机器学习:朴素贝叶斯模型算法原理
作者:AOAIYI
作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
文章目录
1、前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
在这个信息爆炸的时代,如何高效处理数据并利用数据推动决策显得尤为重要,这便是人们通常所说的“数据分析”。与数据分析相伴而生的机器学习(Machine Learning),有些人可能会感到陌生,然而说到战胜了众多人类围棋高手的智能机器人AlphaGo,想必大多数人都有所耳闻。AlphaGo背后的原理支撑就是机器学习,它通过模拟人类的学习行为,不停地分析海量的围棋数据,发现数据背后的规律,从而在已有条件下做出最为理性的决断,这个过程充满了机器美学。
Python是数据分析和机器学习的一把“利刃”,其功能强大且简单易上手。
2、实验原理
贝叶斯分类是机器学习中应用极为广泛的分类算法之一,其产生来自于贝叶斯对于逆概问题的思考,朴素贝叶斯是贝叶斯模型当中最简单的一种。
其算法核心为贝叶斯公式:

P(A)为事件A发生的概率
P(B)为事件B发生的概率
P(A|B)表示在事件B发生的条件下事件A发生的概率
同理P(B|A)则表示在事件A发生的条件下事件B发生的概率
如果只看公式,有些小伙伴会无法快速知道其中原理。举个例子:
已知流感季节一个人感冒(事件A)的概率为40%(P(A))
一个人打喷嚏(事件B)的概率为80%(P(B))
一个人感冒的条件下打喷嚏的概率为100%(P(B|A))
求这个人在打喷嚏的条件下患感冒的概率P(A|B),求解过程如下图所示:
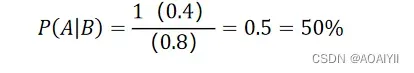
2.1、一维特征向量
首先以一个更详细的例子来讲解一下贝叶斯公式更加偏实战的应用:如何判断一个人是否感冒了。假设已经有5个样本数据,如下表所示:
| 打喷嚏(X) | 感冒(Y) |
|---|---|
| 1 | 1 |
| 1 | 1 |
| 0 | 1 |
| 1 | 1 |
| 1 | 0 |
打喷嚏 (X):其中数字1表示打喷嚏,0表示不打喷嚏;
感冒 (Y):其中数字1表示感冒了,数字0表示未感冒。
我们要利用贝叶斯公式,一个人打喷嚏 (X=1),那么他是否感冒了呢,也即预测他处于感冒状态的概率为多少,我们把此概率写作P(Y|X)。
则贝叶斯公式就有:
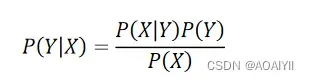
根据上述数据,我们可以计算在打喷嚏 (X=1) 的条件下,患上感冒的概率为:
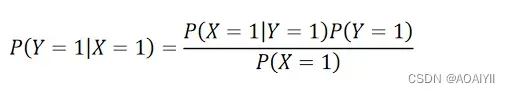
再根据上面的公式,代入数据得:
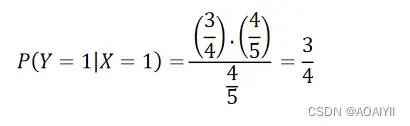
2.2二维特征向量
在上面,我们讲解了一维特征向量,只有两个变量。现在来讲二维特征向量,加入另外一个特征变量:头痛(X),其中数字1表示头痛,0表示不头痛;这里的目标变量仍为感冒(Y)。
| 打喷嚏(X1) | 头痛(X2) | 感冒(Y) |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 1 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
一个人他打喷嚏且头痛 (X1=1, X2=1) ,那么他是否感冒了呢,也即预测他处于感冒状态的概率为多少,在数学上,我们把此概率写作P(Y|X1,X2)。
则贝叶斯公式就有:
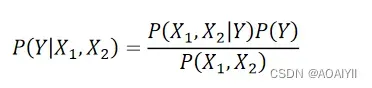
在比较 P(Y=1|X1,X2) 与 P(Y=0|X1,X2) 时,由于分母 P(X1,X2) 的值是相同的,所以我们在实际计算中可以舍去这部分的计算,直接比较两者分子大小即可。即:
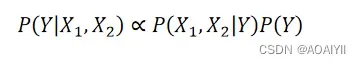
