前面的博客讲了如何基于PyTorch使用神经网络识别手写数字
使用PyTorch构建神经网络
下面在此基础上构建一个生成对抗网络,生成对抗网络可以模拟出新的手写数字数据集。
1 生成对抗网络基本概念
生成对抗网络(GAN)是一种用于生成新的照片,文本或音频的模型。它由两部分组成:生成器和判别器。生成器的作用是生成新的样本,而判别器的作用是识别这些样本是真实的还是假的。两个模型相互博弈,通过不断调整自己的参数来提高自己的能力。生成器希望判别器错误地认为其生成的样本是真实的,而判别器希望能正确地识别生成器生成的样本是假的。最终,生成器会学到如何生成逼真的样本,而判别器会学到如何区分真假样本。
一个非常形象的例子,目前的数据集是人民币,生成器是造假币的,判别器是银行。刚开始造假币的只是粗略模仿人民币的印制,银行由于没有经验也分辨不好真钱还是假币。但随着时间推移,银行对鉴别假币越来越有经验,造假币的水平也变得越来越逼真,二者不断进步,这就是GAN网络。
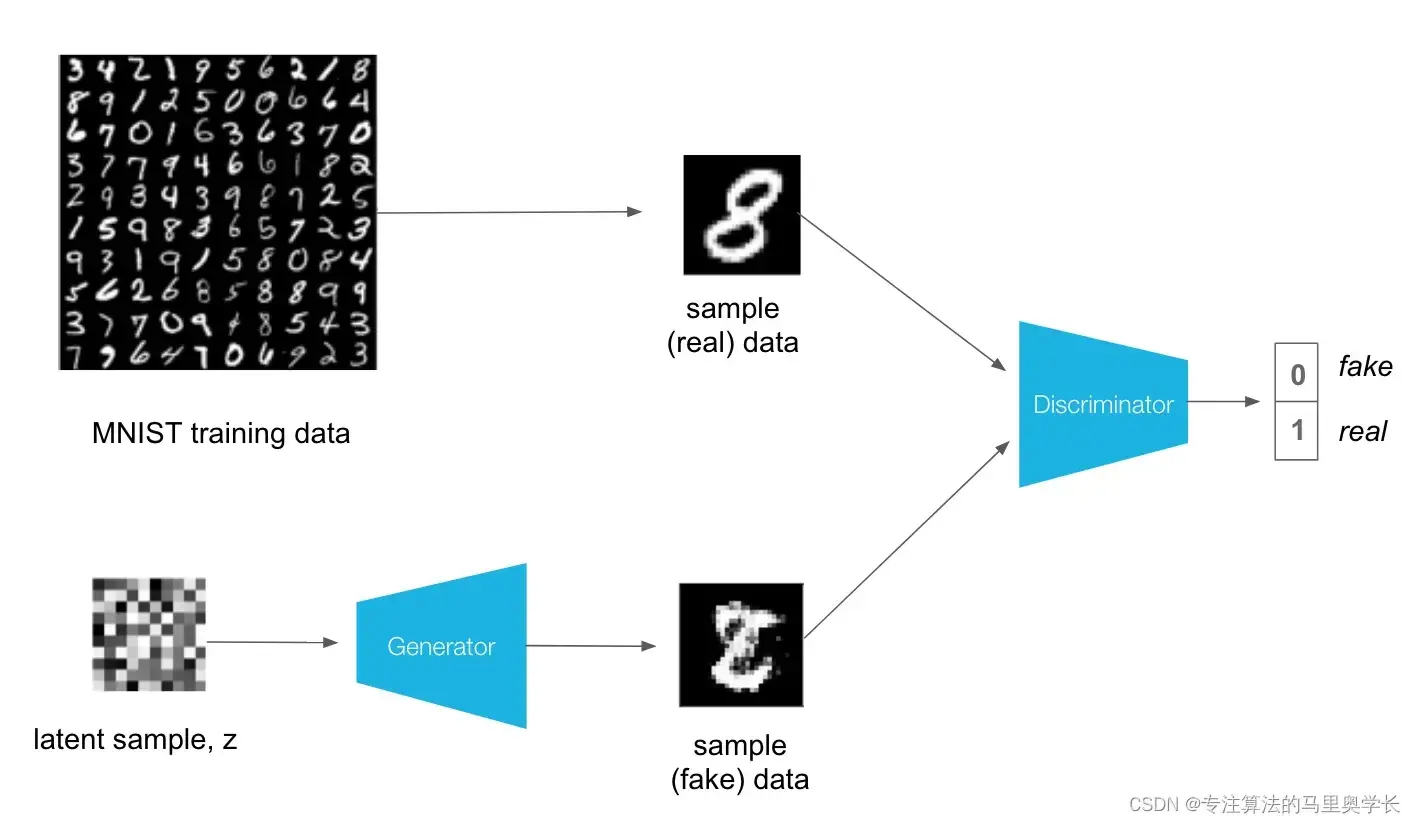
2 生成对抗网络建模
2.1 建立MnistDataset类
对于非GAN独有的建模部分,讲解不会细化到每一行代码,如有阅读困难可参考本博客使用PyTorch构建神经网络部分的文章。但基本上具备Python的基础知识即可顺利阅读本篇文章。
与神经网络建模相同,我们首先构建一个MnistDataset类,这个类具备getitem功能,可以返回每条数据相应的数据标签label,image_values, target。这些变量的含义分别是:
- label:获得了指定数据的第一个数值,也就是这个数据的标签;
- target:制作了一个维度为10的张量,标签对应的项是1,其他是0。比如,某个手写数据的标签是2,则这个张量是[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]。
- image_values:像素输入的值是0-255,这里对像素数据做了标准化,是值位于0-1之间。
