


简介
笔者thefan,目前为一所双非学校的大三在读本科生,对数据挖掘以及计算机视觉感兴趣,曾获得过讯飞房屋租金预测竞赛的top2,本次主要分享为2023 全球人工智能开发者先锋大会—AI 人才学习赛的rank1方案。
赛题分析
该赛题是和鲸社区上的一个AI 人才学习赛,其由上海市人工智能行业协会主办,联合上海多家人工智能相关企业,由 Datawhale、和鲸社区承办的一场面向 AI 开发者的学习实践赛事。本次大赛以企业相关人才需求为导向,聚合广泛的、跨学科的各类 AI 人才参与学习,利用真实场景下的数据研发 AI 算法模型、探索解决方案的学习实践赛事。比赛链接为: 2023 全球人工智能开发者先锋大会—AI 人才学习赛。
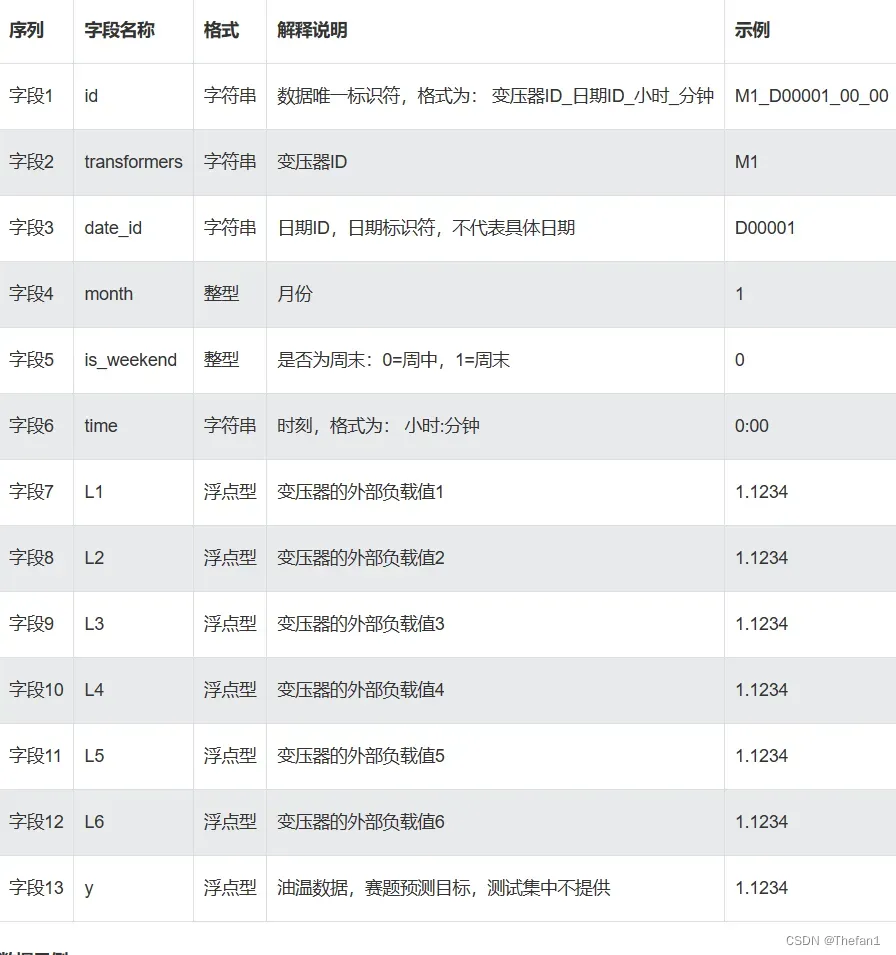
上图是数据的字段解释说明。很明显这是一个时序回归任务,我们需要探索油温与变压器运行的季节月份、时刻、外部负载等信息之间的关系。以构架一个模型来预测油温。在大致看了一下数据之后发现,我发现该赛题的连续性特征只有六个,分别为变压器的外部负载值的六个值,并且我并不知道变压器的外部负载值的六个值的具体含义,因此在这里我没办法根据这六个外部负载值根绝业务理解构造出业务特征。我便打算先试试对六个外部负载值进行暴力特征衍生;之后发现在特征中有time字段,我初步打算根据time字段先按照时间顺序进行排序,然后再对这六个外部负载值构造时序特征;并且还能够根据date_id,transformers,month,time,is_weekend等字段进行groupby操作,之后再对六个外部负载值进行agg操作计算出六个外部负载值的统计值;对于y值,基于经验我一般都会对标签做log平滑处理。
在对以上我提到的思路进行复现的时候,发现这个赛题虽然是时许回归任务,但是可能是数据质量的问题,如果我加入了六个外部负载值的时序特征,会导致分数的抖动非常大,并且在线下看来提升也并没有很大,因为考虑到还有B榜,为了尽量能够在AB榜换榜的时候分数不会抖动太大,我便放弃了构造时序特征的想法。之后我又开始尝试了对六个外部负载值进行暴力特征衍生,但是结果显示效果并不是很好,最开始我认为可能是特征维数太大,之后我便只保留了排名在特征重要性前面的特征进行训练发现效果还是不是很好,因此对六个外部负载值构造暴力衍生的特征我也放弃了。之后我又尝试了统计特征,当我加入了统计特征之后我线下的mse从300多下降到了60多,并且单纯用统计特征线上的分数就能到260+。但是这样做的风险为线下过拟合太严重了,因为我线下的mse下降了200多,然后我线上的分数才下降30多,因此我为了在AB榜换榜的时候分数不会抖动太大,我选择不对模型的参数进行细粒度的调整并且使用多个模型进行融合。

