文章目录
前言
案例代码https://github.com/2012Netsky/pytorch_cnn/blob/main/4_time_series_bikes.ipynb
对于分类问题,机器预测的和实际的还是会有所偏差,所以我们引入以下几个概念来评价分类器的优良。
一、TP、TN、FP、FN概念
首先有关TP、TN、FP、FN的概念。大体来看,TP与TN都是分对了情况,TP是正类,TN是负类。则推断出,FP是把错的分成了对的,而FN则是把对的分成了错的。
我的记忆方法:首先看第一个字母是T则代表分类正确,反之分类错误;然后看P,在T中则是正类,若在F中则实际为负类分成了正的。
【举例】以二分类为例(多分类问题类似 混淆矩阵用于计算一下评价指标) 一个班里有男女生,我们来进行分类,把女生看成正类,男生看成是负类。我们可以用混淆矩阵来描述TP、TN、FP、FN。
| 1 | 相关(Relevant),正类 | 无关(NonRelevant),负类 |
|---|---|---|
| 被检索到(Retrieved) | True Positives(TP,正类判定为正类。即女生是女生) | False Positives(FP,负类判定为正类,即“存伪”。男生判定为女生) |
| 未被检索到(Not Retrieved) | False Negatives(FN,正类判定为负类,即“去真”。女生判定为男生) | True Negatives(TN,负类判定为负类。即男生判定为男生) |
二、准确率、精确率(精准率)、召回率、F1值
1.准确率(Accuracy)
顾名思义,就是所有的预测正确(正类负类)的占总的比重。

2.精确率(Precision)查准率
即正确预测为正的占全部预测为正的比例。个人理解:真正正确的占所有预测为正的比例。

3.召回率(Recall)查全率
即正确预测为正的占全部实际为正的比例。个人理解:真正正确的占所有实际为正的比例。

4.F1值(H-mean值)
F1值为算数平均数除以几何平均数,且越大越好,将Precision和Recall的上述公式带入会发现,当F1值小时,True Positive相对增加,而false相对减少,即Precision和Recall都相对增加,即F1对Precision和Recall都进行了加权。

公式转化之后为:

三、ROC曲线、AUC值
1.ROC曲线
接收者操作特征曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,ROC曲线上每个点反映着对同一信号刺激的感受性 下图是ROC曲线例子。
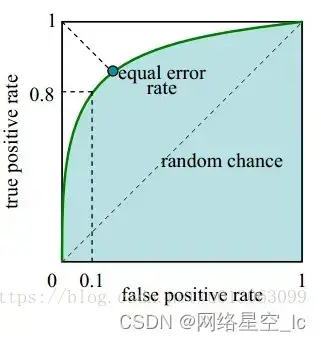
- 横坐标: 1-Specificity,伪正类率(False positive rate,FPR,FPR=FP/(FP+TN)),预测为正但实际为负的样本占所有负例样本的比例;
- 纵坐标: Sensitivity,真正类率(True positive rate,TPR,TPR=TP/(TP+FN)),预测为正且实际为正的样本占所有正例样本的比例。
在一个二分类模型中,假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
真正的理想情况,TPR应接近1,FPR接近0,即图中的(0,1)点。ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。
2.AUC值
AUC (Area Under Curve) 被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。**又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围一般在0.5和1之间。**使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
从AUC判断分类器(预测模型)优劣的标准:
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
一句话来说,AUC值越大的分类器,正确率越高。
四、AP/MAP/PR曲线
①首先介绍一下Recall(召回率/查全率)和Precision(精度/查准率):
以一张图片物体检测为例,检测算法框出N=1000个框,正确检测出物体A的框有k=50个,实际上图片中有M=100个物体A:
-
Recall = k / M
-
Precision = k / N
Recall和Precision之间是有关系的,如果大幅度增加检测框,比如增加100万个框,此时k↑,M→,N↑↑,那么召回率↑、精度↓
于是引入AP,来衡量测试集中某一个类的分类误差,并体现召回率和精度。
②那么接下来,怎么计算AP?
