今天是春节后的第一篇原创,关于多任务学习,AAAI2023的work,如果您有相关工作需要分享,请在文末联系我们!
论文名称:Deformable Mixer Transformer for Multi-Task Learning of Dense Prediction
卷积神经网络(CNN)和Transformer具有各自的优势,它们都被广泛用于多任务学习(MTL)中的密集预测。目前对MTL的大多数研究仅依赖于CNN或Transformer,本文结合了可变形CNN和query-based 的Transformer优点,提出了一种新的MTL模型,用于密集预测的多任务学习,基于简单有效的编码器-解码器架构(即,可变形混合器编码器和任务感知transformer解码器),称之为DeMT。首先,可变形混合器编码器包含两种类型的算子:信道感知混合算子,用于允许不同信道之间的通信(即,有效的信道位置混合),以及空间感知可变形算子,其可变形卷积应用于有效地采样更多信息的空间位置(即,变形特征)。第二,任务感知transformer解码器由任务交互block和任务查询block组成。前者用于通过自关注来捕捉任务交互特征,后者利用变形特征和任务交互特征,通过基于查询的Transformer生成相应的任务特定特征,用于相应的任务预测。在两个密集图像预测数据集NYUD-v2和PASCAL Context上的大量实验表明,本文的模型使用更少的GFLOP,但在各种指标上显著优于当前基于Transformer和CNN的模型。
代码:https://github.com/yangyangxu0/DeMT.
1领域背景介绍
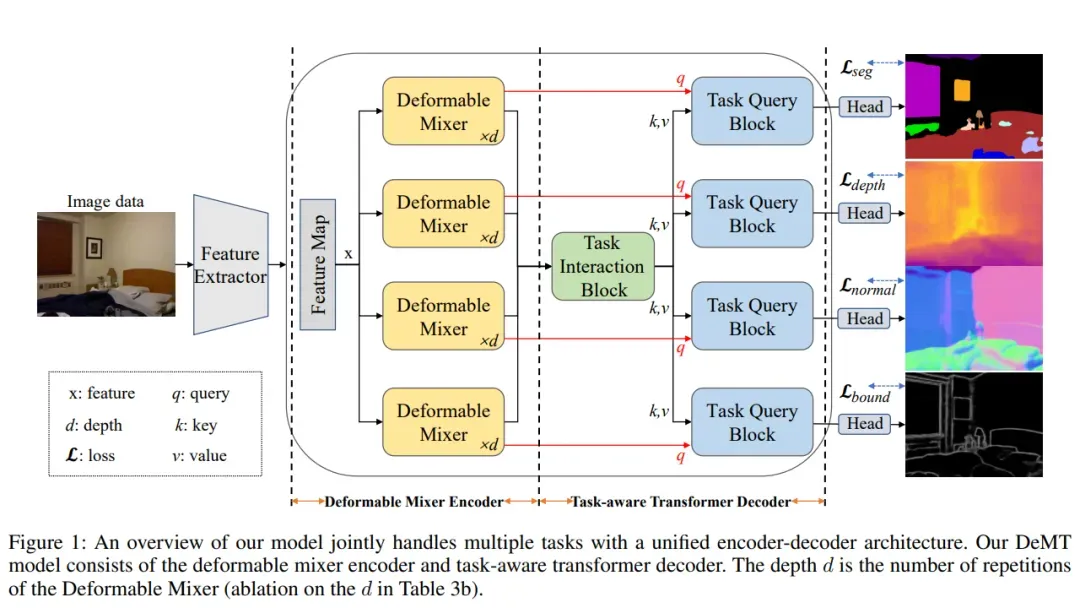
人类视觉可以从一个视觉场景执行不同的任务,如分类、分割、识别等。因此,多任务学习(MTL)研究是计算机视觉领域的热点。期望开发一个强大的视觉模型,以在不同的视觉场景中同时执行多个任务,有望高效工作。如图1所示,本文旨在开发一个强大的视觉模型同时学习多个任务,包括语义分割、人体部位分割、深度估计、边界检测、显著性估计和normal estimation。
