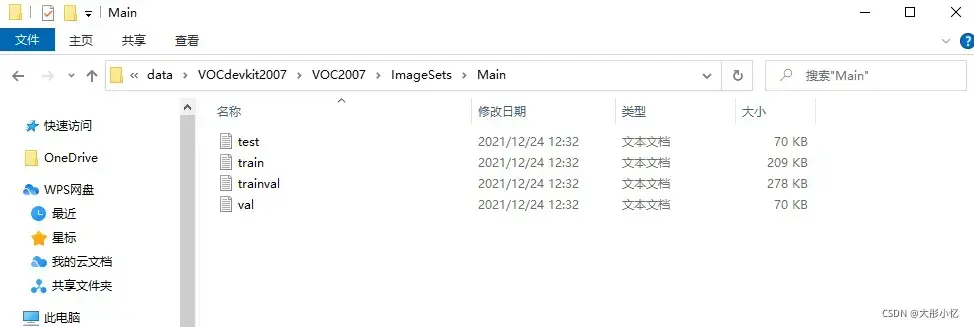
- 对DOTA数据集进行划分,划分为train、val、trainval、test四个文件。划分代码
split_data.py及结果如下所示。
import os
import random
trainval_percent = 0.8 # 表示训练集和验证集(交叉验证集)所占总图片的比例
train_percent = 0.75 # 训练集所占验证集的比例
xmlfilepath = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/Annotations'
txtsavepath = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent) # xml文件中的交叉验证集数
tr = int(tv * train_percent) # xml文件中的训练集数,注意,我们在前面定义的是训练集占验证集的比例
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("done!")

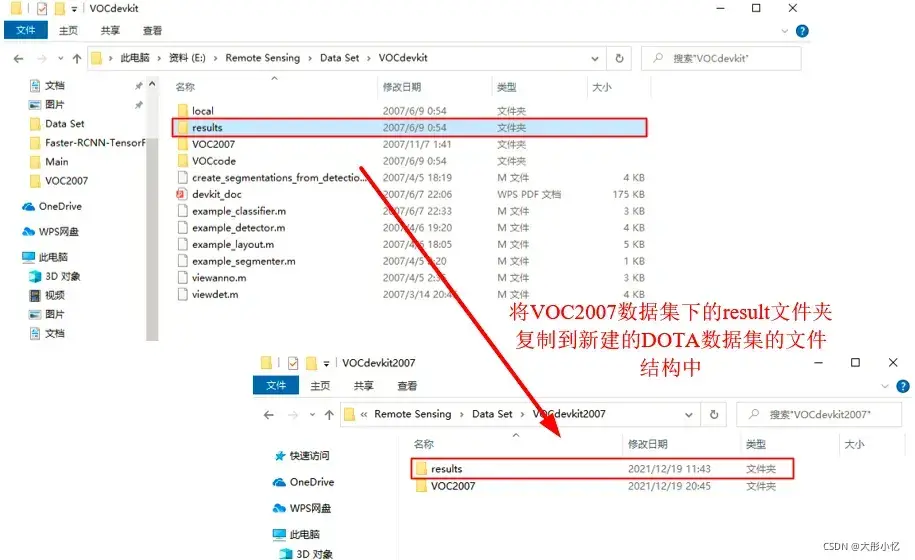
- 最后,将VOC2007数据集下的
result文件夹复制到新建的DOTA数据集的VOC文件结构中,后面训练测试模型时会用到。

至此,就可以将DOTA数据集的格式转换成VOC2007数据集的的格式了,我们得到一个属于DOTA数据集的VOCdevkit2007文件夹!
参考文章:https://blog.csdn.net/mary_0830/article/details/104263619
文章出处登录后可见!