Stacking模型融合
Stacking是一种嵌套组合型的模型融合方法,其基本思路就是在第一层训练多个不同的基学习器,然后把第一层训练的各个基学习器的输出作为输入来训练第二层的学习器,从而得到一个最终的输出。
具体的构建思路如下:
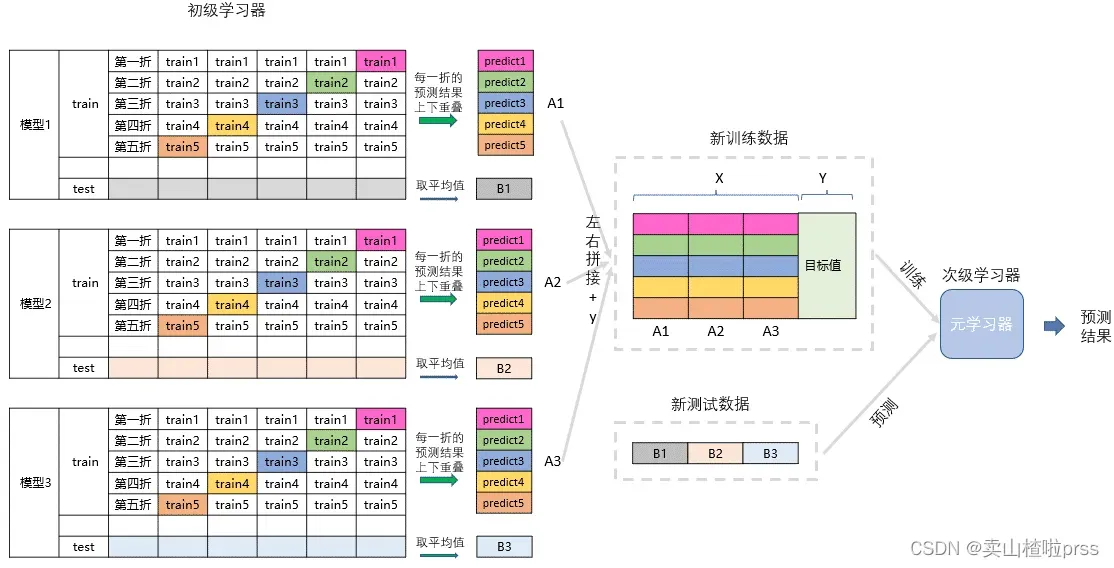
用一个基础模型进行5折交叉验证,对于训练集先拿出4折作为训练数据,另外一折作为测试数据,每一次交叉验证我们都会基于训练数据训练生成的模型对测试数据进行预测,这部分预测值最后拼接起来就是第二层模型的训练集。