目录
1 概述
一元线性回归模型研究的是一个因变量与一个自变量之间呈直线趋势的数量关系。在实际问题中,常会遇到一个自变量与多个因变量数量关系的问题,这就需要我们建立多元线性回归模型。
我用一个公式来描述:
①其中,x1 , x2 , . . . , x n 分别表示 1号自变量、2号自变量、…、n号自变量。
②f ( x1 , x2 , . . . , xn ) 表示受这些自变量共同影响而 线性合成 的因变量。
③α1 、 α2 、 . . . 、 αn 分别表示待拟合的系数。
④β表示待拟合的常数。
现实问题中,我们往往会碰到多个变量间的线性关系的问题,这时就要用到多元线性回归,多元线性回归是一元回归的一种推广,其在实际应用中非常广泛,本文就用python代码和Matlab代码来展示一下如何用多元线性回归来解决实际问题。
2 算例1
2.1 算例
本算例来源于2022宁夏杯大学生就业分析。
大学生就业问题一直是社会关注的焦点。据此前教育部新闻发布会通报,2022届高校毕业生规模达1076万人,首次突破1000万人,规模和增量均创下了历史新高。同时受市场环境和疫情等因素的影响,就业压力较大。大学生就业呈现出哪些特征和趋势呢?在众多就业的学生中,是什么样的因素决定了部分学生在众多的竞争中获得了薪水不同的工作?这些因素可能包括大学的成绩、本身的技能、大学与工业中心的接近程度、拥有的专业化程度、特定行业的市场条件等。据悉,印度共有6214所工程和技术院校,其中约有290万名学生。每年平均有150万学生获得工程学学位,但由于缺乏从事技术工作所需的技能,只有不到20%的学﹐生﹐在其核﹑心领域找 到工﹑作。附﹐件(https: / /www.datafountain.cn/datasets/4955)给出了印度工程类专业毕业生就业的工资水平和各因素情况表。根据附件数据结合其他资料研究:
分析影响高校工程类专业毕业生薪资的主要因素。
2.2 Python代码实现
from sklearn import linear_model
import pandas as pd
# 可以根据相关性删除一些特征
shuju=pd.read_csv('数据.csv')
x =shuju[["10percentage","12percentage","CollegeTier","MechanicalEngg","ElectricalEngg","TelecomEngg","CivilEngg","collegeGPA","Logical","GraduationYear"]]
y =shuju["Salary"]
regr = linear_model.LinearRegression() #建立模型
regr.fit(x, y) # 训练
# 获取回归的系数。
print(regr.coef_)
2.3 结果
然后得到薪资和其他自变量的关系:这里展现各自变量求得的系数:

3 算例2
3.1 算例
本算例用算例1的数据,但是我们换一种解法,高级一点的。
3.2 Python代码
# ====导入相关库===========
import numpy as np
import pandas as pd
import statsmodels.api as sm # 实现多元线性回归
# =====接下来是数据预处理===========
file = r'shuju.csv'
data = pd.read_csv(file)
data.columns = ["Salary","10percentage","12percentage","CollegeTier","MechanicalEngg","ElectricalEngg","TelecomEngg","CivilEngg","collegeGPA","Logical","GraduationYear"]
# ====开始生成多元线性模型=====
x = sm.add_constant(data.iloc[:, 1:]) # 生成自变量x1~x9,Python从0开始索引喔,和Matlab不一样,Matlab从1开始索引
y = data["Salary"] # 生成因变量
model = sm.OLS(y, x) # 生成模型
result = model.fit() # 模型拟合
result.summary() # 模型描述
print(result.summary())结果:
OLS Regression Results
==============================================================================
Dep. Variable: Salary R-squared: 0.084
Model: OLS Adj. R-squared: 0.080
Method: Least Squares F-statistic: 27.21
Date: Wed, 21 Sep 2022 Prob (F-statistic): 2.90e-50
Time: 20:17:27 Log-Likelihood: -40896.