2.3n维特征向量
我们可以在2个特征变量的基础上推广至n个特征变量 X1, X2, … , Xn,应用贝叶斯公式有:
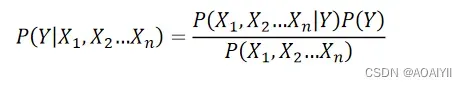
朴素贝叶斯模型假设给定目标值后特征之间相互独立,上式可以写作:
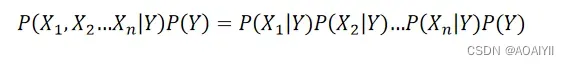
3、朴素贝叶斯模型演示
朴素贝叶斯模型(这里用的是高斯贝叶斯分类器)的引入方式如下所示:
导入模块
from sklearn.naive_bayes import GaussianNB
创建相关数据
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
y = [0, 0, 0, 1, 1]
建立高斯贝叶斯分类器
model = GaussianNB()
model.fit(X, y)
使用模型对数据预测
print(model.predict([[6,6]]))
![]()
4、案例实战:肿瘤预测
4.1案例背景
医疗水平突飞猛进,人们对医院快速识别肿瘤是否为良性的要求同样也越来越高,能否根据患者肿瘤的相关特征水平快速判断肿瘤的性质影响着患者的治疗方式和痊愈速度。传统的做法是医生根据数十个指标来判断肿瘤的性质,不过该方法的预测效果依赖于医生的个人经验而且效率较低,而通过机器学习我们有望能快速预测肿瘤的性质。
4.2读取数据
import pandas as pd
df = pd.read_excel(r"D:\CSDN\data\naivebayes\肿瘤数据.xlsx")
df.head()
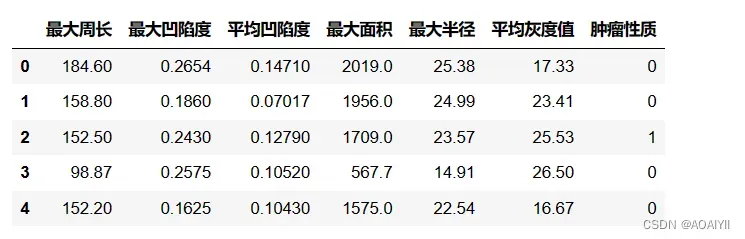
最大周长,最大凹陷度,最大面积,最大半径代表所有肿瘤中最大3个值的平均值
平均凹陷度,平均表面纹理灰度值,代表所有肿瘤度的平均值
对于目标变量肿瘤性质,Y=0 代表肿瘤为恶性,Y=1代表肿瘤为良性
4.3划分特征变量和目标变量
将特征变量和目标变量单独提取出来
X = df.drop(columns='肿瘤性质')
y = df['肿瘤性质']
4.4划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
4.5高斯朴素贝叶斯模型
from sklearn.naive_bayes import GaussianNB
nb_clf = GaussianNB()
nb_clf.fit(X_train,y_train)
nb_clf.score(X_train,y_train)
![]()
4.6模型预测
搭建模型的目的便是希望利用它来预测数据,这里把测试集中的数据导入到模型中来进行预测,代码如下,其中nb_clf就是上面搭建的朴素贝叶斯回归模型。
pre = nb_clf.predict(X_test)
利用创建DataFrame相关知识点,将预测的y_pred和测试集实际的y_test汇总,代码如下:
data = pd.DataFrame()
data['预测值'] = list(pre)
data['实际值'] = list(y_test)
查看测试集数据对预测准确度
from sklearn.metrics import accuracy_score
score = accuracy_score(pre,y_test)
score
![]()
将score打印输出,发现score的值为0.947,也即预测准确度为94.7%,说明114(569*0.2)个测试数据中,共有约108个数据预测正确,6个数据预测错误。
总结
朴素贝叶斯模型是一种非常经典的机器学习模型,它主要基于贝叶斯公式,在应用过程中会把数据集中的特征看成是相互独立的,而不需考虑特征间的关联关系,因此运算速度较快。相比于其他经典的机器学习模型,朴素贝叶斯模型的泛化能力稍弱,不过当样本及特征的数量增加时,其预测效果也是不错的。
文章出处登录后可见!