前言
开始进入研究生生活啦~想研究的方向是图深度学习方向,现在对图卷积神经网络GCN进行相应的了解。这篇文章就是对《Semi-Supervised Classification with Graph Convolutional Networks》这篇发表在2017年ICLR上的会议论文。这是一篇经典的论文,对刚刚接触GCN的研究人员来说,是一个很好的开始。
一、论文拟解决问题与思想
《Semi-Supervised Classification with Graph Convolutional Networks》这篇论文受到谱图卷积的局部一阶近似可以用于对局部图结构与节点的特征进行编码从而确定卷积网络结构的启发,提出了一种可扩展的图卷积的实现方法,可用于具有图结构数据的半监督学习。
二、正文
1.标识概念
首先需要对论文中所涉及到的基本概念进行相应的了解。
A(Adjacency Matrix)表示图的邻接矩阵。表示顶点之间相邻关系的矩阵。 A的上面在加一横线的计算方式为A + I,表示带自环的邻接矩阵。
D(Degree Matrix)表示图的度矩阵。为对角矩阵,对角上的元素为各个顶点的度。顶点vi的度表示和该顶点相关联的边的数量。(无向图中一般记录的是单纯的入度或者出度)
L(Laplacian Matrix)表示图的拉普拉斯矩阵。其为半正定矩阵,运算规则是D-A。
Lsym(Symmetric Normalized Laplacian Matrix)表示对称归一化的拉普拉斯矩阵。表示为L左乘D的-1/2次方,再右乘D的-1/2次方;也可以表示为用单位矩阵I减去L左乘D的-1/2次方,再右乘D的-1/2次方。式子如下:
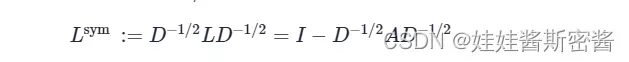
此矩阵还有一种计算方式:
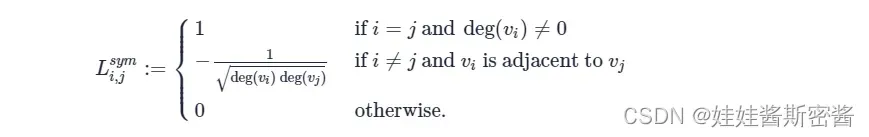
2.快速卷积
首先必须理解卷积的概念:这个地方主要理解为:翻转->滑动->叠加->滑动->叠加…
连续情况下叠加是指乘积的积,离散情况下是加权求和。
在一张图中,我们可以知道每个节点都有自己的特征信息和结构信息,GCN是一种能对图数据进行深度学习的方法。可以通过以下三个步骤进行理解图卷积算法:
1.发射:每一个节点将自身的特征信息经过变换后发送给邻居节点。这是对节点的特征信息进行抽取变换。
2.接收:每个节点将邻居节点的特征信息聚集起来。这是对节点的局部结构信息进行融合。
3.变换:把前面的信息聚集之后做非线性变换,增加模型的表达能力。
论文中所提到的使用神经网络模型f(X,A)对所有带标签节点进行基于监督损失的训练。其中X为输入数据,A为图的邻接矩阵。
f (⋅)表示一个运算或者代表一个神经网络函数,可以允许模型从监督损失L0中分配梯度信息,可以学习所有节点包括带标签的和不带标签的表示。
本文在快速卷积方面提出了多层图卷积网络的规则,其中公式如下:
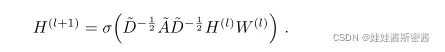
上面式子所涉及到的W (l)表示为特定层可训练的权重矩阵。值得注意的是,在多层GCN中,带自环的邻接矩阵是固定不变的,它依赖于最开始拓扑图的构建,我们需要学习的只有权重矩阵的参数。此处插入几个疑问:
Q:为什么需要添加自环?
A:如果不添加自环,在汇集邻居信息的时候,不管使用平均法还是加权平均法都忽略了自身节点的特征。所以在更新自身节点时,一般需要添加一个自环,把自身特征和邻居特征结合起来更新节点。
Q:为什么使用对称归一化?
A:一张图中,不同节点,其边的数量和权重幅值都不一样,比如有的节点特别多的边,这就导致了多边或者权重很大的节点在聚合后的特征值远远大于少边或者边权重小的节点。这可能导致网络训练过程中梯度爆炸或者梯度消失的问题。所以需要在节点更新自身前,对邻居传来的信息(包括自环信息)以及邻居节点所传播的信息进行归一化消除这样的问题。总结来说,可以将归一化的矩阵看作是对邻接矩阵的一种横、纵向归一化。
Q:为什么会引入拉普拉斯矩阵?
A:因为拉普拉斯矩阵是一个对称矩阵,可以进行特征分解。在谱域研究图,需要对图进行傅里叶变换将图投影到傅里叶域。一个域之所以称之为“域”,起码应该包含一组正交基,使得该域的各个位置或者各个状态都可以由这组正交基的线性组合来表示。其中拉普拉斯矩阵的特征向量恰好可以组成一组正交基,所以可以使用矩阵形式来表示图的傅里叶变换。
Q:为什么要对拉普拉斯矩阵进行特征分解?