No. Observations: 2998 AIC: 8.181e+04
Df Residuals: 2987 BIC: 8.188e+04
Df Model: 10
Covariance Type: nonrobust
==================================================================================
coef std err t P>|t| [0.025 0.975]
----------------------------------------------------------------------------------
const 8.2e+04 2.12e+05 0.387 0.699 -3.34e+05 4.98e+05
10percentage 1341.3623 503.139 2.666 0.008 354.828 2327.897
12percentage 1410.6973 446.494 3.160 0.002 535.231 2286.164
CollegeTier -1.055e+05 1.44e+04 -7.309 0.000 -1.34e+05 -7.72e+04
MechanicalEngg 37.9658 37.902 1.002 0.317 -36.350 112.282
ElectricalEngg -134.0305 43.477 -3.083 0.002 -219.278 -48.783
TelecomEngg -76.8638 36.165 -2.125 0.034 -147.775 -5.952
CivilEngg 199.5630 116.302 1.716 0.086 -28.478 427.604
collegeGPA 1502.1779 494.583 3.037 0.002 532.420 2471.936
Logical 294.6543 45.724 6.444 0.000 205.000 384.309
GraduationYear -17.0930 101.498 -0.168 0.866 -216.107 181.921
==============================================================================
Omnibus: 4088.757 Durbin-Watson: 2.029
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1454349.913
Skew: 7.577 Prob(JB): 0.00
Kurtosis: 109.831 Cond. No. 1.18e+05
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.18e+05. This might indicate that there are
strong multicollinearity or other numerical problems.在这个结果中,我们主要看
“coef”、“t”和“P>|t|”这三列。coef就是前面说过的回归系数,const这个值就是回归常数,所以我们得到的这个回归模型就是:
y = 320.640948 + 1341.3623x1 + 1410.6973x2 + -1.055e+05x3 - 37.9658x4 + -134.0305x5 -76.8638x6 +199.5630x7 -1502.1779x8 + 294.6543x9-17.0930x10。
而“t”和“P>|t|”这两列是等价的,使用时选择其中一个就行,其主要用来判断每个自变量和y的线性显著关系,后面我们会讲到。从图中还可以看出,Prob (F-statistic)为4.21e-20,这个值就是我们常用的P值,其接近于零,说明我们的多元线性方程是显著的,也就是y与x1、x2、...、x9有着显著的线性关系,而R-squared是0.992,也说明这个线性关系比较显著。
理论上,这个多元线性方程已经求出来了,而且效果还不错,我们就可以用其进行预测了,但这里我们还是要进行更深一步的探讨。
前面说过,
y与x1、x2、...、x9有着显著的线性关系,这里要注意x1到x9这9个变量被看作是一个整体,y与这个整体有显著的线性关系,但不代表y与其中的每个自变量都有显著的线性关系,我们在这里要找出那些与y的线性关系不显著的自变量,然后把它们剔除,只留下关系显著的,这就是前面说过的t检验。
t检验的原理内容有些复杂,有兴趣的读者可以自行查阅资料,这里不再赘述。我们可以通过图3中“P>|t|”这一列来判断,这一列中我们可以选定一个阈值,比如统计学常用的就是0.05、0.02或0.01,这里我们就用0.05,凡是P>|t|这列中数值大于0.05的自变量,我们都把它剔除掉,这些就是和y线性关系不显著的自变量,所以都舍去,请注意这里指的自变量是x1到x9,不包括图3中const这个值。但是这里有一个原则,就是一次只能剔除一个,剔除的这个往往是P值最大的那个,比如图3中P值最大的是x4,那么就把它剔除掉,然后再用剩下的x1、x2、x3、x5、x6、x7、x8、x9来重复上述建模过程,再找出P值最大的那个自变量,把它剔除,如此重复这个过程,直到所有P值都小于等于0.05,剩下的这些自变量就是我们需要的自变量,这些自变量和y的线性关系都比较显著,我们要用这些自变量来进行建模。
下面是Python代码:
# ====导入相关库===========
import numpy as np
import pandas as pd
import statsmodels.api as sm # 实现多元线性回归
# =====接下来是数据预处理===========
file = r'shuju.csv'
data = pd.read_csv(file)
data.columns = ["Salary","10percentage","12percentage","CollegeTier","MechanicalEngg","ElectricalEngg","TelecomEngg","CivilEngg","collegeGPA","Logical","GraduationYear"]
# ====开始生成多元线性模型=====
x = sm.add_constant(data.iloc[:, 1:]) # 生成自变量x1~x9,Python从0开始索引喔,和Matlab不一样,Matlab从1开始索引
y = data["Salary"] # 生成因变量
model = sm.OLS(y, x) # 生成模型
result = model.fit() # 模型拟合
result.summary() # 模型描述
print(result.summary())
'''
y与x1、x2、...、x9有着显著的线性关系,这里要注意x1到x9这9个变量被看作是一个整体,
y与这个整体有显著的线性关系,但不代表y与其中的每个自变量都有显著的线性关系,
我们在这里要找出那些与y的线性关系不显著的自变量,然后把它们剔除,下面这个函数就是这个作用。
'''
# =====找出y与哪几个自变量有显著的关系=============
def looper(limit): # limit一般取0.05
cols = ["10percentage","12percentage","CollegeTier","MechanicalEngg","ElectricalEngg","TelecomEngg","CivilEngg","collegeGPA","Logical","GraduationYear"]