AP = SPR =PR AP #概念针对单个类
mAP = 平均AP针对所有类
总结
首先,需要区分四个概念:TP(True Positive,真阳性),TN(True Negative,真阴性),FP(False Positive,假阳性)以及FN(False Negetive,假阴性)。
举例:有10个人来检测糖尿病,其中1,3,5号有糖尿病,剩下的没有,即1,3,5号为正样本,2,4,6,7,8,9,10为负样本。
我们的糖尿病系统检测结果是,1,3,6号有糖尿病,剩下的没有。
TP:在这10个人中,1号和3号被检测为正样本,同时检测正确,因此TP就等于2;
TN:2,4,7,8,9,10号被检测为负样本,同时检测也是正确的,因此TN就是6
FP:6号病人,虽然被检测为正样本,但是检测结果是错的,因此FP是1 FN:5号病人,
虽然被检测为负样本,但是检测结果也是错的,FN就是1.
- 准确率(Accuracy)
准确率计算了预测正确的样本数,占总样本数的比例:
Accuracy = n_correct / n_total = (TP + TN) / (TP + TN + FP + FN)
局限性:
当两类样本数量很不均衡时,accuracy就不能很好的反映模型的性能了。比如,总样本中,负样本占95%,那么即使模型将所有样本都预测成负样本,accuracy还是可以高达95%。但是显然,这个模型是不具备正确区分两类样本的能力的。
- 精度(Precision)和召回(Recall)
考虑模型返回的前N个正样本,
精度计算了这N个返回的正样本中,预测正确的比例: Precision = TP / N = TP / (TP + FP) .
召回计算了这N个返回的正样本中预测正确的样本数,占真正总的正样本数的比例: Recall = TP / (TP + FN)
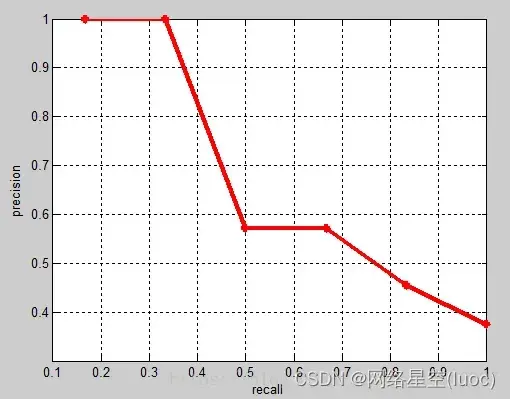
通常,为了使精度变高,模型会趋于保守,只有非常肯定某个样本是正样本时,才将其作为正样本输出,但是这样会使得很多相对不肯定的正样本被错误判断为负样本,从而降低召回。因此,精度和召回不能只考虑单一的一方面,这也就有了P-R曲线:
P-R曲线
综合考虑了精度与召回,其横轴是召回,纵轴是精度。通过调节阈值,大于该阈值的为正样本,小于该阈值的为负样本,使得召回可以从0,0.1,0.2一直取到1,计算出每个召回对应的精度,就可以画出一条曲线,称为P-R曲线。下图的b和c就是两个P-R曲线,可以看到,随着recall不断增加,precision是在下降的。
F1值是另一个综合考虑精度和召回的指标,其计算公式为: F1 = 2PR/(P+R),也就是精度和召回的调和平均值。
-
ROC曲线
ROC曲线全称Receiver Operating Characteristic Curve(受试者工作特征曲线)。其横坐标为FPR(False Positive Rate,假阳性率),纵坐标为TPR(True Positive Rate,真阳性率)。计算方法为:
FPR = FP / (FP + TN) = FP / Neg,
TPR = TP / (TP + FN) = TP / Pos = Recall.
