


前言
不得不说环境是一个非常玄学的东西,距离上次成功在 FB15k-237 数据集上跑 convE 模型没多久
ConvE,知识图谱嵌入(KGE)论文复现(Ubuntu 20.04)_Starprog_UESTC_Ax的博客-CSDN博客_conve 知识图谱ConvE(KGE模型)—论文复现(Ubuntu 20.04)(2022.03.07)
RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED在跑两次模型之间这段时间,我并没有动我的 GPU 环境,包括内核都用的之前的:
内核版本:5.13.0-35-generic
uname -a![]()

另外,用这个环境跑 OpenKE【这 个工具包不含convE 】 也都没问题
网上搜了这个错误,有的说是指定显卡号,大多说是 cuda 和 cuDNN 版本不匹配的问题,让安装对应版本的 cuDNN。由于我之前装的时候,cuda 和 cuDNN 版本是匹配的【是否匹配,在 cuDNN 官网 可查】,所以我将 cuDNN 卸载重装,最终成功,把今天排错解决过程放在下边,大家有需要可以参考
一、检查是否有可用的显卡
输入 python 进入环境,运行命令:
import torch
print(torch.cuda.device_count()) #可用GPU数量如果 没有可用显卡 或 GPU 环境配置有误,就会输出 0,在模型运行中,就会报以下错误:
cuda runtime error (38) : no CUDA-capable device is detected我的莫名其妙重启解决了这个错误【也可以通过开机的高级选项,换个内核版本看看】,输出 0 这种情况每台机器不一样,详细原因可以百度对应解决,多说无益…
如果输出大于等于 2,前言部分所提错误可能是由于没有指定显卡号造成的,可以在模型代码前加入一行:
os.environ['CUDA_VISIBLE_DEVICES'] = '0'由于我的输出为 1,错误应该不在这一节
二、检查 cuda 版本 和 cuDNN 版本
① 检查 cuda 版本
查询当前驱动支持的最高版本:
nvidia-smi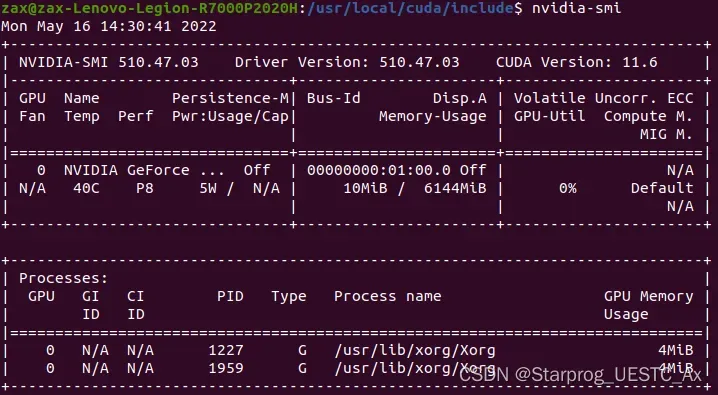