for i in range(len(cols)):
data1 = data[cols]
x = sm.add_constant(data1) # 生成自变量
y = data['Salary'] # 生成因变量
model = sm.OLS(y, x) # 生成模型
result = model.fit() # 模型拟合
pvalues = result.pvalues # 得到结果中所有P值
pvalues.drop('const', inplace=True) # 删除const这一列
pmax = max(pvalues) # 选出最大的P值
if pmax > limit:
ind = pvalues.idxmax() # 找出最大P值的index
cols.remove(ind) # 把这个index从cols中删除
else:
return result
result = looper(0.05)
result.summary()
print(result.summary())
3.3 结果
Covariance Type: nonrobust
==================================================================================
coef std err t P>|t| [0.025 0.975]
----------------------------------------------------------------------------------
const 5.174e+04 5.31e+04 0.975 0.330 -5.23e+04 1.56e+05
10percentage 1400.6369 502.351 2.788 0.005 415.648 2385.626
12percentage 1419.5952 446.442 3.180 0.001 544.230 2294.960
CollegeTier -1.06e+05 1.44e+04 -7.347 0.000 -1.34e+05 -7.77e+04
ElectricalEngg -137.5982 43.436 -3.168 0.002 -222.766 -52.431
TelecomEngg -81.7501 36.052 -2.268 0.023 -152.440 -11.061
collegeGPA 1433.1099 493.383 2.905 0.004 465.706 2400.514
Logical 290.7453 45.668 6.366 0.000 201.201 380.289
==============================================================================
Omnibus: 4083.414 Durbin-Watson: 2.028
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1441070.840
Skew: 7.561 Prob(JB): 0.00
Kurtosis: 109.337 Cond. No. 7.62e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 7.62e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
Process finished with exit code 0那么问题来了,前面我们得到的包含所有自变量的多元线性模型和这个剔除部分变量的模型,我们要选择哪一个,毕竟第一个模型的整体线性效果也挺显著,依据笔者的经验,这个还是要看具体的项目要求。因为我们实际项目中遇到的问题都是现实生活中真实存在的例子,不再是单纯的数学题了,这两个肯定对y是有一定影响的,如果盲目剔除,可能会对最终的结果产生不良影响,所以我们还是要根据实际需求来做决定。
4 算例3
4.1 算例
这里我们用到的数据来源于2013年《中国统计年鉴》,数据以居民的消费性支出为因变量y,其他9个变量为自变量,其中x1是居民的食品花费,x2是衣着花费,x3是居住花费,x4是医疗保健花费,x5是文教娱乐花费,x6是职工平均工资,x7是地区的人均GDP,x8是地区的消费价格指数,x9是地区的失业率。在这所有变量里面,x1至x7以及y的单位是元,x9是百分数,x8没有单位,因为其是消费价格指数。数据的总体大小为31×10,即31行、10列,大体内容下表所示。
4.2 Python代码
#====导入相关库===========
import numpy as np
import pandas as pd
import statsmodels.api as sm #实现多元线性回归
#=====接下来是数据预处理===========
file = r'data.xlsx'
data = pd.read_excel(file)
data.columns = ['y', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9']
#====开始生成多元线性模型=====
x = sm.add_constant(data.iloc[:,1:]) #生成自变量x1~x9
y = data['y'] #生成因变量
model = sm.OLS(y, x) #生成模型
result = model.fit() #模型拟合
result.summary() #模型描述
print(result.summary())结果:
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 320.6409 3951.557 0.081 0.936 -7897.071 8538.353
x1 1.3166 0.106 12.400 0.000 1.096 1.537
x2 1.6499 0.301 5.484 0.000 1.024 2.275
x3 2.1787 0.520 4.190 0.000 1.097 3.260
x4 -0.0056 0.477 -0.012 0.991 -0.997 0.985
x5 1.6843 0.214 7.864 0.000 1.239 2.130
x6 0.0103 0.013 0.769 0.451 -0.018 0.038
x7 0.0037 0.011 0.342 0.736 -0.019 0.026
x8 -19.1306 31.970 -0.598 0.556 -85.617 47.355
x9 50.5156 150.212 0.336 0.740 -261.868 362.899
==============================================================================
Omnibus: 4.552 Durbin-Watson: 2.334
Prob(Omnibus): 0.103 Jarque-Bera (JB): 3.059
Skew: -0.717 Prob(JB): 0.217
Kurtosis: 3.559 Cond. No. 3.76e+06
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.76e+06. This might indicate that there are
strong multicollinearity or other numerical problems.
