



ChatGPT对话数据备份
文章目录
1. 背景
之前在ChatGPT更新时有好几天都无法查看过往对话,而在服务器爆满宕机的时候更是不能登录回顾自己的对话。
所以有了缓存自己对话的需要,做好数据的备份。
2. 其他(失败的)方法
2.1 右键另存为
第一个想到最便捷的方法无疑是直接在浏览器端右键“另存为”:
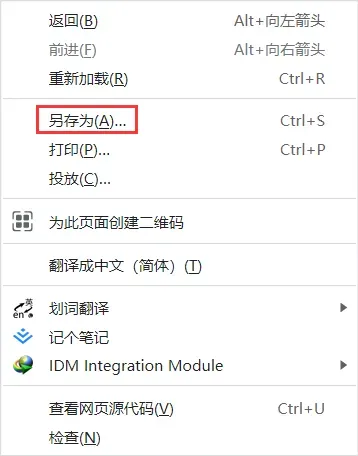
然而这种方法会额外下载许多资源文件:并放在一个目录上。


关键是当你双击页面进入时,只会出现首页,根本没有保存到对话:
(猜测是因为router:每次进入都是先进入该首页,随后再进行路由跳转到对应的对话。)

2.2 直接copy html代码
学过前端基础的小伙伴就知道,我们右键“检查”可以打开控制台,在“元素”栏目上找到整个对话的html代码——即main标签,随后粘贴到本地的html文件中进行重现。
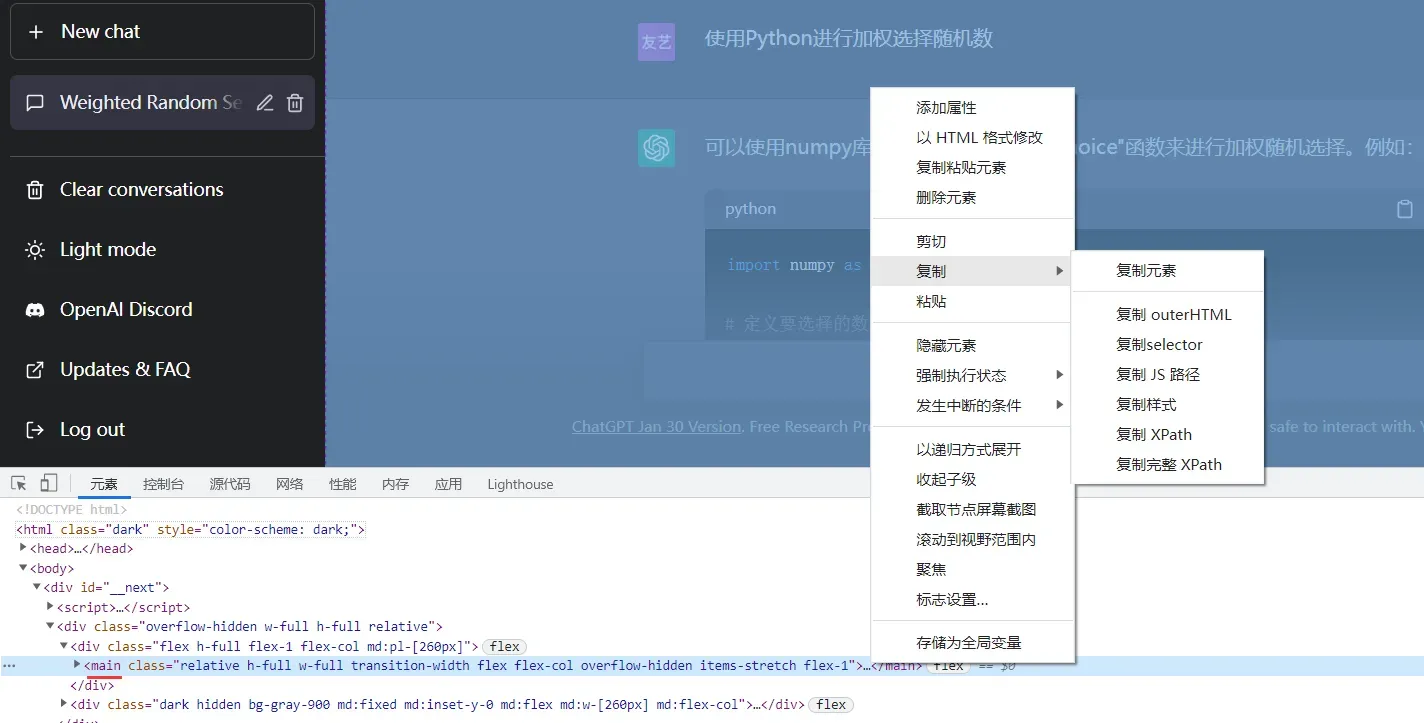

这种方式可以得到我们对话的数据,当然,因为仅有main标签,所以损失了对应的样式和copy code的功能。