尽管基于CNN的MTL模型被谨慎地提出以在多任务密集预测任务上实现有希望的性能,但这些模型仍然受到卷积运算的限制,即缺乏全局建模和跨任务交互能力。一些工作(Bruggemann et al.2021;Vandenhende et al.2020)开发了一种蒸馏方案,通过扩大感受野和堆叠多个卷积层来增加跨任务和全局信息传递的表达能力,但仍然无法直接建立全局依赖性。为了建模全局和跨任务交互信息,基于Transformer的MTL模型利用有效的注意力机制进行全局建模和任务交互。然而,由于query、key和value基于相同的特征,这种自关注方法可能无法关注任务感知特征,特定的自关注可能会导致高计算成本,并限制区分特定任务特征的能力。
基于CNN的模型可以更好地捕捉本地领域中的多任务上下文,但缺乏全局建模和任务交互。基于Transformer的模型更好地关注不同任务的全局信息。然而,它们忽略了task感知,并引入了许多计算成本。因此,开发更好的MTL模型的技术挑战是如何结合基于CNN和基于Transformer的MTL模式的优点。为了解决这些挑战,本文引入了可变形混合transformer(DeMT):一种基于可变形CNN和基于query的transformer优点的简单有效的多任务密集预测方法。
具体来说,DeMT由可变形混合器编码器和任务感知transformer解码器组成。受可变形卷积网络在视觉任务中的成功激励,本文的可变形混合器编码器基于更有效的采样空间位置和信道位置混合(即变形特征),为每个任务学习不同的变形特征。它学习多个变形特征,突出显示与不同任务相关的更多信息区域。在任务感知transformer解码器中,多个变形特征被融合并输入到任务交互模块。使用融合的特征,通过模型任务交互的多头自关注来生成任务交互特征。为了关注每个任务的任务感知,论文直接使用变形特征作为查询标记。希望候选key/value集来自任务交互特性。然后,任务查询块将变形特征和任务交互特征作为输入,并生成任务感知特征。通过这种方式,可变形混合器编码器选择更有价值的区域作为变形特征,以缓解CNN中缺乏全局建模的问题。任务感知transformer解码器通过自关注来执行任务交互,并通过基于查询的transformer来增强任务感知。这种设计既降低了计算成本,又注重任务感知功能。通过在几个公开的MTL密集预测数据集上实验,证明了所提出的DeMT方法在各种指标上取得了最先进的结果!