同样,我们定义了一个绘制的功能,这个功能在建模中并没有实际作用,但是会很方便我们快速查看数据是否成功导入。MnistDataset类的全部代码如下:
class MnistDataset:
def __init__(self, csv_file):
self.data = pandas.read_csv(csv_file)
pass
def __len__(self):
return len(self.data)
def __getitem__(self, index):
# 预期输出的张量制作
label = self.data.iloc[index, 0]
target = torch.zeros(10)
target[label] = 1.0
# 图像数据标准化
image_values = torch.FloatTensor(self.data.iloc[index, 1:].values) / 255.0
return label, image_values, target
# 制图
def plot_image(self, index):
arr = self.data.iloc[index, 1:].values.reshape(28, 28)
plt.title("label=" + str(self.data.iloc[index, 0]))
plt.imshow(arr, interpolation='none', cmap='Blues')
plt.show()
2.2 建立鉴别器
此处的鉴别器与基于PyTorch建立神经网络一文中的鉴别器基本相同。主要不同的是网络的输出层:本鉴别器的的网格为784-200-1。网格的输出层只有一个节点,这是因为鉴别器只需要判断这是真实数据还是虚假数据即可。真实数据为1,虚假数据为0。
鉴别器的主要函数包括:
# 鉴别器类
class Discriminator(nn.Module):
def __init__(self):