查询目前安装的 cuda 版本:
nvcc -V

也可以通过如下命令,看到更为详细的信息,包括与之 communicate 的驱动:
cat /usr/local/cuda/cuda.json② 检查 cuDNN 版本
有 cudnn.h 文件但无输出,版本未知,理论上,我之前安装的 v 8.3.0,不会去傻乎乎动这个库的
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2三、卸载并重新安装 cuDNN
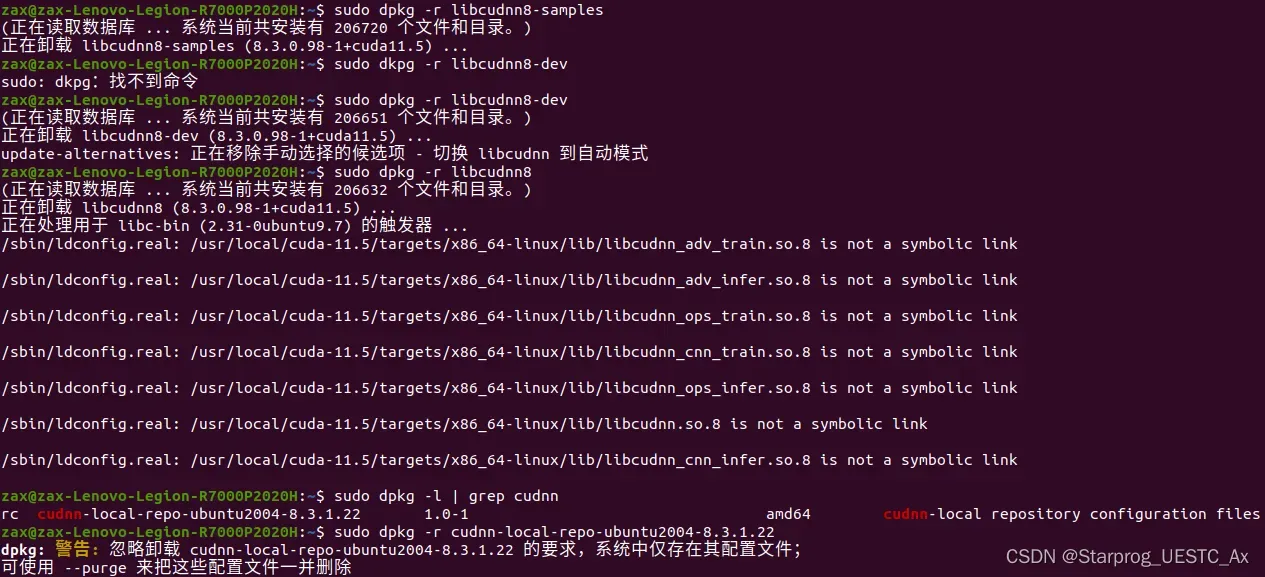
① 卸载 cuDNN v 8.3.0
查找出现位置:


注意按照下图顺序卸载【含 2004 的那项那个不卸】:

② 安装 cuDNN v 8.3.0
重复内容,不再赘述,参考以下博文:
(15条消息) Ubuntu 20.04 系统(双系统环境下)中深度学习环境配置(Pytorch + GPU)_Starprog_UESTC_Ax的博客-CSDN博客_ubuntu子系统![]()

AttributeError: module 'torch.jit' has no attribute 'unused'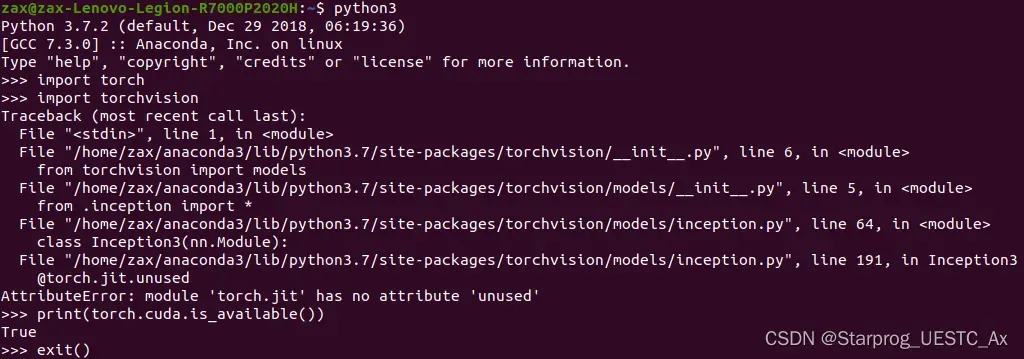