绘制ROC曲线的方法与P-R曲线类似,通过调节阈值,绘制出不同的FPR及其对应的TPR。
AUC指的是ROC曲线下的面积大小,通过对ROC曲线进行积分,就可以计算得到AUC。AUC取之在0.5~1之间(如果小于0.5,把正负样本预测对调一下就行了),AUC越大,表明模型把真正的正样本排的越靠前,相应的性能就越好。 -
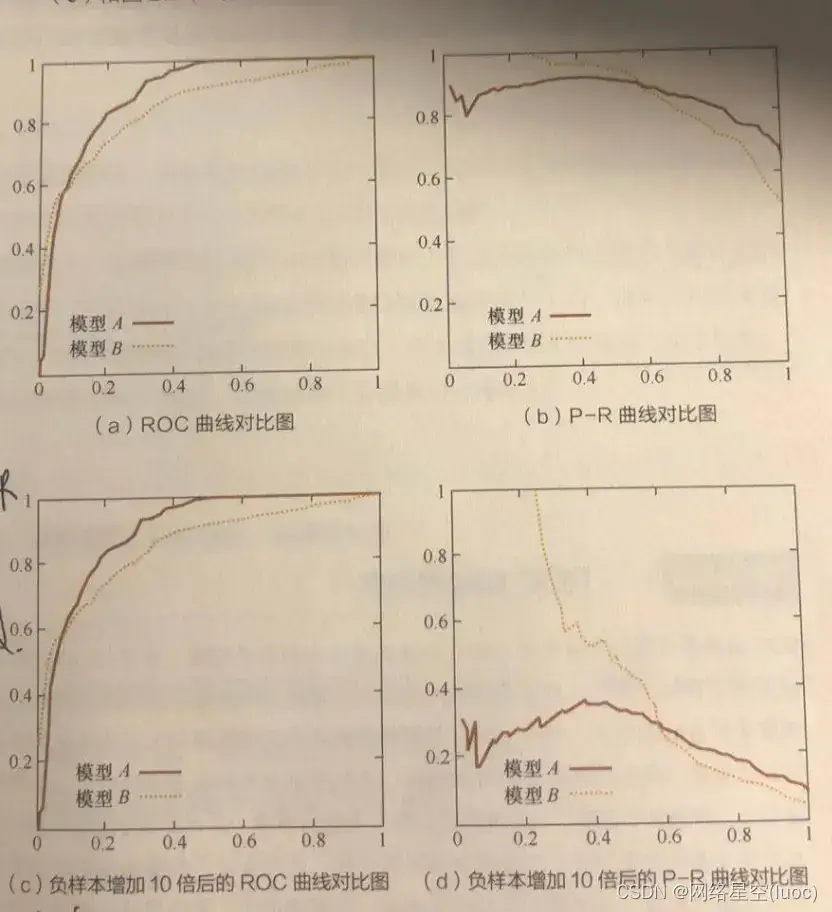
ROC曲线和P-R曲线比较
如下图,ac是ROC曲线,bd是P-R曲线,可以看到,ROC曲线的横纵坐标走势是相同的,而P-R曲线则是反着的。
不管是Precision,还是Recall,其实P-R曲线只考虑了正样本(预测对多少个正样本,以及找出来多少正样本),而ROC曲线即考虑了正样本(TPR,找出来多少正样本),也考虑到了负样本(找错了多少负样本)。当正负样本比例发生变化时,P-R曲线的形状会发生较大的变化,而ROC曲线则比较稳定。
因此,ROC曲线能够更加稳定的反映模型本身的好坏,适用于更多的场景。但是,当希望观测到特定数据集上的表现时,P-R曲线则可以更直观的反映其性能。
- COCO中的mAP