同时每次交叉验证我们还要对数据集原来的整个测试集进行预测,最后将各部分预测值取算术平均,作为第二层模型测试集,在此之后,我们把第一层模型的训练集预测值并列合并得到的矩阵作为训练集,第一层模型的预测集预测值并列合并得到的矩阵作为测试集,带入第二层的模型,再基于它们进一步训练,从而得到最终预测结果。
可参考之前的博客,关于融合模型的一些简单整理(Stacking、Blending)
其流程图如下所示:
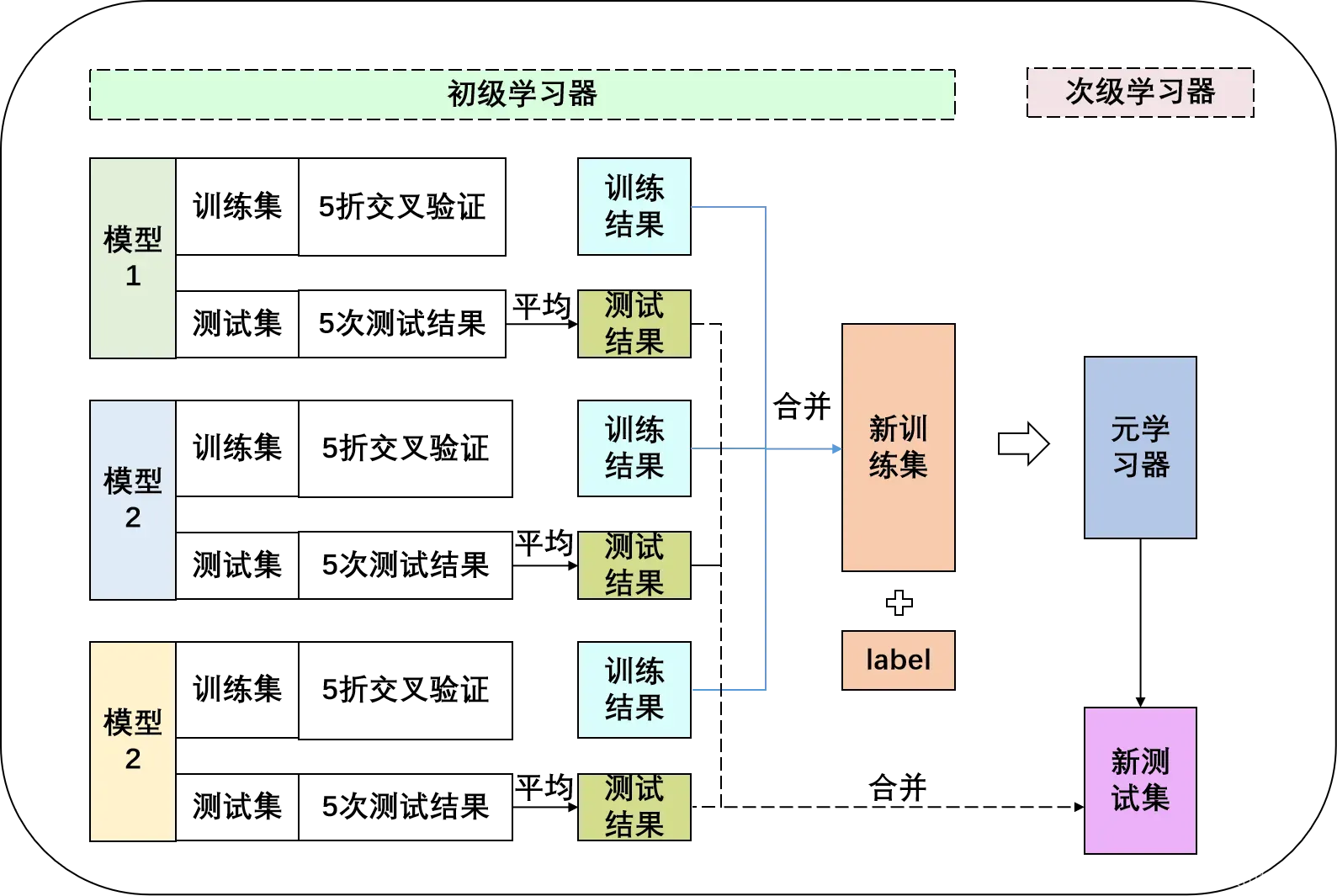
简化一下,可以画成这样