# 初始化父类
super().__init__()
# 定义神经网络
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200, 1),
nn.Sigmoid()
)
# 创造损失函数
self.loss_function = nn.MSELoss()
# 创造优化器
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# 创造进程计数器
self.counter = 0
self.progress = []
对类的初始化中:继承父类nn.Module的初始化属性;并建立784-200-1的神经网络,神经网络的激活函数使用最经典的Sigmoid函数;建立损失函数与优化器,损失函数选择MSE方法(均方误差)。
def forward(self, inputs):
# 执行模型
return self.model(inputs)
简单的执行功能,能够基于input输出预测结果,即0或1。
def train(self, inputs, targets):
# 计算输出
outputs = self.forward(inputs)
# 计算损失
loss = self.loss_function(outputs, targets)
# 赋值进程计数器
self.counter += 1
if self.counter % 10 == 0:
self.progress.append(loss.item())
if self.counter % 10000 == 0:
print("counter = ", self.counter)
# 计算损失梯度,优化权重
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
训练模块,可以实现基于模型实际输出与与其输出,不断更新网络的权重。并每隔10次训练计算此时模型的损失,每隔10000次训练打印一次训练次数,方便掌握训练进度。
# 绘制损失与训练过程的关系
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16, 8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
对前面每10条保存一次的模型损失函数结果进行绘图。
2.3 测试鉴别器
此处我们还没有编写生成器,但是可以创建一个随机数据集,看看鉴别器是否可以分辨出真实的mnist数据和随机数据。
首先建立一个用于生成随机数据的生成器,size是生成数据的特征数。
def generate_random(size):
random_data = torch.rand(size)
return random_data
接下来我们用真是数据与随机数据训练模型
for label, image_data_tensor, target_tensor in mnist_dataset:
# 真实数据
D.train(image_data_tensor, torch.FloatTensor([1.0]))
# 随机数据
D.train(generate_random(784), torch.FloatTensor([0.0]))
其中真是数据我们希望输出节点的数据输出是1,而随机数据我们希望的输出是0。
在训练完成后,可以使用我们在鉴别器类中定义的绘图功能,查看模型损失的变化情况。同时,也可以再传入4组随机真假数据,来更清晰的查看此时模型的训练情况。
for i in range(4):
image_data_tensor = mnist_dataset[random.randint(0,60000)][1]
print( D.forward( image_data_tensor ).item() )
pass
for i in range(4):
print( D.forward( generate_random(784) ).item() )
pass