2DeMT方法介绍
如图1所示,DeMT是非共享编码器,首先,作者设计了一个可变形的混合器编码器来编码每个任务的特定空间特征。第二,提出了任务交互块和任务查询块来建模和解码任务交互信息,并通过自注意机制来解码任务特定特征。
1)特征提取
特征提取器用于聚合多尺度特征并为每个任务制造共享特征图,初始图像数据(3表示图像通道)被输入到主干,然后主干生成四个阶段的图像特征。然后将四个阶段的图像特征上采样到相同的分辨率,然后沿着通道维度将它们连接起来,以获得图像特征,其中H、W和C分别是图像特征的高度、宽度和通道!
2)Deformable Mixer Encoder
受可变形ConvNets和可变形DETR模型的成功启发,作者提出了可变形mixer编码器,该编码器自适应地为每个任务提供更有效的感受野和采样空间位置。为此,可变形mixer编码器被设计为分离空间感知可变形空间特征和信道感知位置特征的混合。
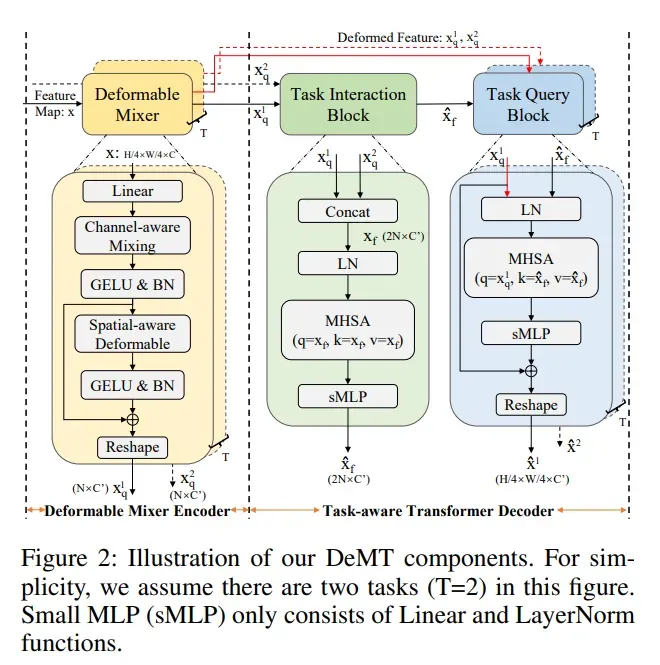
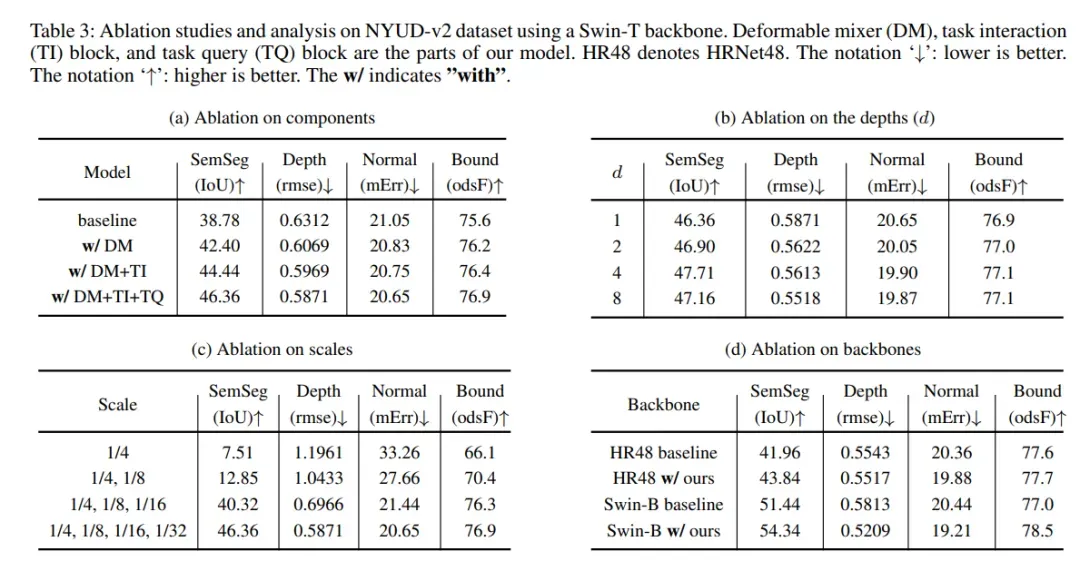
如图2(左)所示,空间感知可变形和信道感知混合算子被交错,以实现两个输入特征维度(HW×C)的交互。可变形的混合器编码器能够捕获与单个任务相对应的独特感受区域,可变形mixer只关注一小组可学习偏移的关键采样点,空间感知可变形体能够对空间上下文聚合进行建模。然后,空间感知可变形、通道感知混合和层归一化算子被堆叠以形成一个可变形混合器。可变形混合器叠层深度对模型的影响如表3b消融实验所示。
可变形混合器编码器结构如图2所示,首先,线性层降低了图像特征X通道维数更小的尺寸C0,线性层可以写成如下:
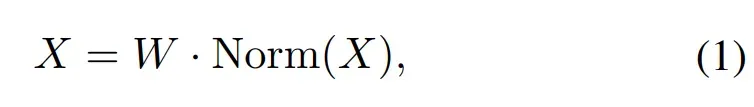
通道感知混合,channel感知混合允许不同通道之间的通信,应用标准逐点卷积(卷积核为1×1)来混合通道位置,它可以表示为:
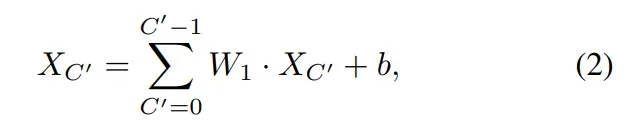
随后,还添加了GELU激活和BatchNorm,该操作计算如下:
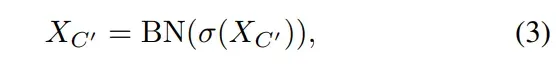
文章出处登录后可见!