A:卷积在傅里叶域的计算相对简单,因此我们需要将图由空域变换到谱域,而在这一变换中,需要找到图的连续正交基以对应于傅里叶变换的基,因此需要使用拉普拉斯矩阵的特征向量。
引入激活函数的目的:如果在神经网络中不引入激活函数,那么在该网络中,每一层的输出都是上一层输入的线性函数,无论最终的神经网络有多少层,输出都是输入的线性组合,这样更深层次的网络便没有了存在的意义,并且在非线性的问题中无法发挥优势。于是添加激活函数引入非线性因素,引入了非线性表达能力,不仅使得神经网络的适用范围更广泛,而且提高了模型的鲁棒性、缓解梯度消失的问题、将特征输入映射到新的特征空间、加速模型的收敛。
2.1 谱图卷积
借助图谱的理论来实现拓扑图上的卷积操作,也是利用图的拉普拉斯矩阵的特征值和特征向量来研究图的性质。
第一种卷积公式如下:
![]()
其中x表示图节点的特征向量;gθ=diag(θ)为卷积核,其中θ为参数;U为图的拉普拉斯矩阵L的特征向量矩阵。
在论文中提到,此公式计算过于复杂、卷积核的选取也不合适,于是提出了以下内容。
第二种卷积公式:
这里提出了一种卷积核的设计方法,即gθ(Λ)可以用切比雪夫多项式T k(x)到第K代的截断展开来近似。
第一类的切比雪夫(Chebyshev)多项式,由以下递推式得到:
![]()
于是新的卷积核表示为:
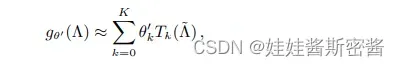
其中Λ横 = 2Λ / λmax – In,λmax为L的最大特征值;θ’ ∈ Rk表示为切比雪夫系数的向量。
进而得到卷积公式如下:
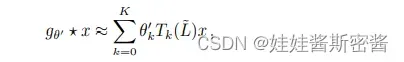
其中L横的计算方式和上面的Λ横计算方式一样。
注意这个公式是拉普拉斯算子中的K阶多项式,仅仅依赖于离中央节点最大K步的节点。
第二种卷积公式将参数化简到了K个,不再需要做特征分解,直接使用L进行变换,解决了最为耗时的一步,利用切比雪夫多项式去拟合卷积核方法降低了复杂度。
Q:为什么要引入切比雪夫多项式?
A:因为切比雪夫多项式可以用来逼近函数。
2.2 线性模型
GCN可视为对ChebNet的进一步简化,当卷积操作K = 1时,关于L是线性的,因此在拉普拉斯谱上有线性函数。在此基础上,假设λmax ≈ 2,可以预测GCN的参数在训练过程中可以适应这样的变化,当ChebNet一阶近似时, 那么ChebNet卷积公式简化近似为如下公式:
![]()
其中此公式中包含两个自由参数θ0’和θ1’,滤波器的参数可以被整个图片共享。
连续使用这种形式的滤波器,可以有效的卷积节点K阶邻域,K为模型中连续滤波操作或者卷积层的数目。
为了限制参数的数量以解决过度拟合, 并最小化每层的计算操作, 1-st ChebNet假设 ,图卷积的定义就近似为(简单一阶模型),在实际运用中,我们采用以下简化操作:
我们令θ = θ0’ = – θ1’,则可以得到以下的公式:
![]()
而 的特征值范围在 [0,2], 所以在深度神经网络中反复使用该算子将导致数值消失或爆炸问题(梯度爆炸或消失问题). 所以引入归一化技巧(renormalization trick),即拓扑图加上自环:
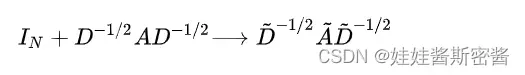
所以论文中的快速卷积公式就是:
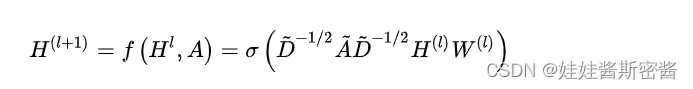
其中 是参数 矩阵, 为节点的特征向量. 计算复杂度也大大降低。
上述的标识符号已在本文前面介绍过,这里不再赘述。
当此定义推广到具有C个输入通道的信号X和F个滤波器中,则特征映射的式子如下:
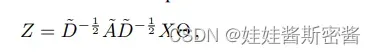
其中Θ是滤波参数矩阵,Z是卷积后的信号矩阵。
3.半监督节点分类
在解决完了模型f ( X , A ) 可以在图中有效传播信息之后,我们回归到半监督节点分类的问题上来。一个整体的多层半监督GCN模型如下图所示: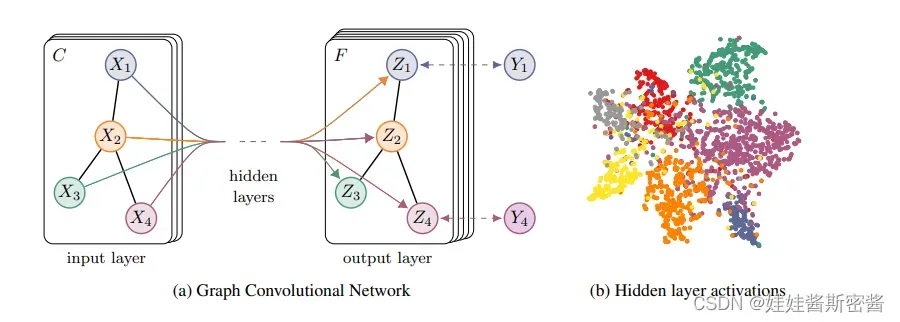
左图(a)是一个GCN的网络示意图,输入层拥有C个通道,中间包含若干隐藏层,输出层有F个特征映射,图的结构在层之间共享,标签用Yi表示。
右图(b)是一个两层GCN在Cora数据集上训练得到的隐藏层激活值的形象表示,颜色代表文档的类别。
预处理出A横,则可以使模型更加简洁:
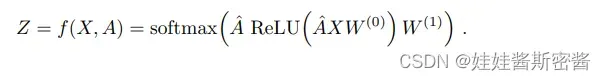
其中W(0)为输入层到隐藏层的权重矩阵;W(1)为隐藏层到输入层的权重矩阵
softmax函数的定义为:softmax函数可以将多分类的输出值转换为范围在[0, 1]和为1的概率分布,作用在每一行上

之后,需要评估所有标记标签的交叉熵误差,交叉熵损失函数刻画了实际输出概率与期望输出概率之间的相似度,若交叉熵的值越小,两个概率分布就越接近。式子如下图所示:
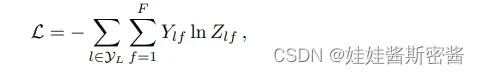
Yl是所有带标签节点的索引集合, Y 是真实标签, Z 是网络输出。将标签传给交叉熵就可以让网络进行学习了,经过训练后, 便可以得到无标签节点的标签。
最后使用梯度下降算法进行训练网络中的权重W(0)和W(1),对每个完整的数据集执行批量梯度下降算法。
4.实验
论文中提到该模型在实验中得到了测试,主要有引文网络中的半监督的文档分类、知识图中提取二分图的半监督实体分类。
使用到的数据集如下表所示:
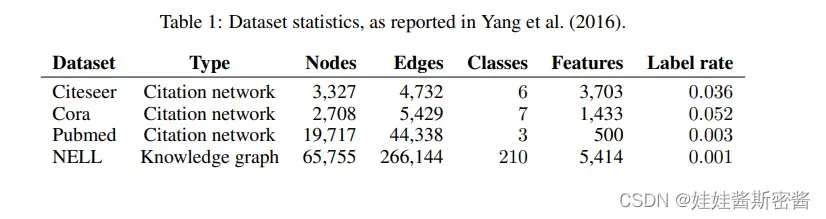
简单分析一下cora数据集:该数据集共2708个样本点,每个样本点都是一篇科学论文,所有样本点被分为7个类别。每篇论文都由一个1433维的词向量表示,所以,每个样本点具有1433个特征。词向量的每个元素都对应一个词,且该元素只有0或1两个取值。取0表示该元素对应的词不在论文中,取1表示在论文中。所有的词来源于一个具有1433个词的字典。
每篇论文都至少引用了一篇其他论文,或者被其他论文引用,也就是样本点之间存在联系,没有任何一个样本点与其他样本点完全没联系。如果将样本点看做图中的点,则这是一个连通的图,不存在孤立点。
5.结果
实验结果如下表所示:
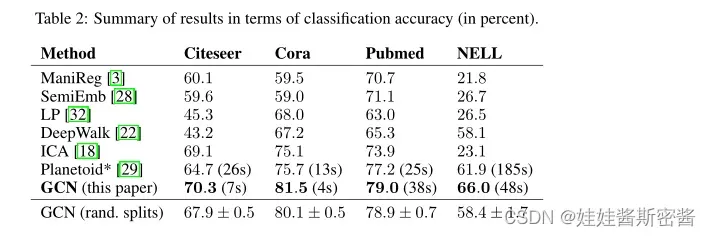
论文中对比了其他方法所作出的实验结果,可以看出,本篇论文的图卷积方法有较高的准确性。
总结
花了一些时间精读和领会,确实有了不小的收获。花了大量的时间在基本概念和计算公式的查阅和理解上,初次阅读当然也不会完全理解,还需要多次精细阅读,在实践中将理论充分运用。继续加油吧。如果有一些新的发现和收获,还会继续补的~
文章出处登录后可见!