OLS Regression Results 在这个结果中,我们主要看
“coef”、“t”和“P>|t|”这三列。coef就是前面说过的回归系数,const这个值就是回归常数,所以我们得到的这个回归模型就是:
y = 320.640948 + 1.316588 x1 + 1.649859 x2 + 2.17866 x3 - 0.005609 x4 + 1.684283 x5 + 0.01032 x6 + 0.003655 x7 -19.130576 x8 + 50.515575 x9。
而“t”和“P>|t|”这两列是等价的,使用时选择其中一个就行,其主要用来判断每个自变量和y的线性显著关系,后面我们会讲到。从图中还可以看出,Prob (F-statistic)为4.21e-20,这个值就是我们常用的P值,其接近于零,说明我们的多元线性方程是显著的,也就是y与x1、x2、...、x9有着显著的线性关系,而R-squared是0.992,也说明这个线性关系比较显著。
理论上,这个多元线性方程已经求出来了,而且效果还不错,我们就可以用其进行预测了,但这里我们还是要进行更深一步的探讨。
前面说过,
y与x1、x2、...、x9有着显著的线性关系,这里要注意x1到x9这9个变量被看作是一个整体,y与这个整体有显著的线性关系,但不代表y与其中的每个自变量都有显著的线性关系,我们在这里要找出那些与y的线性关系不显著的自变量,然后把它们剔除,只留下关系显著的,这就是前面说过的t检验。
t检验的原理内容有些复杂,有兴趣的读者可以自行查阅资料,这里不再赘述。我们可以通过图3中“P>|t|”这一列来判断,这一列中我们可以选定一个阈值,比如统计学常用的就是0.05、0.02或0.01,这里我们就用0.05,凡是P>|t|这列中数值大于0.05的自变量,我们都把它剔除掉,这些就是和y线性关系不显著的自变量,所以都舍去,请注意这里指的自变量是x1到x9,不包括图3中const这个值。但是这里有一个原则,就是一次只能剔除一个,剔除的这个往往是P值最大的那个,比如图3中P值最大的是x4,那么就把它剔除掉,然后再用剩下的x1、x2、x3、x5、x6、x7、x8、x9来重复上述建模过程,再找出P值最大的那个自变量,把它剔除,如此重复这个过程,直到所有P值都小于等于0.05,剩下的这些自变量就是我们需要的自变量,这些自变量和y的线性关系都比较显著,我们要用这些自变量来进行建模。
下面是Python代码:
#====导入相关库===========
import numpy as np
import pandas as pd
import statsmodels.api as sm #实现多元线性回归
#=====接下来是数据预处理===========
file = r'data.xlsx'
data = pd.read_excel(file)
data.columns = ['y', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9']
#====开始生成多元线性模型=====
x = sm.add_constant(data.iloc[:,1:]) #生成自变量x1~x9
y = data['y'] #生成因变量
model = sm.OLS(y, x) #生成模型
result = model.fit() #模型拟合
result.summary() #模型描述
print(result.summary())
'''
y与x1、x2、...、x9有着显著的线性关系,这里要注意x1到x9这9个变量被看作是一个整体,
y与这个整体有显著的线性关系,但不代表y与其中的每个自变量都有显著的线性关系,
我们在这里要找出那些与y的线性关系不显著的自变量,然后把它们剔除,下面这个函数就是这个作用。
'''
#=====找出y与哪几个自变量有显著的关系=============
def looper(limit): #limit一般取0.05
cols = ['x1', 'x2', 'x3', 'x5', 'x6', 'x7', 'x8', 'x9']
for i in range(len(cols)):
data1 = data[cols]
x = sm.add_constant(data1) #生成自变量
y = data['y'] #生成因变量
model = sm.OLS(y, x) #生成模型
result = model.fit() #模型拟合
pvalues = result.pvalues #得到结果中所有P值
pvalues.drop('const',inplace=True) #删除const这一列
pmax = max(pvalues) #选出最大的P值
if pmax>limit:
ind = pvalues.idxmax() #找出最大P值的index
cols.remove(ind) #把这个index从cols中删除
else:
return result
result = looper(0.05)
result.summary()
print(result.summary())
4.3 结果
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -1694.6269 562.977 -3.010 0.006 -2851.843 -537.411
x1 1.3642 0.086 15.844 0.000 1.187 1.541
x2 1.7679 0.201 8.796 0.000 1.355 2.181
x3 2.2894 0.349 6.569 0.000 1.573 3.006
x5 1.7424 0.191 9.111 0.000 1.349 2.136
==============================================================================
Omnibus: 3.769 Durbin-Watson: 2.401
Prob(Omnibus): 0.152 Jarque-Bera (JB): 2.493
Skew: -0.668 Prob(JB): 0.287
Kurtosis: 3.379 Cond. No. 5.74e+04
==============================================================================
其结果如图4所示。从结果中可以看到最后剩下的有效变量为
x1、x2、x3和x5,我们得到的多元线性模型为y = -1694.6269 + 1.3642 x1 + 1.7679 x2 + 2.2894 x3 + 1.7424 x5,这个就是我们最终要用到的有效的多元线性模型。
那么问题来了,前面我们得到的包含所有自变量的多元线性模型和这个剔除部分变量的模型,我们要选择哪一个,毕竟第一个模型的整体线性效果也挺显著,依据笔者的经验,这个还是要看具体的项目要求。因为我们实际项目中遇到的问题都是现实生活中真实存在的例子,不再是单纯的数学题了,比如本例中的x8消费价格指数和x9地区的失业率,这两个肯定对y是有一定影响的,如果盲目剔除,可能会对最终的结果产生不良影响,所以我们还是要根据实际需求来做决定。
5 算例4——Matlab代码实现
5.1 算例
“综合打分” 是 去年 体育老师根据这15名同学的体重、肺活量、50m短跑、1分钟仰卧起坐、跳远成绩、1000米成绩、1分钟跳绳、引体向上、坐位体前屈等等数据综合评价打出的分数。
今年 因为学校器材有限,体育老师只测了这15名同学的三项指标:跳远成绩、1000米成绩、1分钟跳绳。
现在体育老师想要知道这三项指标能不能 线性合成 成最后的 今年 的综合分数?