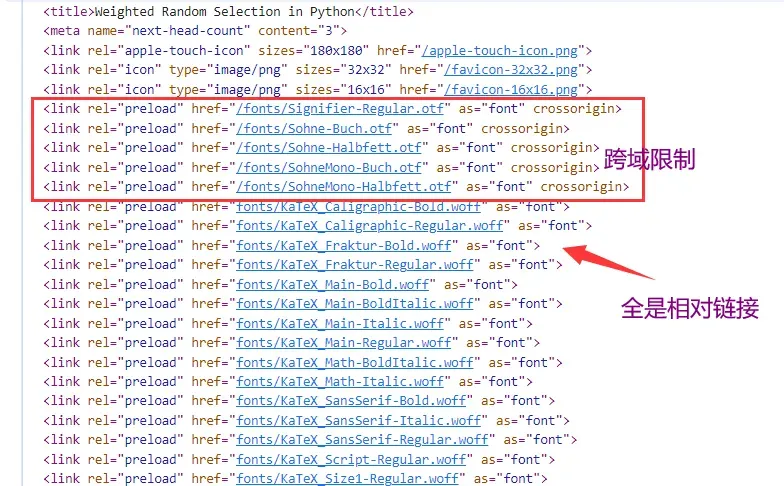
即便是copy整份html代码也是如此。
原因就是源代码上的script标签和样式链接基本都是相对链接,而且部分资源还有跨域限制。

3. 编写Javascript脚本
至此,为了省去不必要的麻烦。同时也是脚本优化的功能所在:
-
一键下载当前对话的html,不额外下载其他静态资源。
-
自动转化所有的相对链接为绝对链接。
-
保留样式风格:
light mode以及dark mode。 -
保证隐私:去除了原页面所有的script脚本,仅保留自己实现的
copy code功能。
3.1 思路过程
- 操作DOM对象
- 仅保留<head>标签和<main>标签、去除侧边栏、底部
- 对DOM对象内部所有的“相对链接”都转成“绝对链接”
- 通过正则提取内部所有的<script>标签并去除,自己写一个
copy code的<script>标签引入。
- 小细节:需要对页面DOM对象进行深拷贝,否则会影响原本的页面。
3.2 安装教程
- 下载浏览器端脚本管理器(如Tampermonkey,暴力猴)。
- 脚本下载途径:(两种)
- 下载Gitee仓库js文件夹内的downloadgpt.js,并将该脚本导入到管理器。
- 通过
Greasyfork网站直接下载:https://greasyfork.org/zh-CN/scripts/459853-download-chatgpt-record
3.3 使用说明
下载脚本后进入ChatGPT聊天,右下角出现download按钮,点击即可保存当前的对话记录。
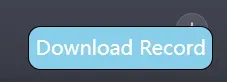

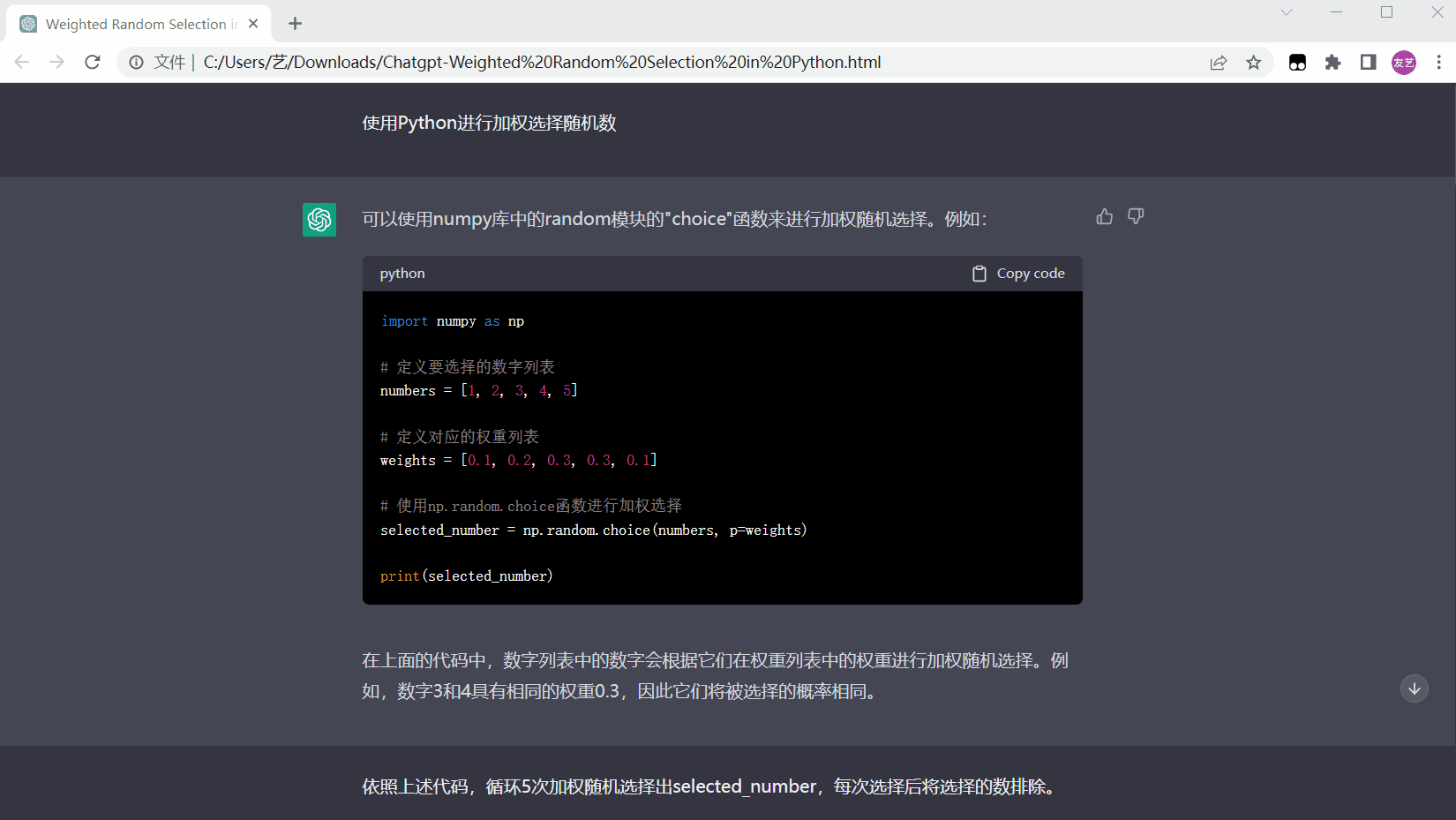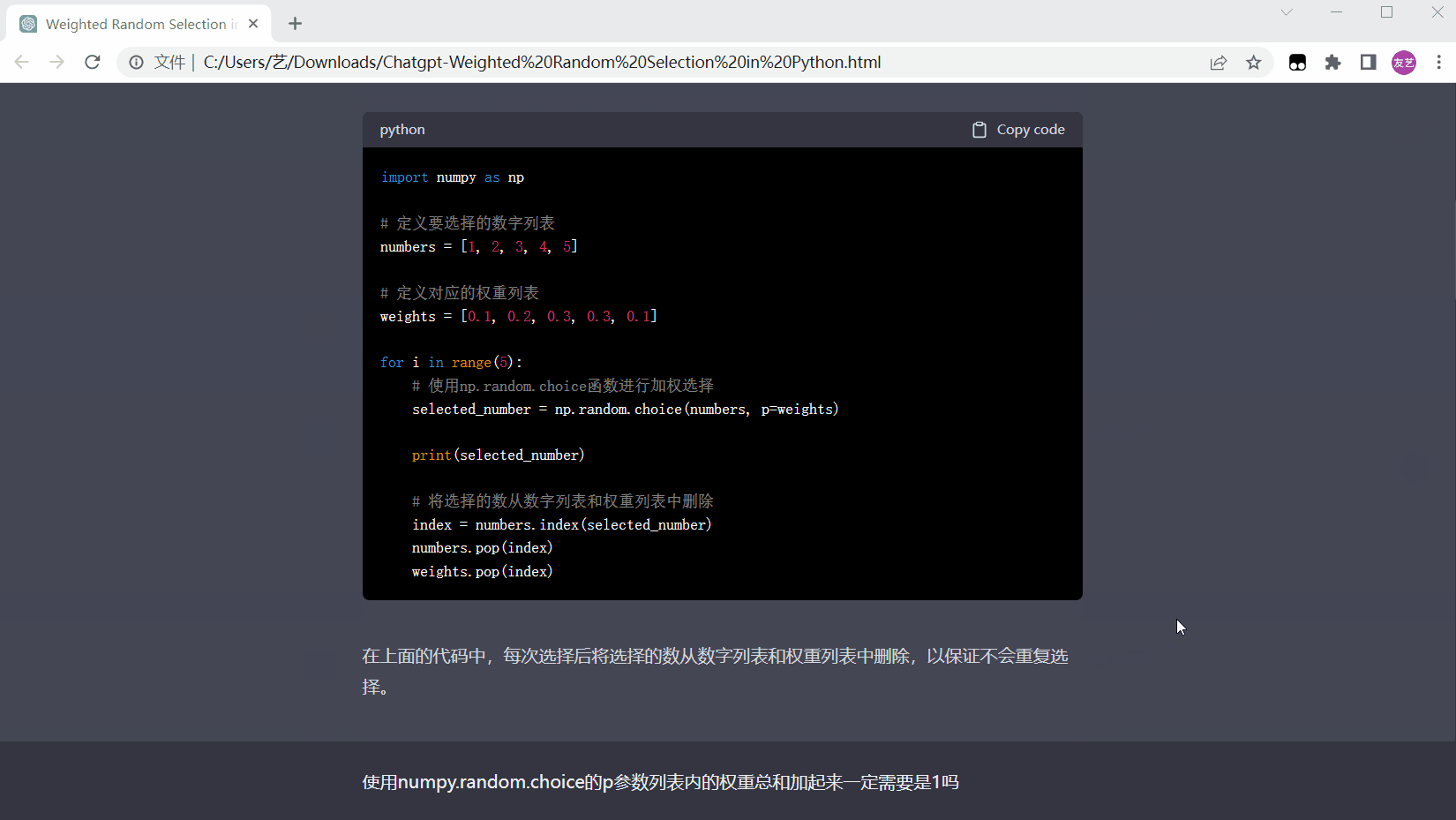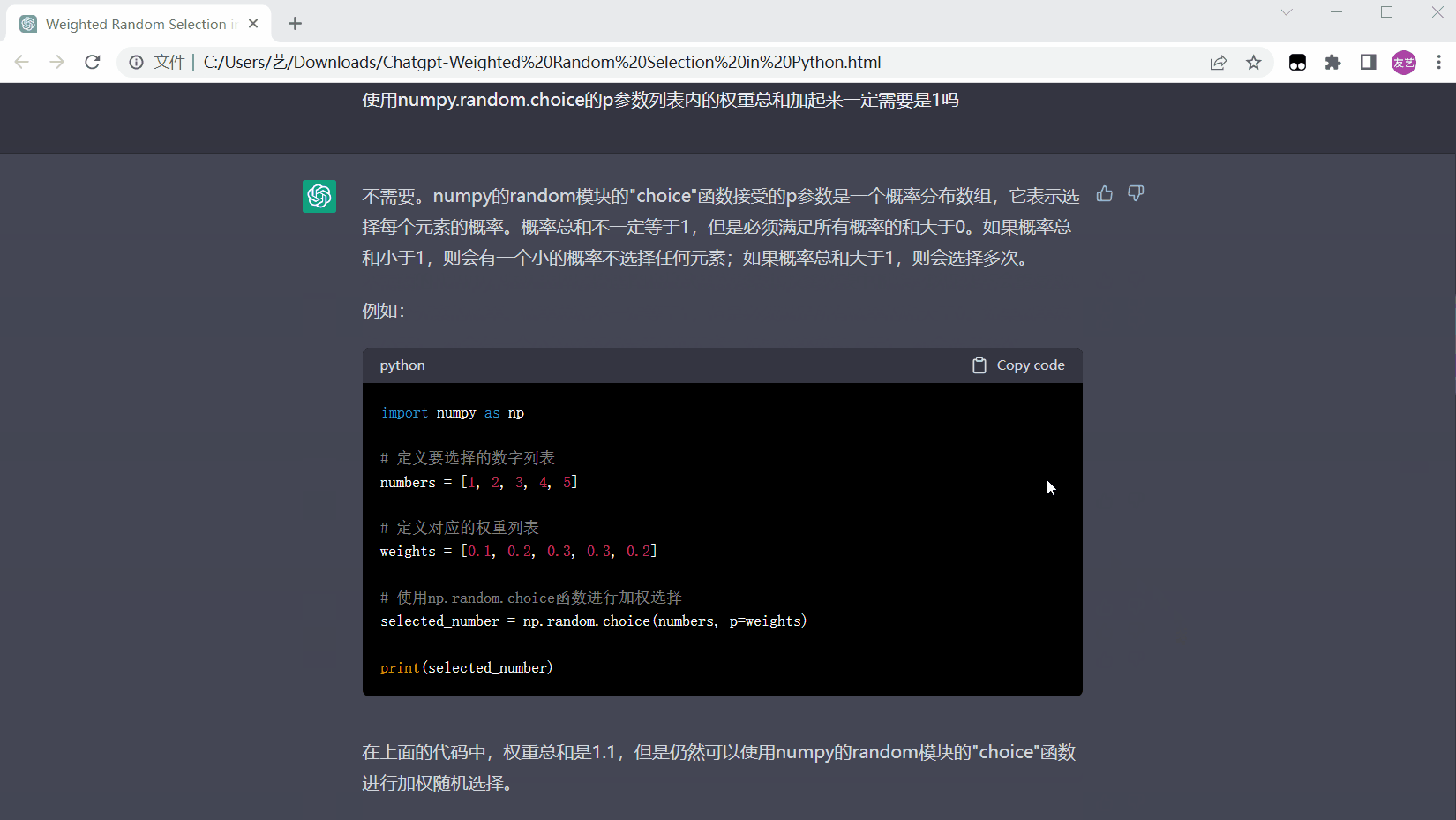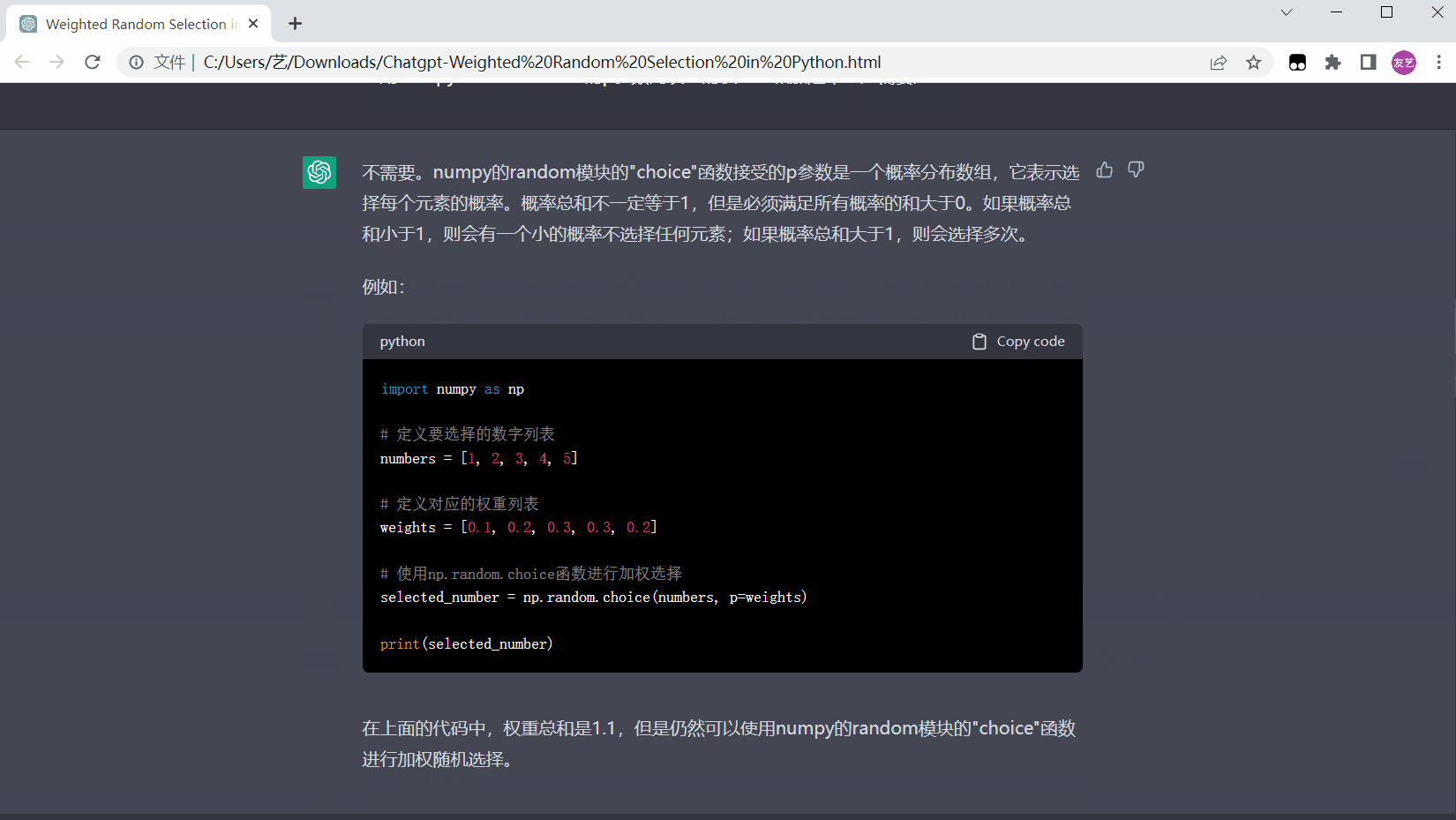
3.4 最终效果
保存后的html文件页面如下:

文章出处登录后可见!
已经登录?立即刷新