统计特征的构造
在统计特征的构造的过程中,我对一些提升不大的并且重要性偏低的统计特征进行了删除,最后所用到的特征构造代码如下:
def brute_force(df, features, groups):
for method in tqdm(['mean', 'std', 'median']):
for feature in features:
for group in groups:
df[f'{group}_{feature}_{method}'] = df.groupby(group)[feature].transform(method)
return df
dense_feats = ['L1', 'L2', 'L3', 'L4', 'L5', 'L6']
cat_feats = ['date_id', 'month', 'time']
df = brute_force(df, dense_feats, cat_feats)
标签y值的处理
因为该赛题的标签y值最小值为-4+,因此并不能按照常规的log1p(y)的方法对y值进行平滑处理,而应该将其替换为log(y + 5)。并且在预测完之后使用np.exp(y) – 5对预测值进行还原。
具体代码如下:
# 对y值进行平滑处理
y = np.log(df_train['y'] + 5)
# 将预测值进行还原
test['y'] = np.exp(prediction_lgb) - 5
模型的选择以及参数的选择
由于在加入了统计特征之后,过拟合太明显了,因此在模型的选择上我选择的是常规的树模型,并没有选择更容易过拟合的nn模型,因此我在选择了lgb和catboost两个常用的模型对数据进行拟合预测。在参数上我没有对参数进行细致的调整,直接用的是我一直以来喜欢用的参数。
lgb模型参数:
params = {
'learning_rate': 0.05,
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'feature_fraction': 0.7,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'seed': 2022,
}
catboost模型参数:
cbt_model = CatBoostRegressor(iterations=100000,
learning_rate=0.05,
eval_metric='MAE',
use_best_model=True,
random_seed=42,
logging_level='Verbose',
task_type='GPU',
devices='0',
gpu_ram_part=0.5,
early_stopping_rounds=200)
缓解过拟合的思考
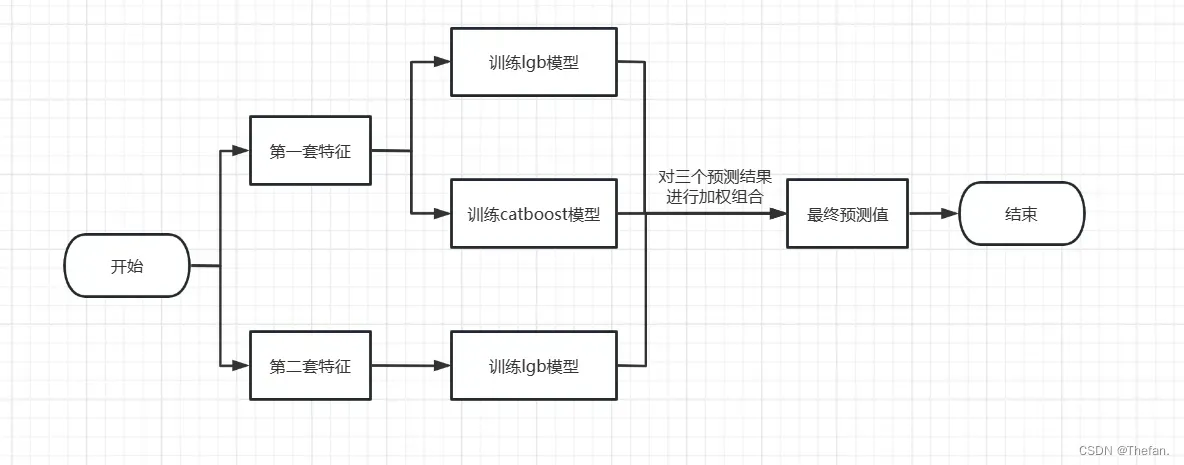
上面提到统计特征的加入会导致过拟合太严重,因此这里我们不但使用了不同的模型进行融合,而且其中一个模型使用到的参数也和另外两个模型使用到的特征并不是同一套特征。具体流程图如下:

赛后总结
由于第二套特征的构造思路就是我之前提到的,因此这里就不再赘述。
通过看我们使用到的特征可以看出虽然该赛题为时间序列数据,但是可能是由于数据质量的问题,常规的时间序列特征在该赛题并不能有多大的提升,不过也有可能是我的打开方式不对,但是统计特征对于这个赛题确有很大的提升,虽然会导致我们的模型线下的过拟合很严重,但是我们可以通过模型的融合来缓解分数抖动过大的问题。
完整可运行的代码链接
下面是我们在该赛题上的完整方案的可一键运行的完整代码。
2023 全球人工智能开发者先锋大会—AI 人才学习赛Rank1完整代码
文章出处登录后可见!