| 项目 | 跳远成绩(cm) | 1000米成绩(s) | 1分钟跳绳(个) | 综合打分(100分制) |
| 样本1 | 180 | 280 | 153 | 60 |
| 样本2 | 201 | 240 | 170 | 75 |
| 样本3 | 205 | 226 | 162 | 70 |
| 样本4 | 208 | 224 | 160 | 70 |
| 样本5 | 213 | 220 | 162 | 75 |
| 样本6 | 217 | 217 | 165 | 75 |
| 样本7 | 218 | 225 | 170 | 85 |
| 样本8 | 222 | 221 | 168 | 80 |
| 样本9 | 226 | 211 | 169 | 8o |
| 样本10 | 230 | 213 | 179 | 85 |
| 样本11 | 233 | 199 | 172 | 9o |
| 样本12 | 238 | 198 | 172 | 90 |
| 样本13 | 240 | 195 | 175 | 90 |
| 样本14 | 242 | 186 | 181 | 95 |
| 样本15 | 253 | 183 | 176 q | 96 |
5.2 Matlab代码实现
语法:
[b,bint,r,rint,stats]=regress(y,x,0.05); % 95%的置信区间说明:
①regress()中的α为显著性水平(缺省时默认为0.05)②b,bint 为 回归系数估计值 和 它们的置信区间
③r,rint 为 残差(向量) 及其置信区间
④stats 是用于检验回归模型的统计量,有4个数值,第一个是拟合优度 R2,第二个是 对方程整体显著性检验 的 F检验 ,第三个是 p值,第四个是 误差方差的估计值
clc;
clear;
close all;
%% 读取数据
shuju=xlsread('case4.xlsx');
%shuju=xlsread('case5.xlsx');
% 因为用的3是维拟合,则 x 应该为 3*15 的矩阵,第一列为 1 ,第二列为 x1 ,第三列为 x2 , 第四列为 x3