基于这个运行结果也可以判断出,模型是可以有效的区分真实数据与随机数据的。
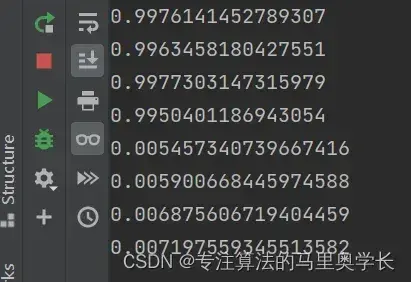
2.4 Mnist生成器制作
生成器与判别器都是神经网络模型,所以代码基本相同,这里主要讲一下不同的地方。与判别器相比,Mnist生成器应该与判别器的网格结构刚好相反。因为判别器是输入图像输出判别结果,而生成器应该是输入判别结果,输出图像。所以网络的结构可以是1-200-784。事实上,此处我们只要保证输出的格式是784个数据即可,为了让输出的数据更加多元,我们也可以增加输入层的节点数量。这里节点数量使用1,10,甚至是100都是可以的。此处我们以100个输入节点为例。
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(100, 200),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200, 784),
nn.Sigmoid()
)
除此之外,生成器的训练过程也稍有不同。在使用生成器生成数据后,我们需要将这个数据传入判别器,并使用判别器返回的损失作为这个生成器的损失。在Python中,在一个类调用类一个类的功能是完全可以的因此这一步骤变得简单了很多。
class Generator(nn.Module):
def train(self, D, inputs, targets):
# 生成器生成数据
g_output = self.forward(inputs)
# 将生成的数据传入判别器
d_output = D.forward(g_output)
loss = D.loss_function(d_output, targets)
if self.counter % 10 == 0:
self.progress.append(loss.item())
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