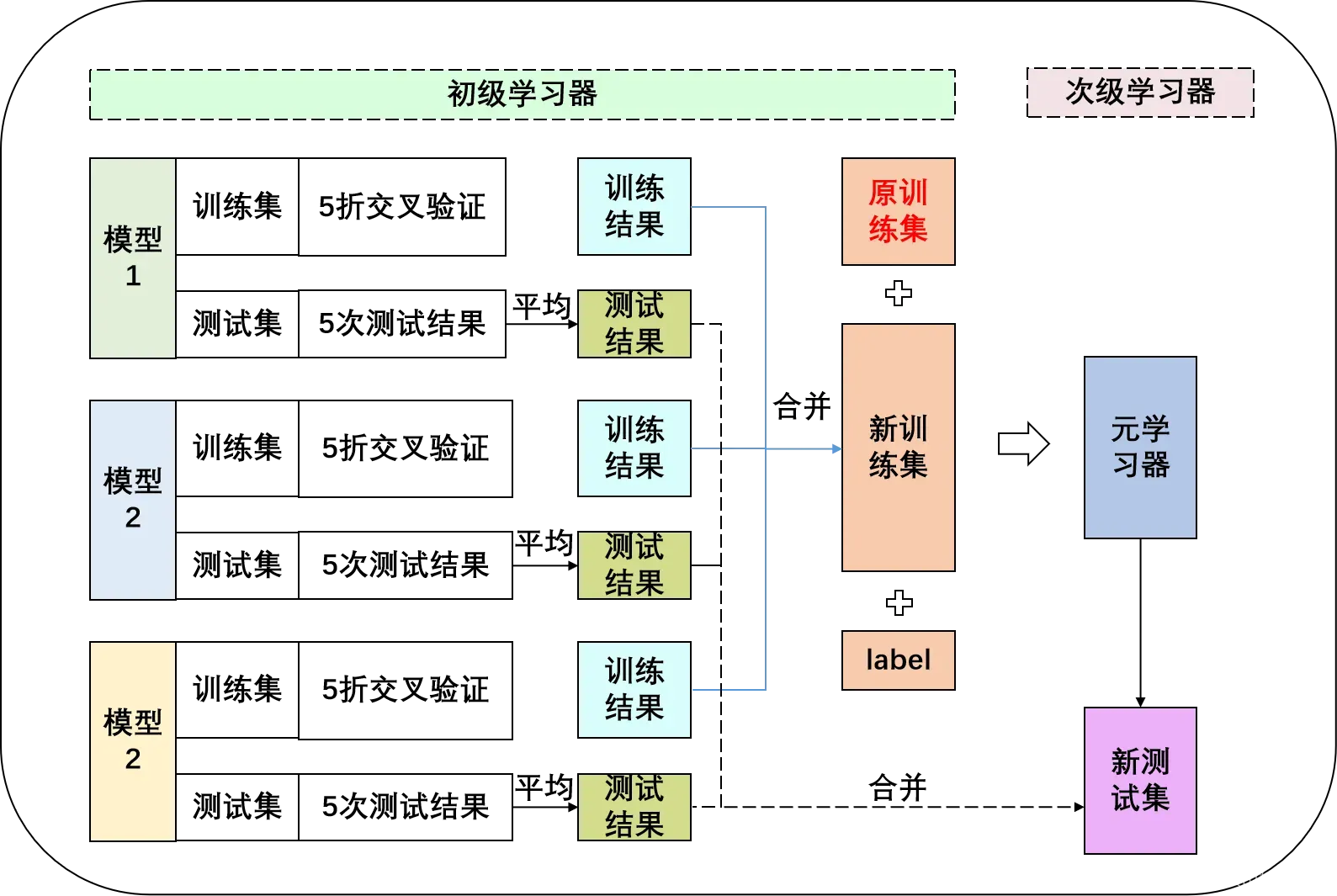
(1)加入原始训练集的Stacking融合模型构建
标准的Stacking融合模型第二阶段模型训练使用的数据集是由第一阶段各模型训练集的输出值组合而成的,一般有几个初级学习器就有几个输入特征,这种方式虽然能有效避免模型过拟合,提高模型效果,但使用新的组合训练集可能会丢失部分原始训练集中的信息。
因此,为了探索Stacking融合模型效果是否可以进一步有所提高,这里将原始数据集也作为次级学习器训练的一部分,即次级学 