% 15 代表的是 样本个数
x1=shuju(:,1); % 跳高成绩
x2=shuju(:,2); % 1000m成绩
x3=shuju(:,3); % 跳绳个数
y=shuju(:,4);% 综合打分
len = length(y);
pelta = ones(len,1);
%% 多元线性拟合
x = [pelta, x1, x2, x3];
[b,bint,r,rint,stats]=regress(y,x,0.05); % 95%的置信区间
%% 拟合函数
Y_NiHe = b(1) + b(2) .* x1 + b(3) .* x2 + b(4) .* x3 ;
%% 可视化
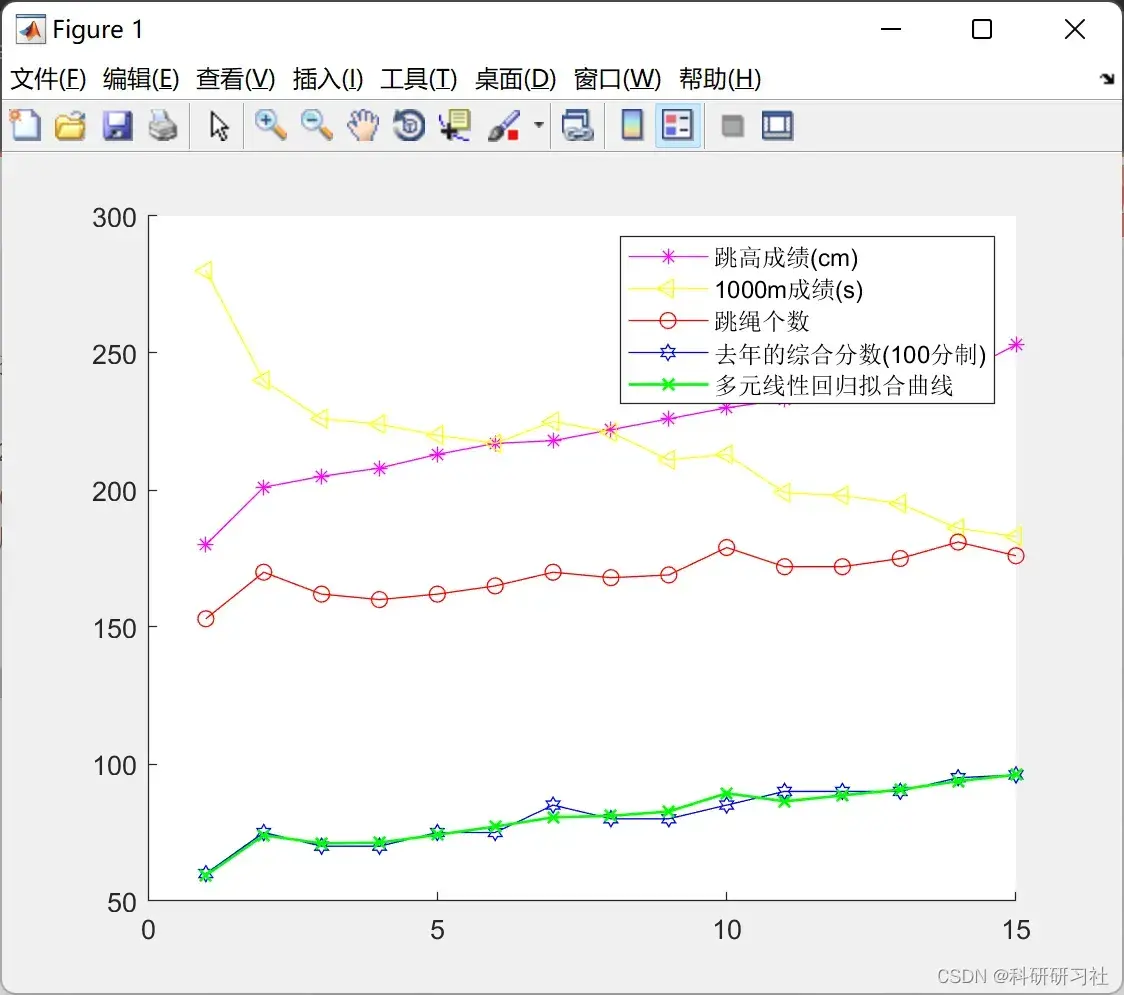
figure(1);
hold on;
plot(x1,'m*-');
plot(x2,'y<-');
plot(x3,'ro-');
plot(y,'bh-');
plot(Y_NiHe,'gx-','LineWidth',1);