这个问题困扰我好久了,今天终于搞得差不多了。检测(或者实例分割)中的mAP,也就是mean Average Precision,其实跟二分类的AP很像。不同之处在于,检测结果不仅要给出bounding box,还要给出类别;第二,bounding box跟ground truth的框不可能完全重合,需要定义怎样算预测对了,怎样算预测错了。
AP, AP@X
我们用预测的框和gt的IoU(交并比)来衡量预测的正确性,设置一个阈值(比如0.5),如果IoU大于0.5,则认为这个框预测对了,作为正样本输出(True);否则,就是负样本(False)。
假设某一类一共有5个ground truth
object,我们预测出了10个框,将这些框按照置信度(检测网络一般每个框会输出一个置信度)排序,结果如下:
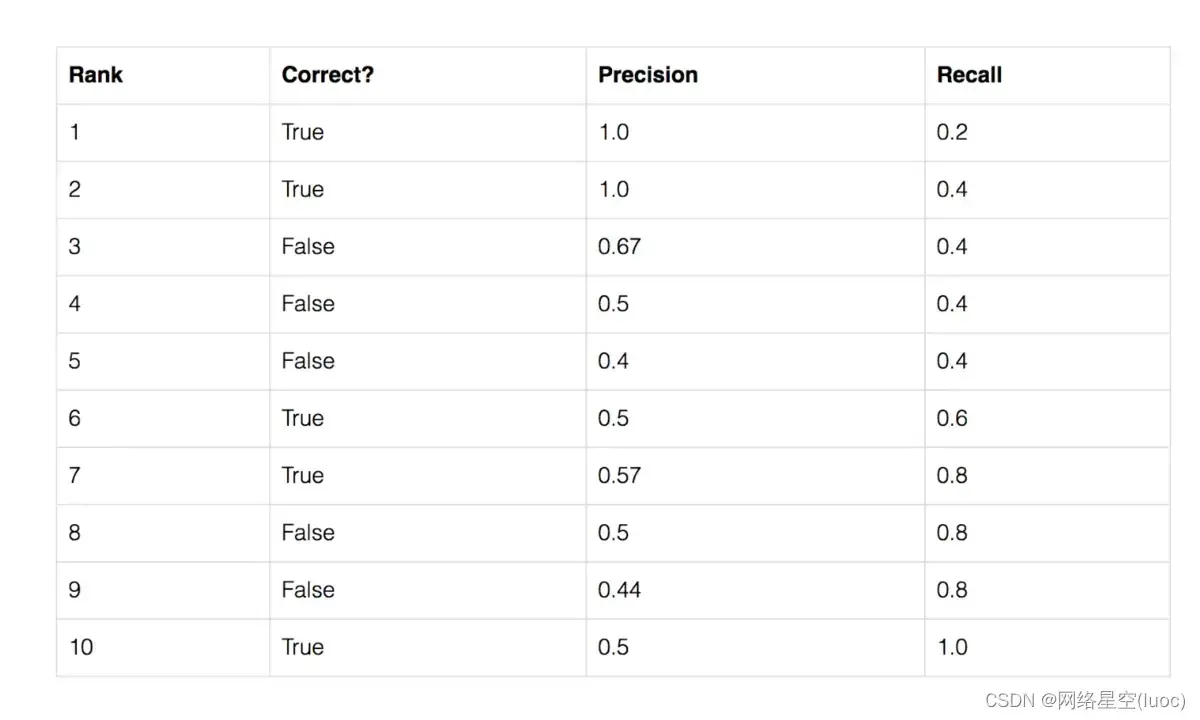
第一个框,预测正确,此时precision就是1,recall是1/5=0.2.
到第三个框,预测错误,此时precision是2/3=0.67,recall是2/5=0.4, 。。。
这样,我们可以得到一系列recall对应的precision,画出它的P-R曲线。这里又一个对precision进行修正的过程,也就是下图的绿色折线。将每个Recall