除了以上两项,这个生成器都与鉴别器完全相同,大家按此更改或者直接在文末下载完整版代码均可。
在训练GAN之前,可以检查一下生成器的输出是否正确。方法还是让生成器生成一个数据,然后使用plt包绘制出来
G = Generator()
output = G.forward(generate_random(100))
img = output.detach().numpy().reshape(28,28)
plt.imshow(img, interpolation='none', cmap='Blues')
plt.show()
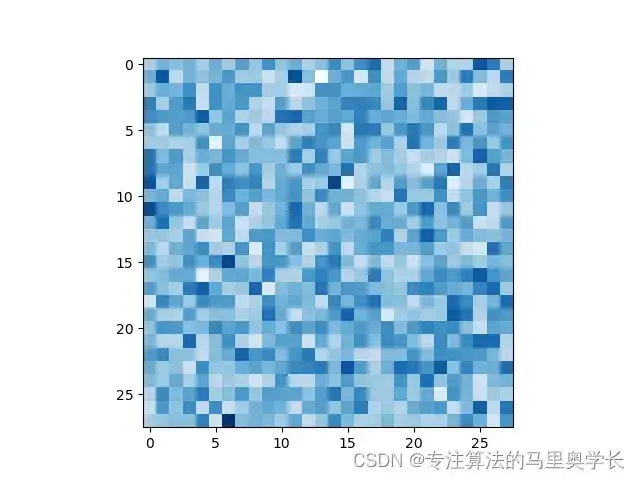
现在,我们的模型中就具备了生成对抗网络的三要素:真实数据、生成器与对抗器。
3 模型的训练
对于生成器,其输入是由我们使用随机数据生成器来产生的。之前我们使用torch.rand进行随机数据的生成,这次可以尝试使用torch.randn。两者的区别是:randn是从标准正态分布中返回一个或多个样本值。
# 生成器使用的随即输入
def generate_random_seed(size):
random_data = torch.randn(size)
return random_data
同2.3的过程一样,在训练过程中,我们将真是数据与生成器产出的数据交替传入鉴别器,只是此处增加了对生成器的训练。
for label, image_data_tensor, target_tensor in mnist_dataset:
# 使用真实数据训练判别器
D.train(image_data_tensor, torch.FloatTensor([1.0]))
# 使用生成器数据训练判别器
# 使用 detach() 截断梯度计算
D.train(G.forward(generate_random_seed(100)).detach(), torch.FloatTensor([0.0]))