legend('跳高成绩(cm)','1000m成绩(s)','跳绳个数','去年的综合分数(100分制)','多元线性回归拟合曲线')
R_2 = 1 - sum( (Y_NiHe - y).^2 )./ sum( (y - mean(y)).^2 );
str = num2str(R_2);
disp(['拟合优度为:',str])
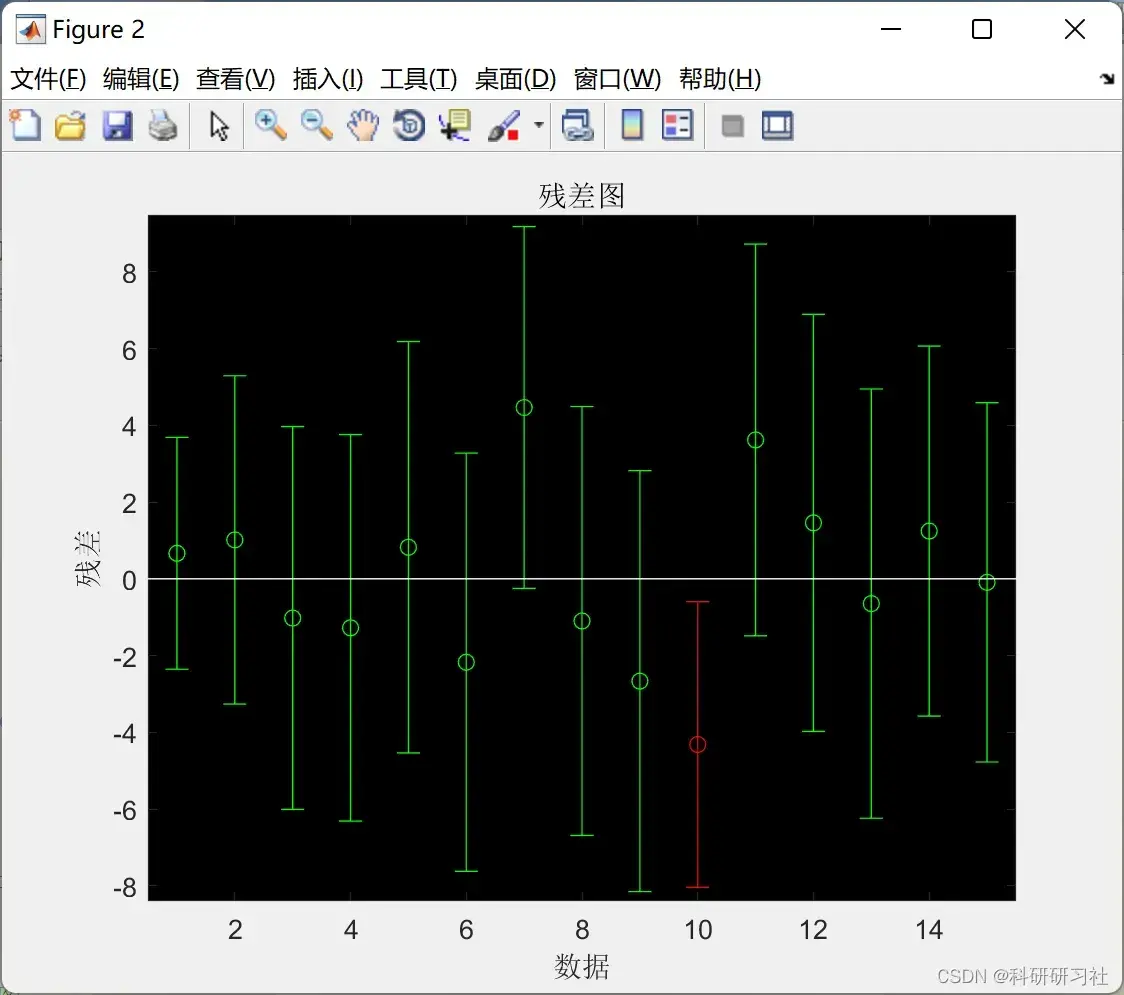
figure(2)
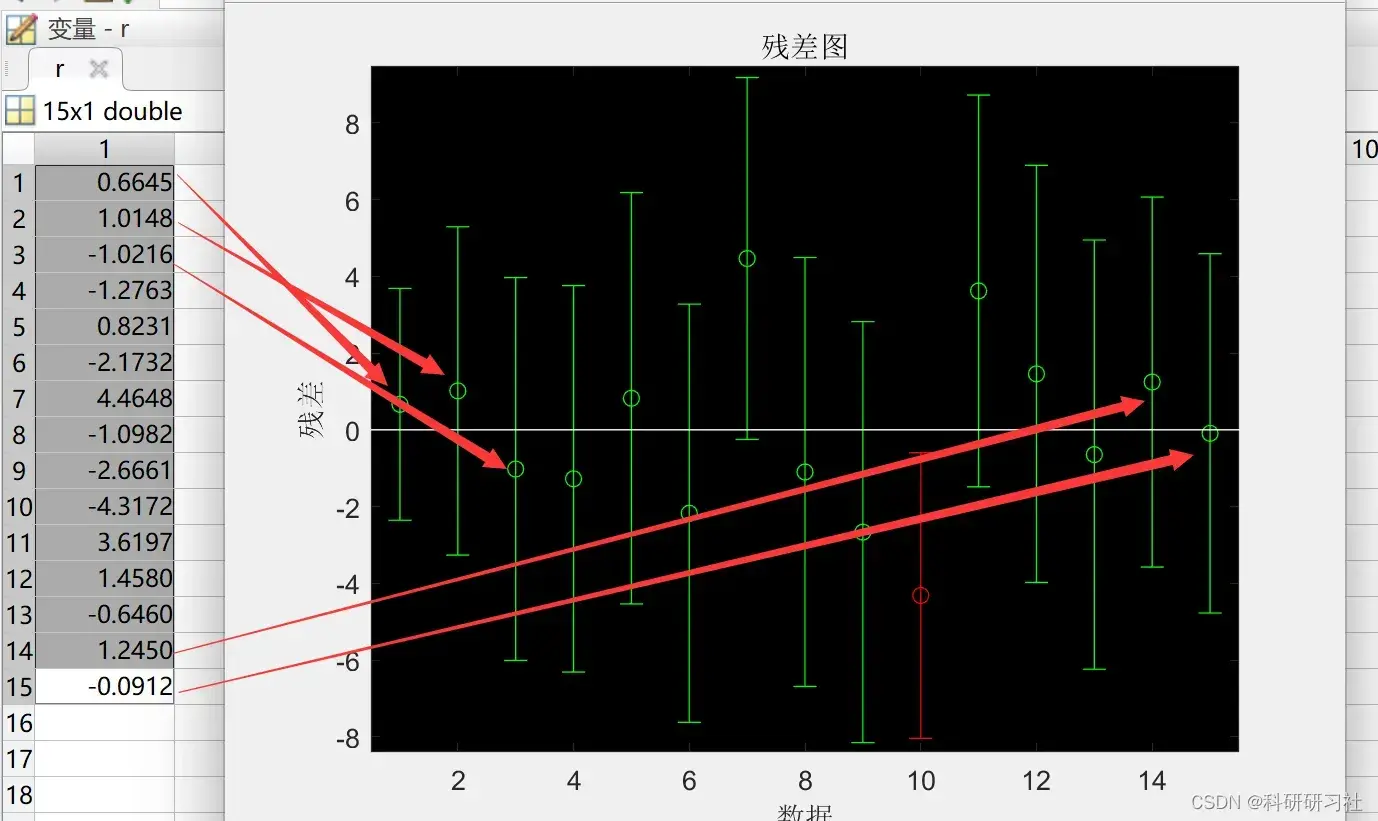
rcoplot(r,rint)%做残差图
title('厚度残差图')
xlabel('数据');ylabel('残差');
5.3 结果
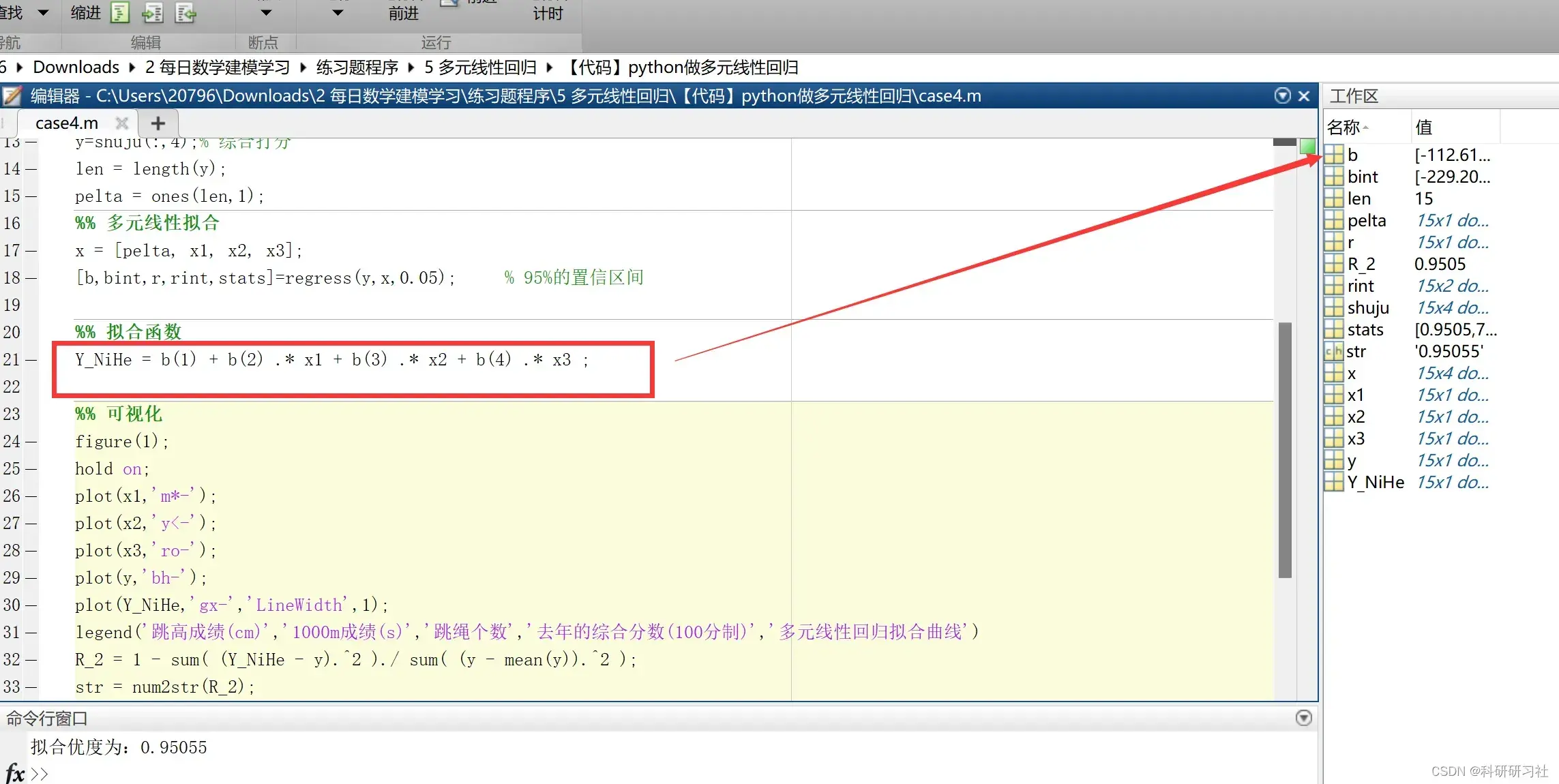
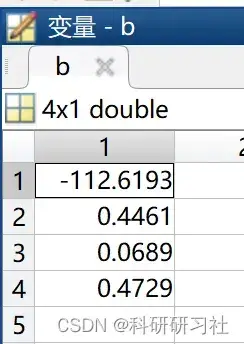
得到最终表达式如下:
残差:
6 写在最后
多元线性回归(Python&Matlab代码实现)
文章出处登录后可见!