r对应的precision,修正为recall大于等于r时,能达到的最大的precision。
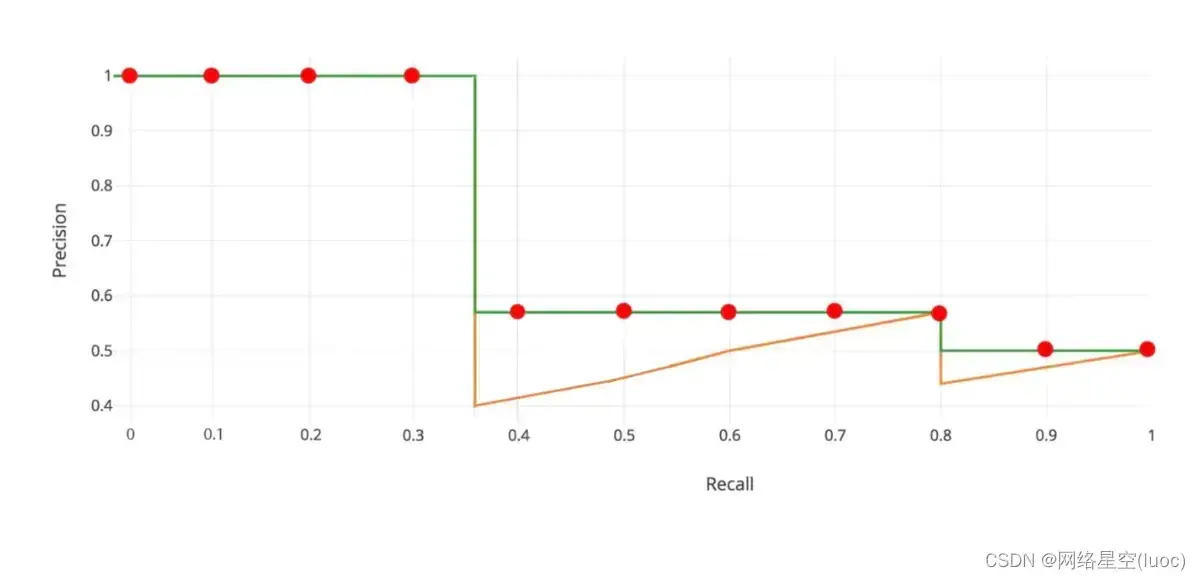
从recall=0,到recall=1,将这11个precision加起来求平均,就是这一类的average precision。
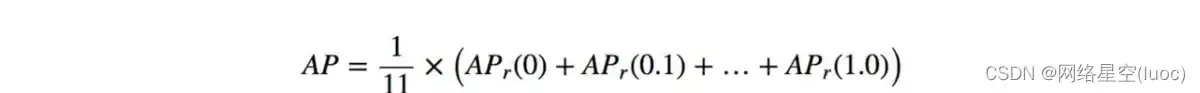
所有类的AP平均,得到的就是IoU阈值为0.5的AP,即AP@50。有的地方也把这个值称为mAP,需要看具体语境。
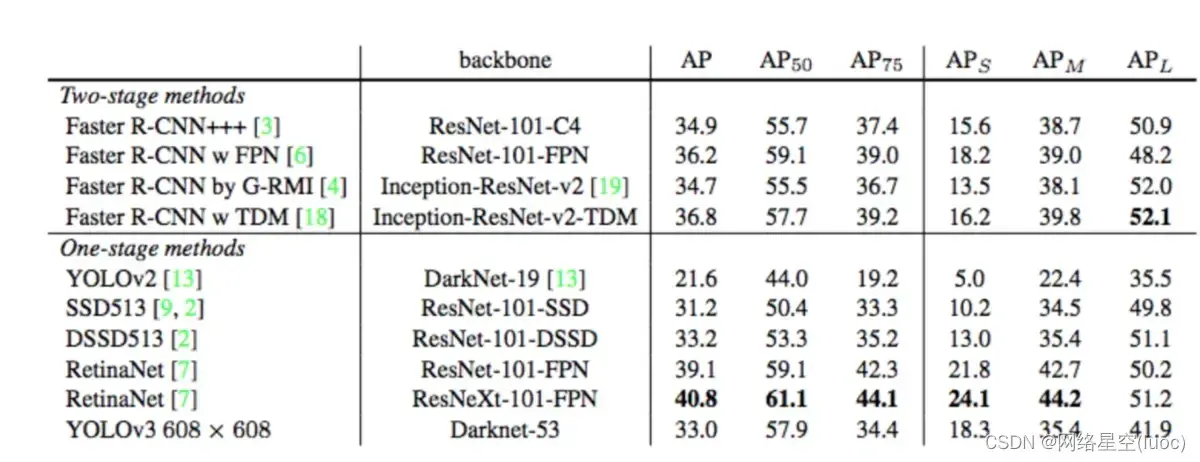
mAP 上面我们得到的是某一个IoU作为阈值的AP,也就是AP@X。以0.5作为起点,0.05步长,0.95终点,我们可以得到0.5,
0.55, 0.6, 。。。, 0.95一共10个值,将这10个值分别作为IoU阈值,就能得到AP@50, AP@55, 。。。,AP@95. mAP = (AP@50+AP@55+…+AP@95)/10 这个结果,对应的就是下表里的AP。 YOLOv3
文章出处登录后可见!