# 训练生成器
G.train(D, generate_random_seed(100), torch.FloatTensor([1.0]))
值得注意的是,在这里使用生成器数据训练判别器时,我们使用detach进行了截断。这个作用是在计算梯度时,对下图红叉所示地方进行切断,使梯度计算到这里就截止了,也就是此次计算只对生成器有效。这一操作的功能是降低模型的计算量。
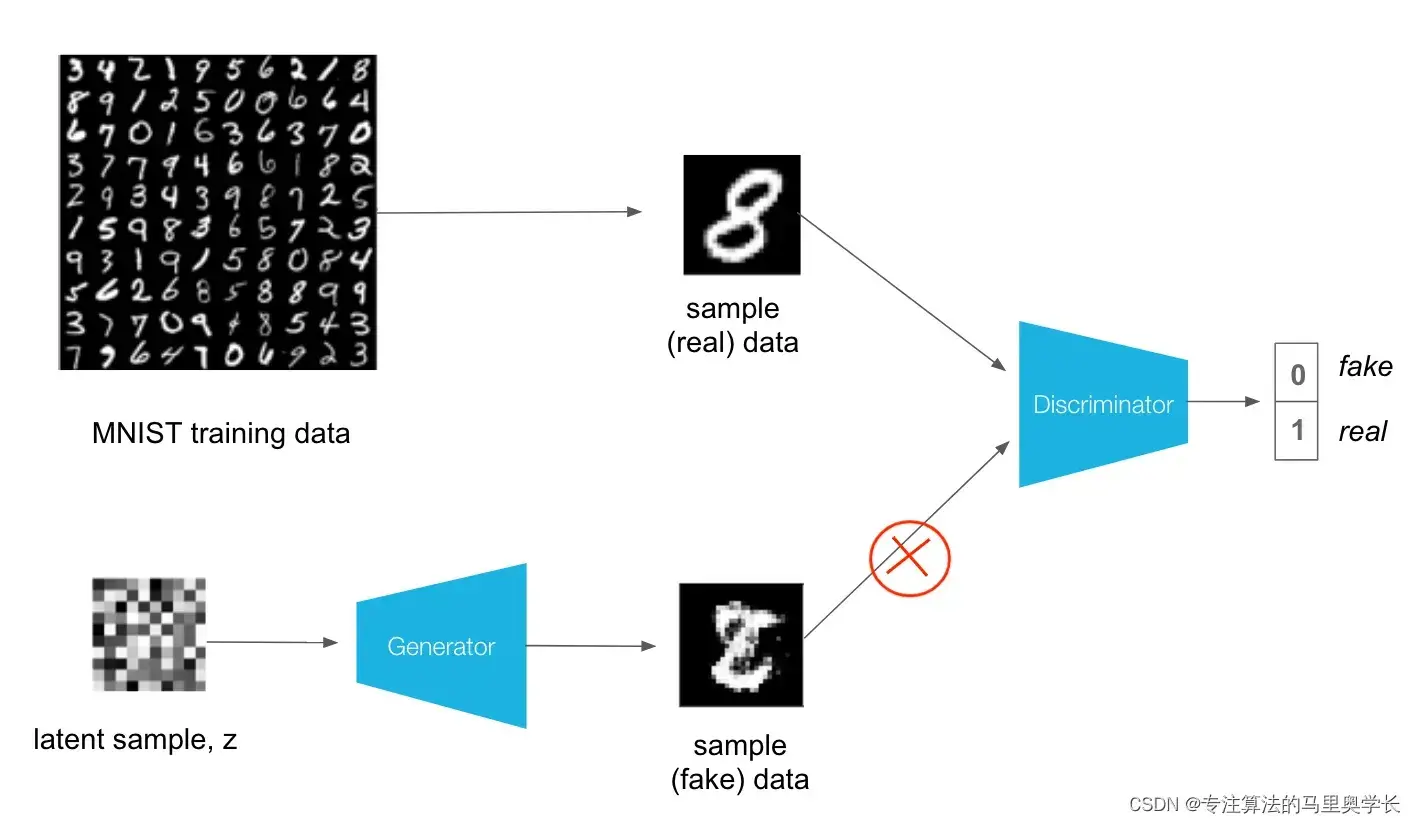
同样此处也可以引入time模块对训练进行计时。
4 模型表现的判断
前面在定义类时,我们已经内置好了绘制损失随训练变化的功能,这里直接调用即可。
D.plot_progress()
G.plot_progress()
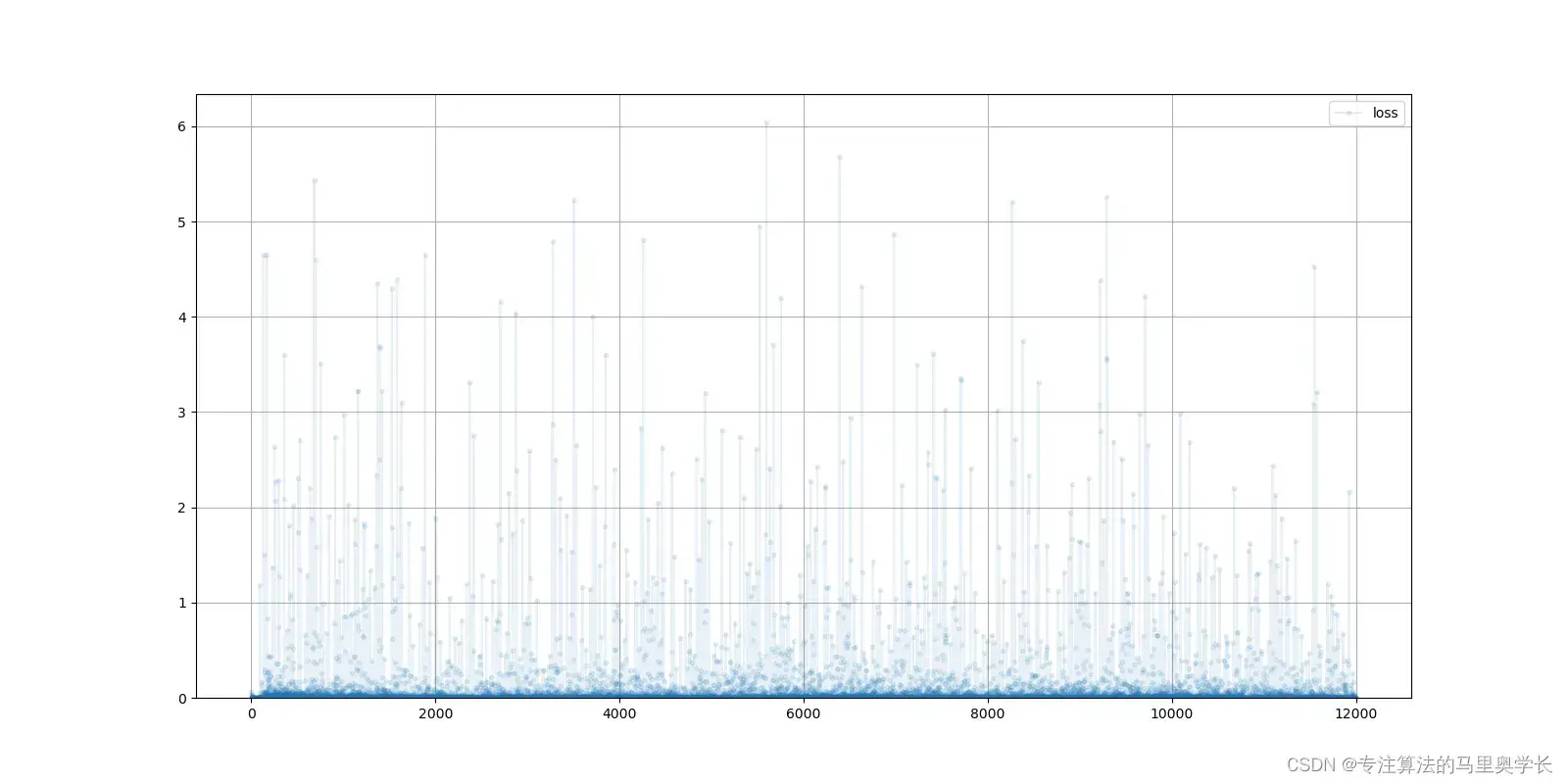
鉴别器的损失基本看不到明显的变化,这是因为尽管鉴别器的能力不断提升,生成器的能力却也在不断提升。
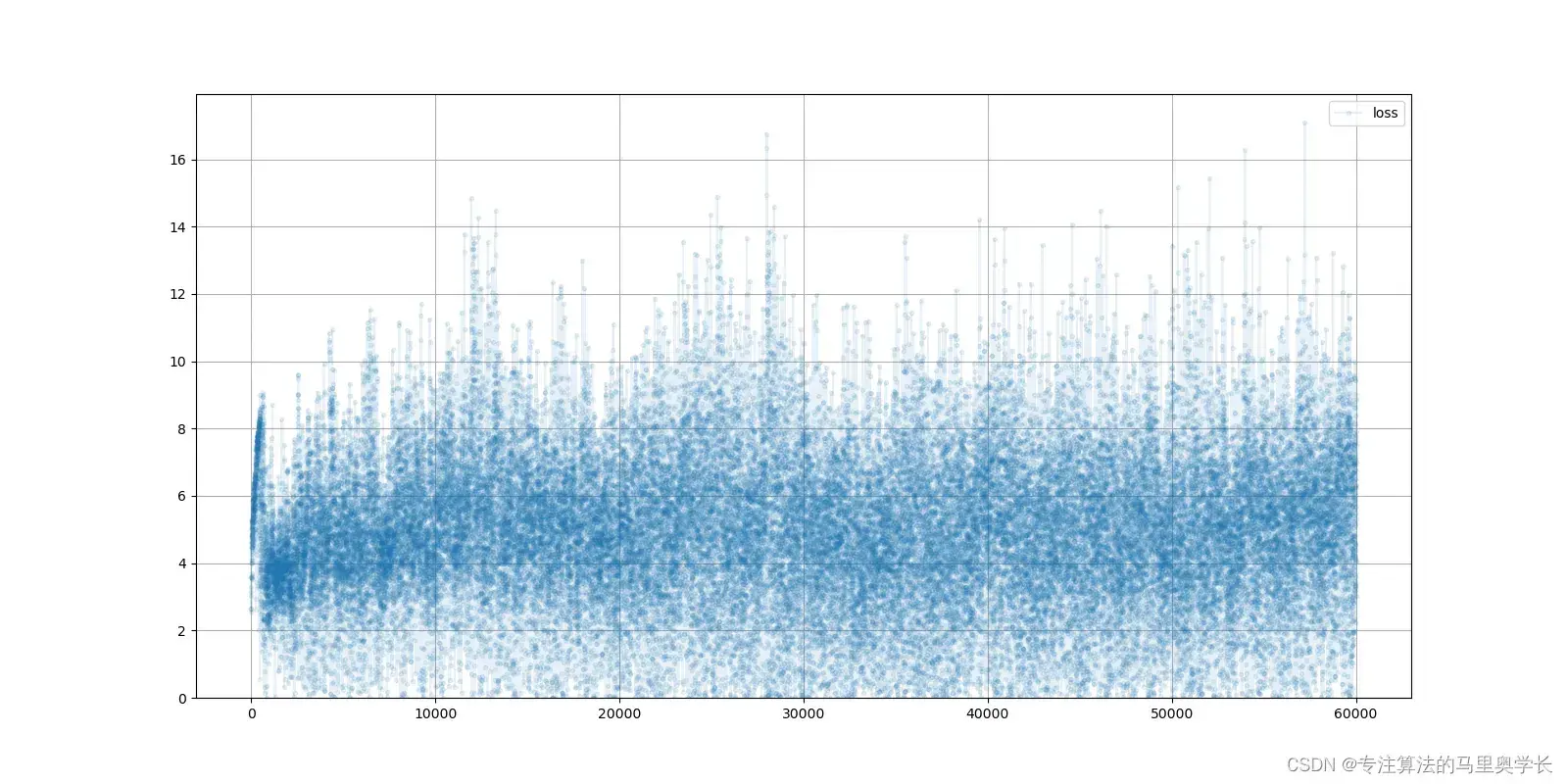
生成器稍有不同,在前期出现了下降的趋势,在一定程度上骗过了鉴别器,但后期随着鉴别器能力的提升,生成器的随时也趋于稳定。
我们也可以依据生成器输出的图像,来更直观的判断生成器的表现。
f, axarr = plt.subplots(2,3, figsize=(16,8))
for i in range(2):
for j in range(3):
output = G.forward(generate_random_seed(100))
img = output.detach().numpy().reshape(28,28)
axarr[i,j].imshow(img, interpolation='none', cmap='Blues')
plt.show()
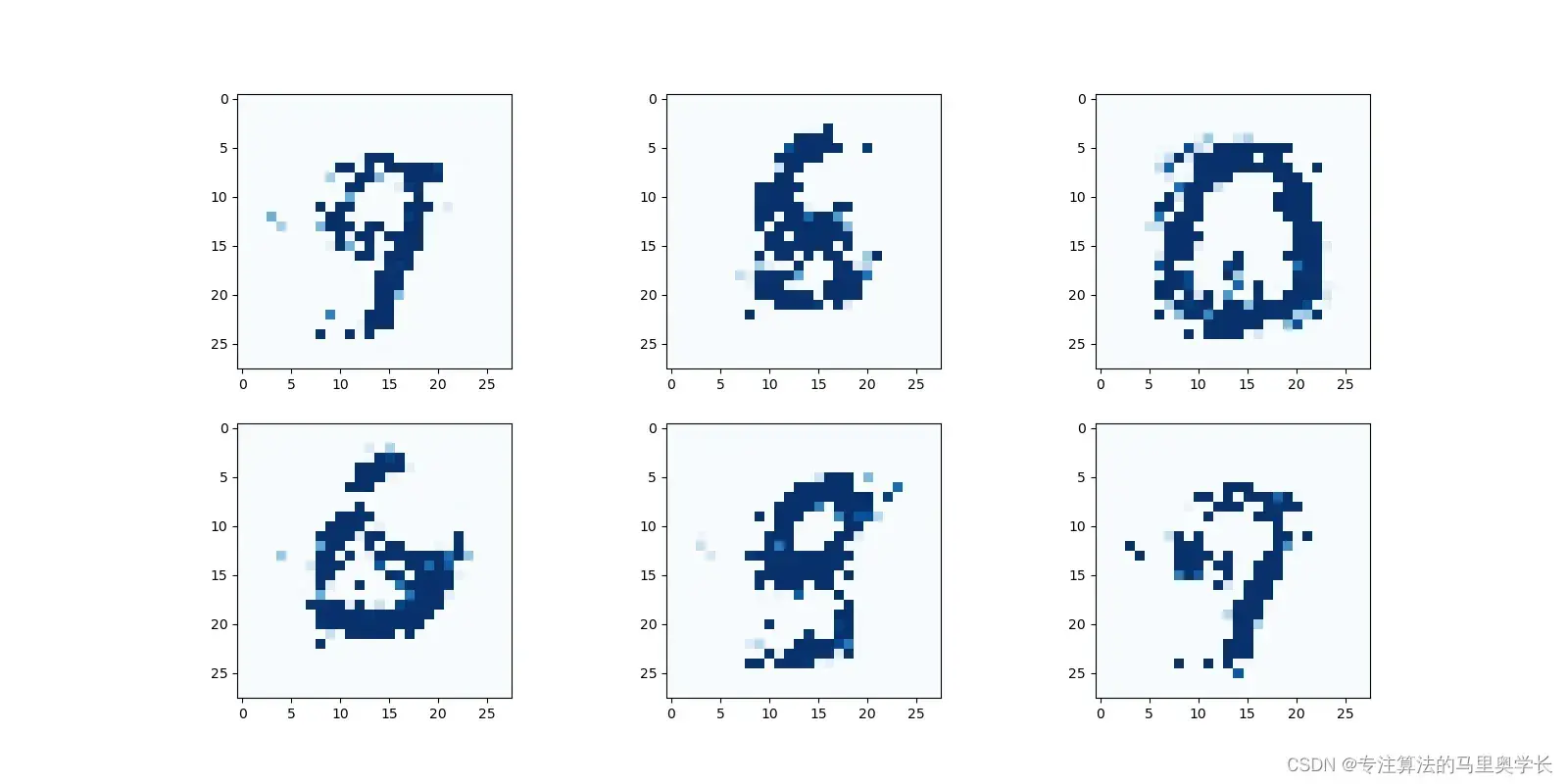
我们使用plt建立了一个2行3列的画布,并向生成器传入了随机参数,可以看到生成器的输出已经和手写图像很像了。
文章出处登录后可见!