习器的训练集由原始训练集和第一阶段形成的新数据集组合得到,使得次级学习 器学习到原始训练集与新训练集之间的隐含关系,从而提升模型预测效果。
(2)加权Stacking融合模型构建
由于初级学习器中的模型的性能各有差异,为了更好地得到初级学习器中的有效信息,可以基于第一层中每个学习器性能的好坏,对第一层中每个学习器输出的结果进行加权平均(这里初级学习器的权重可以设定为每个模型输出的AUC值)。
过程如下:
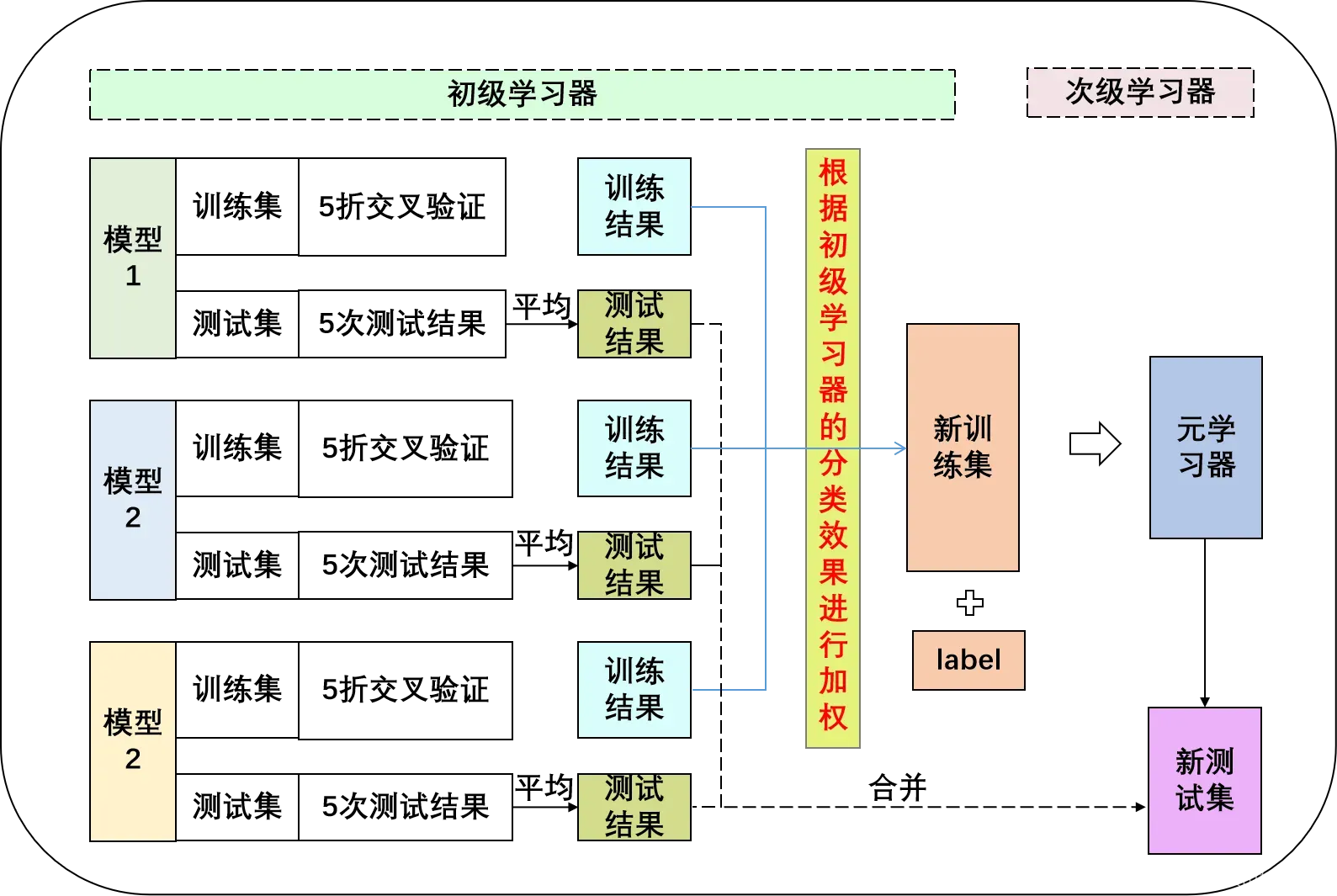
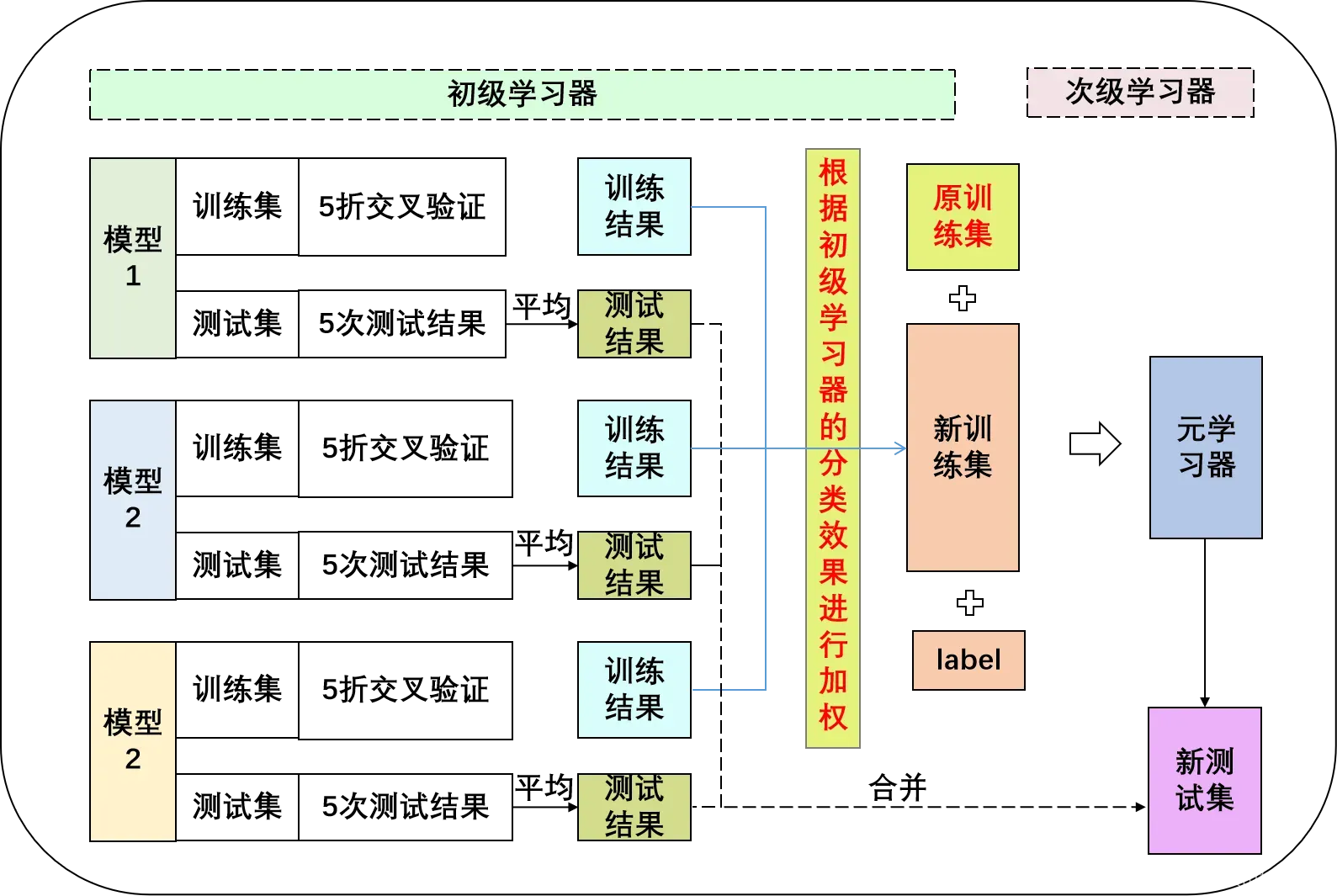
(3)加入原始训练集+加权的Stacking融合模型构建
第三个改动是综合了前面两种改动,即对标准Stacking模型加入原始数据集的同时还对标准Stacking模型进行加权处理,既要挖掘原始训练集与新训练集之间的隐含关系,又要对每个学习器设置不同的权重,突出模型预测性能好坏。模型框架如下图:
至此,以上为对模型融合Stacking的一些小改动思路,具体可以在实践中去验证改进效果,不一定说进行了改进后模型效果就会有提升,有时候可能反而效果降低~具体问题具体分析。
文章出处登录后可见!