原因:torch 和 torchvision 版本不匹配
解决:
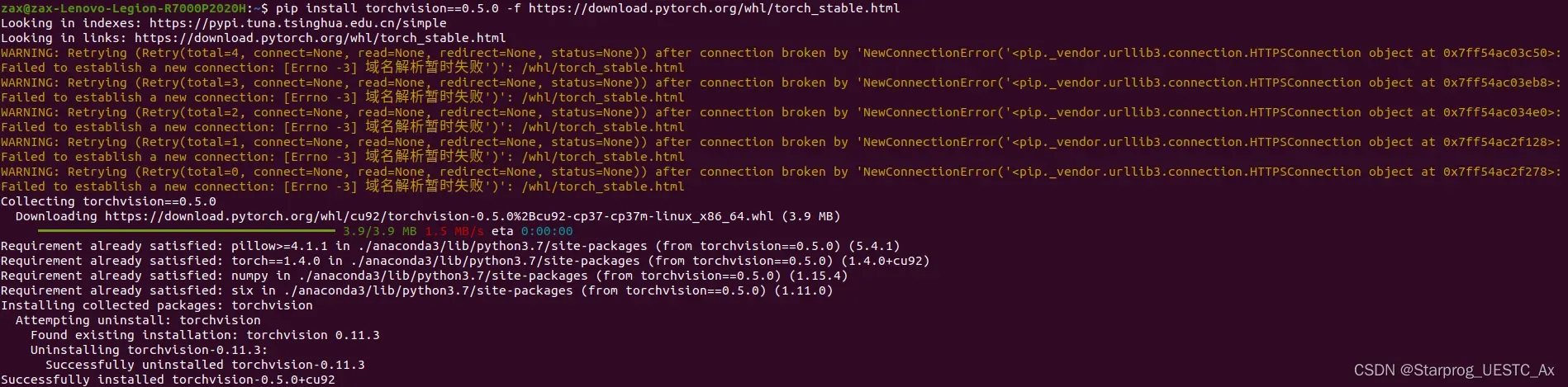
安装 torch 1.4.0 版本:
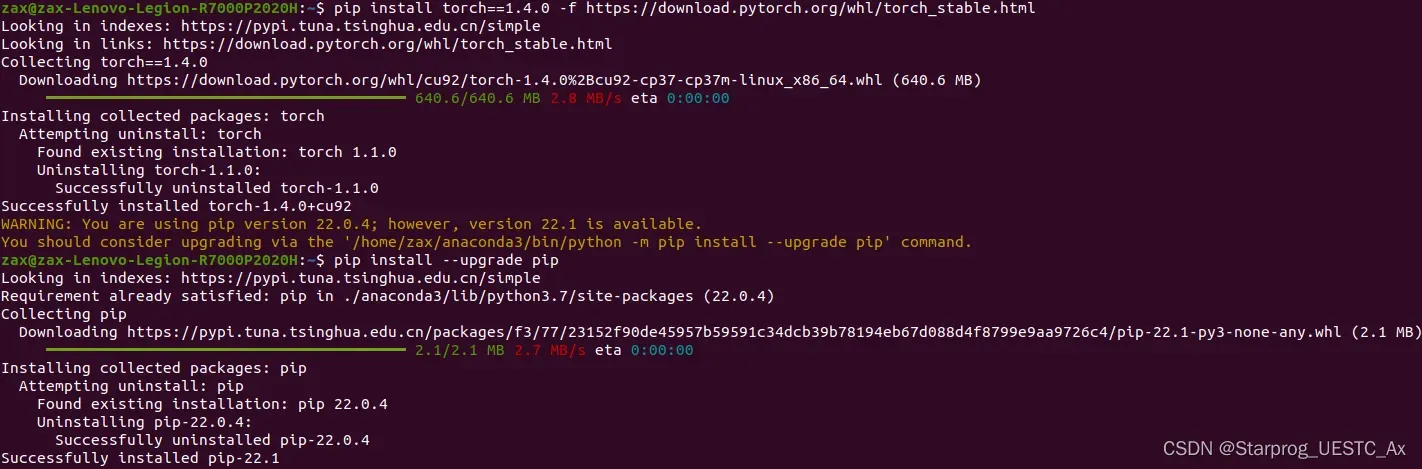

安装 torchvision 0.5.0 版本
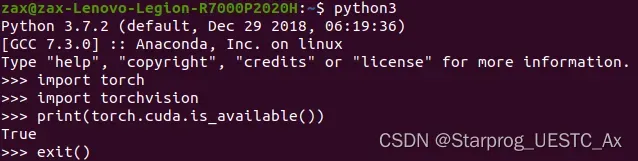
再次验证,成功:

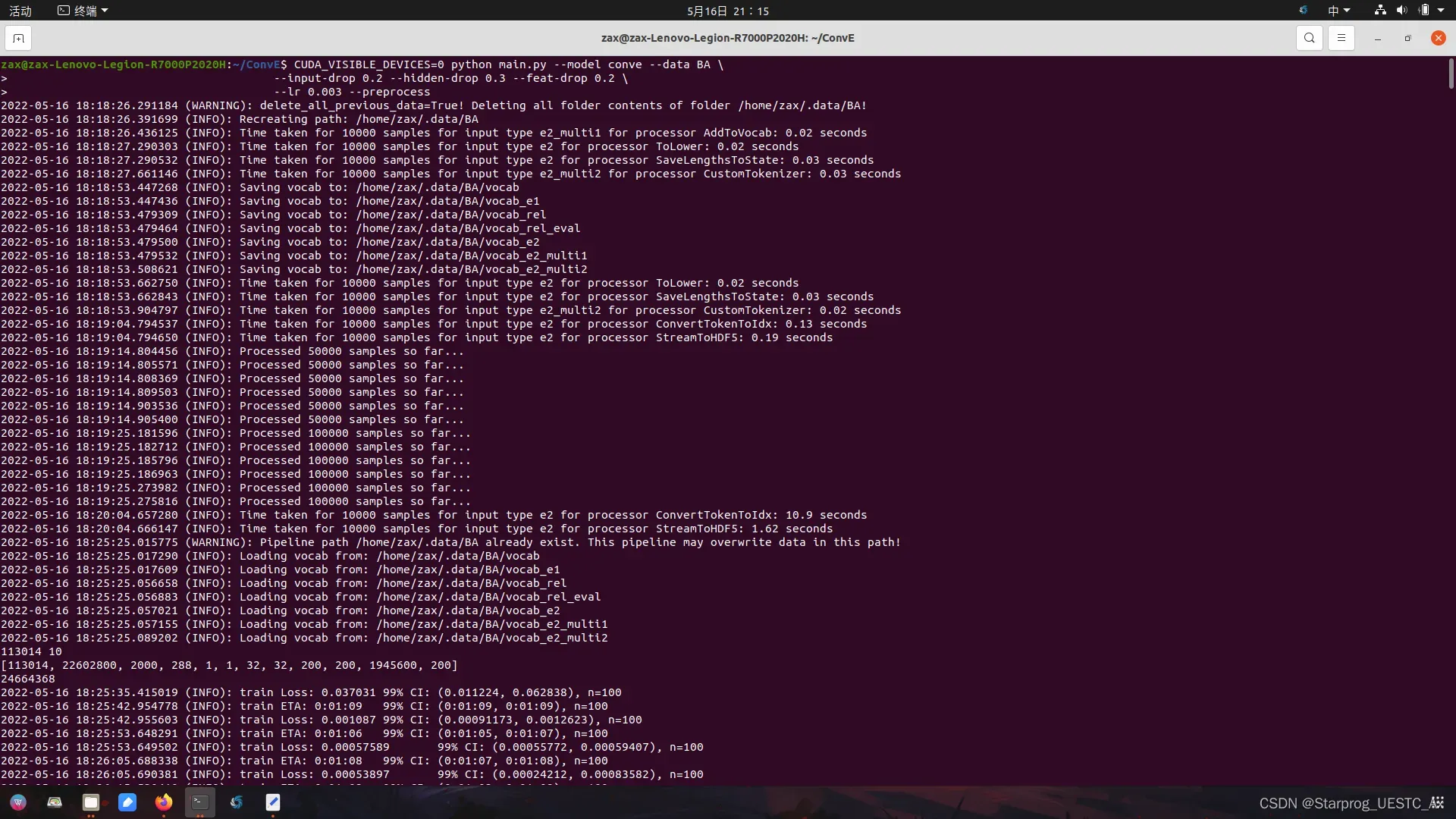
四、重跑模型 convE
python wrangle_KG.py BA
CUDA_VISIBLE_DEVICES=0 python main.py --model conve --data BA \
--input-drop 0.2 --hidden-drop 0.3 --feat-drop 0.2 \
--lr 0.003 --preprocess成功执行:

附录
换源加速安装
如果下载速度很慢,在原来安装语句上添加 -i 和 如下任一镜像地址即可切换国内服务器:
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
文章出处登录后可见!